如何解决AI代理的CAPTCHA挑战:使用n8n、CapSolver和OpenClaw进行数据提取

Lucas Mitchell
Automation Engineer

让您的AI助手触发自动化的服务器端数据提取 —— 无需浏览器注入,无需代码。
挑战:CAPTCHAs 阻碍您的AI代理效率
当您的AI代理浏览网络时,CAPTCHAs是主要障碍。受保护的页面会阻止代理,表单无法提交,任务停滞,等待人工干预。这显著限制了AI代理在自动化数据抓取和信息处理中的效率和自主性。
为了解决这一核心问题,我们提供两种强大的解决方案,结合OpenClaw和CapSolver:
方法1 —— 浏览器扩展集成
将CapSolver Chrome扩展加载到OpenClaw的浏览器环境中。该扩展在客户端无声地检测并解决CAPTCHAs,无需n8n的参与,使AI代理在浏览页面时无缝绕过验证。(请参阅我们的扩展方法完整指南)
方法2 —— 服务器端n8n自动化流水线(本指南重点)
OpenClaw通过webhook触发单个请求,n8n然后通过CapSolver API解决CAPTCHA,提交表单,并将清理后的页面内容返回给您的AI代理。在此过程中,AI代理永远不会直接处理CAPTCHA验证。
您将构建的内容:
一个由webhook触发的服务器端CAPTCHA自动化流水线。n8n将利用CapSolver解决CAPTCHA,提交表单,并将处理后的页面内容返回给您的AI代理,确保数据提取任务的顺利执行。
前提条件
在开始之前,请确保您拥有以下环境和工具:
- 安装并运行OpenClaw网关 (
openclaw gateway start) - 本地运行的n8n — 安装指南
- CapSolver账户及API密钥 — 立即注册
- n8n中可用的CapSolver节点 (官方集成 — 已内置)
在n8n中设置CapSolver
CapSolver作为n8n的官方集成提供,无需额外安装社区节点。您可以在构建工作流时直接在节点面板中找到它。要使CapSolver节点能够与您的账户进行身份验证,您需要在n8n中创建凭据。
打开您的n8n画布,点击 + 添加节点,并搜索CapSolver。此节点在一个单元中处理任务创建、轮询和令牌检索。
添加凭据的步骤:
- 在n8n中,进入 凭据 → 新建凭据
- 搜索CapSolver
- 将您的API密钥粘贴到CapSolver仪表板
- 保存
重要:您工作流中的每个CapSolver节点都会引用此凭据。您只需创建一次 — 所有您的CAPTCHA解决工作流都将共享同一凭据。此外,CapSolver官方提供了一个丰富的GitHub技能库,您可以在其中探索与CapSolver相关的更多集成和用例,进一步扩展您的AI代理功能。
工作流:OpenClaw CAPTCHA自动化流水线
以下内容仅为示例。URL、字段名称、CAPTCHA类型、成功条件、响应结构 — 所有内容都特定于此处使用的演示站点。您的实际目标将不同。请将每个节点配置视为起点,而非最终设置。
工作原理
- Webhook — 接收来自OpenClaw(或任何HTTP客户端)的POST请求。
- CapSolver — 使用配置的任务类型解决CAPTCHA。
- HTTP请求 — 提交解决后的令牌到目标站点。
- 如果 — 检查响应是否表示成功或失败。
- 编辑字段 — 从响应中提取
pageText。 - 响应Webhook — 将结果返回给调用者。
Webhook ──► 解决CAPTCHA ──► 提交令牌 ──► 成功? ──► 提取结果 ──► 响应Webhook
└─► 标记失败 ────┘节点配置详情
创建一个名为“OpenClaw/Capsolver/n8n Scraper”的新工作流,包含以下节点:
1. Webhook节点
- 类型: Webhook
- HTTP方法: POST
- 路径:
openclaw/scrape - 响应: 响应节点 (使调用同步 — 调用者等待结果)
2. CapSolver节点
- 类型: CapSolver
- 任务类型:
ReCaptchaV2TaskProxyless - 网站URL:
https://example.com/protected-page - 网站密钥:
YOUR_SITE_KEY(在页面源代码中查找 — 查找data-sitekey) - 凭据: 您的CapSolver API密钥
使用reCAPTCHA v3?将任务类型切换为
ReCaptchaV3TaskProxyless并添加页面操作字段(例如login、submit、homepage)。这是v3所必需的 —— 它是站点与Google注册的操作名称。您可以在页面源代码中grecaptcha.execute(...)调用附近找到它。请注意,每种CAPTCHA类型都有其自己的参数集 —— v2中某些可选字段在v3中成为必需字段,v3可能暴露v2中不存在的字段(如
minScore)。始终查阅CapSolver文档以获取您的任务类型所需的准确参数。
此节点调用CapSolver API,等待解决(通常5-20秒),并返回令牌 $json.data.solution.gRecaptchaResponse。
3. HTTP请求节点
- 方法: POST
- URL:
https://example.com/protected-page - 正文: 表单编码
g-recaptcha-response=={{ $json.data.solution.gRecaptchaResponse }}
- 头部: 标准浏览器头部(User-Agent、Accept、Referer、Origin等)
这将提交表单,与浏览器的行为完全相同。
注意:令牌提交方式因站点而异。大多数表单期望它作为请求正文中的
g-recaptcha-response,但某些站点可能将其作为JSON字段、自定义头部,甚至作为cookie或不同名称发送。使用浏览器的DevTools(网络选项卡)检查真实提交的外观,并在HTTP请求节点中镜像它。
4. If节点(成功检查)
- 条件:
$json.data包含"recaptcha-success" - 正确分支 → 编辑字段(成功)
- 错误分支 → 编辑字段1(失败)
5. 编辑字段 / 编辑字段1节点
两个分支设置一个字段:
pageText={{ $json.data }}
成功和失败分支都传递 pageText —— 调用者可以检查HTML以确定结果。
根据您的页面进行调整:您如何解析和使用响应数据完全取决于您想要的内容以及目标站点返回的内容。某些页面返回JSON,其他返回HTML,一些在成功时重定向。您可能需要提取特定字段、解析表格、检查会话cookie或完全剥离HTML。成功条件(
"recaptcha-success")只是一个示例 —— 您的站点将有其自己的指示器。这些节点是起点;请预期根据您的用例进行自定义。
6. 保存结果节点
此节点将 { pageText, savedAt } 传递给webhook响应,并可选择将结果持久化到存储中。
注意:n8n的代码节点运行在沙盒VM中,会阻止Node.js内置模块如
require('fs')。使用执行命令节点代替以写入磁盘,或完全用适合您堆栈的任何n8n集成替换此节点。
选项A — 本地JSON文件(执行命令节点):
使用两个连接的节点:
节点7a — 准备数据(代码节点):
javascript
const item = $input.first().json;
const now = new Date();
const savedAt = now.toISOString();
const data = { pageText: item.pageText || '', savedAt };
const encoded = Buffer.from(JSON.stringify(data)).toString('base64');
const cmd = 'python3 /path/to/save-result.py ' + encoded;
return [{ json: { cmd, pageText: data.pageText, savedAt } }];节点7b — 保存结果(执行命令节点):
- 命令:
={{ $json.cmd }}
其中 save-result.py 读取base64参数并追加到本地JSON文件。
选项B — 任何n8n支持的存储:
n8n有几乎每个存储系统的原生节点。将节点7替换为以下任一节点:
| 存储 | n8n节点 |
|---|---|
| Google Sheets | 使用 pageText + 时间戳追加一行 |
| Airtable | 创建记录 |
| Notion | 创建数据库条目 |
| PostgreSQL / MySQL | 插入到表中 |
| AWS S3 / Cloudflare R2 | 上传JSON文件 |
| Slack / Telegram | 将结果发布到频道 |
只需在编辑字段和响应Webhook之间连接节点,并配置它以存储 $json.pageText 和时间戳。
7. 响应Webhook节点
- 响应内容: JSON
- 响应体:
={{ JSON.stringify($json) }} - 出错继续: 启用
一旦构建完成,激活工作流。webhook路径将处于以下状态:
POST http://127.0.0.1:3005/webhook/openclaw/scrape导入此工作流
复制以下JSON并通过 菜单 → 从JSON导入 导入到n8n中。导入后,在“解决CAPTCHA”节点中选择您的CapSolver凭据。
点击展开工作流JSON
json
{
"nodes": [
{
"parameters": {
"content": "## OpenClaw CAPTCHA自动化流水线\n\n### 工作原理\n\n1. 通过webhook触发器启动流程。\n2. 使用专用服务尝试解决CAPTCHA。\n3. 提交CAPTCHA令牌进行验证。\n4. 评估令牌提交是否成功。\n5. 设置结果并通过webhook返回。\n\n### 设置步骤\n\n- [ ] 使用所需的端点URL配置webhook触发器。\n- [ ] 设置CAPTCHA解决服务凭据。\n- [ ] 确保HTTP请求配置对于令牌提交有效。\n- [ ] 自定义成功和失败的响应消息。\n\n### 自定义\n\n您可以在“成功?”节点中自定义成功和失败条件及响应。",
"width": 480,
"height": 656
},
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
-1312,
-352
],
"id": "de683912-ba9c-4879-9a8e-38190c4b236c",
"name": "便签"
},
{
"parameters": {
"content": "## 初始化和CAPTCHA解决\n\n从webhook触发器开始,并使用外部服务解决CAPTCHA。",
"width": 800,
"height": 272,
"color": 7
},
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
-752,
-208
],
"id": "41705a72-53ba-4c61-951b-251f7f35f422",
"name": "便签1"
},
{
"parameters": {
"content": "## 令牌提交\n\n提交解决后的CAPTCHA令牌进行验证并检查结果。",
"width": 496,
"height": 304,
"color": 7
},
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
160,
-224
],
"id": "260fdb86-71a7-46dc-9b41-1abd4ae08b79",
"name": "便签2"
},
{
"parameters": {
"content": "## 结果处理和响应\n\n处理成功和失败结果并通过webhook发送响应。",
"width": 496,
"height": 480,
"color": 7
},
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
768,
-352
],
"id": "e17032fd-3901-4c2a-aeea-4088c9f79bd4",
"name": "便签3"
},
{
"parameters": {
"httpMethod": "POST",
"path": "openclaw/scrape",
"responseMode": "responseNode",
"options": {}
},
"type": "n8n-nodes-base.webhook",
"typeVersion": 2.1,
"position": [
-704,
-96
],
"id": "oc-909",
"name": "Webhook触发器",
"webhookId": "oc-909-webhook",
"onError": "continueRegularOutput"
},
{
"parameters": {
"websiteURL": "={{ $json.body.websiteURL || 'https://example.com/protected-page' }}",
"websiteKey": "={{ $json.body.websiteKey || 'YOUR_SITE_KEY_HERE' }}",
"optional": {}
},
"type": "n8n-nodes-capsolver.capSolver",
"typeVersion": 1,
"position": [
-96,
-96
],
"id": "oc-910",
"name": "解决CAPTCHA [Webhook]",
"credentials": {
"capSolverApi": {
"id": "BeBFMAsySMsMGeE9",
"name": "CapSolver账户"
}
}
},
{
"parameters": {
"method": "POST",
"url": "={{ $('Webhook Trigger').item.json.body.targetURL || 'https://example.com/protected-page' }}",
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "user-agent",
"value": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"
},
{
"name": "content-type",
"value": "application/x-www-form-urlencoded"
}
]
},
"sendBody": true,
"contentType": "form-urlencoded",
"bodyParameters": {
"parameters": [
{
"name": "g-recaptcha-response",
"value": "={{ $json.data.solution.gRecaptchaResponse }}"
}
]
},
"options": {
"response": {
"response": {}
}
}
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.3,
"position": [
208,
-96
],
"id": "oc-911",
"name": "提交令牌 [Webhook]"
},
{
"parameters": {
"conditions": {
"options": {
"caseSensitive": false,
"leftValue": "",
"typeValidation": "loose",
"version": 2
},
"conditions": [
{
"id": "if-2",
"leftValue": "={{ String($json.data || $json || '').includes($('Webhook Trigger').item.json.body.successMarker || 'recaptcha-success') }}",
"operator": {
"type": "boolean",
"operation": "true",
"singleValue": true
}
}
],
"combinator": "and"
},
"options": {}
},
"type": "n8n-nodes-base.if",
"typeVersion": 2.2,
"position": [
512,
-96
],
"id": "oc-912",
"name": "成功? [Webhook]"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "ws1",
"name": "success",
"value": "true",
"type": "boolean"
},
{
"id": "ws2",
"name": "pageText",
"value": "={{ $json.data || $json }}",
"type": "string"
},
{
"id": "ws3",
"name": "savedAt",
"value": "={{ new Date().toISOString() }}",
"type": "string"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
816,
-224
],
"id": "oc-913",
"name": "Extract Result [Webhook]"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "wf1",
"name": "success",
"value": "false",
"type": "boolean"
},
{
"id": "wf2",
"name": "pageText",
"value": "={{ $json.data || $json }}",
"type": "string"
},
{
"id": "wf3",
"name": "error",
"value": "Response did not contain success marker",
"type": "string"
},
{
"id": "wf4",
"name": "savedAt",
"value": "={{ new Date().toISOString() }}",
"type": "string"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
816,
-48
],
"id": "oc-914",
"name": "Mark Failed [Webhook]"
},
{
"parameters": {
"respondWith": "json",
"responseBody": "={{ JSON.stringify($json) }}",
"options": {}
},
"type": "n8n-nodes-base.respondToWebhook",
"typeVersion": 1.5,
"position": [
1120,
-96
],
"id": "oc-917",
"name": "Respond to Webhook"
}
],
"connections": {
"Webhook Trigger": {
"main": [
[
{
"node": "Solve CAPTCHA [Webhook]",
"type": "main",
"index": 0
}
]
]
},
"Solve CAPTCHA [Webhook]": {
"main": [
[
{
"node": "Submit Token [Webhook]",
"type": "main",
"index": 0
}
]
]
},
"Submit Token [Webhook]": {
"main": [
[
{
"node": "Success? [Webhook]",
"type": "main",
"index": 0
}
]
]
},
"Success? [Webhook]": {
"main": [
[
{
"node": "Extract Result [Webhook]",
"type": "main",
"index": 0
}
],
[
{
"node": "Mark Failed [Webhook]",
"type": "main",
"index": 0
}
]
]
},
"Extract Result [Webhook]": {
"main": [
[
{
"node": "Respond to Webhook",
"type": "main",
"index": 0
}
]
]
},
"Mark Failed [Webhook]": {
"main": [
[
{
"node": "Respond to Webhook",
"type": "main",
"index": 0
}
]
]
}
},
"pinData": {},
"meta": {
"instanceId": "962ff0267b713be0344b866fa54daae28de8ed2144e2e6867da355dae193ea1f"
}
}OpenClaw 集成
要将 OpenClaw 连接到此工作流,请创建一个触发脚本并注册它。
创建触发脚本:
bash
cat > ~/.openclaw/scripts/extract-data << \'EOF\'
#!/usr/bin/env bash
curl -s -X POST http://127.0.0.1:3005/webhook/openclaw/scrape
EOF
chmod +x ~/.openclaw/scripts/extract-data这是 OpenClaw 运行的唯一内容。没有参数、没有站点密钥、没有 URL —— 工作流知道要抓取什么。
OpenClaw 如何获取数据:脚本等待 n8n 完成(CapSolver 解决 + 表单提交),然后直接在 Webhook 响应中接收
{ pageText, savedAt }。没有文件读取 —— 数据通过 HTTP 同步返回。响应结构只是此工作流返回的内容 —— 如果你需要不同的字段(例如,解析后的价格、登录状态、结构化 JSON 对象),修改 Edit Fields 和 Save Result 节点以返回你用例所需的内容。
在 TOOLS.md 中注册命令:
打开 ~/.openclaw/workspace/TOOLS.md 并添加以下条目,以便 OpenClaw 了解该命令:
markdown
### extract-data
运行:`/root/.openclaw/scripts/extract-data`
从实时流水线返回新鲜的 `{ pageText, savedAt }`。从 JSON 响应中返回 `pageText` 字段。测试你的 AI 代理自动化流程
从 OpenClaw 触发 —— 通过 Discord、Telegram、WhatsApp 或任何频道向你的 AI 代理发送此命令:
extract dataOpenClaw 运行 extract-data 脚本,该脚本触发 Webhook 并等待。n8n 解决 CAPTCHA,提交表单,并直接在 HTTP 响应中返回 { pageText, savedAt }。OpenClaw 接收并总结结果 —— 通常在 10–40 秒内。
从终端测试:
bash
curl -s -X POST http://127.0.0.1:3005/webhook/openclaw/scrape适应工作流到你的目标网站
本指南的工作流是为特定的演示网站构建的。对于你的实际目标,管道的每个部分可能都需要调整。以下是需要关注的内容:
1. CAPTCHA 类型
并非所有网站都使用 reCAPTCHA v2。将 CapSolver 节点的任务类型更改为与目标使用的一致:
| 你在网站上看到的内容 | n8n 节点操作 |
|---|---|
| "我不是机器人"复选框 | reCAPTCHA v2 |
| 不可见的 reCAPTCHA(自动触发) | reCAPTCHA v2 |
| reCAPTCHA v3 分数 | reCAPTCHA v3 |
| Cloudflare Turnstile 小部件 | Cloudflare Turnstile |
| Cloudflare 挑战(5秒页面) | Cloudflare Challenge |
| GeeTest 拼图(v3) | GeeTest V3 |
| GeeTest 拼图(v4) | GeeTest V4 |
| DataDome 机器人保护 | DataDome |
| AWS WAF CAPTCHA | AWS WAF |
| MTCaptcha | MTCaptcha |
同时更新网站 URL 和网站密钥以匹配你的目标。你可以在页面源代码中找到站点密钥(查找 data-sitekey 属性,或 CapSolver 浏览器扩展会自动检测它)。
2. Token 提交方式
这是在不同网站之间变化最大的部分。演示网站使用带有 token 的简单表单 POST。你的目标可能不同:
作为表单字段(最常见)
POST /submit
Content-Type: application/x-www-form-urlencoded
g-recaptcha-response=TOKEN&other_field=value在 JSON 正文中
POST /api/login
Content-Type: application/json
{ "username": "...", "password": "...", "captchaToken": "TOKEN" }在头部
POST /api/action
X-Captcha-Token: TOKEN作为 Cookie
POST /submit
Cookie: cf_clearance=TOKEN在 URL 中作为查询参数
GET /search?q=query&token=TOKEN在浏览器的开发者工具的网络标签中手动解决 CAPTCHA 时,查看立即在解决后触发的请求 —— 这会显示 token 的位置。
3. HTTP 请求节点
一旦你知道 token 是如何提交的,根据需要配置 HTTP 请求节点:
- 方法:匹配网站(POST、GET、PUT)
- URL:接收表单或 API 调用的精确端点
- 头部:从网络标签中复制浏览器头部 —— User-Agent、Referer、Origin、Accept、Content-Type 通常需要
- 正文:根据端点使用表单编码、JSON 或 multipart
- Cookies:如果网站使用会话 Cookie,可以通过头部传递,或使用之前的 HTTP 请求节点通过登录步骤获取
4. 提取你需要的数据
当前工作流将响应的完整 HTML 作为 pageText 传递。根据你的用例,你可能需要进行后处理:
- 在 HTTP 请求后添加一个代码节点以解析 HTML 并提取特定字段(产品名称、价格、状态)
- 使用 n8n 的 HTML 提取节点从特定 CSS 选择器中提取数据而无需编写代码
- 存储结构化字段而不是原始 HTML —— 更容易查询和跨运行比较
5. 多步骤流程
一些目标需要多于一个请求:
- GET 页面以获取 CSRF 令牌或会话 Cookie
- 解决 CAPTCHA
- 使用 CSRF 令牌 + CAPTCHA 令牌 + 凭据提交表单
在 n8n 中链式多个 HTTP 请求节点来处理此问题。使用 $json 表达式在节点之间传递值。
故障排除
"无法到达 n8n 抓取器"
json
{"success": false, "error": "无法到达 n8n 抓取器。是否激活了 OpenClaw CAPTCHA 抓取工作流?"}检查:n8n 是否正在运行?工作流是否已激活?打开 n8n 并验证工作流是否处于活动状态(绿色开关)。
CapSolver 超时 / 无 Token
可能原因:
- 无效的 API 密钥 —— 检查
~/.n8n/credentials - 余额不足 —— 在 capsolver.com/dashboard 充值
- n8n 服务器与 CapSolver API 之间的网络问题
pageText 为空或包含错误页面
- HTTP 请求 URL 或表单字段名称可能与你的目标不匹配
- 检查
g-recaptcha-response字段名称 —— 一些网站使用不同的字段名称 - 在 HTTP 请求节点中启用
fullResponse: true以查看状态码
完整配置参考
n8n 工作流节点摘要
| 节点 | 类型 | 关键配置 |
|---|---|---|
| Webhook | n8n-nodes-base.webhook |
POST,路径:openclaw/scrape,responseMode:responseNode |
| 抓取网站 | n8n-nodes-capsolver.capSolver |
任务:ReCaptchaV2TaskProxyless |
| HTTP 请求 | n8n-nodes-base.httpRequest |
POST 到目标 URL,将 token 放入正文 |
| If | n8n-nodes-base.if |
检查 $json.data 是否包含 "recaptcha-success" |
| 编辑字段 | n8n-nodes-base.set |
pageText = $json.data |
| 保存结果 | n8n-nodes-base.executeCommand 或任何存储节点 |
持久化结果(文件、数据库、电子表格等) |
| 回应 Webhook | n8n-nodes-base.respondToWebhook |
JSON,continueOnFail: true |
CAPTCHA 任务类型
| CAPTCHA | n8n 节点操作 |
|---|---|
| reCAPTCHA v2(复选框) | reCAPTCHA v2 |
| reCAPTCHA v2(不可见) | reCAPTCHA v2 |
| reCAPTCHA v3 | reCAPTCHA v3 |
| Cloudflare Turnstile | Cloudflare Turnstile |
| Cloudflare Challenge | Cloudflare Challenge |
| GeeTest V3 | GeeTest V3 |
| GeeTest V4 | GeeTest V4 |
| DataDome | DataDome |
| AWS WAF | AWS WAF |
| MTCaptcha | MTCaptcha |
结论
OpenClaw + n8n + CapSolver 管道提供了一个生产级的数据提取设置,它:
- 在你的 AI 代理通过 webhook 请求时按需运行。
- 完全不需要浏览器或显示器。
- 完全隐藏 CAPTCHA 处理 —— 对你和 AI 代理都不可见。
AI 代理只需发出 "extract data" 命令并接收干净的页面内容。CapSolver 处理困难的部分,n8n 协调流程,而 OpenClaw 作为接口。
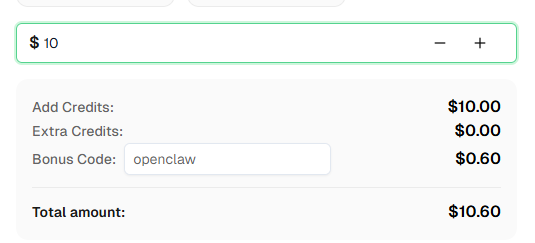
准备好了吗?在 CapSolver 注册 并使用优惠码 OPENCLAW 在首次充值时获得额外 6% 的奖励!
常见问题
我需要告诉 OpenClaw 关于 CapSolver 或 CAPTCHAs 吗?
不需要。OpenClaw 只是运行一个触发 HTTP 请求的脚本。n8n 处理其余部分。你的 AI 代理不知道 CAPTCHAs —— 它只是触发一个任务并读取结果。
我可以将其指向不同的网站吗?
可以,但你可能需要调整的不仅仅是 URL。每个网站提交 CAPTCHA token 的方式不同 —— 有些使用表单字段,有些使用 JSON 正文,有些使用头部或 Cookie。请参阅上面的“将工作流适应你的目标网站”部分,了解需要检查和更改的完整说明。
如果我的目标使用 Turnstile 而不是 reCAPTCHA 呢?
将 CapSolver 节点的任务类型更改为 AntiTurnstileTaskProxyless。然后检查你的目标网络请求以找到 Turnstile token 提交的位置 —— 它通常在名为 cf-turnstile-response 的隐藏表单字段中,但某些实现可能通过 JSON 正文、头部或 Cookie 传递它。
存储了多少结果?
这取决于你的存储选择。使用本地 JSON 文件,你可以保存任意数量。使用 Google Sheets 或数据库,每次运行都会无限追加一行。配置 Save Result 节点以匹配你的保留需求。
我可以使用 cron 作业而不是 OpenClaw 触发它吗?
可以 —— webhook 端点只是一个 HTTP POST。任何可以发出 HTTP 请求的东西都可以触发它:
bash
curl -s -X POST http://127.0.0.1:3005/webhook/openclaw/scrape每次提取的成本是多少?
每次运行需要一个 CapSolver 信用用于 CAPTCHA 解决。reCAPTCHA v2 是最便宜的类型之一。查看当前定价 capsolver.com。
OpenClaw 是免费的吗?
OpenClaw 是开源的,可以自托管。你需要为你的 AI 模型提供者和 CapSolver 的 CAPTCHA 解决支付 API 信用。

