Cách tích hợp giải pháp reCAPTCHA v2 trong Python cho khai thác dữ liệu

Anh Tuan
Data Science Expert
Giới thiệu
Khi internet phát triển, web scraping và khai thác dữ liệu được sử dụng rộng rãi để thu thập thông tin từ các trang web cho nhiều mục đích, bao gồm thông tin kinh doanh, tổng hợp nội dung và phân tích thị trường. Tuy nhiên, khi các bot trở nên tinh vi hơn, các trang web đã triển khai các công cụ để phân biệt giữa người dùng thực và các chương trình tự động. Một trong những công cụ như vậy là reCAPTCHA. Trong bài viết này, chúng ta sẽ khám phá reCAPTCHA là gì, các phiên bản khác nhau có sẵn và cách giải quyết các thách thức reCAPTCHA v2 bằng Capsolver trong Python. Cuối cùng, chúng ta sẽ đi qua một ví dụ mã đơn giản để tích hợp reCAPTCHA v2 vào dự án khai thác dữ liệu của bạn.
reCAPTCHA là gì?

reCAPTCHA là một dịch vụ miễn phí do Google phát triển giúp bảo vệ các trang web khỏi thư rác và lạm dụng bằng cách đảm bảo rằng một người thực (chứ không phải bot tự động) đang tương tác với trang web. Khi người dùng truy cập một trang web triển khai reCAPTCHA, họ có thể được yêu cầu hoàn thành một thử thách để xác minh rằng họ là người.
Các phiên bản reCAPTCHA khác nhau
Có một số phiên bản reCAPTCHA, mỗi phiên bản có điểm mạnh và trường hợp sử dụng riêng:
-
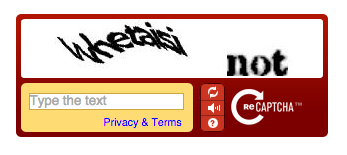
reCAPTCHA v1: Phiên bản sớm nhất, hiện đã lỗi thời. Nó yêu cầu người dùng sao chép văn bản bị bóp méo từ hình ảnh.
-
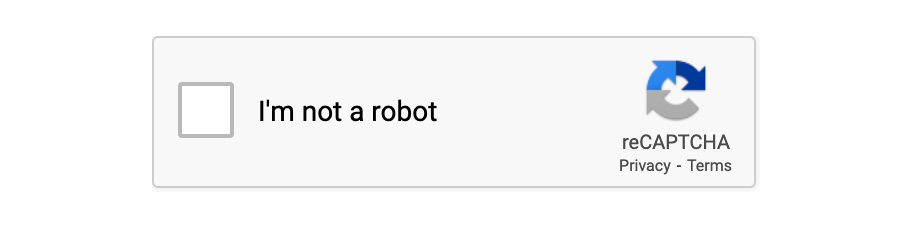
reCAPTCHA v2: Một phiên bản nâng cao hơn trình bày cho người dùng một hộp kiểm ("Tôi không phải là robot"). Nếu cần, nó cũng thách thức họ chọn một số hình ảnh (như đèn giao thông hoặc đường dành cho người đi bộ). Phiên bản này được sử dụng phổ biến nhất hiện nay.
-
reCAPTCHA v3: Phiên bản này phân tích hành vi của người dùng và tương tác với trang web để gán điểm từ 0 đến 1, trong đó 0 cho thấy một bot và 1 cho thấy một người. Nó mượt mà hơn đối với người dùng vì nó không yêu cầu các thử thách tương tác.

-
reCAPTCHA ẩn: Phiên bản này hoạt động ẩn danh và chỉ hiển thị các thử thách khi phát hiện hoạt động đáng ngờ. Nó được thiết kế để vô hình đối với người dùng hợp pháp.
Khai thác dữ liệu là gì?

Khai thác dữ liệu đề cập đến quy trình truy xuất dữ liệu có cấu trúc từ các nguồn không có cấu trúc như trang web, cơ sở dữ liệu hoặc các định dạng kỹ thuật số khác. Nó thường được sử dụng trong web scraping, nơi các chương trình tự động thu thập một lượng lớn thông tin từ các trang web để phân tích hoặc tổng hợp.
Các trường hợp sử dụng phổ biến cho khai thác dữ liệu
-
Nghiên cứu thị trường: Các công ty khai thác dữ liệu giá cả cạnh tranh và đánh giá của khách hàng để điều chỉnh chiến lược tiếp thị và bán hàng của họ.
-
Trí tuệ kinh doanh: Các tổ chức thu thập thông tin từ các báo cáo tài chính, tin tức và các nguồn lực khác để đưa ra quyết định kinh doanh sáng suốt.
-
Tổng hợp nội dung: Các trang web tổng hợp và hiển thị thông tin từ nhiều nguồn thường khai thác dữ liệu từ các trang web khác.
-
Phân tích SEO: Khai thác nội dung, từ khóa và thẻ meta từ các trang web cạnh tranh giúp tối ưu hóa chiến lược SEO.
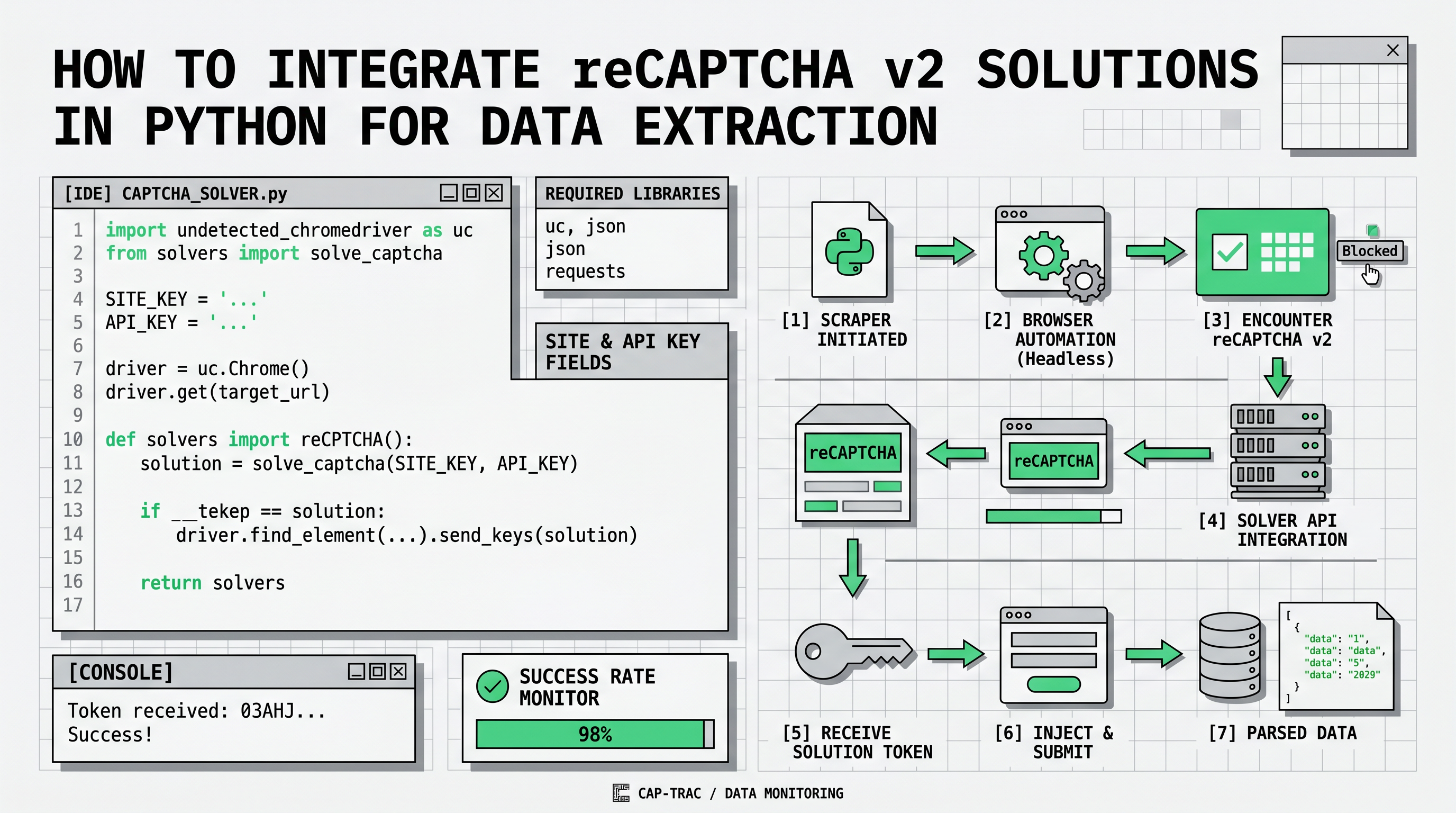
Tích hợp giải pháp reCAPTCHA v2 vào Python
Khi khai thác dữ liệu từ các trang web, bạn có thể gặp phải các thử thách reCAPTCHA. Điều này gây trở ngại cho việc thu thập thông tin tự động. May mắn thay, các công cụ như Capsolver có thể giải quyết các thách thức reCAPTCHA v2 một cách lập trình, cho phép bạn tiếp tục các tác vụ khai thác dữ liệu của mình.
Đây là một triển khai Python để giải quyết reCAPTCHA v2 bằng cách sử dụng gói Capsolver.
Các bước:
-
Cài đặt thư viện
capsolverbằng cách chạy:bashpip install capsolver -
Sử dụng mã Python sau để giải quyết thử thách reCAPTCHA v2:
python
import capsolver
# Xem xét sử dụng các biến môi trường cho thông tin nhạy cảm
capsolver.api_key = "Your Capsolver API Key"
PAGE_URL = "PAGE_URL"
PAGE_KEY = "PAGE_SITE_KEY"
def solve_recaptcha_v2(url,key):
solution = capsolver.solve({
"type": "ReCaptchaV2TaskProxyless",
"websiteURL": url,
"websiteKey":key,
})
return solution
def main():
print("Giải quyết reCaptcha v2")
solution = solve_recaptcha_v2(PAGE_URL, PAGE_KEY)
print("Giải pháp: ", solution)
if __name__ == "__main__":
main()Giải thích về mã
-
Thiết lập Capsolver API: Trong mã, chúng ta xác định
capsolver.api_keychứa khóa API Capsolver của bạn. Khóa này sẽ xác thực các yêu cầu của bạn đến dịch vụ Capsolver. -
Hàm giải quyết: Hàm
solve_recaptcha_v2chấp nhậnurlcủa trang vàsite_key(là khóa reCAPTCHA có trên trang web). Nó gửi yêu cầu đến Capsolver để giải quyết thử thách reCAPTCHA. -
Hàm chính: Hàm chính chạy trình giải quyết và in ra giải pháp.
-
Biến môi trường: Nên sử dụng các biến môi trường để lưu trữ thông tin nhạy cảm như khóa API để tăng cường bảo mật. Trong ví dụ trên, bạn nên thay thế
Your Capsolver API Key,PAGE_URLvàPAGE_SITE_KEYbằng các giá trị thực tế của bạn.
Mã thưởng
Nhận Mã thưởng cho các giải pháp captcha hàng đầu; CapSolver: scrape. Sau khi đổi mã, bạn sẽ nhận được thêm 5% tiền thưởng sau mỗi lần nạp tiền, Không giới hạn

Để biết thêm thông tin, hãy đọc bài viết này
Kết luận
reCAPTCHA là một công cụ cần thiết để bảo vệ các trang web khỏi bot, nhưng nó có thể tạo ra các thách thức cho mục đích tự động hợp pháp như khai thác dữ liệu. Sử dụng các công cụ như Capsolver cho phép các nhà phát triển giải quyết các thách thức reCAPTCHA v2 một cách lập trình, cho phép khai thác dữ liệu không bị gián đoạn. Luôn đảm bảo rằng các hoạt động khai thác dữ liệu của bạn tuân thủ điều khoản dịch vụ và hướng dẫn pháp lý của trang web để tránh bất kỳ vấn đề nào.
Bằng cách tích hợp giải pháp được cung cấp ở trên vào các dự án Python của bạn, bạn có thể tiếp tục thu thập dữ liệu có giá trị từ các trang web trong khi vượt qua các trở ngại reCAPTCHA.
Xem thêm
AutomationJul 29, 2026
Đánh giá Skyvern: Tự động hóa web thế hệ mới với Suy luận trực quan
Phân tích kiến trúc Kế hoạch viên-Đại lý-Người xác minh của Skyvern. Khám phá cách Skyvern đột phá việc trích xuất dữ liệu từ web và tự động điền form với khả năng tự phục hồi và tích hợp giải CAPTCHA mượt mà.
Web ScrapingJul 29, 2026
Cách thu thập dữ liệu bảng việc làm cho các đại lý tuyển dụng AI
Xây dựng một dòng dữ liệu bảng việc làm cho các đại lý tuyển dụng AI với giải CAPTCHA trên Indeed, LinkedIn và Glassdoor để ghép đôi ứng viên và phân tích thị trường.