What Is Data Grounding in AI? Practical Guide for Reliable LLMs

Sora Fujimoto
AI Solutions Architect
TL;DR
- Data grounding connects AI outputs to trusted, current, and relevant information sources.
- Data grounding reduces unsupported answers by adding context at inference time.
- Grounding data can include documents, databases, search results, catalogs, policies, and permitted records.
- RAG is a common technique for data grounding, but it is not the whole discipline.
- Strong data grounding needs quality checks, permissions, retrieval evaluation, citations, and monitoring.
- Teams using automation should collect data lawfully and handle CAPTCHA challenges only in authorized workflows.
Introduction
Data grounding is the practice that makes AI answers more accurate, current, and verifiable. It gives a model the right context before it answers. This guide is for product teams, SEO teams, developers, and automation teams building AI tools on top of LLMs. You will learn what data grounding in AI means, how it works, how it differs from RAG and fine-tuning, and how to apply it responsibly. The value is practical: grounded AI systems can cite sources, respect permissions, and reduce stale answers. When lawful automation workflows meet traffic validation or CAPTCHA challenges, CapSolver can support compliant testing processes.
Data Grounding Definition
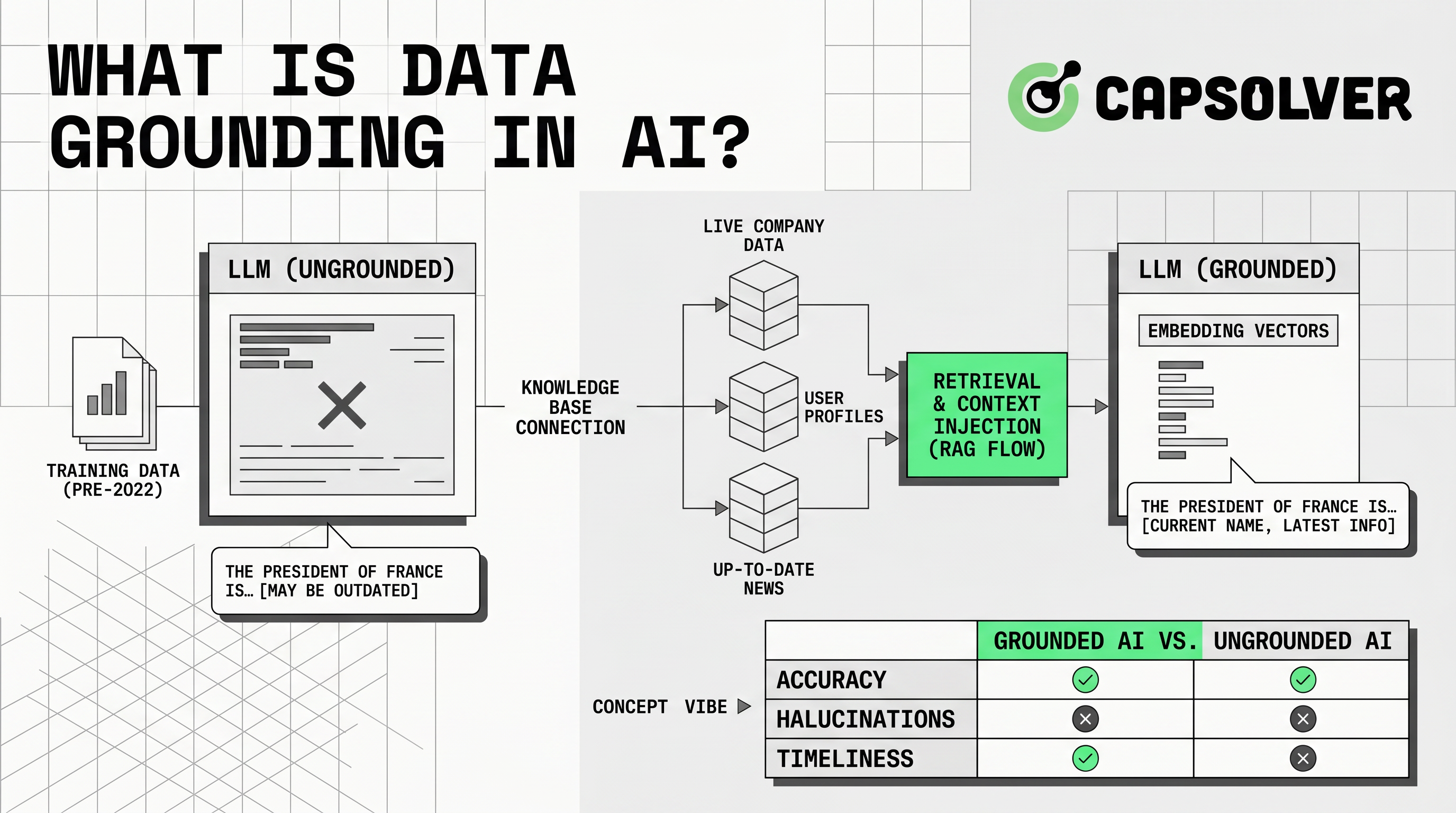
Data grounding means anchoring AI responses in trusted external context. The application supplies relevant information to a model when a user asks a question. Microsoft defines grounding data as information provided to a language model at inference time to improve accuracy and relevance through context not found in original training data via Microsoft Azure Well-Architected guidance.
Data grounding matters because LLMs predict language. They do not automatically know your latest prices, policies, documents, customer records, or public market data. Without trusted context, an answer can sound confident while missing facts. With data grounding, the system can retrieve source material, insert it into the prompt, and ask the model to answer from that material.
AI data grounding is not only a prompt trick. It is a data design pattern. It includes source selection, cleaning, indexing, access control, retrieval, response generation, citation, evaluation, and monitoring.
Why Data Grounding Matters for AI Accuracy
Data grounding improves AI reliability by narrowing the model’s answer space. Google Cloud describes enterprise grounding as connecting models to web information, enterprise data, databases, applications, and trusted sources to improve completeness and accuracy through Google Cloud enterprise truth.
This is useful for fast-changing domains. Inventory, support policies, documentation, pricing, and event schedules change often. A model trained months ago cannot know every update. Data grounding gives the application a path to fresh information without retraining the model every day.
Data grounding also helps teams explain answers. Citations, timestamps, and source fields support QA, compliance review, and user trust.
How Data Grounding Works
Data grounding works through a retrieval and generation flow. The system first identifies which sources are trustworthy. It then prepares those sources for search. Common sources include help centers, manuals, APIs, SQL databases, vector indexes, product feeds, and approved public pages.
The next step is ingestion. Teams clean documents, remove duplicates, standardize metadata, split content into chunks, and store it in a search index. The index may use keyword search, vector search, hybrid search, or graph search. Microsoft recommends externalizing grounding data to a search index when it improves retrieval, performance, and source-system protection through AI grounding data design.
When a user asks a question, the system retrieves relevant records. It filters by permissions, freshness, language, region, or product line. It then adds retrieved context to the model prompt. The model answers from that context and may return source citations.
Data grounding succeeds when retrieval is precise. Strong systems measure relevance, faithfulness, latency, and source coverage.
Comparison Summary
Data grounding overlaps with several AI methods. The table below shows the practical difference.
| Method | Main Purpose | Best Use Case | Key Limitation |
|---|---|---|---|
| Data grounding | Anchor answers in trusted context | Current, source-backed answers | Requires strong retrieval and governance |
| RAG | Retrieve documents before generation | Knowledge-base Q&A and support agents | Can retrieve irrelevant or outdated context |
| Fine-tuning | Change model behavior through examples | Style, format, or domain behavior | Not ideal for changing facts |
| Prompt engineering | Guide behavior with instructions | Small tasks and response formatting | Cannot supply missing facts alone |
| Guardrails | Enforce policy and output controls | Safety, format, and compliance checks | Cannot replace verified source context |
This comparison shows why data grounding is broader than RAG. RAG is a common implementation pattern. Data grounding is the full discipline of connecting model output to reliable evidence.
Common Data Grounding Sources
Data grounding starts with source quality. Teams should rank sources by authority, freshness, ownership, and permission level.
Internal sources often provide the most business value. These include CRM records, tickets, policies, inventory systems, product specifications, and knowledge bases. They require strict access control.
External sources add freshness and breadth. These include official documentation, government guidance, public datasets, standards bodies, and reputable market data. NIST states that its AI Risk Management Framework helps organizations manage risks to individuals, organizations, and society through NIST AI RMF. Such sources are useful when writing policies for trustworthy AI systems.
Public web data can support market monitoring, SEO research, and competitive analysis. Teams should keep this lawful and reasonable. They should respect site terms, rate limits, applicable robots guidance, and privacy obligations. CapSolver’s resources on AI and automation and automation workflows are useful starting points for responsible processes.
A Production Workflow for Data Grounding
Data grounding works best with a clear operating model. First, define the answer boundary. Decide what the AI may answer, which sources it may use, and when it must refuse or escalate.
Second, prepare the data. Remove duplicates, outdated records, private fields, and noisy boilerplate. Add metadata such as owner, date, region, product, language, and permission level. This makes retrieval more accurate.
Third, design retrieval. Use keyword search for exact terms, vector search for semantic similarity, and filters for permitted records.
Fourth, evaluate performance. Create a test set of real questions. Score retrieval relevance, answer faithfulness, citation accuracy, and latency. Review edge cases with domain experts. Do not rely only on model confidence.
Fifth, monitor drift. Data grounding can fail when documents become stale, indexes break, permissions change, or user intent shifts. Critical systems need automated freshness checks and human review paths.
Compliance and Security Considerations
Data grounding must respect legal, privacy, and security boundaries. Technical access does not mean permission. Grounded AI systems should avoid private, restricted, sensitive, or unauthorized data unless the organization has a clear lawful basis and user permission.
Security risks also matter. OWASP lists prompt injection, sensitive information disclosure, excessive agency, and overreliance among major risks for LLM applications through OWASP Top 10 for LLM Applications. Data grounding can reduce unsupported claims, but it can introduce risks if retrieval accepts malicious content or exposes protected records.
Teams should use permission-aware retrieval. They should sanitize untrusted text, log source IDs instead of sensitive records, and separate data by classification.
Automation teams need extra care. Web data collection should focus on permitted public data, reasonable request rates, and documented business purposes. When CAPTCHA challenges appear in authorized QA, monitoring, or data workflows, teams should treat them as part of traffic validation. CapSolver’s article on public web data collection and its guide to CAPTCHA challenges can help teams understand the operational context.
Where CapSolver Fits in Responsible AI Workflows
CapSolver is relevant when data grounding depends on lawful automation workflows. Some teams collect public data for price monitoring, SEO checks, ad verification, QA testing, or research. These workflows may face CAPTCHA challenges during normal browsing or testing.
CapSolver can help teams handle those challenges through a service designed for automation environments. The recommendation is narrow and compliance-first. Use it only where you have authorization, respect applicable rules, and avoid restricted or sensitive data. Teams can review CapSolver products to understand supported scenarios and match them to approved workflows.
Redeem Your CapSolver Bonus Code
Boost your automation budget instantly!
Use bonus code CAP26 when topping up your CapSolver account to get an extra 5% bonus on every recharge — with no limits.
Redeem it now in your CapSolver Dashboard
Data grounding and CAPTCHA handling should not be mixed casually. The grounding layer decides which evidence the AI may use. The automation layer collects or checks data under approved rules. Keeping these layers separate makes audits easier and reduces operational risk.
Practical Metrics for Grounded AI Systems
Data grounding needs measurable quality standards. Retrieval relevance asks whether returned context answers the question. A low score means the model is working with weak evidence.
Answer faithfulness asks whether the answer stays inside the retrieved sources. This matters because fluent answers can still add unsupported details.
Citation accuracy checks whether every cited source supports the sentence it follows. Freshness tracks document age, index update time, and source update frequency. Refusal quality checks whether the system says when evidence is missing.
Conclusion and CTA
Data grounding is one of the most practical ways to make AI systems more reliable. It connects answers to trusted context, improves freshness, supports citations, and helps teams manage risk. RAG is often part of the solution, but production-grade data grounding also needs clean data, strong permissions, evaluation, monitoring, and responsible automation practices.
If your AI workflow depends on public data monitoring, browser automation, QA testing, or research, plan the data pipeline carefully. Keep source access lawful. Keep sensitive data protected. Review outputs before using them for important decisions. For approved workflows that encounter CAPTCHA challenges, consider evaluating CapSolver as part of a compliant automation stack.
FAQ
What is data grounding in AI?
Data grounding is the process of connecting AI answers to trusted context. The context may come from documents, databases, APIs, search indexes, or approved public sources. It helps the model answer from evidence instead of relying only on training data.
Is data grounding the same as RAG?
No. RAG is one common way to implement data grounding. Data grounding is broader. It includes source governance, indexing, permissions, retrieval evaluation, citations, monitoring, and escalation rules.
Why does data grounding reduce unsupported AI answers?
Data grounding reduces unsupported answers because it gives the model relevant evidence at inference time. The model can answer from current context instead of filling gaps from statistical patterns alone.
What data should be used for grounding data for LLMs?
Use data that is accurate, permitted, current, and relevant. Good examples include official documentation, product records, support policies, knowledge bases, public datasets, and approved business databases. Avoid private or restricted data without proper authorization.
How should teams apply data grounding responsibly?
Teams should define source rules, enforce access controls, monitor retrieval quality, and review high-impact outputs. Automation teams should collect data lawfully, respect site rules, and use CAPTCHA-related services only in authorized workflows.
More
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
Learn scalable Rust web scraping architecture with reqwest, scraper, async scraping, headless browser scraping, proxy rotation, and compliant CAPTCHA handling.

Web ScrapingApr 17, 2026
How to Scrape Job Listings Without Getting Blocked
Learn the best techniques to scrape job listings without getting blocked. Master Indeed scraping, Google Jobs API, and web scraping API with CapSolver.
