Cómo scrapear ofertas de trabajo sin ser bloqueado

Lucas Mitchell
Automation Engineer
TL;DR:
- Rotar proxies residenciales: Utilice IPs residenciales de alta calidad para evitar ser marcado por grandes tableros de empleo o plataformas de redes profesionales.
- Imitar huellas dactilares de navegador: Ajuste su huella TLS y encabezados HTTP a perfiles de navegador real usando herramientas como
curl_cffi. - Gestionar CAPTCHAS automáticamente: Integre un solucionador confiable como CapSolver para manejar desafíos de Cloudflare Turnstile y reCAPTCHA.
- Respetar robots.txt y límites de velocidad: Implemente retrasos aleatorios y siga guías éticas para mantener el acceso a largo plazo.
Introducción
La extracción de listas de empleos se ha convertido en una pieza clave para agencias de reclutamiento, investigadores del mercado y agregadores de empleos. Sin embargo, los grandes tableros de empleo han implementado medidas de seguridad sofisticadas que pueden detener su recolección de datos en segundos. Si alguna vez ha enfrentado bloqueos inmediatos de IP o bucles de verificación interminables al intentar extraer ofertas de empleo, no está solo. El desafío radica en hacer que sus scripts automatizados sean indistinguibles del comportamiento de navegación humana. Esta guía proporciona un mapa técnico completo para ayudarle a extraer listas de empleos de manera efectiva mientras mantiene un perfil de detección bajo.
¿Por qué los tableros de empleo bloquean sus extracciones?
Las plataformas de empleo y sitios de redes profesionales invierten grandes recursos en seguridad para proteger sus datos propietarios y garantizar la estabilidad del sitio. Principalmente utilizan cuatro capas de detección para identificar y bloquear extracciones.
Reputación de IP y límites de velocidad
La mayoría de los tableros de empleo rastrean el número de solicitudes que provienen de una sola dirección IP. Si supera un cierto umbral, su IP se bloquea temporal o permanentemente. Las IPs de centros de datos son particularmente vulnerables porque se identifican fácilmente como pertenecientes a granjas de servidores en lugar de usuarios reales.
Detección de huella de navegador y TLS
Los sistemas modernos anti-bot como Cloudflare y DataDome analizan más allá de su Agente de usuario. Analizan su handshake TLS (Capa de Seguridad de Transporte), verificando conjuntos de cifra y extensiones específicas. Si su script de Python usa la biblioteca estándar requests, su huella JA3 señalará inmediatamente que es un bot.
Análisis de comportamiento
Los usuarios humanos no hacen clic en enlaces cada 0,5 segundos ni navegan en patrones perfectamente lineales. Las extracciones que muestran comportamiento robótico, como intervalos de solicitud fijos o carga faltante de CSS/imagenes, son rápidamente marcadas por motores de análisis de comportamiento.
CAPTCHAS y desafíos de JavaScript
Cuando un sitio es sospechoso pero no seguro, activa un desafío. Esto podría ser una verificación simple de ejecución de JavaScript o un CAPTCHA complejo. Sin una forma automatizada de resolver estos desafíos, su flujo de trabajo de extracción se detendrá por completo.
Técnicas esenciales para extracción de empleos no detectables
Para construir un extrayedor resistente, debe abordar cada capa de detección con contra medidas técnicas específicas.
1. Implementar rotación de proxies residenciales
Usar una sola IP es la forma más rápida de ser bloqueado. En su lugar, debe usar un conjunto de proxies residenciales. A diferencia de las IPs de centros de datos, las IPs residenciales son asignadas por proveedores de servicios de Internet (ISPs) a hogares reales, lo que las hace mucho más difíciles de distinguir del tráfico legítimo.
| Tipo de Proxy | Riesgo de Detección | Costo | Caso de uso ideal |
|---|---|---|---|
| Centro de datos | Alto | Bajo | Sitios de baja seguridad, pruebas |
| Residencial | Bajo | Medio | Tableros de empleo y motores de búsqueda de alta seguridad |
| Móvil (4G/5G) | Muy bajo | Alto | Sistemas anti-bot muy agresivos |
Al extraer listas de empleos, asegúrese de que su proveedor de proxies soporte rotación automática. Esto garantiza que cada solicitud o sesión provenga de una ubicación geográfica y IP diferente.
2. Dominar la imitación de huella TLS
Como se mencionó anteriormente, bibliotecas estándar como requests o urllib tienen huellas TLS distintas. Para resolver esto, debe usar curl_cffi, que le permite imitar el handshake TLS de un navegador real como Chrome o Firefox.
python
from curl_cffi import requests
# Imitando la huella TLS de Chrome 120
response = requests.get(
"https://www.target-job-board.com/jobs?q=software+engineer",
impersonate="chrome120",
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
}
)
print(response.status_code)Al coincidir su Agente de usuario con el perfil TLS correspondiente, reduce significativamente las probabilidades de ser bloqueado por Cloudflare o Akamai.
3. Manejar CAPTCHAS con CapSolver
Incluso con encabezados y proxies perfectos, eventualmente encontrará un desafío. Los tableros de empleo utilizan con frecuencia Cloudflare Turnstile o reCAPTCHA para verificar usuarios. Resolver estos manualmente es imposible a escala. Es aquí donde CapSolver se convierte en una parte esencial de su pila de automatización.
CapSolver proporciona una API fluida para resolver diversos tipos de CAPTCHA. Por ejemplo, si encuentra un desafío de Cloudflare Turnstile al usar una API de búsqueda de empleos o al extraer plataformas de empleo principales, puede usar la siguiente implementación oficial:
python
import requests
import time
api_key = "SU_CLAVE_DE_API_DE_CAPSOLVER"
site_key = "0x4XXXXXXXXXXXXXXXXX" # Encontrado en el HTML del sitio objetivo
site_url = "https://www.target-job-board.com"
def solve_turnstile():
payload = {
"clientKey": api_key,
"task": {
"type": 'AntiTurnstileTaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
task_id = res.json().get("taskId")
if not task_id:
return None
while True:
time.sleep(1)
result_res = requests.post("https://api.capsolver.com/getTaskResult", json={"clientKey": api_key, "taskId": task_id})
result = result_res.json()
if result.get("status") == "ready":
return result.get("solution", {}).get('token')
if result.get("status") == "failed":
return None
token = solve_turnstile()Integrar esto en su flujo de trabajo asegura que su extrayedor pueda continuar su tarea sin intervención humana, manteniendo efectivamente la disponibilidad de su canal de datos.
Redime tu código de bonificación de CapSolver
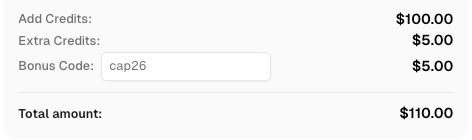
¡Aumenta tu presupuesto de automatización instantáneamente!
Usa el código de bonificación CAP26 al recargar tu cuenta de CapSolver para obtener un 5% adicional en cada recarga — sin límites.
Redímelo ahora en tu Panel de CapSolver
4. Optimizar encabezados de solicitud y referers
Un error común es enviar solicitudes "descubiertas". Los navegadores reales siempre envían un encabezado Referer y varios encabezados Sec-CH-UA (Hints del Cliente). Al extraer listas de empleos, siempre establezca el referer en la página principal del sitio o en una página de resultados anteriores.
- User-Agent: Use una cadena reciente y popular.
- Referer:
https://www.google.com/o el dominio del sitio. - Accept-Encoding:
gzip, deflate, br(asegúrese de que su código pueda descomprimir estos).
Resumen de comparación: Estrategias de extracción
| Estrategia | Efectividad | Esfuerzo de implementación | Recomendado para |
|---|---|---|---|
| Python Básico Requests | Muy baja | Bajo | Blogs personales no protegidos |
| Navegadores sin cabeza (Selenium) | Medio | Medio | Sitios con JavaScript pesado |
| Navegadores stealth + proxies | Alto | Alto | Plataformas de empleo de alta seguridad |
| API de extracción web | Muy alto | Bajo | Extracción de datos de empleo a escala empresarial |
Consideraciones éticas y legales
Aunque el éxito técnico es importante, debe priorizar la extracción ética. Siempre revise el archivo robots.txt del sitio y sus términos de servicio. Según las directrices del Consortium de la World Wide Web (W3C), la recolección ética de datos implica respetar la salud del servidor objetivo evitando sobrecargarlo con solicitudes excesivas. Además, la Electronic Frontier Foundation destaca que la extracción de datos públicamente disponibles generalmente está protegida, pero debe evitar acceder a información privada de usuarios o resolver paredes de inicio de sesión sin permiso.
Conclusión
Extraer eficazmente listas de empleos sin ser bloqueado requiere un enfoque de múltiples capas. Combinando la rotación de proxies residenciales, la imitación de huellas TLS y la resolución automatizada de CAPTCHAS mediante CapSolver, puede construir un sistema robusto que imite el comportamiento humano. Recuerde que el paisaje de extracción web está en constante evolución; mantenerse actualizado con las últimas tendencias en gestión de seguridad es clave para mantener su ventaja competitiva.
Preguntas frecuentes
1. ¿Es legal extraer ofertas de empleo?
Generalmente, extraer ofertas de empleo públicamente disponibles es legal en muchas jurisdicciones, siempre que no viole la Ley de Fraude por Computadora y Abuso (CFAA) o leyes de derechos de autor. Siempre consulte con asesoría legal para casos específicos.
2. ¿Con qué frecuencia debo rotar mis proxies?
Para sitios de alta seguridad, es mejor rotar su IP para cada solicitud o cada pocos minutos para evitar la detección de patrones.
3. ¿Puedo extraer sitios de redes profesionales sin cuenta?
Muchas plataformas profesionales son altamente restrictivas. Aunque algunas perfiles y empleos públicos son visibles, la mayoría de los datos están detrás de una pared de inicio de sesión. La extracción detrás de un inicio de sesión conlleva mayores riesgos legales y técnicos.
4. ¿Por qué mi navegador sin cabeza aún se atrapa?
Navegadores sin cabeza estándar como Puppeteer o Selenium dejan "huellas" como navigator.webdriver = true. Debería usar complementos como stealth para ocultar estas propiedades.
5. ¿Cuál es la mejor forma de evitar bloqueos de IP?
La forma más efectiva de evitar bloqueos de IP es una combinación de proxies residenciales y intervalos de solicitud aleatorios (jitter).