Web Scraping con SeleniumBase y Python en 2024

Aloísio Vítor
Image Processing Expert

Introducción a SeleniumBase
SeleniumBase es un framework de Python que simplifica la automatización web y las pruebas. Amplía las capacidades de Selenium WebDriver con una API más fácil de usar, selectores avanzados, esperas automáticas y herramientas de prueba adicionales.
Configuración de SeleniumBase
Antes de comenzar, asegúrese de tener Python 3 instalado en su sistema. Siga estos pasos para configurar SeleniumBase:
-
Instala SeleniumBase:
bashpip install seleniumbase -
Verifica la instalación:
bashsbase --help
Raspador básico con SeleniumBase
Comencemos creando un script simple que navega a quotes.toscrape.com y extrae citas y autores.
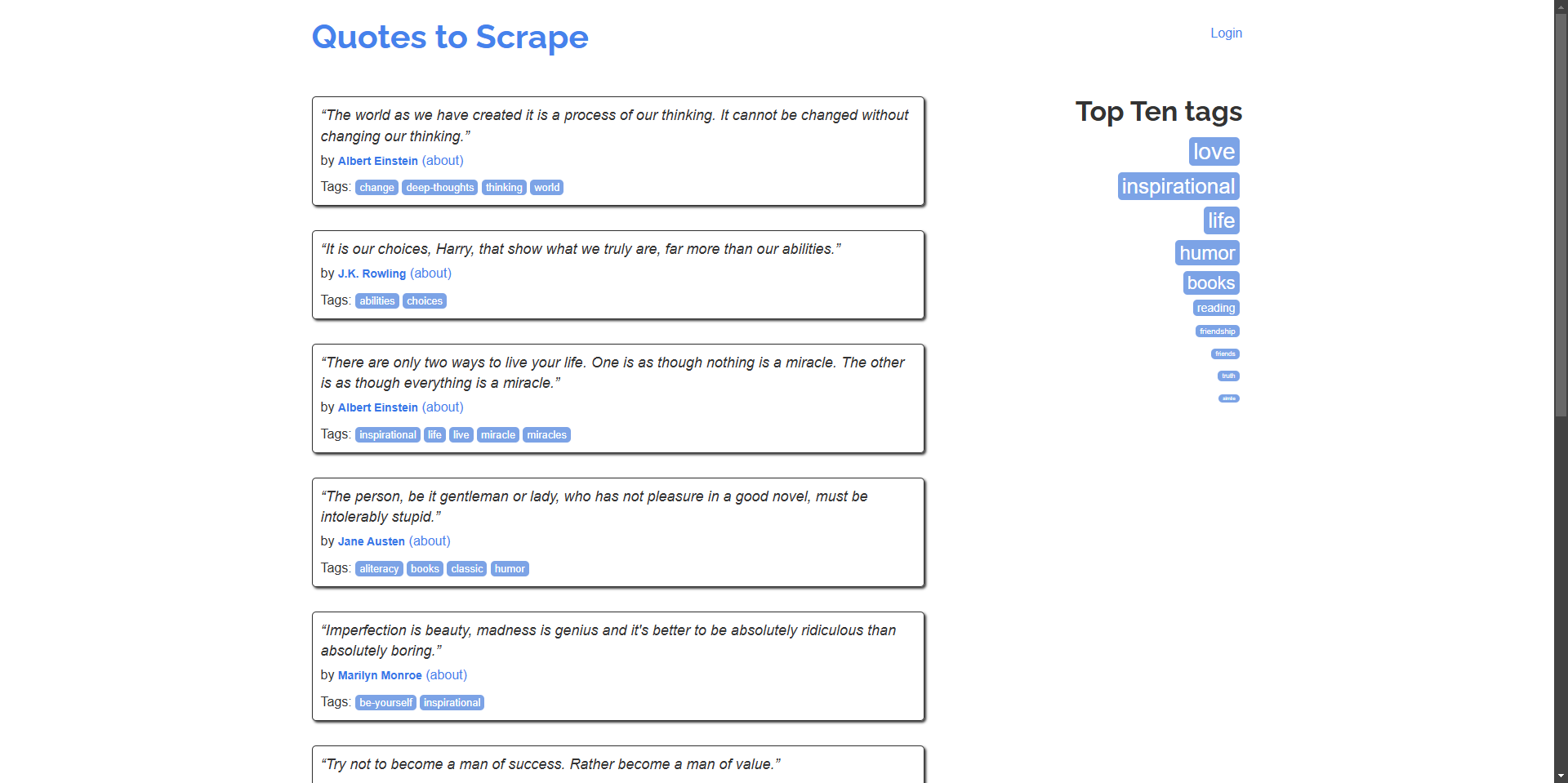
Ejemplo: Raspa las citas y sus autores de la página de inicio.
python
# scrape_quotes.py
from seleniumbase import BaseCase
class QuotesScraper(BaseCase):
def test_scrape_quotes(self):
self.open("https://quotes.toscrape.com/")
quotes = self.find_elements("div.quote")
for quote in quotes:
text = quote.find_element("span.text").text
author = quote.find_element("small.author").text
print(f"\"{text}\" - {author}")
if __name__ == "__main__":
QuotesScraper().main()Ejecuta el script:
bash
python scrape_quotes.pySalida:
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” - Albert Einstein
...Ejemplos de raspado web más avanzados
Para mejorar tus habilidades de raspado web, exploremos ejemplos más avanzados usando SeleniumBase.
Raspando múltiples páginas (Paginación)
Muchos sitios web muestran contenido en múltiples páginas. Modifiquemos nuestro script para navegar por todas las páginas y raspar citas.
python
# scrape_quotes_pagination.py
from seleniumbase import BaseCase
class QuotesPaginationScraper(BaseCase):
def test_scrape_all_quotes(self):
self.open("https://quotes.toscrape.com/")
while True:
quotes = self.find_elements("div.quote")
for quote in quotes:
text = quote.find_element("span.text").text
author = quote.find_element("small.author").text
print(f"\"{text}\" - {author}")
# Verifica si hay una página siguiente
if self.is_element_visible('li.next > a'):
self.click('li.next > a')
else:
break
if __name__ == "__main__":
QuotesPaginationScraper().main()Explicación:
- Iteramos por las páginas comprobando si el botón "Siguiente" está disponible.
- Usamos
is_element_visiblepara comprobar el botón "Siguiente". - Hacemos clic en el botón "Siguiente" para navegar a la siguiente página.
Manejando contenido dinámico con AJAX
Algunos sitios web cargan contenido dinámicamente utilizando AJAX. SeleniumBase puede manejar estos escenarios esperando a que los elementos se carguen.
Ejemplo: Raspa las etiquetas del sitio web, que se cargan dinámicamente.
python
# scrape_dynamic_content.py
from seleniumbase import BaseCase
class TagsScraper(BaseCase):
def test_scrape_tags(self):
self.open("https://quotes.toscrape.com/")
# Haz clic en el enlace 'Top Ten tags' para cargar las etiquetas dinámicamente
self.click('a[href="/tag/"]')
self.wait_for_element("div.tags-box")
tags = self.find_elements("span.tag-item > a")
for tag in tags:
tag_name = tag.text
print(f"Tag: {tag_name}")
if __name__ == "__main__":
TagsScraper().main()Explicación:
- Esperamos a que el elemento
div.tags-boxse cargue para asegurar que el contenido dinámico esté disponible. wait_for_elementasegura que el script no proceda hasta que el elemento esté disponible.
Enviado formularios e iniciando sesión
A veces, necesitas iniciar sesión en un sitio web antes de raspar contenido. Aquí te mostramos cómo puedes manejar el envío de formularios.
Ejemplo: Iniciar sesión en el sitio web y raspar citas desde la página del usuario autenticado.
python
# scrape_with_login.py
from seleniumbase import BaseCase
class LoginScraper(BaseCase):
def test_login_and_scrape(self):
self.open("https://quotes.toscrape.com/login")
# Completa el formulario de inicio de sesión
self.type("input#username", "testuser")
self.type("input#password", "testpass")
self.click("input[type='submit']")
# Verifica el inicio de sesión buscando un enlace de cierre de sesión
if self.is_element_visible('a[href="/logout"]'):
print("¡Inició sesión correctamente!")
# Ahora raspa las citas
self.open("https://quotes.toscrape.com/")
quotes = self.find_elements("div.quote")
for quote in quotes:
text = quote.find_element("span.text").text
author = quote.find_element("small.author").text
print(f"\"{text}\" - {author}")
else:
print("Error de inicio de sesión.")
if __name__ == "__main__":
LoginScraper().main()Explicación:
- Navegamos a la página de inicio de sesión y rellenamos las credenciales.
- Después de enviar el formulario, verificamos el inicio de sesión comprobando la presencia de un enlace de cierre de sesión.
- Luego, procedemos a raspar el contenido disponible para los usuarios que han iniciado sesión.
Nota: Dado que quotes.toscrape.com permite cualquier nombre de usuario y contraseña para demostración, podemos usar credenciales ficticias.
Extrayendo datos de tablas
Los sitios web a menudo presentan datos en tablas. Aquí te mostramos cómo extraer datos de tablas.
Ejemplo: Raspa datos de una tabla (ejemplo hipotético ya que el sitio web no tiene tablas).
python
# scrape_table.py
from seleniumbase import BaseCase
class TableScraper(BaseCase):
def test_scrape_table(self):
self.open("https://www.example.com/table-page")
# Espera a que la tabla se cargue
self.wait_for_element("table#data-table")
rows = self.find_elements("table#data-table > tbody > tr")
for row in rows:
cells = row.find_elements("td")
row_data = [cell.text for cell in cells]
print(row_data)
if __name__ == "__main__":
TableScraper().main()Explicación:
- Localizamos la tabla por su ID o clase.
- Iteramos por cada fila y luego por cada celda para extraer datos.
- Dado que
quotes.toscrape.comno tiene tablas, reemplaza la URL con un sitio web real que contenga una tabla.
Integrando CapSolver en SeleniumBase
Mientras que quotes.toscrape.com no tiene CAPTCHAs, muchos sitios web del mundo real sí. Para prepararte para estos casos, demostraremos cómo integrar CapSolver en nuestro script de SeleniumBase usando la extensión de navegador CapSolver.
Cómo resolver captchas con SeleniumBase usando Capsolver
-
Descarga la extensión de CapSolver:
- Visita la página de lanzamientos de GitHub de CapSolver.
- Descarga la última versión de la extensión de navegador CapSolver.
- Descomprime la extensión en un directorio en la raíz de tu proyecto, por ejemplo,
./capsolver_extension.
Configurando la extensión de CapSolver
-
Localiza el archivo de configuración:
- Busca el archivo
config.jsonubicado en el directoriocapsolver_extension/assets.
- Busca el archivo
-
Actualiza la configuración:
- Establece
enabledForcaptchay/oenabledForRecaptchaV2entruedependiendo de los tipos de CAPTCHA que quieras resolver. - Establece el
captchaModeo elreCaptchaV2Modeen"token"para la resolución automática.
Ejemplo de
config.json:json{ "apiKey": "YOUR_CAPSOLVER_API_KEY", "enabledForcaptcha": true, "captchaMode": "token", "enabledForRecaptchaV2": true, "reCaptchaV2Mode": "token", "solveInvisibleRecaptcha": true, "verbose": false }- Reemplaza
"YOUR_CAPSOLVER_API_KEY"con tu clave de API real de CapSolver.
- Establece
Cargando la extensión de CapSolver en SeleniumBase
Para usar la extensión de CapSolver en SeleniumBase, necesitamos configurar el navegador para que cargue la extensión cuando se inicie.
-
Modifica tu script de SeleniumBase:
- Importa
ChromeOptionsdeselenium.webdriver.chrome.options. - Configura las opciones para cargar la extensión de CapSolver.
Ejemplo:
pythonfrom seleniumbase import BaseCase from selenium.webdriver.chrome.options import Options as ChromeOptions import os class QuotesScraper(BaseCase): def setUp(self): super().setUp() # Ruta a la extensión de CapSolver extension_path = os.path.abspath('capsolver_extension') # Configura las opciones de Chrome options = ChromeOptions() options.add_argument(f"--load-extension={extension_path}") options.add_argument("--disable-gpu") options.add_argument("--no-sandbox") # Actualiza el controlador con las nuevas opciones self.driver.quit() self.driver = self.get_new_driver(browser_name="chrome", options=options) - Importa
-
Asegúrate de que la ruta de la extensión sea correcta:
- Asegúrate de que
extension_pathapunte al directorio donde descomprimiste la extensión de CapSolver.
- Asegúrate de que
Ejemplo de script con integración de CapSolver
Aquí tienes un script completo que integra CapSolver en SeleniumBase para resolver CAPTCHAs automáticamente. Seguiremos usando https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php como nuestro sitio de ejemplo.
python
# scrape_quotes_with_capsolver.py
from seleniumbase import BaseCase
from selenium.webdriver.chrome.options import Options as ChromeOptions
import os
class QuotesScraper(BaseCase):
def setUp(self):
super().setUp()
# Ruta a la carpeta de la extensión de CapSolver
# Asegúrate de que esta ruta apunte correctamente a la carpeta de la extensión de Chrome de CapSolver
extension_path = os.path.abspath('capsolver_extension')
# Configura las opciones de Chrome
options = ChromeOptions()
options.add_argument(f"--load-extension={extension_path}")
options.add_argument("--disable-gpu")
options.add_argument("--no-sandbox")
# Actualiza el controlador con las nuevas opciones
self.driver.quit() # Cierra cualquier instancia de controlador existente
self.driver = self.get_new_driver(browser_name="chrome", options=options)
def test_scrape_quotes(self):
# Navega al sitio de destino con reCAPTCHA
self.open("https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php")
# Comprueba la presencia de CAPTCHA y resuelve si es necesario
if self.is_element_visible("iframe[src*='recaptcha']"):
# La extensión de CapSolver debería manejar el CAPTCHA automáticamente
print("CAPTCHA detectado, esperando a que la extensión de CapSolver lo resuelva...")
# Espera a que se resuelva el CAPTCHA
self.sleep(10) # Ajusta el tiempo en función del tiempo medio de resolución
# Procede con las acciones de raspado después de que se resuelva el CAPTCHA
# Ejemplo de acción: hacer clic en un botón o extraer texto
self.assert_text("reCAPTCHA demo", "h1") # Confirma el contenido de la página
def tearDown(self):
# Limpia y cierra el navegador después de la prueba
self.driver.quit()
super().tearDown()
if __name__ == "__main__":
QuotesScraper().main()Explicación:
-
Método setUp:
- Anulamos el método
setUppara configurar el navegador Chrome con la extensión de CapSolver antes de cada prueba. - Especificamos la ruta a la extensión de CapSolver y la añadimos a las opciones de Chrome.
- Cerramos el controlador existente y creamos uno nuevo con las opciones actualizadas.
- Anulamos el método
-
Método test_scrape_quotes:
- Navegamos al sitio web de destino.
- La extensión de CapSolver detectaría y resolvería automáticamente cualquier CAPTCHA.
- Realizamos las tareas de raspado como de costumbre.
-
Método tearDown:
- Nos aseguramos de que el navegador se cierre después de la prueba para liberar recursos.
Ejecutando el script:
bash
python scrape_quotes_with_capsolver.pyNota: Aunque quotes.toscrape.com no tiene CAPTCHAs, la integración de CapSolver prepara tu raspador para sitios que sí los tienen.
Código extra
Reclama tu Código extra para las mejores soluciones de captcha en CapSolver: scrape. Después de canjearlo, obtendrás un bono extra del 5% después de cada recarga, sin límite de veces.

Conclusión
En esta guía, hemos explorado cómo realizar el raspado web usando SeleniumBase, cubriendo las técnicas básicas de raspado y ejemplos más avanzados como el manejo de la paginación, el contenido dinámico y el envío de formularios. También hemos demostrado cómo integrar CapSolver en tus scripts de SeleniumBase para resolver CAPTCHAs automáticamente, asegurando sesiones de raspado ininterrumpidas.
Ver más
AIJun 18, 2026
Elegir un Solucionador de CAPTCHA para tu Infraestructura de Agentes
Un marco de decisión para elegir un solucionador de CAPTCHA para la infraestructura de agente, enfocado en el mapeo de desafíos, la vinculación de sesión, la observabilidad, los controles de tasa y el uso responsable.
AIJun 18, 2026
Mejor API de CAPTCHA para Agentes de IA en 2026
Una guía práctica de evaluación para elegir una API de CAPTCHA para agentes de IA en 2026, centrada en la cobertura de tareas documentada, los contratos de sondeo, la validación de tokens y los controles operativos.