如何在Crawl4AI中通过CapSolver集成解决reCAPTCHA v3

Ethan Collins
Pattern Recognition Specialist

简介
reCAPTCHA v3 是 Google 的高级不可见 CAPTCHA,它在后台静默运行,通过分析用户行为来分配一个评分,以指示机器人活动的可能性。与前代 reCAPTCHA v2 不同,它通常不会向用户展示交互式挑战。虽然这改善了用户体验,但为网络自动化和数据抓取引入了新的复杂性,因为传统的令牌注入方法通常不足以应对或容易被覆盖。
本文深入介绍了如何将 Crawl4AI(一款强大的网络爬虫)与 CapSolver(领先的 CAPTCHA 求解服务)集成,专门用于解决 reCAPTCHA v3。我们将探讨高级技术,包括基于 API 的解决方案(JavaScript fetch 钩子)和浏览器扩展集成,以确保即使在受 reCAPTCHA v3 保护的网站上也能实现无缝且可靠的网络数据提取。
理解 reCAPTCHA v3 及其独特挑战
reCAPTCHA v3 通过在无需用户交互的情况下为每次请求返回一个评分(0.0 到 1.0 之间)来工作。评分 0.0 表示高度可能为机器人活动,而 1.0 表示人类用户。网站随后使用此评分来决定是否允许该操作、显示挑战或阻止请求。reCAPTCHA v3 的不可见性意味着:
- 无可见挑战: 用户不会看到复选框或图像谜题。
- 基于评分的验证: 决策基于风险评分。
- 动态令牌生成: 令牌通常通过
fetch或XMLHttpRequest请求动态生成。 - 时间敏感性: 过早注入令牌可能导致被覆盖,而过晚可能错过验证步骤。
CapSolver 的先进 AI 功能对于获取高评分的有效 reCAPTCHA v3 令牌至关重要。当与 Crawl4AI 的强大浏览器控制结合使用时,它使开发人员能够克服这些挑战并保持不间断的数据流。
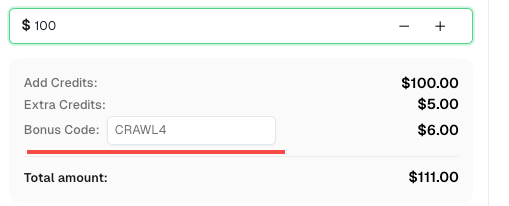
💡 Crawl4AI 集成用户的独家优惠:
为了庆祝此次集成,我们为通过本教程注册的所有 CapSolver 用户提供独家 6% 优惠码 —CRAWL4。
在 仪表板 中充值时输入该代码,即可 立即获得额外 6% 的信用额度。
集成方法 1:通过 API 集成 CapSolver 与 Crawl4AI(Fetch 钩子)
通过 API 集成绕过 reCAPTCHA v3 需要比 v2 更高级的方法,主要是由于其不可见性和动态令牌验证。关键策略是通过 CapSolver 获取 reCAPTCHA v3 令牌,然后在浏览器中钩住 window.fetch 方法,在验证的精确时刻用 CapSolver 提供的令牌替换原始 reCAPTCHA v3 令牌。
工作原理:
- 预先获取令牌: 在 Crawl4AI 导航到目标页面之前,使用 CapSolver 的 SDK 调用其 API 来解决 reCAPTCHA v3。这将为您提供一个有效的
gRecaptchaResponse令牌,并可能获得更高的评分。 - 导航并注入 JavaScript: Crawl4AI 导航到目标页面。关键的是,它通过
CrawlerRunConfig中的js_code注入 JavaScript 代码,覆盖window.fetch方法。 - 钩住 Fetch 请求: 注入的 JavaScript 会拦截
fetch请求。当检测到针对 reCAPTCHA v3 验证端点(例如/recaptcha-v3-verify.php)的请求时,JavaScript 会修改请求以包含 CapSolver 提供的令牌,而不是页面本身生成的令牌。 - 继续操作: 在成功钩住 fetch 请求并提交有效令牌后,Crawl4AI 可以继续其他操作,因为 reCAPTCHA v3 验证将通过。
示例代码:API 集成用于 reCAPTCHA v3(Fetch 钩子)
以下 Python 代码演示了将 CapSolver 的 API 与 Crawl4AI 集成以解决 reCAPTCHA v3 的高级技术。此示例使用了 reCAPTCHA v3 演示页面。
python
import asyncio
import capsolver
from crawl4ai import *
# TODO: 设置您的配置
api_key = "CAP-xxxxxxxxxxxxxxxxxxxxx" # 您的 CapSolver API 密钥
site_key = "6LdKlZEpAAAAAAOQjzC2v_d36tWxCl6dWsozdSy9" # 您目标网站的站点密钥
site_url = "https://recaptcha-demo.appspot.com/recaptcha-v3-request-scores.php" # 您目标网站的页面 URL
page_action = "examples/v3scores" # 您目标网站的页面操作
captcha_type = "ReCaptchaV3TaskProxyLess" # 您目标验证码的类型
capsolver.api_key = api_key
async def main():
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
)
# 使用 CapSolver SDK 获取 reCAPTCHA 令牌
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"websiteKey": site_key,
"pageAction": page_action,
})
token = solution["gRecaptchaResponse"]
print("reCAPTCHA 令牌:", token)
async with AsyncWebCrawler(config=browser_config) as crawler:
await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
js_code = """
const originalFetch = window.fetch;
window.fetch = function(...args) {
if (typeof args[0] === \'string\' && args[0].includes(\'/recaptcha-v3-verify.php\')) {
const url = new URL(args[0], window.location.origin);
url.searchParams.set(\'action\', \""" + token + """\");
args[0] = url.toString();
document.querySelector(\".token\").innerHTML = \"fetch(\\'/recaptcha-v3-verify.php?action=examples/v3scores&token="""+token+"""\')\";
console.log(\'Fetch URL 钩住:\', args[0]);
}
return originalFetch.apply(this, args);
};
"""
wait_condition = """() => {
return document.querySelector(\".step3:not(.hidden)\");
}"""
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
wait_for=f"js:{wait_condition}"
)
result_next = await crawler.arun(
url=site_url,
config=run_config,
)
print(result_next.markdown)
if __name__ == "__main__":
asyncio.run(main())代码分析:
- CapSolver
solve调用:capsolver.solve方法被调用,使用ReCaptchaV3TaskProxyLess类型、websiteURL、websiteKey,并重要的是pageAction。pageAction参数对于 reCAPTCHA v3 至关重要,因为它帮助 CapSolver 理解页面上 reCAPTCHA 的上下文并生成更准确的令牌。 - JavaScript
fetch钩子:js_code是此解决方案的核心。它重新定义window.fetch。当向/recaptcha-v3-verify.php发起fetch请求时,脚本会拦截它,修改 URL 以在action参数中包含 CapSolver 提供的token,然后允许原始fetch继续。这确保服务器接收来自 CapSolver 的高评分令牌。 wait_for条件:wait_condition确保 Crawl4AI 等待特定元素(.step3:not(.hidden))可见,表明 reCAPTCHA v3 验证过程已成功完成,页面已推进。
集成方法 2:CapSolver 浏览器扩展集成用于 reCAPTCHA v3
对于 reCAPTCHA v3,使用 CapSolver 浏览器扩展可以简化集成过程,尤其是当目标是利用扩展的自动求解功能时。该扩展设计用于在后台检测并解决 reCAPTCHA v3,通常在访问网站时触发。
工作原理:
- 持久化浏览器上下文: 配置 Crawl4AI 使用
user_data_dir启动一个浏览器实例,该实例保持安装的 CapSolver 扩展。 - 扩展配置: 在此浏览器配置文件中安装 CapSolver 扩展并确保配置了您的 API 密钥。对于 reCAPTCHA v3,通常建议让扩展自动求解,即
manualSolving应为false(或默认值)。 - 导航到目标页面: Crawl4AI 导航到受 reCAPTCHA v3 保护的网页。
- 自动求解: 运行在浏览器上下文中的 CapSolver 扩展会检测到 reCAPTCHA v3 并自动求解它,按需注入令牌。这通常在后台无缝完成。
- 继续操作: 一旦 reCAPTCHA v3 被扩展求解,Crawl4AI 可以继续其抓取任务,因为浏览器上下文现在将具有后续请求所需的必要有效令牌。
示例代码:扩展集成用于 reCAPTCHA v3(自动求解)
此示例演示了如何配置 Crawl4AI 使用带有 CapSolver 扩展的浏览器配置文件以实现自动 reCAPTCHA v3 求解。关键是确保扩展在 user_data_dir 中正确设置。
python
import asyncio
import time
from crawl4ai import *
# TODO: 设置您的配置
user_data_dir = "/browser-profile/Default1" # 确保此路径正确设置并包含您的配置扩展
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120", # 可选:如需配置代理
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v3-request-scores.php", # 使用 reCAPTCHA v3 演示 URL
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# reCAPTCHA v3 通常在页面加载时由扩展自动求解。
# 您可能需要添加等待条件或 time.sleep 以在继续依赖令牌的进一步操作之前等待 CAPTCHA 求解完成。
time.sleep(30) # 示例等待,根据扩展操作需要进行调整
# 在 CAPTCHA 求解后继续其他 Crawl4AI 操作
# 例如,检查在成功验证后出现的元素或内容
# print(result_initial.markdown) # 您可以在等待后检查页面内容
if __name__ == "__main__":
asyncio.run(main())代码分析:
user_data_dir: 与 reCAPTCHA v2 扩展集成类似,此参数对于 Crawl4AI 使用带有预安装和配置的 CapSolver 扩展的浏览器配置文件至关重要。然后,该扩展将自动处理 reCAPTCHA v3 的解决。- 自动求解: CapSolver 扩展设计用于自动检测和解决 reCAPTCHA v3 挑战。包含
time.sleep作为一般占位符,以允许扩展完成其后台操作。对于更稳健的解决方案,考虑使用 Crawl4AI 的wait_for功能来检查表示 reCAPTCHA v3 成功解决的特定页面变化。
结论
由于 reCAPTCHA v3 的不可见性和动态验证机制,解决其在网页抓取中的挑战需要复杂的解决方案。Crawl4AI 与 CapSolver 的集成提供了克服这些挑战的有力工具。无论是通过 JavaScript fetch 钩子的 API 集成的精确控制,还是浏览器扩展提供的简化自动化,开发人员都可以确保其网页抓取操作保持高效且不间断。
通过利用 CapSolver 的高精度 reCAPTCHA v3 求解能力和 Crawl4AI 的高级浏览器控制,您可以从受此先进 CAPTCHA 保护的网站中保持高数据提取成功率。这种协同作用使开发人员能够构建更强大且可靠的自动化网络数据收集系统。


