खोज एपीआई विरुद्ध ज्ञान आपूर्ति शृंखला: कृत्रिम बुद्धिमत्ता डेटा इंफ्रास्ट्रक्चर गाइड

Rajinder Singh
Deep Learning Researcher
टीएल; डीआर
- सर्च एपीआई टूल तेज खोज के लिए उपयोगी होते हैं, लेकिन उत्पादन एआई प्रणालियों की पूरी आवश्यकताओं को नहीं पूरा करते हैं।
- ज्ञान आपूर्ति श्रृंखला खोज, निष्कर्षण, पुष्टिकरण, भंडारण, अनुक्रमण और मॉनिटरिंग शामिल है।
- एक SERP एपीआई रैंक किए गए खोज परिणाम संग्रह करने में मदद करता है, जबकि वेब डेटा एपीआई पृष्ठ-स्तरीय सामग्री संग्रह करने में मदद करता है।
- मजबूत वेब डेटा बुनियादी ढांचा ताजगी, स्रोत की गुणवत्ता, लेखापरीक्षण योग्यता और नीति-जागरूक संग्रह पर निर्भर करता है।
- एआई डेटा पाइपलाइन को अन्वेषण के साथ पारसिंग, समृद्धि, शासन और नीचे के मॉडल उपयोग से जोड़ना चाहिए।
- अनुमोदित स्वचालन के लिए, टीमें जांच चरणों द्वारा संग्रह प्रवाह को बाधित कर सकती हैं, तो विश्वसनीयता परतें भी आवश्यक हो सकती हैं।
परिचय
संक्षिप्त उत्तर सरल है। एक सर्च एपीआई एक अन्वेषण इंटरफेस है, जबकि ज्ञान आपूर्ति श्रृंखला एआई डेटा बुनियादी ढांचे के लिए एक संचालन मॉडल है। यह लेख एआई इंजीनियर, तकनीकी संस्थापक, एसईओ टीमें और डेटा प्लेटफॉर्म निर्माता के लिए है जिन्हें गुणवत्ता या सुसंगतता के बिना वर्तमान वेब डेटा की आवश्यकता होती है। अगर आप एक सर्च इंटरफेस, एक SERP एपीआई और एक व्यापक वेब डेटा बुनियादी ढांचा स्टैक के बीच चयन कर रहे हैं, तो सही निर्णय जोखिम, ताजगी और नीचे के उपयोग पर निर्भर करता है। मुख्य मूल्य व्यावहारिक स्पष्टता है। आप देखेंगे कि प्रत्येक विकल्प कहां फिट होता है, कहां असफल होता है और एक अधिक विश्वसनीय एआई डेटा पाइपलाइन कैसे डिज़ाइन करें।
सर्च एपीआई और ज्ञान आपूर्ति श्रृंखला का परिचय
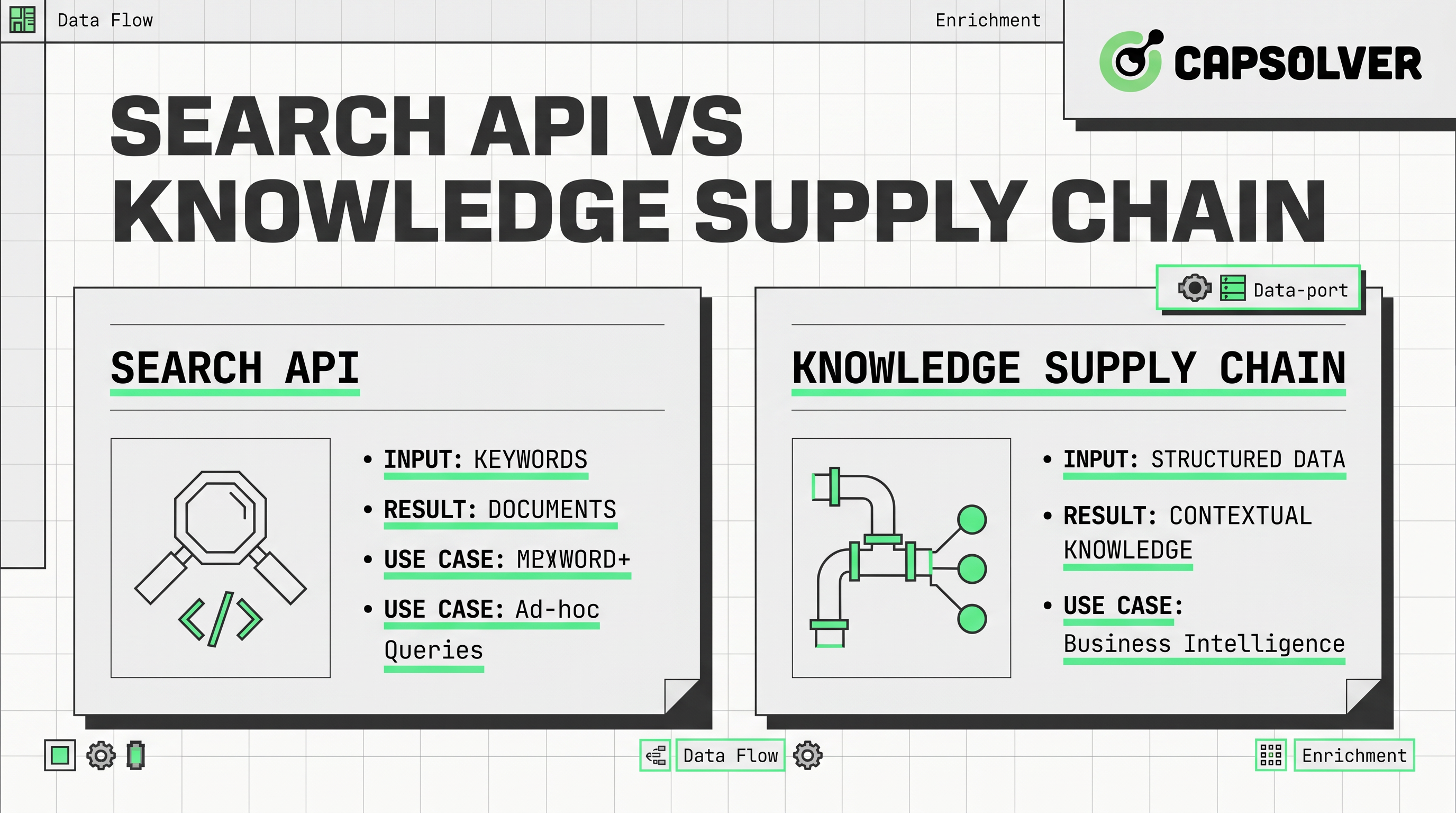
मुख्य अंतर वास्तुविधि में है। एक सर्च एपीआई आमतौर पर एक प्रश्न स्वीकार करता है और एक सूची से रैंक किए गए लिंक, टुकड़े या सारांश परिणाम लौटाता है। इस कारण, इन उपकरणों को टीमों के लिए आकर्षक बनाता है जिन्हें तेज उत्तर, हल्का समृद्धि या प्रारंभिक प्रोटोटाइप की आवश्यकता होती है।
एक ज्ञान आपूर्ति श्रृंखला डिज़ाइन के अनुसार व्यापक होती है। यह एआई के लिए डेटा अधिग्रहण को एक लगातार प्रवाह के रूप में लेता है, स्रोत खोज से संग्रह, पुष्टिकरण, भंडारण, रूपांतरण और वितरण तक। यह मॉडल एजेंट प्रणालियों, बाजार जांच उपकरणों और दोहराए जा सकने वाले निर्णयों के लिए समर्थन करने वाली अन्वेषण परतों के साथ बेहतर मेल खाता है।
यह अंतर महत्वपूर्ण है क्योंकि एआई प्रणालियां जो कुछ भी प्राप्त करती हैं, उस पर कार्य करती हैं। एनआईएसटी एआई जोखिम प्रबंधन ढांचा बताता है कि विश्वसनीय एआई डिज़ाइन, विकास, उपयोग और मूल्यांकन अभ्यास पर निर्भर करता है, मॉडल आउटपुट के साथ नहीं। व्यावहारिक रूप से, यह अर्थ यह है कि अन्वेषण परत जोखिम के क्षेत्र में है।
एक और कारण नीति है। गूगल सर्च सेंटर कहता है कि रोबोट्स.टीएक्स्ट का मुख्य उद्देश्य बुलडोजर ट्रैफिक के प्रबंधन के लिए होता है और यह सामग्री छिपाने के लिए एक सार्वभौमिक विधि नहीं है। यह याद दिलाना किसी भी टीम के लिए महत्वपूर्ण है जो वेब डेटा बुनियादी ढांचा बना रही है। सुसंगतता पहले अनुरोध से शुरू होती है।
डेटा अन्वेषण प्रणालियों में सर्च एपीआई कैसे काम करता है
सबसे सरल विवरण यह है। एक सर्च एपीआई खोज परत पर स्थित होता है। यह एक पाठ प्रश्न को रैंक किए गए परिणाम में बदलता है जो चैटबॉट, कॉपिलॉट या अनुसंधान सहायकों को भोजन प्रदान कर सकता है।
अधिकांश सर्च उपकरण गति और डेवलपर सुविधा के लिए अनुकूलित होते हैं। आमतौर पर, यह सूचीबद्ध डेटा, कैश किए गए परिणाम या एक पूर्व-निर्मित संबंधता परत के लिए होता है। कम जोखिम वाले कार्यों के लिए, यह पर्याप्त है। एक समर्थन बॉट, एसईओ विचार उत्पादन उपकरण या एक प्रोटोटाइप एजेंट आमतौर पर इस तरह के अन्वेषण एंडपॉइंट से लाभ उठा सकते हैं क्योंकि प्रणाली को गहरी साक्ष्य की आवश्यकता से पहले दिशा की आवश्यकता होती है।
एक SERP एपीआई संकीर्ण है। यह सर्च इंजन परिणाम पृष्ठों और संबंधित परिणाम तत्वों पर केंद्रित होता है। यह रैंक ट्रैकिंग, प्रश्न मॉनिटरिंग और प्रतिस्पर्धी एसईओ अनुसंधान के लिए उपयोगी हो सकता है। हालांकि, एक SERP एपीआई अभी भी सर्च परत के बजाय पूर्ण सामग्री परत का प्रतिनिधित्व नहीं करता है। अगर आपकी प्रणाली वास्तविक पृष्ठ पाठ, संरचित क्षेत्र या ऐतिहासिक तुलना की आवश्यकता होती है, तो आमतौर पर एक अन्य चरण की आवश्यकता होती है।
यह जगह है जहां लोग खोज के साथ ज्ञान के बीच भ्रम में रहते हैं। खोज आपको देखने के लिए कहता है। ज्ञान के लिए आपको वास्तविक रूप से वहां होने वाले को लोड करना, पारस करना और जांचना आवश्यक होता है। एक सर्च एंडपॉइंट पहले भाग में मदद करता है। यह पूर्ण एआई डेटा पाइपलाइन पूरा नहीं करता है।
एआई आर्किटेक्चर में ज्ञान आपूर्ति श्रृंखला क्या है
बेहतर तरीका ऑपरेशनल रूप से परिभाषित करना है। एक ज्ञान आपूर्ति श्रृंखला वह प्रणाली है जो ओपन वेब से डेटा को मॉडल, एजेंट और विश्लेषकों के लिए निर्णय-तैयार संदर्भ में ले जाती है।
आपूर्ति-श्रृंखला विचार हाल के उद्योग लेखन में दिखाई देता है, लेकिन बहुत सारे लेख अंतर्निहित रूप से रह जाते हैं। व्यावहारिक संस्करण में छह स्तर होते हैं। पहला खोज इंटरफेस, SERP एपीआई, फीड, साइटमैप या ज्ञात स्रोतों के माध्यम से खोज होती है। दूसरा एक वेब डेटा एपीआई, ब्राउजर ऑटोमेशन या प्रत्यक्ष स्रोत कनेक्टर्स के माध्यम से निष्कर्षण होता है। तीसरा सामान्यीकरण होता है, जहां एचटीएमएल, जेसॉन, पीडीएफ और अतिरिक्त जानकारी को संगत रिकॉर्ड में बदल दिया जाता है। चौथा परीक्षण होता है, जो ताजगी, दोहराव, स्वामित्व और स्रोत की गुणवत्ता की जांच करता है। पांचवां भंडारण और इंडेक्सिंग होता है जो अन्वेषण के लिए होता है। छठा अनुक्रमण होता है, जहां एआई डेटा पाइपलाइन परिणाम को आरएजी प्रणालियों, मूल्यांकनकर्ताओं या एजेंट उपकरणों में भेजता है।
मॉडल संदर्भ प्रोटोकॉल एक उपयोगी संकेत प्रदान करता है। MCP दस्तावेज़ इसे एआई एप्लिकेशन के लिए डेटा स्रोतों, उपकरणों और वर्कफ़्लो के साथ जोड़ने के लिए एक खुला मानक के रूप में परिभाषित करता है। यह सर्च परत को बदल नहीं देता है, लेकिन यह यह स्पष्ट करता है कि ज्ञान आपूर्ति श्रृंखला को अन्वेषण के बाहर के इंटरफेस शामिल करना आवश्यक है।
संक्षेप में, एक सर्च एपीआई एक उपकरण है। एक ज्ञान आपूर्ति श्रृंखला एक प्रणाली है।
सर्च एपीआई और ज्ञान आपूर्ति श्रृंखला के बीच मुख्य अंतर
सबसे स्पष्ट उत्तर ऑपरेटिंग सीमाओं में है। एक सर्च एपीआई आमतौर पर तेज खोज के लिए अनुकूलित होता है। एक ज्ञान आपूर्ति श्रृंखला वास्तविक कार्यभार में डेटा गुणवत्ता के लिए अनुकूलित होता है।
तुलना सारांश
| आयाम | सर्च एपीआई | SERP एपीआई | ज्ञान आपूर्ति श्रृंखला |
|---|---|---|---|
| प्राथमिक कार्य | प्रश्न-आधारित खोज | सर्च-परिणाम संग्रह | एआई के लिए पूर्ण डेटा अधिग्रहण |
| सामान्य आउटपुट | लिंक, टुकड़े, सारांश | रैंक किए गए SERP तत्व | पूर्ण सामग्री, अतिरिक्त जानकारी, इतिहास, पुष्टिकरण |
| सबसे अच्छा | प्रोटोटाइप, सहायक, हल्का अनुसंधान | एसईओ मॉनिटरिंग, परिणाम ट्रैकिंग | एजेंट, बाजार जांच प्रणालियां, उत्पादन एआई |
| ताजगी नियंत्रण | सीमित और प्रदाता-निर्भर | मध्यम सर्च परत पर | उच्च जब प्रत्यक्ष संग्रह के साथ |
| साक्ष्य गहराई | कम से मध्यम | कम से मध्यम | उच्च |
| नीति फिट | सीमित | मध्यम | मजबूत |
| एआई डेटा पाइपलाइन में भूमिका | पहला चरण | पहला चरण SERP ध्यान के साथ | बहु-चरण संचालन मॉडल |
वर्तमान लेखों में प्रतिस्पर्धा के अंतर में व्यावहारिक निर्देश है। बहुत सारे पोस्ट यह स्पष्ट करते हैं कि सर्च उपकरण क्यों तेज हैं, या ज्ञान आपूर्ति श्रृंखला क्यों रणनीतिक लगती है। कम लोग बताते हैं कि एक वास्तविक वेब डेटा बुनियादी ढांचा में एक कहां खत्म होता है और दूसरा कहां शुरू होता है। यह सीमा प्रणाली विश्वसनीयता निर्धारित करती है।
दूसरा अंतर लेखापरीक्षण योग्यता है। जब एक मॉडल केवल टुकड़ों से उत्तर देता है, तो टीमें आमतौर पर स्रोत परिवर्तन पथ की जांच नहीं कर सकती हैं। जब एक ज्ञान आपूर्ति श्रृंखला पृष्ठ सामग्री, समय-चिह्न, निष्कर्षण लॉग और गुणवत्ता जांच के साथ संग्रहित करती है, तो एक ही उत्तर की समीक्षा और सुधार आसान होता है।
तीसरा अंतर विफलता लागत है। यदि एक खोज एपीआई एक जीर्ण सारांश लौटाता है, तो एक प्रोटोटाइप चैट एप्लिकेशन अभी भी स्वीकार्य लग सकता है। यदि एक ही समस्या मूल्य जांच या नीति मॉनिटरिंग को प्रभावित करती है, तो लागत बहुत अधिक हो सकती है।
एआई एजेंट और डेटा बुनियादी ढांचा में उपयोग मामले
संगतता सबसे आसानी से उपयोग मामलों के माध्यम से देखी जा सकती है। एक सर्च एपीआई तब अच्छा काम करता है जब प्रणाली को तेज अवगत होने की आवश्यकता होती है। एजेंट इस अन्वेषण परत का उपयोग गंतव्य यूआरएल, हाल के उल्लेख या विषय समूह खोजने के लिए कर सकता है जब गहरा अन्वेषण शुरू होता है।
एक SERP एपीआई जब कार्य सर्च-मुख्य होता है तो अच्छा काम करता है। एसईओ टीमें रैंक मॉनिटरिंग, भुगतान और ऑर्गेनिक परिणाम विश्लेषण और क्षेत्रीय प्रश्न परीक्षण के लिए SERP एपीआई का उपयोग करती हैं। आउटपुट उपयोगी है, लेकिन यह एक ही परत के साक्ष्य रहता है।
एक ज्ञान आपूर्ति श्रृंखला जब कार्य ऑपरेशनल होता है तो बेहतर होता है। मूल्य मॉनिटरिंग, लीड जांच, नीति ट्रैकिंग, कैटलॉग समृद्धि, खरीदारी अनुसंधान और समाचार सत्यापन सभी रैंक किए गए परिणामों से अधिक आवश्यकता होती है। उन्हें निष्कर्षण, समय-चिह्न, स्कीमा नियंत्रण और एक विश्वसनीय एआई डेटा पाइपलाइन की आवश्यकता होती है।
यह वह जगह है जहां आंतरिक उपकरण महत्वपूर्ण होते हैं। एजेंट बनाने वाली टीमें एआई एजेंट फ्रेमवर्क, सर्वोत्तम डेटा निष्कर्षण उपकरण और एलएमएम ट्रेनिंग के लिए डेटा संग्रह के पैमाने पर के एक स्टैक में जोड़ सकती हैं। ये घटक तब आसानी से मूल्यांकन किए जा सकते हैं जब आप खोज, निष्कर्षण और अनुक्रमण को अलग करते हैं बजाय ऊपरी स्रोत प्रविष्टि को एक ही उपकरण श्रेणी के रूप में लेते हैं।
वेब स्क्रैपिंग और डेटा इंजीनियरिंग उपकरणों के लिए अनुप्रयोग
सबसे बड़ा अध्ययन यह है कि अन्वेषण अकेले विश्वसनीय डेटा उत्पन्न नहीं करता है। एक वेब स्क्रैपिंग एपीआई महत्वपूर्ण है क्यो