如何不被阻止地抓取招聘职位

Lucas Mitchell
Automation Engineer
TL;Dr:
- 使用住宅代理IP: 使用高质量的住宅IP来避免被主要招聘网站或专业社交平台标记。
- 模拟浏览器指纹: 使用工具如
curl_cffi匹配TLS指纹和HTTP头部以匹配真实浏览器配置文件。 - 自动处理CAPTCHAs: 集成可靠的求解器如 CapSolver 来处理Cloudflare Turnstile和reCAPTCHA挑战。
- 遵守robots.txt和速率限制: 实现随机延迟并遵循道德爬取指南以保持长期访问。
引言
网络爬取职位信息已成为招聘机构、市场研究人员和职位聚合器的核心工具。然而,主要招聘网站已部署了复杂的安全部署措施,可以在几秒钟内阻止您的数据收集。如果您曾经在尝试爬取职位信息时遇到立即的IP封禁或无尽的验证循环,您并不孤单。挑战在于让您的自动化脚本难以与人类浏览行为区分。本指南提供了一个全面的技术路线图,帮助您有效地爬取职位信息,同时保持低检测率。
为什么招聘网站会阻止您的爬虫
招聘平台和专业社交网站投入大量资金用于安全防护,以保护其专有数据并确保网站稳定性。他们主要使用四层检测机制来识别和阻止爬虫。
基于IP的声誉和速率限制
大多数招聘网站会跟踪来自单个IP地址的请求数量。如果您超过一定阈值,您的IP将被临时或永久列入黑名单。数据中心IP尤其容易受到攻击,因为它们很容易被识别为属于服务器农场而非真实用户。
浏览器和TLS指纹识别
现代反机器人系统如Cloudflare和DataDome不仅关注您的User-Agent。它们分析您的TLS(传输层安全)握手,检查特定的密码套件和扩展。如果您使用默认的requests库,其JA3指纹会立即表明这是一个机器人。
行为分析
人类用户不会每0.5秒点击一次链接或以完全线性的方式导航。表现出机器人行为的爬虫——例如固定请求间隔或缺少CSS/图像加载——会被行为分析引擎迅速标记。
CAPTCHAs和JavaScript挑战
当网站怀疑但不确定时,它会触发一个挑战。这可能是一个简单的JavaScript执行检查或一个复杂的CAPTCHA。如果没有自动解决这些挑战的方法,您的爬取流程将完全停止。
无检测职位爬取的关键技术
要构建一个健壮的爬虫,您必须针对每层检测机制采取特定的技术对策。
1. 实施住宅代理IP轮换
使用单个IP是最快被封禁的方式。相反,您应该使用住宅代理池。与数据中心IP不同,住宅IP由互联网服务提供商(ISP)分配给真实家庭,使它们比合法流量更难区分。
| 代理类型 | 检测风险 | 成本 | 最佳使用场景 |
|---|---|---|---|
| 数据中心 | 高 | 低 | 低安全网站,测试 |
| 住宅 | 低 | 中 | 高安全招聘网站和搜索引擎 |
| 移动(4G/5G) | 非常低 | 高 | 高度反机器人系统 |
当您爬取职位信息时,请确保您的代理提供商支持自动轮换。这确保了每次请求或每次会话都来自不同的地理位置和IP。
2. 掌握TLS指纹模拟
如前所述,标准库如requests或urllib具有独特的TLS指纹。为了解决这个问题,您应该使用curl_cffi,它允许您的脚本模拟真实浏览器(如Chrome或Firefox)的TLS握手。
python
from curl_cffi import requests
# 模拟Chrome 120 TLS指纹
response = requests.get(
"https://www.target-job-board.com/jobs?q=software+engineer",
impersonate="chrome120",
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
}
)
print(response.status_code)通过将您的User-Agent与相应的TLS配置文件匹配,您可以显著降低被Cloudflare或Akamai阻止的可能性。
3. 使用CapSolver处理CAPTCHAs
即使有完美的头部和代理,您最终仍会遇到挑战。招聘网站经常使用Cloudflare Turnstile或reCAPTCHA来验证用户。在大规模手动解决这些挑战是不可能的。这就是CapSolver成为您自动化栈中必不可少的部分的原因。
CapSolver 提供了一个无缝的API来解决各种类型的CAPTCHA。例如,如果您在使用职位搜索API或爬取主要就业平台时遇到Cloudflare Turnstile挑战,可以使用以下官方实现:
python
import requests
import time
api_key = "YOUR_CAPSOLVER_API_KEY"
site_key = "0x4XXXXXXXXXXXXXXXXX" # 在目标网站的HTML中找到
site_url = "https://www.target-job-board.com"
def solve_turnstile():
payload = {
"clientKey": api_key,
"task": {
"type": 'AntiTurnstileTaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
task_id = res.json().get("taskId")
if not task_id:
return None
while True:
time.sleep(1)
result_res = requests.post("https://api.capsolver.com/getTaskResult", json={"clientKey": api_key, "taskId": task_id})
result = result_res.json()
if result.get("status") == "ready":
return result.get("solution", {}).get('token')
if result.get("status") == "failed":
return None
token = solve_turnstile()将此集成到您的工作流中可确保您的爬虫无需人工干预即可继续任务,从而有效保持您的数据管道的正常运行。
领取您的CapSolver优惠码
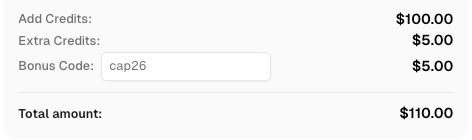
立即提升您的自动化预算!
在充值CapSolver账户时使用优惠码 CAP26,每次充值可获得额外 5% 的奖励 —— 没有限制。
立即在您的 CapSolver仪表板 中领取
4. 优化请求头部和引用来源
一个常见错误是发送“裸请求”。真实浏览器总是发送Referer头部和各种Sec-CH-UA(客户端提示)头部。当您爬取职位信息时,请始终将引用来源设置为网站的主页或之前的搜索结果页面。
- User-Agent: 使用最近的、流行的字符串。
- Referer:
https://www.google.com/或网站的域名。 - Accept-Encoding:
gzip, deflate, br(确保您的代码可以解压缩这些内容)。
爬取策略比较总结
| 策略 | 有效性 | 实施难度 | 推荐用途 |
|---|---|---|---|
| 基础Python Requests | 非常低 | 低 | 非保护的个人博客 |
| 无头浏览器(Selenium) | 中等 | 中等 | 有大量JavaScript的网站 |
| 隐形浏览器 + 代理 | 高 | 高 | 高安全就业平台 |
| 网络爬虫API | 非常高 | 低 | 企业级职位数据提取 |
伦理和法律考虑
虽然技术成功很重要,但您还必须优先考虑伦理爬取。始终检查网站的robots.txt文件和使用条款。根据 万维网联盟(W3C) 的指南,伦理数据收集涉及通过不向服务器发送过多请求来尊重目标服务器的健康。此外,电子前沿基金会 强调,抓取公开可用的数据通常受到保护,但您应避免未经许可访问私人用户信息或破解登录墙。
结论
成功爬取职位信息而不被阻止需要多层方法。通过结合住宅代理轮换、TLS指纹模拟以及通过CapSolver自动解决CAPTCHA,您可以构建一个模仿人类行为的健壮系统。请记住,网络爬虫环境在不断演变;紧跟最新的安全管理趋势是保持竞争优势的关键。
常见问题
1. 爬取职位信息是否合法?
在许多司法管辖区,爬取公开的职位信息通常是合法的,前提是您不违反《计算机欺诈和滥用法》(CFAA)或版权法。对于具体用例,请咨询法律顾问。
2. 我应该多久轮换一次代理?
对于高安全网站,最好为每次请求或每隔几分钟轮换IP以避免模式检测。
3. 我可以不登录账户就爬取专业社交网站吗?
许多专业平台限制严格。虽然一些公开资料和职位信息可见,但大部分数据在登录墙后。在登录墙后爬取会带来更高的法律和技术风险。
4. 为什么我的无头浏览器仍然被抓住?
标准无头浏览器如Puppeteer或Selenium会留下“指纹”如navigator.webdriver = true。您应该使用插件如stealth来隐藏这些属性。
5. 避免IP封禁的最佳方法是什么?
避免IP封禁最有效的方法是结合住宅代理和随机请求间隔(抖动)。