Cómo resolver CAPTCHAS en el web scraping 2026

Adélia Cruz
Neural Network Developer

TL;DR: CAPTCHA, que significa "Completely Automated Public Turing test to tell Computers and Humans Apart", es un mecanismo de seguridad implementado por los sitios web para diferenciar entre usuarios humanos y bots automatizados. Estos desafíos buscan prevenir actividades maliciosas, como el spam y el scraping de datos. Sin embargo, con los avances en tecnología y la disponibilidad de servicios para resolver CAPTCHAs, resolver CAPTCHAs en el scraping web se ha vuelto posible.
¿Qué es CAPTCHA
CAPTCHA, que significa "Completely Automated Public Turing test to tell Computers and Humans Apart", es un mecanismo de seguridad implementado por los sitios web para distinguir entre usuarios humanos y bots automatizados. Los CAPTCHAs actúan como guardianes, protegiendo a los sitios web de actividades maliciosas verificando la identidad del usuario. Estos desafíos normalmente implican presentar caracteres distorsionados, imágenes o acertijos que son fáciles de resolver para humanos pero difíciles para máquinas.
El propósito principal de los CAPTCHAs es prevenir actividades como el spam, el scraping de datos y los ataques de fuerza bruta. Al introducir pruebas que solo pueden resolver los humanos, los sitios web aseguran que la información que proporcionan sea accedida y utilizada por usuarios reales, disuadiendo a los bots automatizados. Al requerir que los usuarios completen con éxito estos desafíos, los sitios web pueden verificar que la entidad accediendo a su contenido sea un humano en lugar de un script automatizado.
Diferentes tipos de CAPTCHAs
Los desafíos de CAPTCHA hoy en día vienen en muchos diferentes formatos y variaciones, de los cuales algunos de los más comunes que encontrarás son:
-
ReCaptcha V2&v3: ReCaptcha es un sistema de CAPTCHA ampliamente utilizado desarrollado por Google. Incluye varios tipos, como seleccionar imágenes que coincidan con una descripción dada o resolver acertijos.

-
captcha: captcha se destaca entre las variantes de CAPTCHA al proporcionar a los usuarios acertijos divertidos e interactivos. En lugar de desafíos basados en texto tradicionales, captcha presenta tareas visualmente atractivas, como seleccionar objetos específicos o resolver acertijos. Este enfoque mejora la experiencia del usuario mientras mantiene un alto nivel de seguridad.
-
captcha: captcha se parece mucho a reCaptcha, con la principal diferencia siendo que captcha permite que múltiples empresas se beneficien de la etiquetado de datos realizado por los usuarios al interactuar con los sitios web. En contraste, cuando se utiliza reCaptcha, solo Google se beneficia de los esfuerzos colectivos de etiquetado de datos de crowdsourcing.
-
CAPTCHA basado en texto, los CAPTCHAs basados en texto también son una forma muy común de CAPTCHA, requiriendo al usuario identificar correctamente y escribir una serie de caracteres mostrados en una fuente distorsionada o creativa. La precisión de la respuesta se utiliza luego para decidir si se permite el acceso al sitio web o no.
-
CAPTCHA basado en sonido
Este tipo de CAPTCHA también es conocido como CAPTCHA de audio, que proporciona un clip de audio con una combinación de letras o números que el usuario tiene que separar y escribir más tarde. Este tipo de CAPTCHA generalmente viene acompañado de ruido de fondo para hacerlo más difícil de reconocer. -
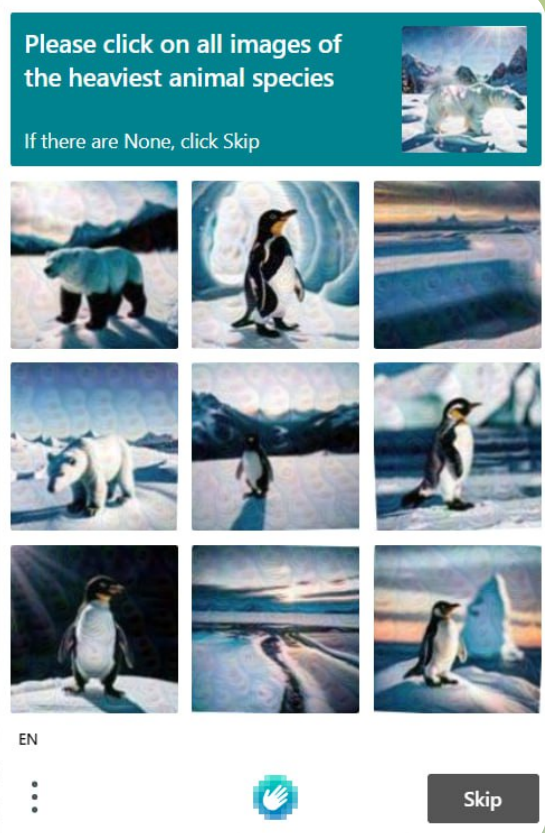
CAPTCHA basado en imágenes, en los CAPTCHAs basados en imágenes, el usuario debe reconocer y interactuar correctamente con la imagen para obtener acceso. Estos desafíos de imagen son visualmente atractivos y difíciles para los scripts automatizados, debido a las complejas capacidades de reconocimiento de imágenes que requieren, que a menudo están fuera del alcance de los scripts automatizados
¿Se puede resolver CAPTCHA en el scraping web?
Aunque los CAPTCHAs están diseñados para ser desafiantes para los bots, existen métodos y tecnologías disponibles que pueden resolverlos en el scraping web. Con el tiempo, la tecnología CAPTCHA ha evolucionado, y así también las técnicas para superarla. Con los avances en tecnología, incluida la inteligencia artificial, se han desarrollado soluciones automatizadas para abordar los desafíos CAPTCHA. Sin embargo, es importante tener en cuenta que la efectividad de estas soluciones puede variar dependiendo de la complejidad de la implementación CAPTCHA y las medidas de seguridad en vigor.
Una solución notoria en el mercado es CapSolver, que ofrece una combinación de velocidad, precisión, cobertura y asequibilidad. Como se explica con más detalle a continuación
Cómo resolver CAPTCHA en el scraping web
Al momento de resolver desafíos CAPTCHA durante el scraping web, existen varios métodos disponibles.
Aprovechar servicios de resolución de CAPTCHA
Como medida de seguridad adicional, los sitios web a menudo implementan CAPTCHAs para verificar que el usuario sea humano y no un bot automatizado. Resolver CAPTCHAs de forma programática es un aspecto crítico del scraping web avanzado en Python.
Incorporar un servicio de resolución de CAPTCHA confiable como CapSolver en tu flujo de trabajo de scraping web puede agilizar el proceso de resolver estos desafíos. CapSolver ofrece APIs y herramientas para resolver de forma programática diversos tipos de CAPTCHAs, permitiendo una integración fluida con tus scripts de Python.
Al aprovechar las capacidades avanzadas de resolución de CAPTCHA de CapSolver, puedes superar estos obstáculos y asegurar una extracción exitosa de datos, incluso desde sitios web con medidas de seguridad robustas.
Redimir tu código de bono de CapSolver
Aumenta tu presupuesto de automatización instantáneamente!
Usa el código de bono CAPN al recargar tu cuenta de CapSolver para obtener un 5% adicional en cada recarga — sin límites.
Redímelo ahora en tu Panel de CapSolver
.
Rotación de proxies premium:
La rotación de proxies puede utilizarse como un método para resolver CAPTCHAs, aunque su efectividad puede ser menor en comparación con otros enfoques mencionados anteriormente. Muchos sitios web imponen restricciones en el número de solicitudes por cada dirección IP y pueden presentar un CAPTCHA a los usuarios que excedan estos límites.
Al emplear una estrategia de rotación de proxies, tu dirección IP puede ser enmascarada, impidiendo que el servidor identifique la fuente de las solicitudes. Esto permite actividades de scraping web discretas y reduce la probabilidad de interrupciones durante la ejecución causadas por prohibiciones de IP. Sin embargo, asegúrate de usar proxies premium al manejar CAPTCHAs porque los proxies gratuitos generalmente no funcionan.
Utilizar APIs de scraping web:
Una manera eficiente de evitar CAPTCHAs es aprovechar APIs de scraping web. Estas APIs proporcionan acceso a datos ya raspados, permitiéndote extraer información sin enfrentar desafíos CAPTCHA. Al integrarte con un servicio de API de scraping web, puedes agilizar tu proceso de raspado y enfocarte únicamente en la extracción de datos.
Utilizar navegadores headless:
Los navegadores headless proporcionan una forma de automatizar interacciones con sitios web sin una interfaz de usuario visible, convirtiéndolos en herramientas efectivas para resolver CAPTCHAs. Al operar en segundo plano, los navegadores headless pueden realizar tareas automatizadas mientras evitan mecanismos de detección que dependen de interfaces de usuario, como los desafíos CAPTCHA.
Identificar trampas ocultas:
Para resolver con éxito los CAPTCHAs, es importante estar consciente de y superar trampas ocultas. Estas trampas pueden incluir campos de formulario invisibles o desafíos basados en JavaScript diseñados para detectar bots. Al entender y evadir estas trampas, los sistemas automatizados pueden navegar a través de ellas sin activar medidas de seguridad adicionales.
Emular comportamiento humano:
Para evitar la detección y parecer más como un usuario humano, es beneficioso implementar técnicas que imiten el comportamiento humano. Esto puede incluir replicar movimientos del mouse, patrones de desplazamiento y velocidad de escritura. Al simular estas acciones, los sistemas automatizados pueden hacer que sus interacciones con los sitios web parezcan más naturales, reduciendo la probabilidad de ser marcados como un bot.
Gestión de cookies:
Guardar y gestionar cookies es esencial para mantener información de sesión durante interacciones automatizadas. Las cookies almacenan datos como credenciales de inicio de sesión y tokens de sesión, que pueden usarse para resolver CAPTCHAs y acceder a contenido restringido. Al manejar adecuadamente las cookies, los sistemas automatizados pueden mantener la información necesaria para navegar por áreas protegidas por CAPTCHA de un sitio web.
Adaptación continua:
Las técnicas de CAPTCHA y medidas de seguridad están en constante evolución. Para mantenerse a la vanguardia, es crucial adaptar y actualizar continuamente los métodos de resolución de CAPTCHA. Mantenerse al día con los últimos avances y investigar activamente nuevas aproximaciones ayudará a garantizar la efectividad de los sistemas automatizados en la superación de CAPTCHAs.
Cómo resolver cualquier CAPTCHA con Capsolver usando Python:
Requisitos previos
- Un proxy funcionando
- Python instalado
- Clave de API de Capsolver
🤖 Paso 1: Instalar los paquetes necesarios
Ejecuta los siguientes comandos para instalar los paquetes requeridos:
pip install capsolver
Aquí hay un ejemplo de reCAPTCHA v2:
👨💻 Código Python para resolver reCAPTCHA v2 con tu proxy
Aquí hay un script de muestra en Python para realizar la tarea:
python
import capsolver
# Considera usar variables de entorno para información sensible
PROXY = "http://username:password@host:port"
capsolver.api_key = "Tu clave de API de Capsolver"
PAGE_URL = "URL_DE_PAGINA"
PAGE_KEY = "CLAVE_DE_SITIO_DE_RECAPTCHA"
def solve_recaptcha_v2(url,key):
solution = capsolver.solve({
"type": "ReCaptchaV2Task",
"websiteURL": url,
"websiteKey":key,
"proxy": PROXY
})
return solution
def main():
print("Resolviendo reCaptcha v2")
solution = solve_recaptcha_v2(PAGE_URL, PAGE_KEY)
print("Solución: ", solution)
if __name__ == "__main__":
main()👨💻 Código Python para resolver reCAPTCHA v2 sin proxy
Aquí hay un script de muestra en Python para realizar la tarea:
python
import capsolver
# Considera usar variables de entorno para información sensible
capsolver.api_key = "Tu clave de API de Capsolver"
PAGE_URL = "URL_DE_PAGINA"
PAGE_KEY = "CLAVE_DE_SITIO_DE_RECAPTCHA"
def solve_recaptcha_v2(url,key):
solution = capsolver.solve({
"type": "ReCaptchaV2TaskProxyless",
"websiteURL": url,
"websiteKey":key,
})
return solution
def main():
print("Resolviendo reCaptcha v2")
solution = solve_recaptcha_v2(PAGE_URL, PAGE_KEY)
print("Solución: ", solution)
if __name__ == "__main__":
main()Pensamientos finales
Los CAPTCHAs son un mecanismo de defensa crucial para los sitios web para distinguir entre humanos y bots automatizados. Aunque presentan desafíos para el scraping web, existen diversos métodos disponibles para resolver CAPTCHAs de forma efectiva. Al aprovechar servicios avanzados de resolución de CAPTCHAs, utilizar navegadores headless y simular comportamiento humano, los scrapers web pueden superar obstáculos de CAPTCHA y extraer datos valiosos de manera eficiente y efectiva. A medida que la tecnología CAPTCHA continúa evolucionando, es esencial que los scrapers web se mantengan actualizados y adapten sus métodos para garantizar una extracción exitosa de datos.
Preguntas frecuentes
1. ¿Es legal resolver CAPTCHA?
Sí, es legítimo buscar páginas públicas resolviendo CAPTCHA a un ritmo razonable sin dañar el sitio ni violar las reglas del sitio.
2. ¿Por qué es importante resolver CAPTCHAs en el scraping web?
Resolver CAPTCHAs en el scraping web es importante porque permite la automatización de la extracción de datos de sitios web sin ser obstaculizado por estos mecanismos de seguridad. Al resolver CAPTCHAs, los scrapers web pueden ahorrar tiempo y esfuerzo, permitiendo una recolección eficiente de la información deseada para diversos proyectos.
Ver más
The Other CAPTCHAApr 03, 2026
Cómo manejar los bloqueos de scraping web: Métodos prácticos que funcionan
Aprende a manejar eficazmente los bloques de scraping web. Descubre métodos prácticos, conocimientos técnicos sobre la detección de bots y soluciones confiables para la extracción de datos.

The Other CAPTCHAApr 03, 2026
Explicación del Tiempo de Respuesta de la API de Resolución de CAPTCHA: Factores de Velocidad y Rendimiento
Entender el tiempo de respuesta de la API de resolución de CAPTCHA, su impacto en la automatización y los factores clave que afectan la velocidad. Aprende a optimizar el rendimiento y aprovecha soluciones eficientes como CapSolver para la resolución rápida de CAPTCHA.

