Web Scraping Security: Best Practices to Protect Data & Avoid Detection

Nikolai Smirnov
Software Development Lead

TL;Dr:
- Legal & Ethical Compliance: Adhere to
robots.txtand terms of service for ethical data collection. - Mimic Human Behavior: Implement delays, rotate user agents, and manage cookies to avoid bot detection.
- Utilize Proxies: Employ diverse proxy types (residential, datacenter) to distribute requests and mask your IP.
- Handle CAPTCHAs: Integrate automated CAPTCHA solving services for uninterrupted data collection.
- Monitor & Adapt: Continuously monitor scraping performance and website changes to maintain effectiveness.
Introduction
Web scraping, a powerful data extraction technique, presents significant security challenges and detection risks. This guide outlines best practices for web scraping security, helping data professionals protect their data and navigate anti-bot systems. Understanding detection mechanisms and implementing robust strategies ensures efficient, ethical, and uninterrupted data collection. We clarify concepts, establish foundational knowledge, and offer practical solutions to enhance your web scraping operations. For a deeper dive into the fundamentals, explore what is web scraping.
Understanding Web Scraping Security: What, Why, and How
Secure and effective web scraping requires understanding how websites protect their information. Web scraping security involves methods and practices to prevent scrapers from detection, blocking, or legal issues. The goal is to collect data while respecting website policies and avoiding anti-bot triggers. This balances efficiency with stealth, making scraping activities appear as legitimate user interactions.
The Essence of Web Scraping Detection
Websites use various techniques to identify and deter automated scraping. Detection mechanisms analyze patterns deviating from typical human behavior. High request rates from a single IP or missing browser-specific headers can quickly flag a scraper. Understanding these triggers is crucial for resilient scraping strategies. Anti-bot technologies constantly evolve, requiring continuous adaptation of web scraping security practices.
How Anti-Bot Systems Work
Anti-bot systems analyze numerous data points from incoming requests, building a visitor profile and looking for anomalies. Key indicators include IP reputation, browser fingerprinting, request headers, and behavioral patterns. Significant deviations from a human profile can trigger responses from CAPTCHA challenges to IP blocking. Effective web scraping security aims to blend with legitimate traffic, making differentiation difficult for these systems.
Structured Knowledge: Definitions, Classifications, and Scenarios
Building a solid foundation in web scraping security requires categorizing components and understanding their roles. This structured approach helps identify appropriate countermeasures for different scraping challenges.
Key Concepts in Web Scraping Security
- IP Rotation: Changing IP addresses for requests to avoid rate limits and IP bans, making requests appear from multiple distinct users. This technique is fundamental for distributing request load and preventing a single IP from being flagged.
- User-Agent Management: Setting appropriate
User-Agentheaders to mimic popular web browsers, as anti-bot systems check this for legitimacy. Regularly rotating User-Agents can further enhance stealth. - Request Throttling: Introducing delays between requests to simulate human browsing patterns and prevent server overload. Randomizing these delays makes the scraping activity appear more natural.
- Browser Fingerprinting: Collecting unique browser characteristics (e.g., plugins, fonts, screen resolution) to identify and track users. Advanced anti-bot systems use this to detect headless browsers. Scrapers must aim to present consistent and common browser fingerprints. Because of this, many scrapers combine proxies with antidetect browsers to create separate browser fingerprints and improve browsing consistency across multiple sessions.
- CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart): A challenge-response test to verify human users. Various types exist with different recognition logic, posing a significant barrier to automated systems.
Classification of Anti-Bot Measures
Websites deploy layered defenses against scrapers:
- Rate Limiting: Restricting requests from a single IP within a timeframe. Exceeding limits often results in temporary or permanent blocks.
- IP Blacklisting: Blocking known malicious IP addresses or ranges based on historical data or threat intelligence. This is why diverse proxy usage is critical.
- CAPTCHA Challenges: Presenting visual or interactive puzzles to verify human interaction (e.g., reCAPTCHA, Cloudflare Turnstile). These are designed to be difficult for bots to solve automatically.
- User-Agent and Header Checks: Validating
User-Agentstrings and other HTTP headers to resemble legitimate browsers. Inconsistent or outdated headers can quickly flag a bot. - Honeypots: Invisible links or elements designed to trap automated bots. Following these flags the scraper as non-human, leading to immediate blocking.
- JavaScript Challenges: Requiring JavaScript execution to render content or solve computational puzzles, deterring simple HTTP scrapers that do not execute JavaScript.
- Browser Fingerprinting: Analyzing subtle browser characteristics to identify automated tools. This includes checking for inconsistencies in browser properties that might indicate a headless browser.
Usage Scenarios for Secure Scraping
Secure web scraping is vital for various applications, including market research, content aggregation, and competitive intelligence. For instance, an e-commerce business scraping competitor pricing needs a low profile to avoid blocks and gather accurate, real-time data. Academic researchers collecting public data must ensure compliant methods to avoid legal and ethical issues. Web scraping security principles apply universally, regardless of data collection goals, emphasizing the need for robust strategies to ensure data integrity and operational continuity.
Technical Background: CAPTCHA Types, Recognition Logic, and Risk Control
CAPTCHAs are a significant hurdle, designed to differentiate human users from bots. Understanding their technical basis is key to overcoming them. CAPTCHA technology constantly evolves to counter automated solving.
Common CAPTCHA Types and Their Logic
- reCAPTCHA (Google): Evolved from simple text recognition (v1) to sophisticated behavioral analysis and risk scores (v2 "I'm not a robot" checkbox, invisible reCAPTCHA) and invisible background analysis (v3). The logic for v2 and v3 heavily relies on user interaction patterns, browser fingerprinting, and IP reputation. Clean browsing history, typical mouse movements, and consistent user behavior reduce the likelihood of being challenged.
- Cloudflare Turnstile: A privacy-focused reCAPTCHA alternative, often using image-based challenges or passive verification. Its logic focuses on accuracy and consistency of user selections or behavioral signals without requiring explicit user interaction in many cases.
- Image-based CAPTCHAs: These require identifying objects, characters, or patterns within a set of images. The recognition logic uses visual pattern matching, which is challenging for bots without advanced computer vision capabilities.
- Audio CAPTCHAs: These present distorted audio clips of numbers or letters for transcription. Bots typically struggle with the distortion, background noise, and varying accents, making them effective against simple automated solvers.
Recognition Logic and Risk Control
Anti-bot systems, including those that deploy CAPTCHAs, use sophisticated risk control mechanisms. They analyze numerous factors in real-time to assess the likelihood of a request originating from a bot:
- Behavioral Analysis: This involves scrutinizing mouse movements, keyboard inputs, scroll patterns, and time spent on a page. Inconsistent or overly precise actions, or actions that are too fast or too slow, can flag a bot.
- Network Characteristics: Factors such as IP reputation, origin country, and the use of known VPNs or proxies are evaluated. IPs associated with malicious activities or data centers are often flagged more readily.
- Browser Environment: Discrepancies in
User-Agentstrings, missing plugins, unusual JavaScript execution environments, or inconsistencies in reported screen resolutions can indicate a headless browser or an automated script. - Request Frequency and Volume: Abnormally high requests from a single source within a short period, far exceeding typical human browsing patterns, are a strong indicator of automated activity.
Accumulated risk factors escalate responses, leading to more stringent CAPTCHA challenges, rate limiting, or outright IP blocking. Web scraping security strategies aim to minimize these factors, making scrapers appear as legitimate human users.
Simple Process Flow for Secure Web Scraping
A high-level understanding of the secure web scraping process is beneficial for implementing effective countermeasures.
-
Initial Setup & Configuration:
- Choose a reliable proxy provider: Select a service offering diverse IP types (residential, mobile) and rotation. This is fundamental for web scraping security, as it helps distribute requests and mask your true IP address.
- Configure
User-Agentrotation: Maintain up-to-dateUser-Agentstrings and rotate them per request or session. This mimics diverse user environments and avoids detection based on a static User-Agent. - Implement request delays: Introduce random delays between requests (e.g., 2-10 seconds) to mimic human browsing speed. Avoid predictable, fixed delays that can be easily detected.
-
Pre-Scraping Checks:
- Review
robots.txt: Always check the target website'srobots.txtfile (https://example.com/robots.txt) for scraping policies. Respecting these guidelines is crucial for ethical and legal compliance. Ignoringrobots.txtcan lead to legal issues and IP bans. This is a foundational aspect of responsible web scraping security. - Analyze website structure: Understand HTML structure and identify potential honeypots (e.g.,
display: noneorvisibility: hiddenelements) to avoid interacting with them. Interacting with honeypots is a clear sign of automated activity.
- Review
-
Execution & Monitoring:
- Scrape data: Execute your script, adhering to configured delays and proxy rotation.
- Monitor for blocks: Continuously monitor request success rates and HTTP status codes. If blocks occur (e.g., HTTP 403, 429, or CAPTCHA pages), analyze the response to identify the cause. For strategies on how to bypass IP ban, refer to our detailed guide.
- Adapt and refine: Adjust scraping parameters (e.g., increase delays, change proxy types, update
User-Agentstrings) based on real-time monitoring and feedback from website responses.
-
Post-Scraping & Data Handling:
- Data validation: Verify extracted data for accuracy, completeness, and consistency. Implement checks to ensure the data is clean and usable.
- Storage and security: Store collected data securely, adhering to relevant data protection regulations like GDPR and CCPA. Ensure data is encrypted and access is restricted to authorized personnel.
Solutions for Enhanced Web Scraping Security
As anti-bot technologies advance, so must secure web scraping strategies. These solutions address common challenges and provide pathways to resilient data collection.
Mimicking Human Behavior
Making your scraper behave like a human user is highly effective against detection:
- Randomized Delays: Use random intervals (e.g., 5-15 seconds) between requests for a more natural appearance, enhancing web scraping security. This avoids predictable patterns that bots often exhibit.
- Realistic Click Patterns: For headless browsers, simulate natural mouse movements and clicks with varied coordinates and timing. Avoid direct clicks on elements without prior mouse movement.
- Cookie Management: Persist and manage cookies across sessions to maintain state and reduce suspicion. Websites often use cookies to track user sessions and identify returning visitors.
- Referer Headers: Set appropriate
Refererheaders to appear from a legitimate source (e.g., a search engine or a previous page on the same site), adding to request legitimacy and web scraping security.
Advanced Proxy Strategies
Proxies are crucial for web scraping security. A mix of proxy types improves success by distributing requests and masking your IP address:
- Residential Proxies: These IPs are assigned by Internet Service Providers (ISPs) to residential users. They are highly effective as they appear as legitimate user traffic, making them difficult for anti-bot systems to distinguish from real users. Residential proxies are crucial for robust web scraping security, especially for highly protected targets.
- Mobile Proxies: IPs from mobile carriers are even harder to detect due to their dynamic nature and association with real mobile devices. They offer higher anonymity and are excellent for targets with stringent anti-bot measures.
- Datacenter Proxies: These are faster and cheaper but more easily detected as they originate from commercial data centers. They are suitable for less protected websites or initial testing phases where anonymity is not the primary concern.
Comparison Summary: Proxy Types for Web Scraping Security
| Feature | Datacenter Proxies | Residential Proxies | Mobile Proxies |
|---|---|---|---|
| Anonymity Level | Low to Medium | High | Very High |
| Detection Risk | High | Low | Very Low |
| Speed | High | Medium | Medium |
| Cost | Low | Medium to High | High |
| Use Case | Less protected sites | Moderately protected sites | Highly protected sites |
| IP Source | Commercial data centers | ISPs | Mobile carriers |
Overcoming CAPTCHA Challenges with CapSolver
CAPTCHAs are a primary defense against automated scraping. Manual intervention is impractical for large-scale operations, making automated CAPTCHA solving services indispensable for web scraping security.
CapSolver offers a robust solution for various CAPTCHA types, including reCAPTCHA, Cloudflare Turnstile, and image-based challenges. Integrating CapSolver automates CAPTCHA solving, ensuring uninterrupted data collection. CapSolver's advanced AI-powered infrastructure recognizes and solves complex CAPTCHAs, allowing your scraper to proceed as if a human user completed the challenge. This is valuable when traditional human behavior mimicry is insufficient. For example, for reCAPTCHA v3, CapSolver provides a token to bypass verification based on sophisticated risk assessment, significantly enhancing web scraping security and efficiency.
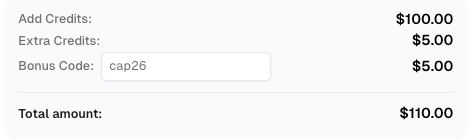
Use code
CAP26when signing up at CapSolver to receive bonus credits!
CapSolver's services integrate seamlessly into existing scraping frameworks, providing solutions for:
- reCAPTCHA v2/v3: Solving both checkbox and invisible reCAPTCHA challenges by generating valid tokens.
- Cloudflare Turnstile: Accurately solving Cloudflare Turnstile puzzles, which are designed to be privacy-preserving and effective against bots.
- ImageToText CAPTCHAs: Transcribing distorted text from images using advanced Optical Character Recognition (OCR) technology.
Leveraging such services improves web scraping operations' resilience against sophisticated anti-bot measures. For integration details, refer to official documentation, such as How to Choose CAPTCHA Solving API? 2026 Buyer's Guide & Comparison.
Legal and Ethical Considerations
Understanding the legal and ethical landscape is paramount for long-term web scraping security. Ignoring these aspects can lead to severe consequences. According to a report by Zyte, web scraping itself is not inherently illegal, but its legality depends heavily on the data being scraped and the methods used. Always prioritize ethical considerations to maintain a positive reputation and avoid legal entanglements.
Respecting robots.txt and Terms of Service
robots.txt: This file directs web crawlers on which parts of a website to avoid. Always adhere to these rules. It's a strong ethical guideline, and ignoring it can violate website policy and compromise web scraping security. Respectingrobots.txtis a fundamental aspect of responsible scraping.- Terms of Service (ToS): Websites often prohibit automated data collection in their ToS. Violating these terms can lead to account termination, IP bans, and legal disputes. Always review the ToS before initiating any scraping activity to ensure compliance.
Data Privacy and Compliance
When scraping personal data, compliance with regulations like GDPR (General Data Protection Regulation) and CCPA (California Consumer Privacy Act) is critical. Ensure collected data is handled responsibly, anonymized if necessary, and used only for legitimate purposes. Non-compliance can result in significant fines and legal repercussions. Prioritizing data privacy is a key component of web scraping security. For instance, the International Association of Privacy Professionals (IAPP) highlights how EU data protection laws significantly limit the legal use of web scraping, especially concerning personal data. Additionally, understanding compliance with both GDPR and CCPA is essential for web scrapers operating globally, as these regulations impose strict requirements on data collection and processing.
Conclusion
Effective web scraping security is a continuous process of adaptation. By understanding anti-bot systems, mimicking human behavior, employing advanced proxy strategies, and leveraging automated CAPTCHA solving services like CapSolver, you enhance data collection resilience. Always prioritize legal and ethical compliance, respecting robots.txt, ToS, and data privacy. Staying informed about anti-bot techniques and monitoring performance ensures robust, undetected operations. This proactive approach to web scraping security allows valuable insights while maintaining a responsible and sustainable data acquisition strategy.
FAQ
Q1: Is web scraping legal?
Web scraping legality is complex, depending on the data being scraped, website Terms of Service (ToS), and data protection laws (e.g., GDPR, CCPA). Generally, scraping publicly available data is often permissible, but copyrighted or personal data without explicit consent can be illegal. It is always advisable to consult legal counsel if you are unsure about the legality of your specific scraping activities.
Q2: How can I avoid getting my IP blocked during web scraping?
To avoid IP blocks, implement a strategy that includes IP rotation with diverse proxies (residential, mobile), introduce random delays between requests to simulate human browsing patterns, and mimic human browser behavior with appropriate User-Agent and Referer headers. Continuously monitoring your scraping logs for unusual activity or error codes (like 403 or 429) is crucial for proactive adjustment and maintaining web scraping security.
Q3: What is browser fingerprinting, and how does it affect web scraping?
Browser fingerprinting collects unique browser characteristics such as installed fonts, plugins, screen resolution, operating system, and language settings to create a unique identifier for a user. Anti-bot systems use this to detect headless browsers or automated scripts that exhibit inconsistent or non-human browser fingerprints. Advanced scrapers must use tools and techniques to simulate realistic and consistent browser fingerprints to avoid detection.
Q4: How do CAPTCHA solving services like CapSolver work?
CapSolver uses advanced Artificial Intelligence (AI) and machine learning algorithms to automatically recognize and solve various CAPTCHA types. When your scraper encounters a CAPTCHA challenge, it sends the challenge to CapSolver's API. CapSolver then processes the challenge, generates a solution, and returns it to your scraper. This process bypasses the CAPTCHA for uninterrupted data extraction, significantly improving the efficiency and reliability of your web scraping operations and enhancing web scraping security.
Q5: What are honeypots, and how can I avoid them?
Honeypots are invisible links or elements embedded within a webpage that are designed to trap automated bots. A human user would not see or interact with these elements, but a bot might. To avoid honeypots, your scraper should analyze the CSS properties of links (e.g., display: none, visibility: hidden, or color: #fff on a white background) and avoid following any links that are hidden from human view. This careful analysis is critical for maintaining web scraping security and avoiding immediate detection and blocking.
More
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
Learn scalable Rust web scraping architecture with reqwest, scraper, async scraping, headless browser scraping, proxy rotation, and compliant CAPTCHA handling.

Web ScrapingApr 17, 2026
How to Scrape Job Listings Without Getting Blocked
Learn the best techniques to scrape job listings without getting blocked. Master Indeed scraping, Google Jobs API, and web scraping API with CapSolver.
