Cómo integrar soluciones reCAPTCHA v2 en Python para la extracción de datos

Adélia Cruz
Neural Network Developer

Introducción
A medida que Internet crece, el raspado web y la extracción de datos se utilizan ampliamente para recopilar información de los sitios web para diversos fines, incluida la inteligencia empresarial, la agregación de contenido y el análisis de mercado. Sin embargo, a medida que los bots se volvieron más sofisticados, los sitios web implementaron herramientas para diferenciar entre usuarios humanos y programas automatizados. Una de esas herramientas es reCAPTCHA. En este blog, exploraremos qué es reCAPTCHA, las diferentes versiones disponibles y cómo resolver los desafíos de reCAPTCHA v2 utilizando Capsolver en Python. Finalmente, repasaremos un código de ejemplo simple para integrar reCAPTCHA v2 en su proyecto de extracción de datos.
¿Qué es reCAPTCHA?

reCAPTCHA es un servicio gratuito desarrollado por Google que ayuda a proteger los sitios web del spam y el abuso asegurando que una persona real (en lugar de un bot automatizado) esté interactuando con el sitio. Cuando los usuarios visitan un sitio web que implementa reCAPTCHA, es posible que se les solicite que completen un desafío para verificar que son humanos.
Diferentes versiones de reCAPTCHA
Hay varias versiones de reCAPTCHA, cada una con sus propias fortalezas y casos de uso:
-
reCAPTCHA v1: La versión más antigua, ahora obsoleta. Requería que los usuarios transcribieran texto distorsionado de imágenes.
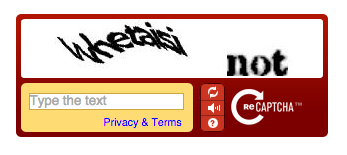
-
reCAPTCHA v2: Una versión más avanzada que presenta a los usuarios una casilla de verificación ("No soy un robot"). Si es necesario, también los desafía a seleccionar ciertas imágenes (como semáforos o pasos de cebra). Esta versión es la más utilizada en la actualidad.
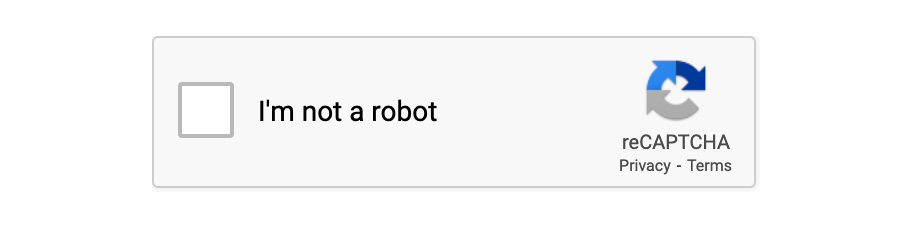
-
reCAPTCHA v3: Esta versión analiza el comportamiento del usuario y la interacción con el sitio web para asignar una puntuación de 0 a 1, donde 0 indica un bot y 1 indica un humano. Es más fluido para los usuarios, ya que no requiere desafíos interactivos.

-
reCAPTCHA invisible: Esta versión opera entre bastidores y solo presenta desafíos cuando se detecta actividad sospechosa. Está diseñado para ser invisible para los usuarios legítimos.
¿Qué es la extracción de datos?

Extracción de datos se refiere al proceso de recuperar datos estructurados de fuentes no estructuradas como páginas web, bases de datos u otros formatos digitales. Se utiliza comúnmente en el raspado web, donde los programas automatizados recopilan grandes cantidades de información de los sitios web para su análisis o agregación.
Casos de uso comunes para la extracción de datos
-
Investigación de mercado: Las empresas extraen datos de precios de la competencia y reseñas de clientes para ajustar sus estrategias de marketing y ventas.
-
Inteligencia empresarial: Las organizaciones rascan informes financieros, noticias y otros recursos para tomar decisiones comerciales informadas.
-
Agregación de contenido: Los sitios web que seleccionan y muestran información de varias fuentes a menudo extraen datos de otras páginas web.
-
Análisis SEO: La extracción de contenido, palabras clave y metaetiquetas de los sitios web de la competencia ayuda a optimizar las estrategias SEO.
Integración de la solución reCAPTCHA v2 en Python
Al extraer datos de sitios web, puede encontrar desafíos de reCAPTCHA. Esto representa un obstáculo para el raspado automatizado. Afortunadamente, herramientas como Capsolver pueden resolver los desafíos de reCAPTCHA v2 programáticamente, lo que le permite continuar con sus tareas de extracción de datos.
Aquí hay una implementación de Python para resolver reCAPTCHA v2 utilizando el paquete Capsolver.
Pasos:
-
Instala la biblioteca
capsolverejecutando:bashpip install capsolver -
Utiliza el siguiente código de Python para resolver el desafío reCAPTCHA v2:
python
import capsolver
# Considera usar variables de entorno para información sensible
capsolver.api_key = "Your Capsolver API Key"
PAGE_URL = "PAGE_URL"
PAGE_KEY = "PAGE_SITE_KEY"
def solve_recaptcha_v2(url,key):
solution = capsolver.solve({
"type": "ReCaptchaV2TaskProxyless",
"websiteURL": url,
"websiteKey":key,
})
return solution
def main():
print("Resolviendo reCaptcha v2")
solution = solve_recaptcha_v2(PAGE_URL, PAGE_KEY)
print("Solución: ", solution)
if __name__ == "__main__":
main()Explicación del código
-
Configuración de la API de Capsolver: En el código, definimos
capsolver.api_key, que debe contener tu clave de API de Capsolver. Esta clave autenticará tus solicitudes al servicio de Capsolver. -
Función Resolver: La función
solve_recaptcha_v2acepta laurlde la página y lasite_key(que es la clave reCAPTCHA presente en el sitio web). Envía una solicitud a Capsolver para resolver el desafío reCAPTCHA. -
Función principal: La función principal ejecuta el solucionador e imprime la solución.
-
Variables de entorno: Se recomienda utilizar variables de entorno para almacenar información confidencial como claves de API para una mejor seguridad. En el ejemplo anterior, debes reemplazar
Your Capsolver API Key,PAGE_URLyPAGE_SITE_KEYcon tus valores reales.
Código adicional
Reclama tu Código de bonificación para las mejores soluciones de captcha; CapSolver: scrape. Después de canjearlo, obtendrás un bono adicional del 5% después de cada recarga, ilimitado

Para obtener más información, lee este blog
Conclusión
reCAPTCHA es una herramienta esencial para proteger los sitios web de los bots, pero puede crear desafíos para fines de automatización legítimos, como la extracción de datos. El uso de herramientas como Capsolver permite a los desarrolladores resolver programáticamente los desafíos de reCAPTCHA v2, lo que permite una extracción de datos ininterrumpida. Siempre asegúrate de que tus actividades de extracción de datos cumplan con los términos de servicio y las pautas legales del sitio web para evitar cualquier problema.
Al integrar la solución proporcionada anteriormente en tus proyectos de Python, puedes continuar recopilando datos valiosos de los sitios web mientras superas los obstáculos de reCAPTCHA.


