如何在网页抓取中使用Python解决reCAPTCHA问题

Ethan Collins
Pattern Recognition Specialist

网络爬虫已成为开发人员、数据工程师和SEO专家的重要工具。然而,网络爬虫中最常见的障碍之一是reCAPTCHA,这是一种设计用于区分人类和自动化机器人的安全机制。reCAPTCHA可以防止网站遭受滥用活动,例如账户创建、垃圾信息发送和数据爬取。
本文详细介绍了reCAPTCHA,解释了它为何对自动化构成挑战,并展示了如何使用Python和****CapSolver**** 安全高效地解决它。
什么是reCAPTCHA
reCAPTCHA 由谷歌开发,是一种安全系统,向用户展示容易被人类识别但对自动化程序困难的挑战。这些挑战旨在防止恶意机器人访问网站内容,确保网络服务的完整性。
常见的reCAPTCHA挑战包括:
- 基于文本的验证:用户输入图像中显示的扭曲字符。
- 图像选择:用户选择与给定描述相符的图像(例如,“选择所有交通灯”)。
- 行为分析:捕捉鼠标移动、滚动和输入模式以判断用户是否为人类。
通过利用这些挑战,网站可以防止不必要的爬取、垃圾信息和自动化攻击。然而,这也给合法的自动化使用场景(如SEO分析、价格监控和市场研究)带来了障碍。
为什么reCAPTCHA会阻止网络爬虫
网络爬虫工具通常模仿人类浏览行为来收集数据。然而,传统爬虫在解决reCAPTCHA时存在局限,因为:
-
图像识别复杂
图像挑战需要准确识别物体,这对简单的自动化脚本来说很困难。 -
行为分析
不可见的CAPTCHA会跟踪鼠标移动、点击模式和页面交互,而传统脚本无法很好地模拟这些行为。 -
IP和会话限制
reCAPTCHA可能会阻止来自同一IP的重复请求或标记可疑模式。
因此,爬虫经常无法提取数据或被完全阻止。这就是CapSolver等工具变得至关重要的原因。
reCAPTCHA的不同类型
多年来,谷歌发布了多个版本的reCAPTCHA以提高安全性和可用性。了解每种类型对于自动化至关重要。
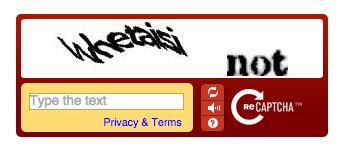
1. reCAPTCHA v1
第一个版本向用户展示两个扭曲的单词。其中一个单词是已知的(用于人类验证),另一个是未知的(用于数字化书籍中的文本)。用户必须正确输入两个单词才能通过测试。
- 特点:简单的文本识别,2个单词,基本的扭曲。
- 限制:现已弃用,很少使用。
2. reCAPTCHA v2
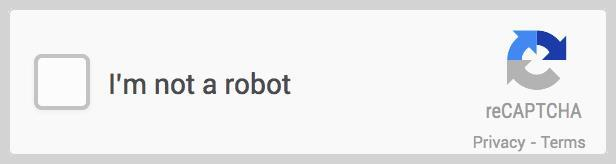
引入了**“我不是机器人”复选框**,在点击时评估用户行为。可疑活动会触发二次挑战,通常是图像拼图。
- 特点:复选框交互,图像识别挑战,人类行为评估。
- 应用:常见于登录页面、表单和评论部分。
3. 不可见的reCAPTCHA v2
此版本不显示复选框。它在后台运行,仅在检测到可疑行为时触发挑战。
- 特点:无缝用户体验,仅在异常时触发。
- 优势:减少人类用户的摩擦,同时保持安全。

4. reCAPTCHA v2 企业版
企业版v2增加了对机器人更高级的防护,包括高级风险分析、自适应挑战和与企业网站更好的集成。
5. reCAPTCHA v3
与v2不同,reCAPTCHA v3完全在后台运行,分析用户行为并分配一个风险评分。除非检测到可疑活动,否则不会显示挑战。
- 特点:基于评分的评估,对大多数用户不可见,用于自适应响应。
- 应用:电子商务平台、金融网站和企业工具。

6. reCAPTCHA v3 企业版
企业版v3提供对网站流量的细粒度洞察,并允许基于风险的响应。非常适合需要处理敏感数据或高流量网站的组织。
网络爬虫中的reCAPTCHA
网站使用reCAPTCHA来阻止自动化爬虫。传统爬虫无法绕过这些挑战,因此集成CAPTCHA解决方案成为继续自动化数据提取的必要条件。
使用CapSolver解决reCAPTCHA
CapSolver 利用机器学习自动解决reCAPTCHA。通过将CapSolver集成到Python工作流中,开发人员可以高效地绕过CAPTCHA障碍。
领取CapSolver奖励
通过快速奖励提升自动化性能!在向CapSolver账户充值时使用优惠码 CAP25,每次充值可获得额外5%的信用额度——无上限。立即优化您的CAPTCHA解决工作流程!

前提条件
- 安装Python
- CapSolver API密钥
- 可选:工作代理(某些任务类型需要)
第1步:安装CapSolver
bash
pip install capsolver第2步:使用代理解决reCAPTCHA v2
python
import capsolver
PROXY = "http://username:password@host:port"
capsolver.api_key = "您的CapSolver API密钥"
PAGE_URL = "PAGE_URL"
PAGE_KEY = "PAGE_SITE_KEY"
def solve_recaptcha_v2(url, key):
solution = capsolver.solve({
"type": "ReCaptchaV2Task",
"websiteURL": url,
"websiteKey": key,
"proxy": PROXY
})
return solution
def main():
print("正在解决reCaptcha v2...")
solution = solve_recaptcha_v2(PAGE_URL, PAGE_KEY)
print("解决方案:", solution)
if __name__ == "__main__":
main()第3步:无代理解决reCAPTCHA v2
python
import capsolver
capsolver.api_key = "您的CapSolver API密钥"
PAGE_URL = "PAGE_URL"
PAGE_KEY = "PAGE_SITE_KEY"
def solve_recaptcha_v2_proxyless(url, key):
solution = capsolver.solve({
"type": "ReCaptchaV2TaskProxyless",
"websiteURL": url,
"websiteKey": key,
})
return solution
def main():
print("正在无代理解决reCaptcha v2...")
solution = solve_recaptcha_v2_proxyless(PAGE_URL, PAGE_KEY)
print("解决方案:", solution)
if __name__ == "__main__":
main()第4步:获取结果
创建任务后,轮询getTaskResult端点直到CAPTCHA被解决:
json
POST https://api.capsolver.com/getTaskResult
Host: api.capsolver.com
Content-Type: application/json
{
"clientKey": "YOUR_API_KEY",
"taskId": "TASK_ID"
}一旦完成,响应中将包含已解决的CAPTCHA令牌。
结论
通过将**CapSolver** 集成到Python工作流中,网络爬虫可以高效地绕过reCAPTCHA障碍。开发人员现在可以自动化数据提取,而不会中断,节省时间并确保更高的成功率。CapSolver的灵活性支持代理和无代理任务,适用于各种爬虫场景。
常见问题(FAQ)
1. CapSolver能解决哪些类型的reCAPTCHA?
CapSolver支持reCAPTCHA v2/v3,包括不可见和企业版,以及图像到文本的CAPTCHA等。
2. 使用CapSolver是否需要代理?
不一定。标准情况可以使用无代理任务。
3. CapSolver解决reCAPTCHA的速度有多快?
平均解决时间为1–10秒,具体取决于CAPTCHA的复杂性和服务器负载。


