Cómo funciona la Extracción de Datos con IA: Resolución de CAPTCHA, Procesamiento de LLM y Tuberías de Datos de la Web Estructurados
Aloísio Vítor
Image Processing Expert
Introducción: Más allá de la parsificación, se trata de la adquisición
La extracción de datos web tradicional depende de métodos de coincidencia mecánica como selectores CSS, XPath y expresiones regulares, que se fijan en posiciones fijas en el árbol DOM para recuperar valores. Frente a rediseños frecuentes de páginas, adopción generalizada del renderizado dinámico y actualizaciones de múltiples capas de anti-escraping, este paradigma ha expuesto debilidades estructurales como altos costos de mantenimiento y "ciega" a contenido asíncrono. La madurez de los modelos de lenguaje a gran escala (LLMs) trae un punto de inflexión: la extracción de datos ya no pregunta "¿en qué etiqueta está ubicada la data?", sino que entiende "¿qué pregunta responde el contenido de la página?", entrando en un nuevo paradigma impulsado por el entendimiento del lenguaje natural. Este cambio no es puramente teórico; frameworks como AXE, al eliminar nodos DOM irrelevantes y combinarlos con modelos más pequeños para generar salida estructurada, superaron a modelos más grandes con una puntuación F1 del 88,1% en el conjunto de datos SWDE, validando la viabilidad y eficiencia de la extracción semántica. Este artículo, desde una perspectiva de implementación técnica, desglosará los principios técnicos y los principales intercambios clave de cada etapa según la secuencia del flujo de datos, desde la capa de adquisición de datos que maneja el anti-escraping y CAPTCHAs, hasta la capa de procesamiento de contenido limpio y extracción semántica de LLM, finalmente llegando al almacenamiento y consumo de datos estructurados.
I. Cambio de paradigma: De la parsificación basada en reglas a la procesamiento del lenguaje natural
Antes de adentrarnos en los detalles técnicos de la extracción de datos con IA, es necesario comprender por qué el antiguo paradigma que reemplaza ha alcanzado sus límites, y en qué dimensión el nuevo paradigma ha logrado un avance.
1.1 Tres dilemas de la era de la parsificación basada en reglas
El método principal de la extracción de datos web tradicional es "posicionamiento de ruta": los desarrolladores inspeccionan el nodo DOM donde se encuentra la data objetivo usando herramientas de desarrollo del navegador, y luego escriben manualmente selectores CSS o expresiones XPath para señalar ese nodo. Este paradigma ha respaldado la mayoría de las necesidades de recolección de datos web durante la última década, pero tiene tres defectos estructurales que han aumentado continuamente con la evolución de la tecnología web.
1.1.1 Anclajes frágiles: Reglas estáticas incapaces de adaptarse a un mundo dinámico
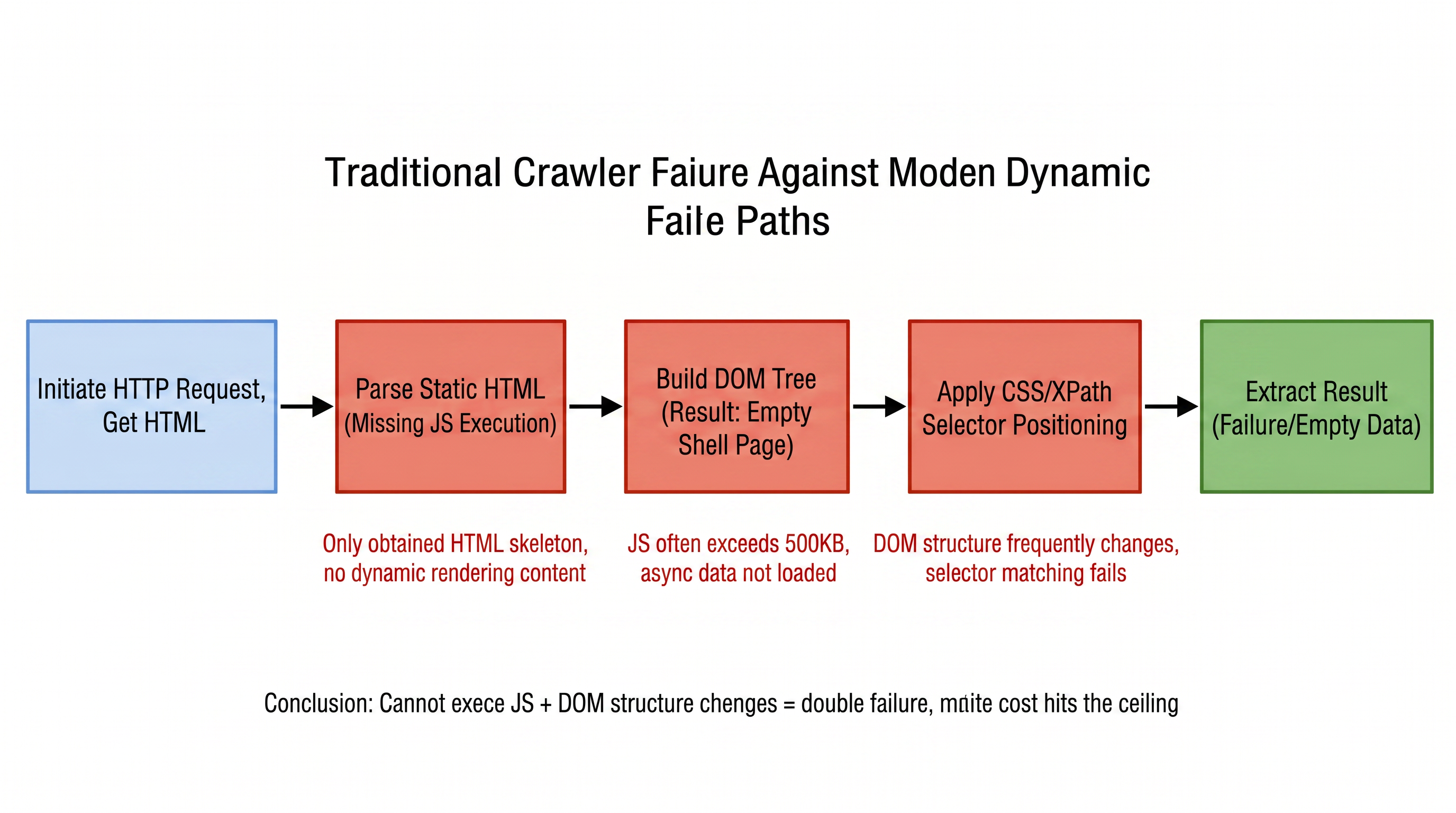
Los sitios web modernos experimentan cambios significativos en la estructura del DOM cada 3 a 6 meses en promedio. Cada rediseño significa que las reglas de los rastreadores basadas en rutas fijas se vuelven inválidas. Para equipos que mantienen cientos de nodos objetivo simultáneamente, esto constituye un ciclo continuo de "patear el molesto". La figura 1-1 ilustra el flujo completo de trabajo de los rastreadores tradicionales al enfrentar sitios web modernos, mostrando cada etapa desde la solicitud hasta la extracción de datos y los problemas encontrados:
Este proceso revela la lógica central del primer dilema: la incompatibilidad entre las capacidades de parsificación estáticas y el contenido renderizado dinámicamente. Según estadísticas de W3Techs, para finales de 2025, aproximadamente X% de los sitios web a nivel mundial utilizarán servicios de anti-escraping como Cloudflare. Basado en la detección simultánea de Netcraft del número total de sitios web, esto implica más de 290 millones de sitios, y el tamaño medio de JS en páginas web excede los 500 KB. Los rastreadores tradicionales solo pueden obtener el esqueleto no renderizado, no solo "ver datos" sino también, una vez que el sitio web se rediseñe, los selectores cuidadosamente escritos inmediatamente se vuelven inválidos. Esta "incapacidad técnica" y "fragilidad de mantenimiento" se superponen, reduciendo continuamente el alcance de la parsificación basada en reglas.
1.1.2 Ojos ciegos: La coincidencia sintáctica falla por completo en capturar la semántica
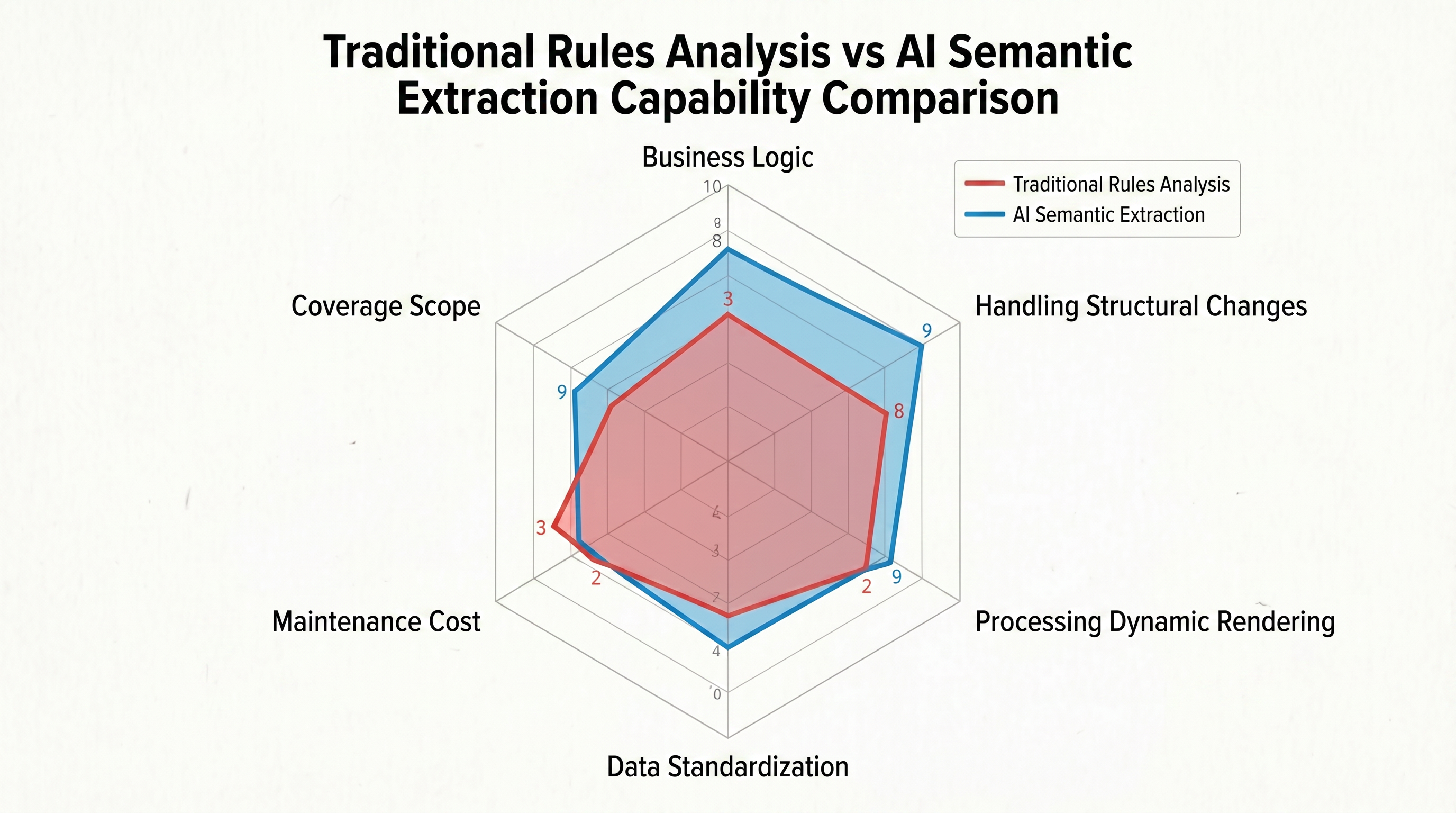
Los métodos tradicionales solo pueden responder "los datos están en esta posición", no "¿qué datos hay en esta posición?". En la misma página de lista de productos, podría haber precios promocionales, precios recomendados y precios de productos simultáneamente - tienen etiquetas idénticas en el DOM, lo que hace imposible que las reglas tradicionales las distingan. Frente a tres formatos heterogéneos de fechas como "2026-04-28", "April 28, 2026" y "28/04/2026", los analizadores tradicionales necesitan escribir expresiones regulares separadas para cada formato y no pueden hacer frente a los cambios dinámicos en el formato. La figura 1-2 utiliza un gráfico radial para comparar visualmente las diferencias entre la parsificación basada en reglas tradicional y la extracción semántica de IA en seis dimensiones clave:
La forma del gráfico radial muestra claramente que la parsificación basada en reglas tradicional depende de la posición precisa de la ruta DOM en la dimensión "lógica de trabajo", que es su única estrategia ejecutable. Sin embargo, en las otras cinco dimensiones, su rendimiento está completamente restringido: su capacidad para adaptarse a cambios estructurales es extremadamente débil, el procesamiento de renderizado dinámico depende por completo de herramientas externas, la estandarización de datos requiere escribir expresiones regulares manualmente, los costos de mantenimiento aumentan linealmente con el número de sitios y su alcance está limitado a un conjunto de reglas por sitio. Cinco de los seis ejes están severamente recesos, y el gráfico parece un polígono irregular "comprimido".
En contraste, el gráfico radial para la extracción semántica de IA se expande de manera uniforme interna y externa: se adapta automáticamente a los cambios estructurales basándose en el entendimiento semántico, procesa completamente el renderizado dinámico con el navegador, logra la estandarización sin reglas a través de las capacidades internas de conversión de formato de LLM, los costos de mantenimiento disminuyen con el aumento de las capacidades del modelo y un solo Esquema puede cubrir páginas similares en todo un sitio.
Cada uno de estos seis puntos débiles de capacidad no es un cuello de botella técnico aislado, sino una consecuencia natural de la lógica subyacente de "coincidencia mecánica" - mientras que la extracción de datos permanezca en el nivel sintáctico, sin importar cuán ingeniosamente se diseñen las reglas, esta limitación estructural no se puede superar. Por lo tanto, para resolver estos problemas de manera integral, lo que se necesita no es parchear las reglas, sino cambiar el paradigma.
1.1.3 El techo tangible: ¿Por qué este paradigma está destinado a ser reemplazado?
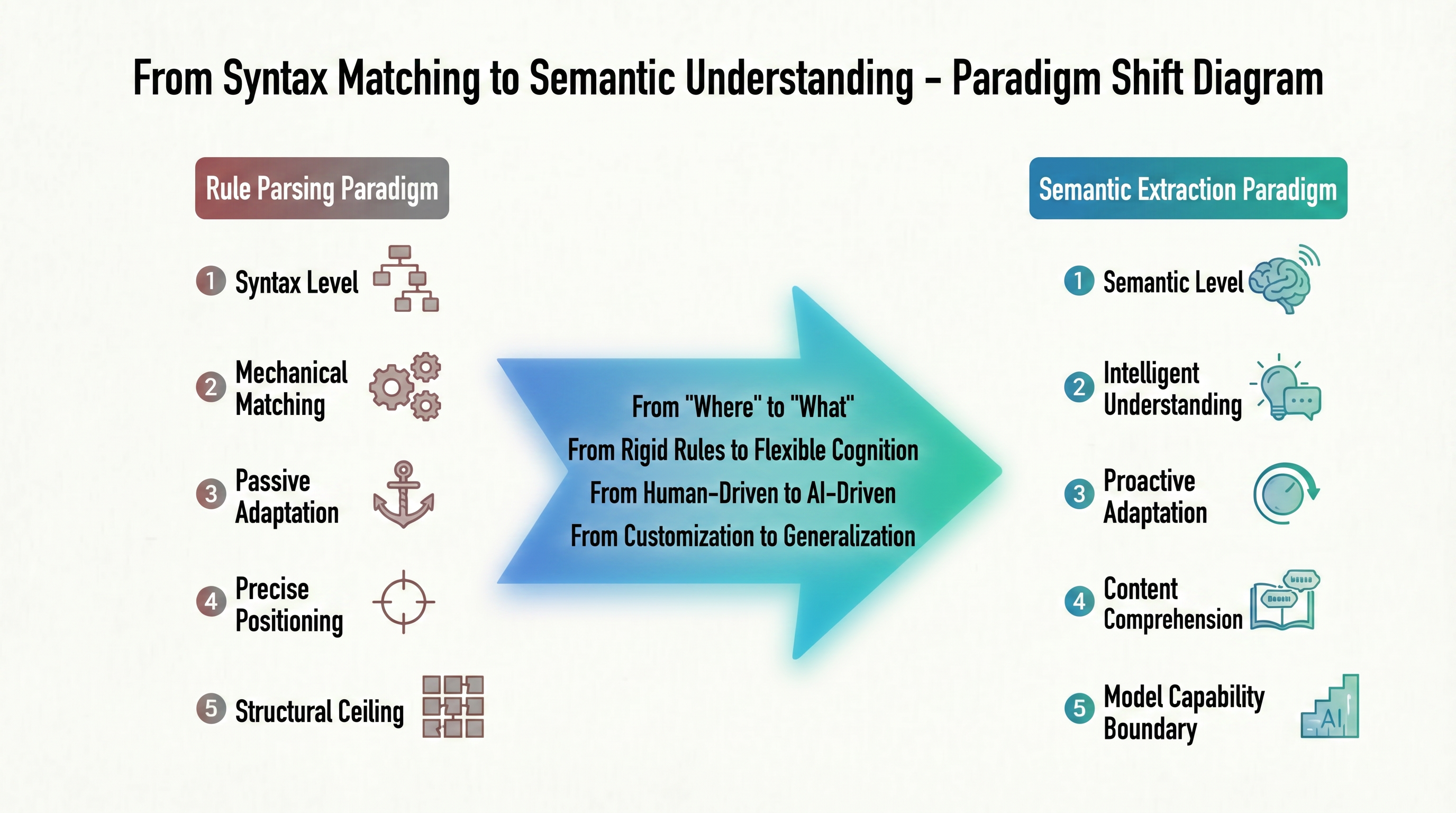
Todos los dilemas del paradigma de parsificación basado en reglas provienen de una fuente: siempre realiza "coincidencia mecánica" en el "nivel sintáctico". Esta lógica de trabajo determina su capacidad para lograr "posicionamiento preciso" - encontrar con precisión la ruta DOM de los datos - pero a costa de "adaptarse pasivamente" a cada cambio en la estructura de la página. Si el sitio se rediseña, las reglas se vuelven inválidas; si los tipos de datos son heterogéneos, se necesitan expresiones regulares nuevas escritas manualmente. Este modo de ser guiado por el sitio web objetivo constituye un "techo estructural" que la parsificación basada en reglas no puede superar. La figura 1-3 prevé la dirección fundamental del salto de este paradigma en forma de evolución comparativa.
Desde la figura anterior, es claro que no se trata de una mejora técnica en el mismo camino, sino de dos caminos fundamentalmente diferentes. El paradigma de parsificación basado en reglas en el lado izquierdo se construye en el "nivel sintáctico", apuntando al "posicionamiento preciso", adaptándose pasivamente a los cambios estructurales y rápidamente alcanzando un "techo estructural" - es como una persona que sabe que un pasaje en un libro está en la página 3, línea 5, pero no tiene idea de lo que dice el pasaje. El paradigma de extracción semántica en el lado derecho cambia fundamentalmente el nivel de trabajo: de "sintaxis" a "semántica", de "coincidencia mecánica" a "comprensión inteligente". Su objetivo ya no es localizar coordenadas de nodos, sino comprender directamente el contenido de la página, y sus límites de capacidad ya no están determinados por los cambios en el DOM.
Esto también explica por qué los tres dilemas de la era de la parsificación basada en reglas no son problemas independientes, sino manifestaciones diferentes de la lógica subyacente de "coincidencia sintáctica". Mientras que la tecnología de extracción de datos permanezca en el nivel sintáctico, sin importar cuán elaboradas sean las reglas de diseño, no se puede superar la paradoja estructural de "posicionamiento preciso" y "puntos ciegos semánticos". Por lo tanto, el surgimiento del paradigma de extracción semántica de IA no es una aceleración en el viejo camino, sino una revolución a nivel cognitivo, de "encontrar posiciones" a "entender contenido". Los mecanismos específicos y ventajas de este cambio de paradigma se explicarán en la sección 1.2.
1.2 Paradigma de IA: De coincidencia sintáctica a comprensión semántica
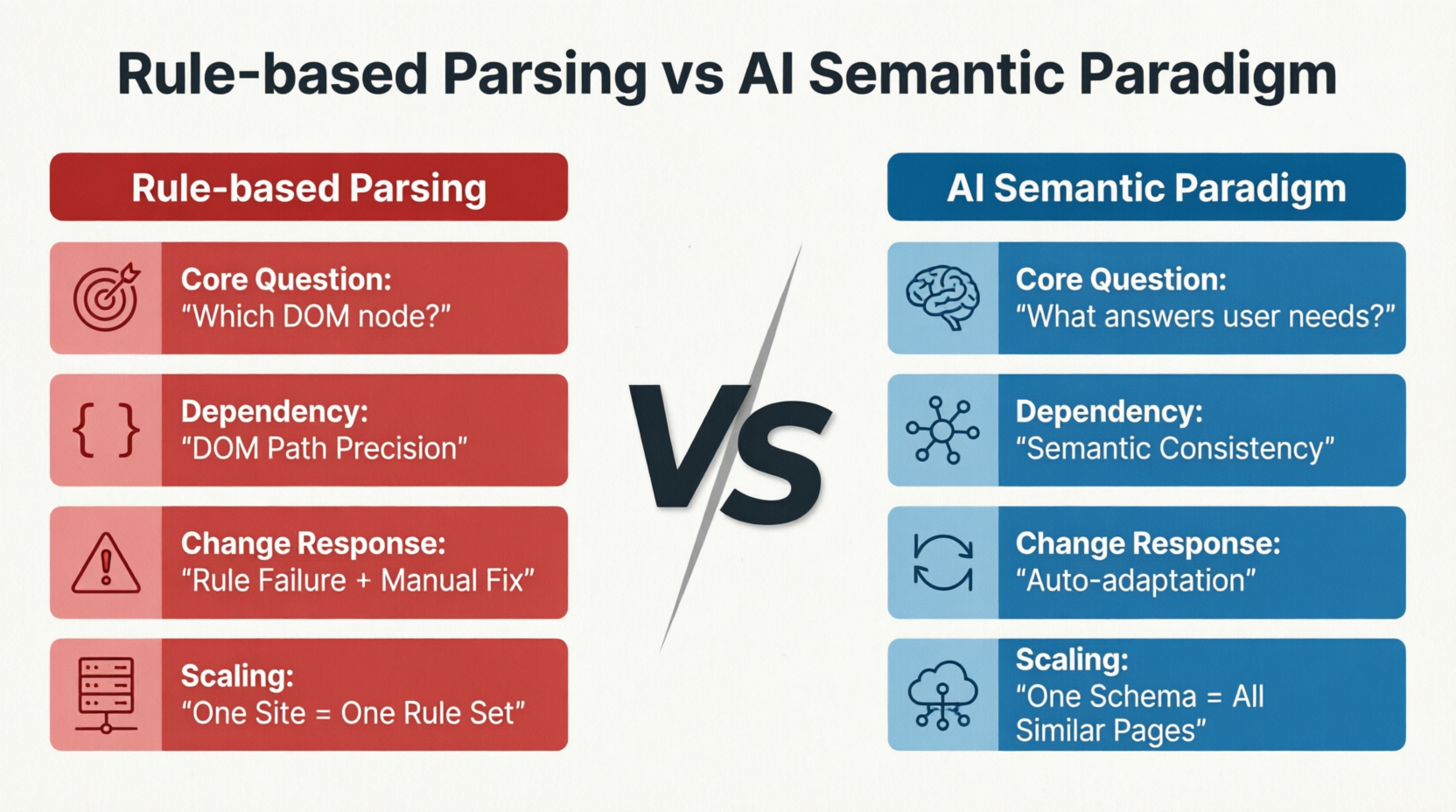
Los métodos impulsados por IA reinventan por completo cómo se abordan los problemas. La figura 1-4 compara las diferencias fundamentales entre los paradigmas de parsificación basada en reglas y el paradigma semántico de IA en cuatro dimensiones: problema central, factores dependientes, adaptación a los cambios y modo de expansión:
Los métodos tradicionales preguntan "¿dónde están los datos en el nodo DOM?", mientras que los métodos de IA preguntan "¿qué contenido en la página es la información principal de interés para el usuario?". Esta diferencia en la pregunta determina la divergencia de todos los caminos técnicos posteriores: el primero depende de la precisión de las rutas DOM, y una vez que la página se rediseñe o los nodos se muevan, las reglas se vuelven inválidas y deben repararse manualmente; el segundo depende de la consistencia del contenido semántico. Las estructuras DOM pueden cambiar y las posiciones de los datos pueden moverse, pero siempre que el contenido semántico permanezca inalterado, el modelo aún puede identificar y extraerlo correctamente. En cuanto al modo de expansión, la parsificación basada en reglas requiere reescribir un conjunto de reglas para cada nuevo sitio, mientras que el paradigma semántico de IA puede cubrir horizontalmente páginas similares en todo un sitio con el mismo Esquema.
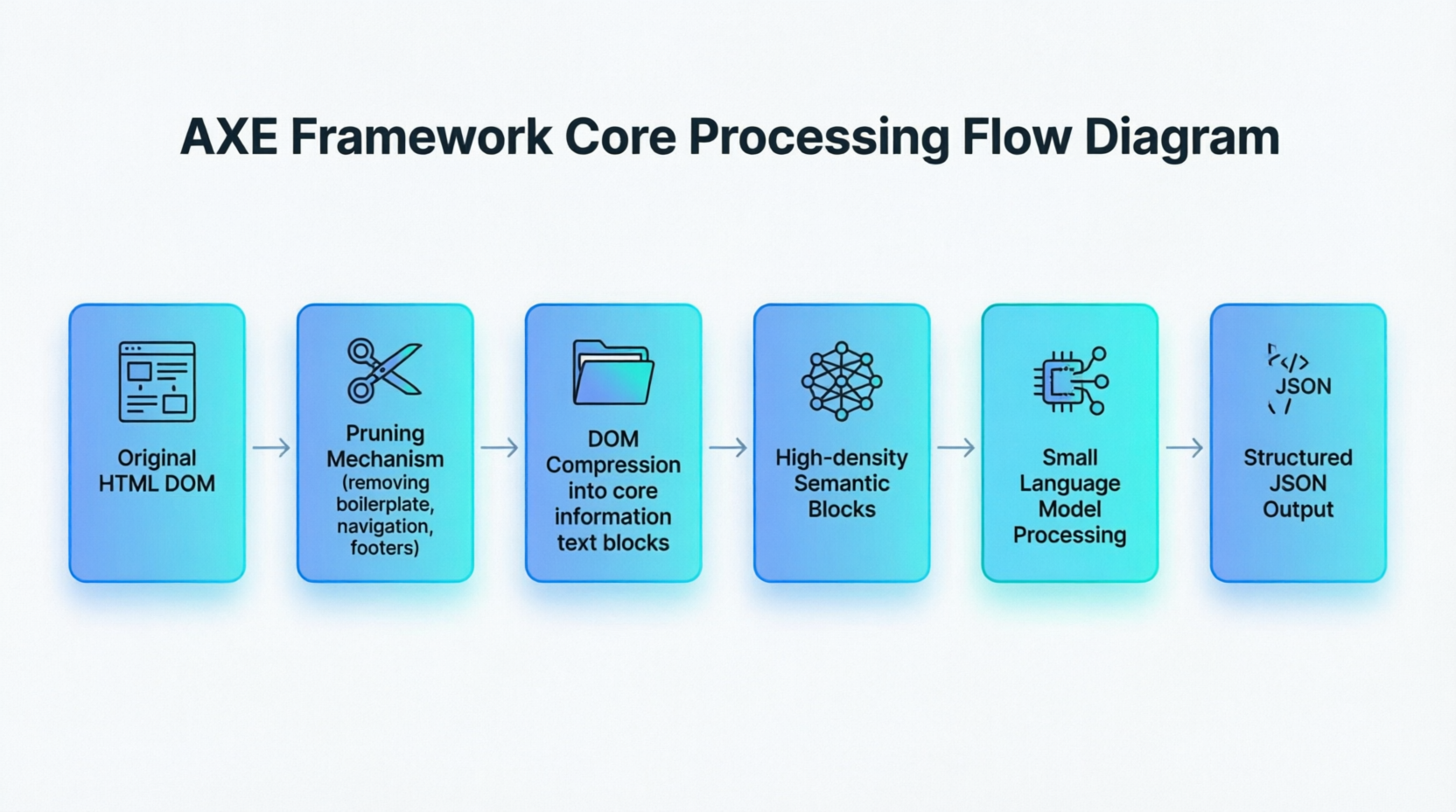
Es este cambio de "posicionamiento sintáctico preciso" a "comprensión semántica difusa" lo que da a los métodos de IA la robustez que carecen las reglas tradicionales. El framework AXE propuesto por la academia proporciona el ejemplo de ingeniería más claro de este cambio de paradigma. La figura 1-5 resume su flujo de procesamiento principal:
La figura 1-5 muestra una cadena completa desde el HTML crudo hasta la salida estructurada: AXE trata primero el HTML DOM como un árbol que necesita podar, eliminando nodos irrelevantes como barras de navegación, pies de página y código de boilerplate a través de un mecanismo especializado de poda; luego, el DOM se comprime en unos pocos bloques semánticos de alta densidad que contienen información principal; finalmente, un modelo pequeño lee estos bloques semánticos para generar una salida JSON estructurada. El proceso completo evita la localización de rutas DOM que los métodos tradicionales deben depender, actuando directamente sobre el contenido semántico de la página.
En el conjunto de datos SWDE, que abarca 8 dominios verticales y más de 80 sitios web reales, AXE logró una puntuación F1 del 88,1%, superando a múltiples modelos mucho más grandes que sí. Este resultado demuestra un hecho contraintuitivo pero crucial: la capacidad de extracción semántica no depende de modelos gigantes; un modelo pequeño cuidadosamente diseñado y entrenado específicamente también puede alcanzar una precisión de nivel de producción. Esta es la evidencia principal de que el paradigma semántico de IA es competitivo en términos de costo y viabilidad de ingeniería.
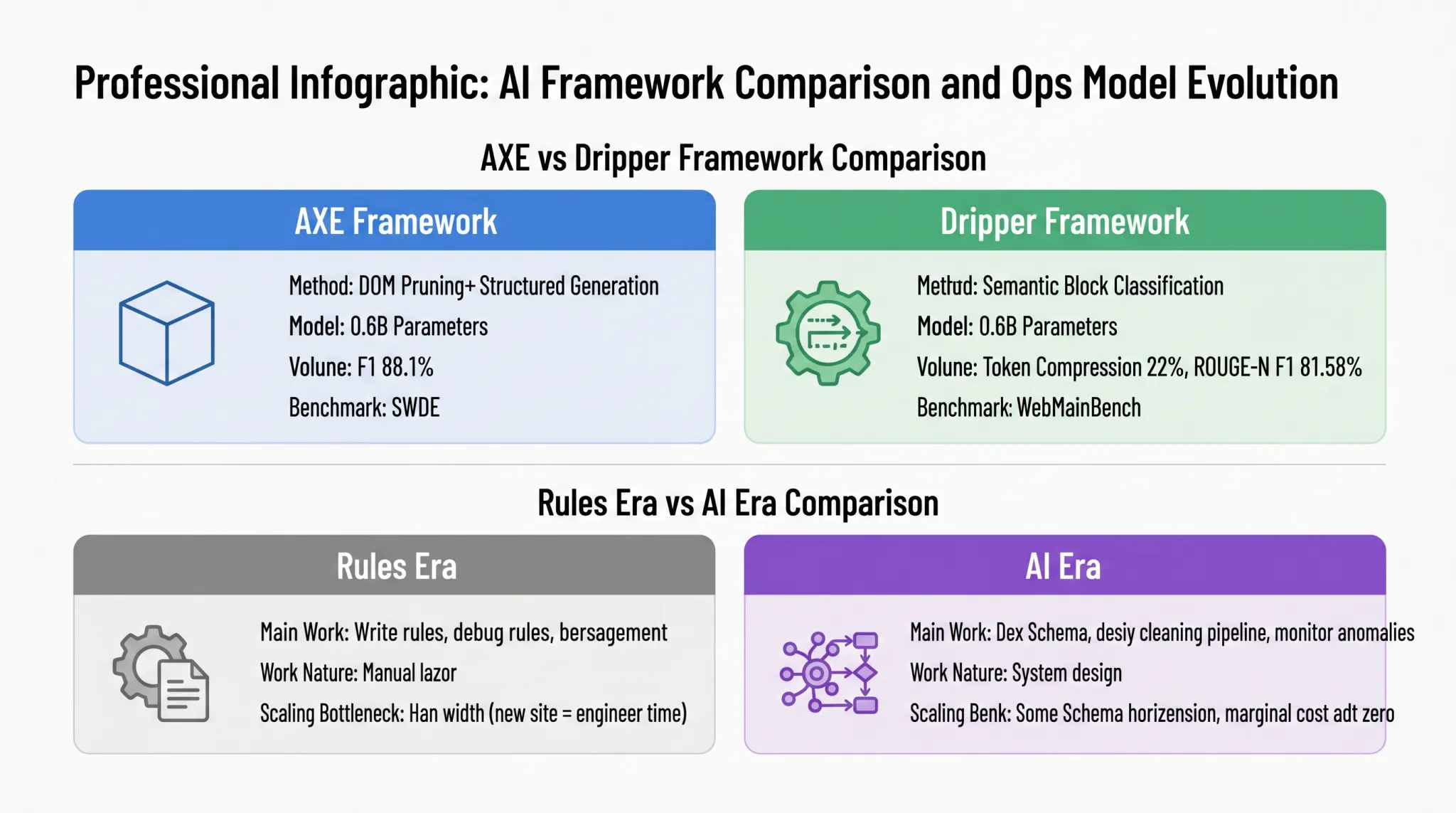
Otra obra representativa, Dripper, toma un camino técnico diferente, redefiniendo la extracción de contenido principal como una tarea de "clasificación de secuencias de bloques semánticos". La figura 1-6 utiliza una comparación de tarjetas para mostrar las diferencias en los métodos entre AXE y Dripper, así como la evolución de los modos de operación y mantenimiento entre la era de las reglas y la era de la IA:
AXE adopta el camino "podar DOM + generación estructurada", comprimiendo el DOM HTML en bloques semánticos de alta densidad y luego produciendo JSON directamente mediante un modelo pequeño; Dripper toma el camino de "clasificación binaria de bloques semánticos", transformando la extracción de contenido principal en una tarea de clasificación que determina si cada bloque semántico pertenece al texto principal. Ambos modelos tienen un tamaño similar de 0,6 mil millones de parámetros y han logrado precisión lista para producción en sus respectivas pruebas. AXE logró una puntuación F1 del 88,1% en el conjunto de datos SWDE, mientras que Dripper redujo los tokens de entrada al 22% del HTML original y logró una puntuación ROUGE-N F1 del 81,58% en WebMainBench. Estos dos caminos diferentes apuntan a la misma conclusión: la extracción de datos de IA es competitiva en precisión y no depende de modelos gigantes; un modelo pequeño cuidadosamente diseñado también puede ser competente.
La mitad derecha revela un significado más profundo del cambio de paradigma: no solo cambia la ruta técnica, sino que también reconstruye el modo diario de operación de los equipos de datos. El trabajo principal en la era de las reglas era escribir reglas, arreglar reglas y gestionar versiones, lo cual era esencialmente trabajo manual. El cuello de botella para la expansión estaba en el ancho de banda humano: cada vez que se agregaba un nuevo sitio objetivo, el tiempo de los ingenieros tenía que invertirse en reescribir y depurar reglas. En la era de la IA, el enfoque del trabajo se traslada a definir Esquemas, diseñar pipelines de limpieza y monitorear casos anómalos. La naturaleza cambia del trabajo manual al diseño del sistema, y el modo de expansión también cambia de "un conjunto de reglas por sitio" a "extensión horizontal con el mismo Esquema". Agregar sitios similares requiere casi ninguna inversión adicional de ingeniería, y el costo marginal se acerca a cero. Este cambio libera las capacidades de extracción de datos de las limitaciones del ancho de banda humano, redefiniendo la economía de la recolección de datos.
II. Proceso principal de la extracción estructurada de datos de IA
El pipeline completo de extracción de datos de IA incluye 7 etapas, que se pueden dividir en tres grupos funcionales:
Capa de Adquisición de Datos (Cola de URLs → Raspado web → Detección de anti-scraping): Responsable de "obtener" el HTML de la página objetivo en un entorno de red complejo. Esta es la zona de mayor riesgo de todo el Pipeline, con el cuello de botella principal del 14% indicado en la Figura 2-2 apuntando a esta capa.
Capa de Procesamiento de Contenido (Limpieza de Contenido → Análisis con LLM → Validación de Esquema): Responsable de transformar el HTML sin procesar ruidoso en datos estructurados de alta calidad. El cuello de botella de precisión (18%) se concentra principalmente en la etapa de limpieza de contenido de esta capa.
Capa de Almacenamiento de Datos (Almacenamiento de Datos): La salida final para el consumo posterior, representando aproximadamente el 5% de la carga total del enlace.
Este capítulo se centrará en los detalles técnicos de la Capa 2, la capa de procesamiento de contenido, demostrando cómo la extracción semántica de IA supera fundamentalmente a los motores de reglas tradicionales. Para la Capa 1, el requisito previo crítico que determina si los datos pueden fluir a la capa de procesamiento, realizaremos un análisis detallado y una discusión de soluciones prácticas en el Capítulo 3.
2.1 Pipeline de Extracción de Datos de IA
Antes de adentrarnos en la capa de procesamiento, echemos un vistazo general a todo el Pipeline a través de la Figura 2-1 para comprender el camino completo desde la cola de URLs hasta el almacenamiento de datos y la distribución real del tráfico en cada etapa. Esto sirve como una visión general de este capítulo y establece la base para abordar los cuellos de botella en el Capítulo 3.
La cola de URLs es el punto de entrada del Pipeline, gestionando la lista de URLs a raspar y controlando el ritmo de las solicitudes. Como se muestra en la Figura 2-1, aproximadamente el 32% de las solicitudes en la etapa de programación de URLs ya están marcadas previamente con riesgos de CAPTCHA, mientras que el 68% puede iniciar solicitudes normales directamente. La etapa de raspado web es responsable de iniciar solicitudes HTTP o impulsar la renderización del navegador para obtener el contenido sin procesar de la página. En este punto, el 12% de las solicitudes será interceptado directamente por CAPTCHAs, y el 80% podrá ingresar suavemente a las etapas siguientes.
Después del raspado inicial, las solicitudes entran en la etapa de detección de anti-scraping. Los sistemas modernos de anti-scraping analizan simultáneamente señales de cuatro dimensiones: reputación de IP, huella TLS, características del navegador y patrones de comportamiento, realizando una validación cruzada de múltiples capas. La Figura 2-1 muestra que aproximadamente el 10% del tráfico en la etapa de detección de anti-scraping será identificado como solicitudes automatizadas y interceptado, y el 20% requiere depender de piscinas de proxies IP y falsificación de huella TLS para evadir la detección. Este es el nodo más incierto de todo el Pipeline. Una vez que se active una CAPTCHA y no se maneje, todos los recursos computacionales de las etapas posteriores permanecerán inactivos.
Después de superar la detección de anti-scraping, se obtiene el contenido HTML sin procesar. El HTML sin procesar de una página de noticias típica puede exceder los 2 MB, alcanzando entre 300.000 y 500.000 tokens después de procesarlo con el tokenizador tiktoken de OpenAI, lleno de menús de navegación, CSS incrustado, píxeles de seguimiento codificados en Base64 y JavaScript comprimido. Por lo tanto, la limpieza de contenido es un paso esencial. La Figura 2-1 muestra que la conversión de HTML a Markdown representa el 50% del trabajo en esta etapa, y la simplificación del DOM y la eliminación de ruido representan el 30%. Estos dos juntos comprimen el HTML sin procesar en texto semántico de alta densidad, asegurando que la potencia computacional efectiva de LLM se centre en información en lugar de ruido.
El texto limpio luego entra en la etapa de análisis con LLM, donde el modelo extrae campos estructurados del texto según un Esquema predefinido. La Figura 2-1 combina esta etapa con la validación de Esquema posterior, mostrando una tasa de precisión del 94,7%. Esto significa que aproximadamente 1 de cada 20 extracciones fallará en pasar las verificaciones de completitud de campos o consistencia de formato. Las salidas exitosas se convierten en datos JSON estructurados, que finalmente se almacenan en sistemas como PostgreSQL o MongoDB para el consumo de negocios posterior.
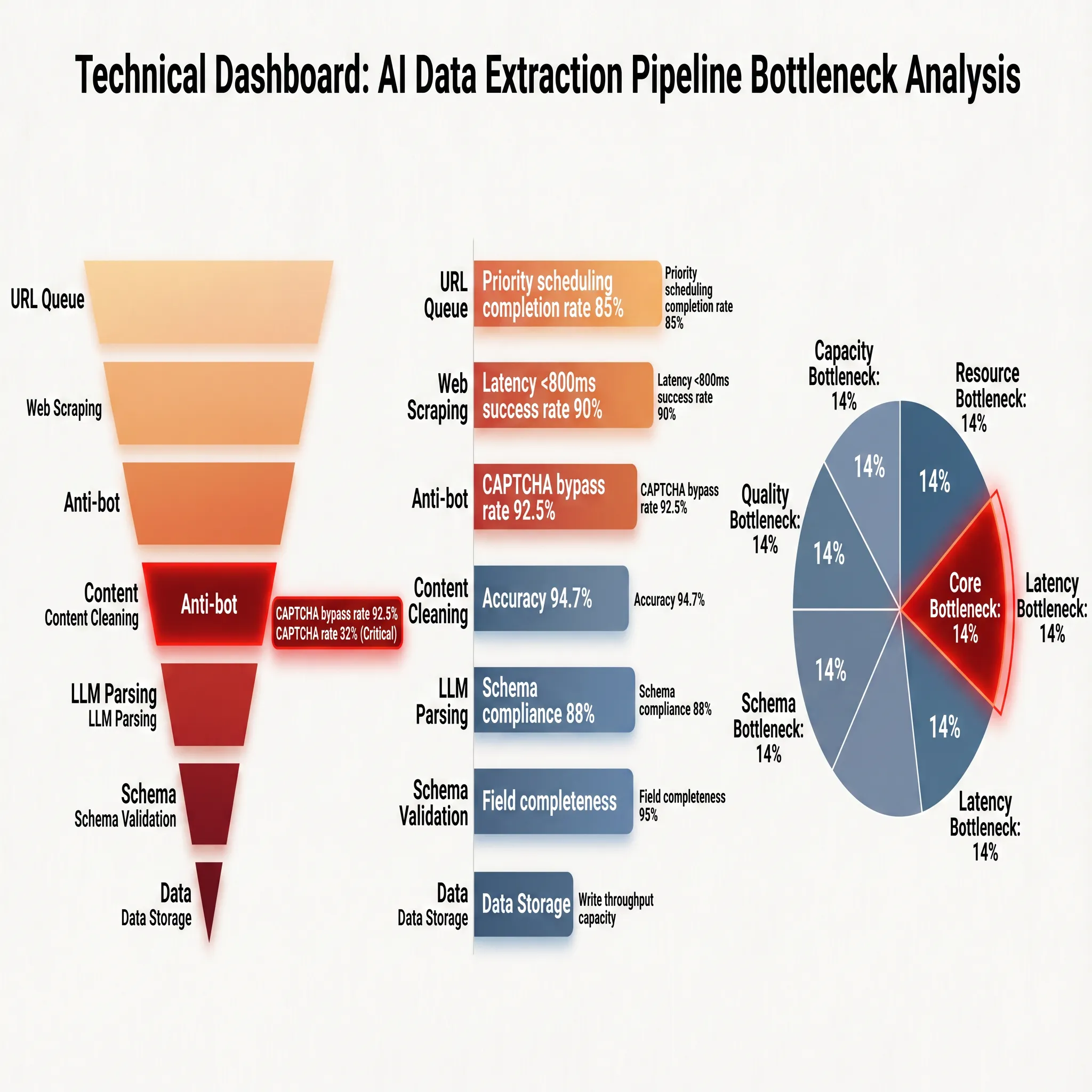
Para desglosar más claramente los portadores técnicos, indicadores de rendimiento y cuellos de botella de ingeniería de cada etapa, la Figura 2-2 presenta una visión panorámica en forma de dashboard:
Los indicadores de rendimiento en el lado derecho de la figura revelan los límites operativos reales de cada etapa: la tasa de logro de programación priorizada de la cola de URLs es del 85%, lo que significa que aproximadamente el 15% de las tareas se retrasan o degradan debido a la contención de programación; el raspado web logra una tasa de éxito del 90% bajo una restricción de latencia inferior a 800 ms, claramente mostrando los límites de recursos de red y renderizado; el mecanismo de anti-scraping tiene una tasa de precisión del 94,7%, lo que significa que aproximadamente 5 de cada 100 solicitudes son interceptadas o activan verificación; después de la limpieza de contenido, la tasa de conformidad con el Esquema es del 88% y la completitud de campos es del 95%. Estos dos indicadores definen el punto de partida de la calidad de los datos, con aproximadamente el 12% de las páginas teniendo desviaciones en la identificación del contenido principal y el 5% de campos requeridos faltantes.
La parte inferior de la Figura 2-2 indica directamente la distribución de los cuellos de botella: el cuello de botella principal apunta al mecanismo de anti-scraping (14%), el cuello de botella de precisión apunta a la limpieza de contenido (18%), los cuellos de botella de capacidad apuntan respectivamente a las etapas de programación de URLs y raspado web, y el cuello de botella de costo recae en la sobrecarga de inspección de calidad de la validación de Esquema. Estos datos se alinean altamente con el análisis anterior. La detección de anti-scraping es el "cuello" de toda la cadena; una vez que se active una estrategia de anti-scraping y no se pueda evadir eficazmente, independientemente de cuán alta sea la precisión de las etapas posteriores, todas fallarán debido a la falta de datos de entrada. Esto es consistente con el problema principal de los raspadores basados en reglas tradicionales: en la era de la extracción semántica de IA, el techo de precisión ha aumentado significativamente, pero el "requisito de entrada" para adquirir datos sigue siendo el primer obstáculo para la implementación ingenieril. Por esta razón, el Capítulo 3 discutirá específicamente la evolución de la tecnología de confrontación contra anti-scraping y las medidas de contención.
2.2 Limpieza de Contenido: De HTML Ruidoso a Texto Legible por LLM
Introducir directamente el HTML sin procesar a LLMs para la extracción estructurada es extremadamente ineficiente en ingeniería. La mecanismo de atención de LLM puede ser distraído por código de plantilla DOM, como el anidamiento profundo de etiquetas
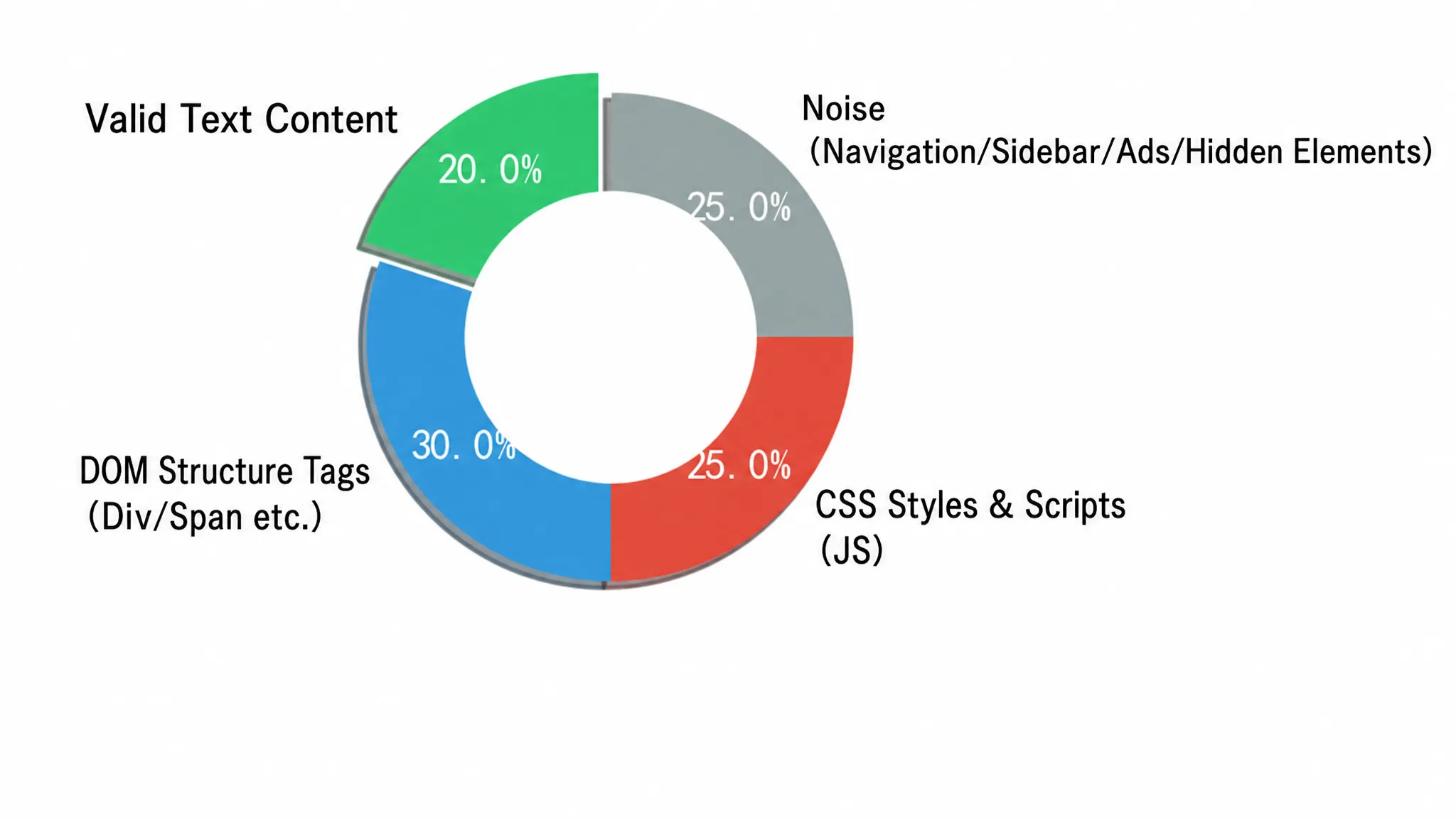
, estilos incrustados, scripts de seguimiento, menús de navegación y enlaces de pie de página. Estos elementos no proporcionan ningún valor semántico y aumentan drásticamente el consumo de tokens. En escenarios a gran escala que procesan miles de páginas al día, este desperdicio se vuelve financieramente insostenible rápidamente. La composición del HTML de una página de noticias típica ilustra intuitivamente la gravedad del problema. La Figura 2-3 presenta la proporción de información efectiva frente a diversos ruidos en el HTML sin procesar en un gráfico circular:
El gráfico circular divide el HTML sin procesar en cuatro áreas. La parte verde (45%) es contenido efectivo del cuerpo, incluyendo texto e imágenes—esta es la señal que realmente necesita LLM. La parte amarilla (20%) es ruido estructural y de estilo, es decir, etiquetas <script>, <style>, <svg>; la parte azul (20%) son navegación y barras laterales; la parte roja (15%) son anuncios y rastreadores. Las tres partes de ruido combinadas superan el 55%, lo que significa que más de la mitad de los tokens enviados a LLM son facturados sin contribuir ningún valor semántico.
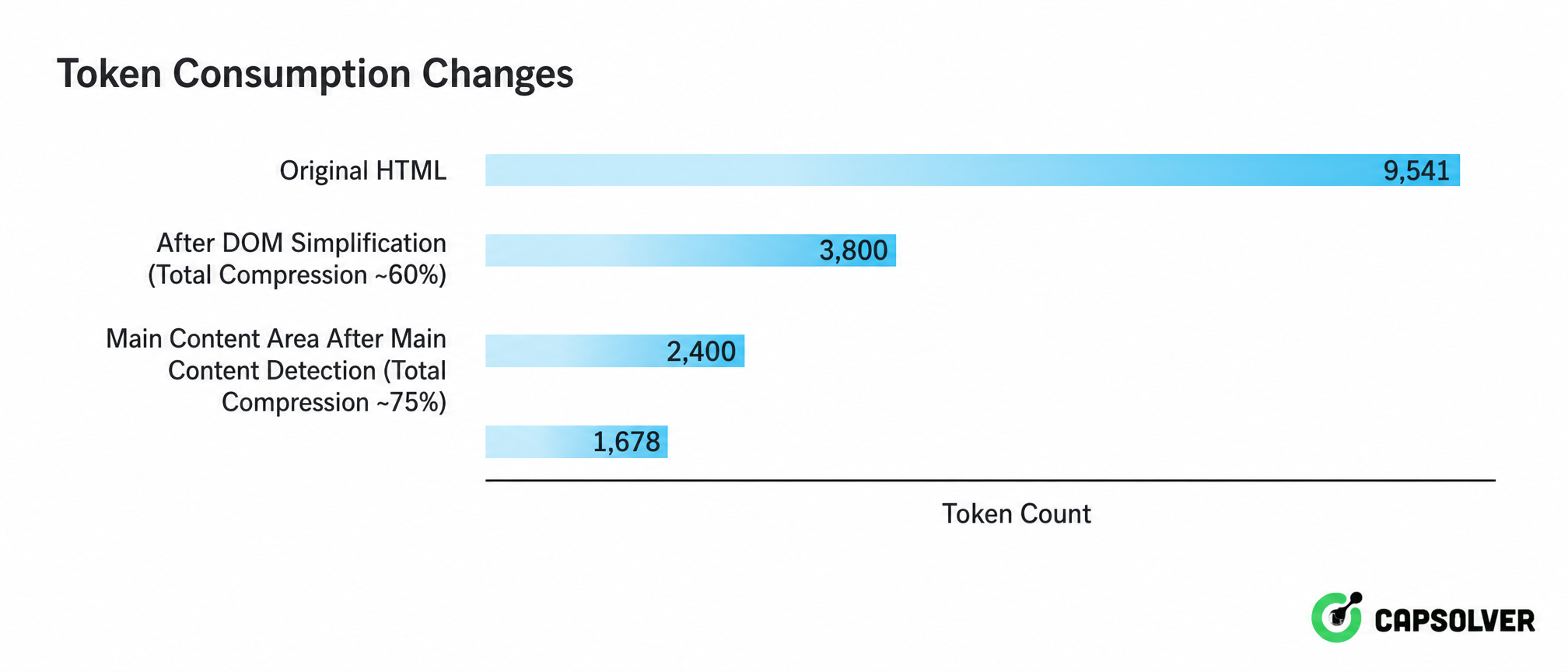
Esta realidad de "señal sumergida en ruido" ha dado lugar a una estrategia de limpieza progresiva en tres capas. La Figura 2-4 muestra la cadena completa de procesamiento desde el HTML sin procesar hasta el texto legible por LLM:
Desde la vista general, es claro a simple vista que las tres capas de limpieza comprimen los tokens de 9.541 a 1.678, solo el 18% del HTML original. Esta relación de compresión significa que en procesamiento a gran escala, los costos de llamadas a la API se pueden reducir a menos de una quinta parte, y la reducción de contexto de 10-100 veces lograda por el filtrado de contexto semántico asegura que la atención de LLM se centre en señales en lugar de ruido. Esto es una parte indispensable de la implementación ingenieril de la extracción de datos de IA.
2.3 Análisis con LLM y Validación de Esquema: De Texto a Datos Estructurados
El texto en formato Markdown, limpio mediante la limpieza de contenido, entra en la etapa de análisis con LLM, con el objetivo de generar JSON estructurado que se ajuste estrictamente a un Esquema predefinido. Dependiendo del escenario, actualmente hay tres caminos técnicos principales disponibles. El primer camino utiliza modelos grandes generales como GPT-4o, que, con una ventana de contexto de 128K, ofrece la velocidad de inferencia más rápida y la puntuación de calidad más alta, pero a un costo moderado, adecuado para la verificación rápida de prototipos con pocos campos y formatos simples. El segundo camino emplea modelos especializados por Esquema como Schematron-3B, operando en una implementación en el lado del servidor compacta, con velocidad media-alta y una puntuación de calidad solo ligeramente por debajo de los modelos grandes generales en 0,12 puntos, mientras que reduce los costos al nivel más bajo, convirtiéndolo en la opción óptima para escenarios de producción a gran escala. El tercer camino aprovecha modelos de lenguaje multimodal para construir arquitecturas híbridas, analizando simultáneamente capturas de pantalla y HTML, capaces de manejar páginas altamente dinámicas interactivas como desplazamiento infinito y ventanas emergentes, pero con velocidad media, costo más alto y puntuación de calidad relativamente más baja, convirtiéndose casi en la única ruta viable para escenarios interactivos complejos. Independientemente del camino elegido, el JSON estructurado inicialmente generado debe pasar tres capas de validación de Esquema—completitud de campos, cumplimiento de tipo y consistencia de formato—antes de salir como datos finales. La Figura 2-5 ilustra la relación completa entre estos tres caminos y la validación de Esquema desde las perspectivas de la cadena de procesamiento y métricas principales.
La matriz muestra claramente un hecho ingenieril contraintuitivo pero crucial: el modelo más grande no siempre es la solución óptima. Schematron-3B, con solo 3B de parámetros, se acerca a la puntuación de calidad de modelos grandes como GPT-4o mientras reduce significativamente los costos. Cuando el procesamiento alcanza una escala de un millón de páginas por día, su costo de inferencia es solo alrededor de 1/80 del de modelos generales grandes, lo que constituye un punto crucial de transición de "técnicamente factible" a "comercialmente rentable." Aunque Webscraper+MLLM tiene el costo más alto y una puntuación de calidad relativamente más baja, es casi la única ruta viable para escenarios altamente dinámicos interactivos, lo que confirma un principio: la corrección de la selección de tecnología depende de las restricciones del escenario, no de valores métricos absolutos.
La validación de Esquema es el último punto de control para garantizar la utilidad de los datos. Entre ellos, las verificaciones de consistencia de formato son particularmente cruciales para campos como fechas, monedas y números de teléfono. Las soluciones tradicionales con expresiones regulares requieren escribir reglas manualmente para cada variante de entrada, mientras que las capacidades internas de conversión de formato de LLM pueden lograr la estandarización con cero reglas. En términos de precisión, el marco AXE ha logrado una puntuación F1 del 88,1% en el conjunto de datos SWDE. La experiencia en entornos de producción real muestra que perseguir una precisión de extracción automática del 90% combinada con un camino de revisión rápida manual es una estrategia ingenieril más pragmática que perseguir obstinadamente una precisión teórica del 100% a un costo de decenas de veces. La posición de esta línea de compromiso depende del cálculo específico de cada equipo sobre "continuidad de datos" y "techo de presupuesto", pero es claro que una precisión moderada es más comercialmente viable.
III. Los Tres Cuellos de Botella de la Extracción de Datos de IA: Anti-Scraping, Rompimiento de CAPTCHA y Control de Costos
En el Capítulo 2, exploramos en profundidad la cadena técnica de la capa de procesamiento de contenido—desde la limpieza de HTML hasta la validación de Esquema—demostrando cómo la extracción semántica de IA eleva significativamente el techo de precisión. Sin embargo, como se revela en la Figura 2-2 de la Sección 2.1, el cuello de botella principal (14%) de todo el Pipeline no está en la capa de procesamiento, sino en la capa anterior de adquisición de datos. Si el HTML no puede obtenerse, todo el posterior análisis inteligente se construye sobre aire. Este capítulo abordará directamente esta etapa crítica que determina la "calificación de entrada."
3.1 Capa de Adquisición de Datos: El Primer Cuello de Botella Fatal del Pipeline
Si la limpieza de contenido y el análisis con LLM resuelven el problema de "cómo procesar los datos", la capa de adquisición de datos aborda una cuestión más fundamental y complicada: "¿los datos pueden obtenerse?". En el camino desde la cola de URLs al acceso normal, el sistema de anti-scraping es la variable más impredecible de todo el Pipeline.
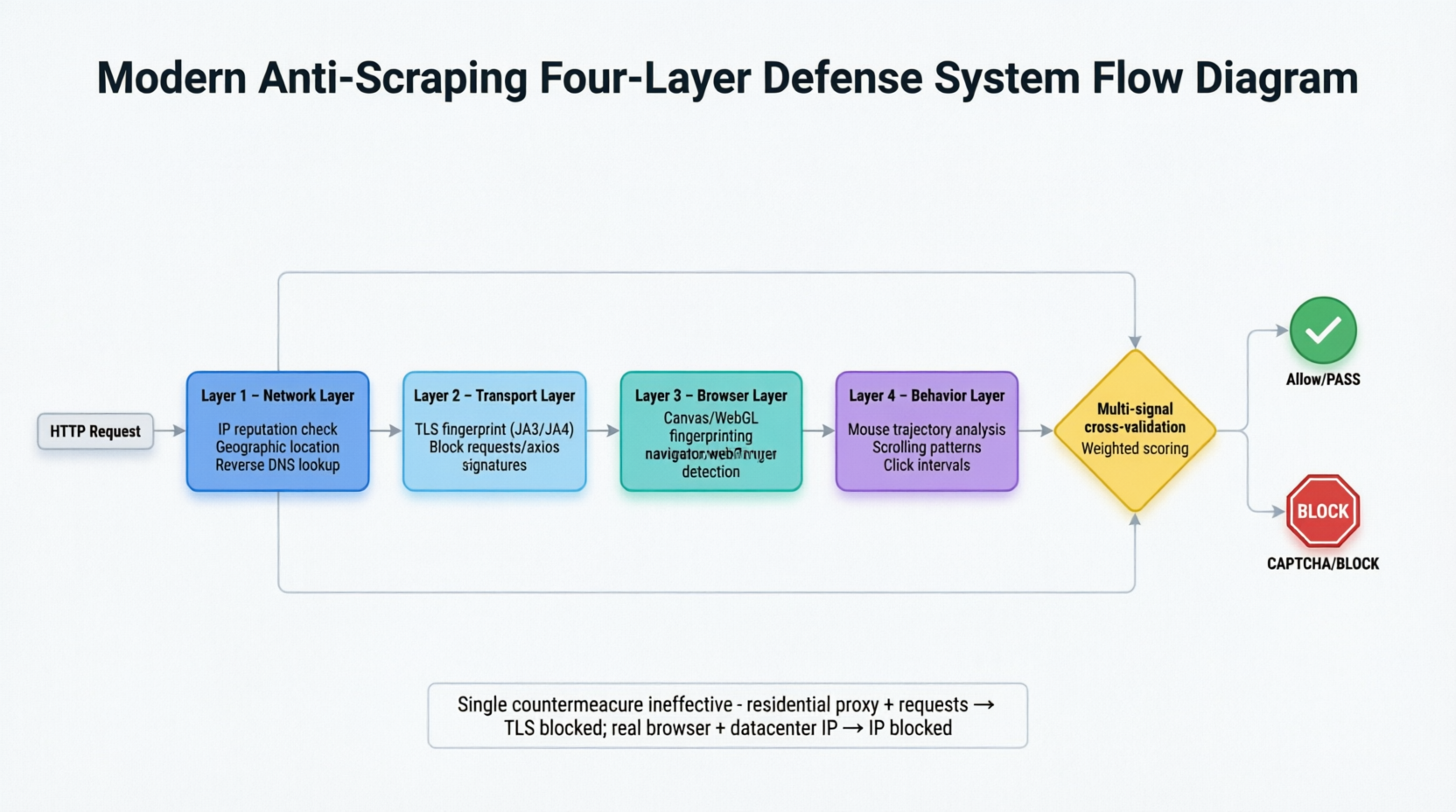
Los sistemas modernos de anti-scraping han evolucionado hacia una arquitectura de defensa en profundidad de cuatro capas, analizando cada solicitud desde las capas de red, transporte, navegador y comportamiento. La Figura 3-1 expande horizontalmente esta arquitectura de detección por capas.
Las solicitudes pasan a través de cuatro capas de filtrado secuencialmente. La capa de red comprueba señales estáticas como la ubicación de IP, si pertenece a un centro de datos y la falta de DNS inverso; la capa de transporte compara huellas TLS; la capa de navegador captura trazas de automatización como la propiedad navigator.webdriver en modo sin cabeza, huellas del lienzo y la información del renderizador WebGL; la capa de comportamiento analiza características de comportamiento humano difíciles de simular con precisión, como trayectorias del mouse, patrones de desplazamiento y intervalos de clic. Las cuatro capas de señales se validan cruzadamente para formar una puntuación ponderada, haciendo difícil que ninguna capa de disfraz pase. Cuando el sistema no puede tomar una determinación clara, se activa la última línea de defensa—CAPTCHA.
Cuando todos los métodos de detección pasiva no pueden determinar claramente la naturaleza del tráfico, el sistema muestra un CAPTCHA, que es la última línea de defensa de los sistemas de anti-scraping. Los CAPTCHAs modernos ya no son simplemente reconocimiento de caracteres distorsionados, sino sistemas de desafío inteligentes basados en puntuaciones de riesgo. La Tabla 3-1 compara los cuatro sistemas de CAPTCHA principales disponibles actualmente.
Sistema CAPTCHA
Formulario de interacción
Mecanismo de juicio
Capacidad/Características de decodificación de IA
Amenaza a los crawlers
reCAPTCHA v2
Hacer clic en la casilla de verificación / Reconocimiento de imágenes
Interacción del usuario + puntuación de comportamiento de IA
Precisión del 85% al 100%
Alta, pero rompible
reCAPTCHA v3
Completamente invisible, sin desafío visible
Puntuación continua de comportamiento en segundo plano
No se puede "romper" directamente, depende de la simulación de comportamiento
Extremadamente alta, puntuación invisible
Cloudflare Turnstile
Verificación de consistencia del entorno del navegador
Verificación no interactiva
Verifica la integridad del navegador
Alta, alternativa a reCAPTCHA
AWS WAF CAPTCHA
Desafíos basados en riesgos, configurables
Juicio del entorno integrado de AWS
Específico del entorno en la nube
Media, ecosistema específico
CAPTCHA está ubicado al final de toda la cadena de defensa. Una vez activado y no manejado, todas las etapas posteriores de limpieza de contenido y análisis de LLM se vuelven completamente ineficaces. Esta es la razón fundamental por la que la capa de adquisición de datos se llama "la primera garganta de botella fatal de la cadena": el mecanismo anti-escraping determina si los datos pueden fluir al sistema, y por sí mismo es una variable profundamente controlada por el sitio web objetivo. En una era donde la extracción semántica de IA ha mejorado significativamente la eficiencia del procesamiento de datos, la ofensiva y defensiva en el lado de adquisición permanecen el punto crítico para el éxito de la ingeniería.
3.2 Completar el rompecabezas: Caminos técnicos para el avance de CAPTCHA moderno
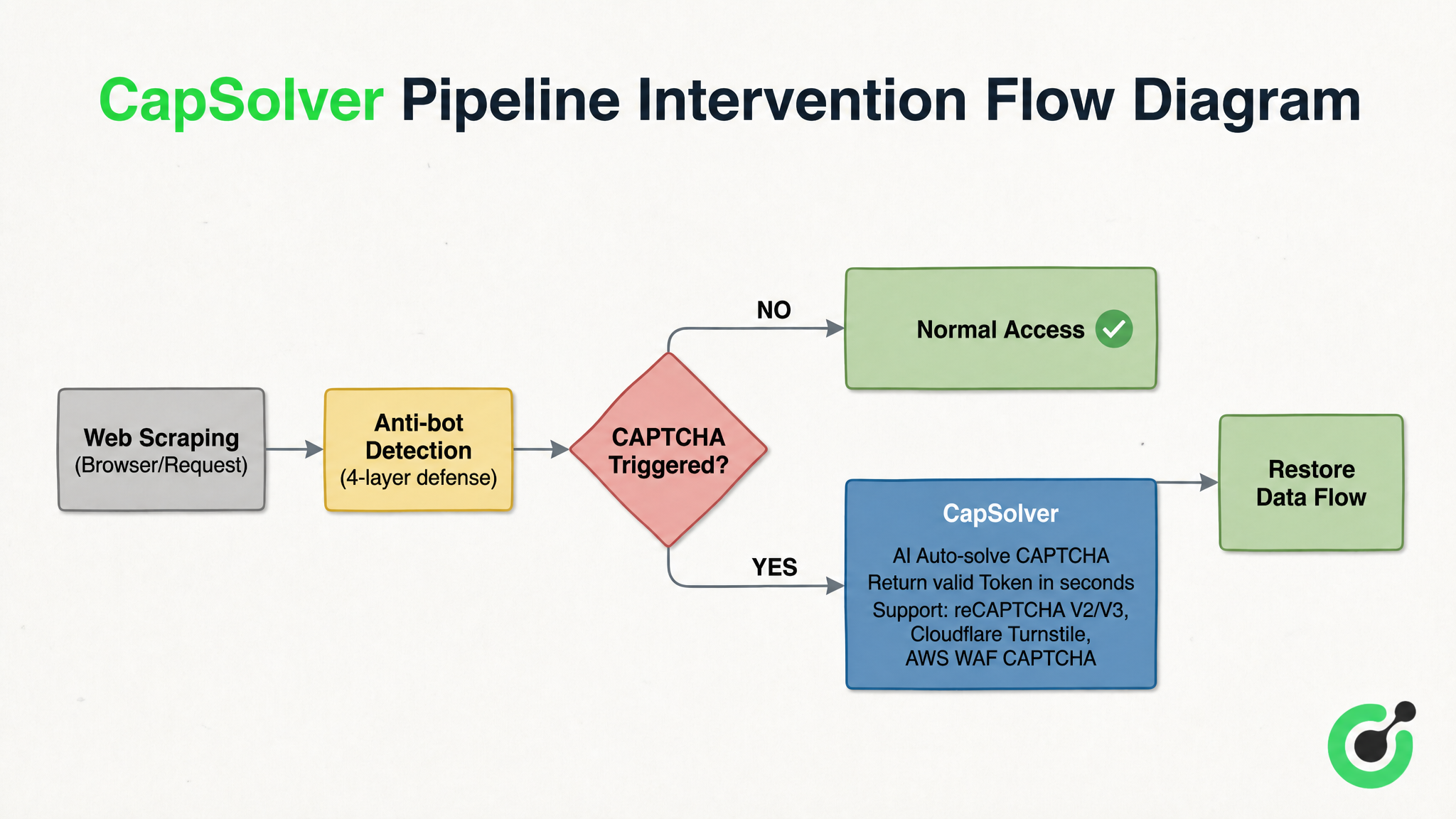
En el sistema de defensa en profundidad de cuatro capas, CAPTCHA es el obstáculo más difícil y último para resolver automáticamente. Las soluciones de reconocimiento de CAPTCHA representadas por CapSolver juegan un papel "similar a un fusible" en toda la cadena: están integradas entre "detección anti-escraping" y "acceso normal". Cuando un crawler se enfrenta a desafíos como reCAPTCHA v2/v3, Cloudflare Turnstile o AWS WAF CAPTCHA, completa el reconocimiento en segundos y devuelve un Token válido, reanudando el flujo de datos. La figura 3-2 utiliza a CapSolver como ejemplo para ilustrar la posición de intervención y la lógica de procesamiento de este tipo de solución:
Según la figura 3-2, el mecanismo de funcionamiento de este tipo de solución es claro: después de que la solicitud de raspado sea detectada por el sistema de defensa en profundidad de cuatro capas, si no se activa CAPTCHA, se libera directamente para acceso normal; una vez que se activa un desafío CAPTCHA, el servicio de reconocimiento interviene inmediatamente y envía el tipo y parámetros de CAPTCHA. La IA completa el reconocimiento en segundos y devuelve un Token válido, y el flujo de datos se reconecta en el punto de ruptura. No reemplaza ningún componente existente, sino que actúa como un fusible en un sistema eléctrico, evitando que todo el sistema se colapse en el momento en que ocurre una anomalía.
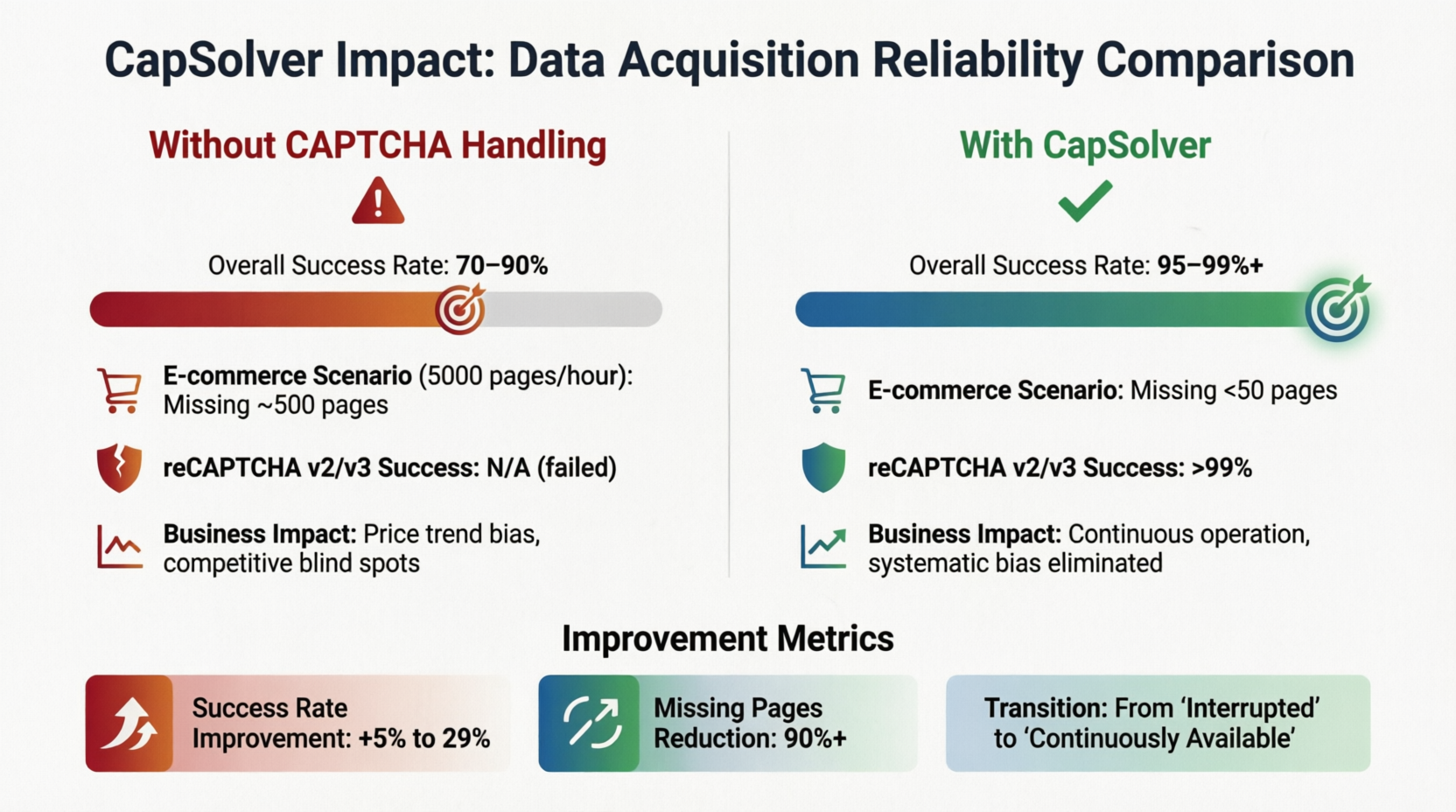
CapSolver es una de las soluciones representativas en este campo. Servicios similares como 2Captcha y Anti-Captcha también ofrecen capacidades similares, y los desarrolladores pueden elegir el proveedor más adecuado según los requisitos de latencia, los tipos soportados y los modelos de precios. Esta integración cambia directamente el modelo de confiabilidad de la capa de adquisición de datos. La figura 3-3 utiliza a CapSolver como estudio de caso para cuantificar los cambios en los indicadores clave antes y después de introducir el reconocimiento de CAPTCHA:
Sin un mecanismo de manejo de CAPTCHA, la tasa de éxito general fluctúa entre el 70% y el 90%. Tan pronto como el sitio objetivo implemente CAPTCHA, hay una probabilidad del 10% al 30% de que el flujo de datos se bloquee. En un sistema de monitoreo de precios de comercio electrónico que raspe 5.000 páginas de productos por hora, incluso con una tasa de éxito básica del 90%, aproximadamente 500 páginas de datos se perderían por hora, lo cual es suficiente para causar desviaciones direccionales en el análisis de tendencias de precios y puntos ciegos sistémicos en las estrategias de competidores. Sin embargo, después de introducir una solución de reconocimiento de CAPTCHA, la tasa de éxito salta al 95% al 99%, y las páginas perdidas disminuyen a menos de 50. La tasa de éxito del reconocimiento de reCAPTCHA v2/v3 supera el 99% cuando los parámetros están configurados correctamente. La parte inferior de la tarjeta resume los mejoramientos: la tasa de éxito aumentó en un 5% a un 29%, y las páginas perdidas se redujeron en más del 90%. "La continuidad es el valor del negocio" no es solo un lema en escenarios a gran escala, sino una práctica de ingeniería confirmada por estos números.
Las plataformas de pruebas de benchmarks de IA y los escenarios de recolección de datos para entrenamiento de LLM también enfrentan este desafío: los investigadores necesitan adquirir continuamente datos diversos, y los sitios que alojan estos datos suelen usar reCAPTCHA para prevenir el acceso automatizado, creando un paradoja donde "los equipos de investigación de IA son obstaculizados por la misma tecnología que estudian". Los servicios de reconocimiento de CAPTCHA proporcionan un método programático para manejar estos desafíos, asegurando la recolección ininterrumpida de datos y resultados completos de pruebas de benchmarks.
A nivel de integración, estas soluciones pueden trabajar en colaboración con marcos de automatización de navegadores, servicios de redes de proxies y plataformas de automatización de bajo código. Los desarrolladores solo necesitan enviar el tipo y parámetros de CAPTCHA a la API, y el sistema devuelve un Token en segundos. Plataformas como n8n proporcionan nodos dedicados, permitiendo a los profesionales de negocios configurar el reconocimiento de CAPTCHA directamente en flujos de trabajo sin escribir código. Los desarrolladores pueden enfocarse en la lógica del negocio y el diseño de esquemas, dejando la confrontación contra el scraping a herramientas profesionales.
Desde una perspectiva arquitectónica, las soluciones de reconocimiento de CAPTCHA no reemplazan ningún componente existente, sino que proporcionan una capa de "garantía de disponibilidad" para el punto de entrada de toda la cadena. Cuando el reconocimiento de CAPTCHA puede completarse automáticamente en segundos, la adquisición de datos pasa de "puntos ciegos intermitentes" a "suministro continuo de datos", lo cual es el requisito previo para la operación estable de toda la cadena de extracción estructurada de datos de IA.
3.3 Precisión y costo: El equilibrio final en la implementación de ingeniería
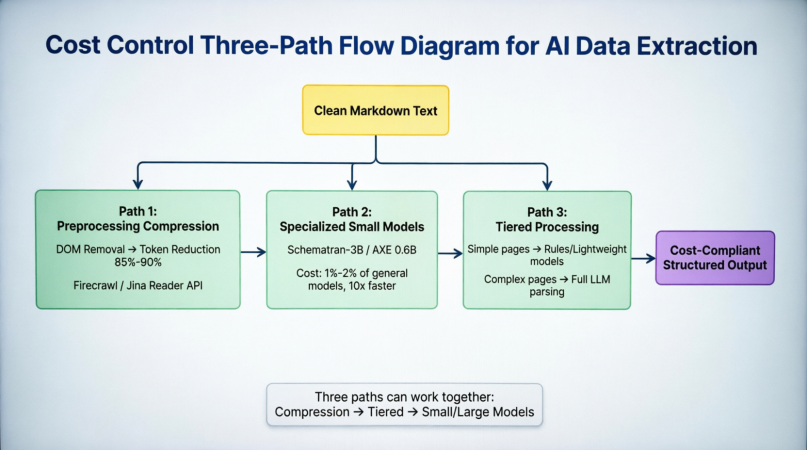
Al empujar la extracción estructurada de datos de IA a un entorno de producción, la variable decisiva final suele no ser "¿la precisión es suficiente?" sino "¿puede soportar el costo?". El consumo de tokens está en el núcleo de este problema: una página de producto moderadamente compleja, incluso después de la limpieza, puede consumir 8.000 a 15.000 tokens. Basado en los precios actuales de las API de modelos principales, el costo por extracción oscila entre $0.001 y $0.01. Esto es casi despreciable en la etapa de prototipo, pero cuando la escala de extracción aumenta a millones de páginas por día, el costo mensual alcanzará decenas de miles de dólares, en ese momento el control de costos ya no es un elemento de optimización, sino un requisito de admisión. Actualmente, hay tres caminos paralelos en la industria para reducir costos. La figura 3-4 muestra su posición y relación sinérgica en toda la cadena de análisis:
Antes de que el Markdown limpio entre en la etapa de análisis, el primer camino reduce los tokens en un 85% a un 90% mediante la eliminación del DOM y la detección del contenido principal en el frontend. Firecrawl y Jina Reader han encapsulado esto en una API, eliminando la necesidad de que los desarrolladores construyan sus propios pipelines de limpieza. El segundo camino reemplaza modelos grandes generales con modelos específicos de tareas como Schematron-3B y AXE 0.6B en la capa de modelo, manteniendo la precisión mientras comprime los costos de inferencia al 1% a 2% y acelera más de 10 veces. El tercer camino utiliza reglas o modelos ligeros para páginas con estructuras simples en la capa de programación, entregando solo páginas complejas al modelo grande completo para análisis. Esto es especialmente efectivo en escenarios como el monitoreo de categorías de comercio electrónico, donde la mayoría de las páginas dentro del mismo sitio tienen estructuras altamente consistentes, y solo unas pocas páginas anómalas requieren intervención del modelo completo. Estos tres caminos no son excluyentes, sino que pueden superponerse sinérgicamente: primero comprimir tokens, luego clasificar por complejidad y finalmente procesar con un modelo de tarea correspondiente. La figura 3-5 cuantifica aún más las tres estrategias desde principios básicos, reducción de tokens, soluciones representativas y magnitud de reducción de costos, e incluye tres verificaciones de calidad de datos:
La compresión previa reduce directamente el volumen de entrada al eliminar el ruido del DOM, logrando una reducción de tokens del 85% al 90%, lo que corresponde a un ahorro del 80% al 90% en costos. Los modelos pequeños especializados reducen el costo de inferencia individual al reducir el tamaño del modelo, con parámetros que disminuyen de decenas de miles de millones a un rango de 0.6B a 3B, ahorrando aproximadamente un 98% en costos de inferencia. El procesamiento por capas optimiza la eficiencia general al asignar recursos de cálculo de manera diferencial, con ahorros que dependen de la proporción de páginas simples. Estos tres enfoques, desde "enviar menos", "calcular menos" y "calcular inteligentemente", forman un sistema completo de reducción de costos que cubre las capas de entrada, modelo y programación.
La segunda mitad se centra en la garantía de calidad. La inspección de calidad de datos es un aspecto a menudo descuidado pero igualmente crucial del control de costos. El costo de corregir datos de baja calidad que fluyen hacia negocios secundarios suele superar con creces la inversión en realizar verificaciones en la etapa de extracción. En un entorno de producción, se deben implementar al menos tres verificaciones automatizadas: las verificaciones de tasa de relleno de campos garantizan que los campos requeridos en el esquema no estén vacíos, marcando registros anómalos para revisión manual en lugar de descartarlos directamente; las verificaciones de rango numérico validan reglas comerciales como precios que no sean negativos e inventario dentro de un rango razonable, rechazando entradas que excedan los límites; las verificaciones de consistencia de formato estandarizan campos como fechas, monedas y números de teléfono, con expresiones regulares y la capacidad interna de conversión de formatos de LLM complementándose mutuamente, procesando automáticamente lo que se puede convertir y marcando lo que no se puede para intervención manual. Estas tres verificaciones mantienen un equilibrio dinámico entre costo y calidad, desviando registros anómalos en lugar de descartarlos, asegurando la completitud mientras evitando puntos ciegos de datos.
Esta estrategia equilibrada también es aplicable a una escala más grande. En la práctica de ingeniería real, perseguir una precisión de extracción automatizada del 90% combinada con un proceso formal de revisión manual suele ser más viable comercialmente que intentar lograr una precisión teórica del 100% pero con costos de implementación decenas de veces más altos. La selección del almacenamiento de datos objetivo también depende del uso posterior: si se utiliza para consultas de API en tiempo real y visualización en el frontend, PostgreSQL o MongoDB son opciones adecuadas; si se utiliza para búsqueda de texto completo y análisis de registros, Elasticsearch es una mejor opción; si se utiliza como corpus de entrenamiento para LLM, JSON estructurado generalmente necesita ser reserializado en el formato requerido por el framework de entrenamiento y almacenado en almacenamiento de objetos. El objetivo no es perseguir una solución de almacenamiento "de un solo tamaño para todos", sino elegir el motor más adecuado según los métodos de consumo de datos y patrones de consulta. Este principio atraviesa todas las decisiones de ingeniería desde el costo de tokens hasta la selección de almacenamiento.
Redime tu código promocional de CapSolver
¡Aumenta tu presupuesto de automatización instantáneamente!
Usa el código promocional CAP26 al recargar tu cuenta de CapSolver para obtener un 5% adicional en cada recarga — sin límites.
Redímelo ahora en tu Panel de CapSolver
Conclusión
Desde HTML crudo hasta JSON estructurado, toda la cadena de extracción de datos de IA se puede resumir en cinco etapas secuenciales: adquisición, limpieza, análisis, validación y almacenamiento. Cada etapa resuelve un problema específico, y la efectividad de cada etapa depende de la finalización exitosa de la etapa anterior.
En esta cadena, la capa de adquisición de datos desempeña el papel de "punto de entrada", determinando si toda la cadena opera normalmente o está completamente inactiva. La defensa en profundidad de cuatro capas de los sistemas modernos anti-escraping y los mecanismos de CAPTCHA actualizados continuamente hacen que la adquisición de datos sea la etapa más impredecible y de mayor riesgo en toda la cadena. Cuando la limpieza de contenido puede comprimir HTML en más del 80%, los modelos pequeños especializados pueden realizar una extracción estructurada precisa en segundos, y la validación del esquema puede garantizar la conformidad de los formatos de salida, "si los datos se pueden obtener de manera estable" se convierte en el problema principal que determina el éxito del proyecto.
Este es precisamente el valor de infraestructura de CapSolver en la pila de tecnología de extracción de datos de IA. No reemplaza ninguna etapa en limpieza, análisis o validación, sino que proporciona una capa de garantía de disponibilidad continua en el punto de entrada de toda la cadena. Cuando el reconocimiento de CAPTCHA puede completarse automáticamente en segundos, con una tasa de éxito consistentemente por encima del 99%, la adquisición de datos pasa de interrupciones intermitentes a salida continua, y los recursos de cálculo e inversión de ingeniería de todas las etapas posteriores producen retornos significativos. Para empresas que dependen de un suministro estable de datos, la continuidad de la cadena en sí misma es valor de negocio, y garantizar esta continuidad es el último obstáculo que debe superar la extracción de datos de IA en su viaje desde la experimentación hasta la implementación a gran escala.