O que é a Fundamentação de Dados na IA? Guia Prático para Grandes Modelos de Linguagem Confiáveis

Adélia Cruz
Neural Network Developer
Resumo
- A fundamentação de dados conecta as saídas da IA a fontes de informações confiáveis, atuais e relevantes.
- A fundamentação de dados reduz respostas não suportadas adicionando contexto no momento da inferência.
- Os dados de fundamentação podem incluir documentos, bancos de dados, resultados de pesquisa, catálogos, políticas e registros permitidos.
- RAG é uma técnica comum para fundamentação de dados, mas não é a disciplina completa.
- Uma forte fundamentação de dados requer verificações de qualidade, permissões, avaliação da recuperação, citações e monitoramento.
- Equipes que usam automação devem coletar dados de forma legal e lidar apenas com desafios CAPTCHA em fluxos autorizados.
Introdução
A fundamentação de dados é a prática que torna as respostas da IA mais precisas, atualizadas e verificáveis. Ela fornece ao modelo o contexto correto antes de responder. Este guia é para equipes de produtos, equipes de SEO, desenvolvedores e equipes de automação que estão construindo ferramentas de IA com base em LLMs. Você aprenderá o que significa fundamentação de dados na IA, como ela funciona, como se difere de RAG e fine-tuning, e como aplicá-la de forma responsável. O valor é prático: sistemas de IA fundamentados podem citar fontes, respeitar permissões e reduzir respostas obsoletas. Quando fluxos de automação legais se encontram com validação de tráfego ou desafios CAPTCHA, CapSolver pode apoiar processos de teste conformes.
Definição de Fundamentação de Dados
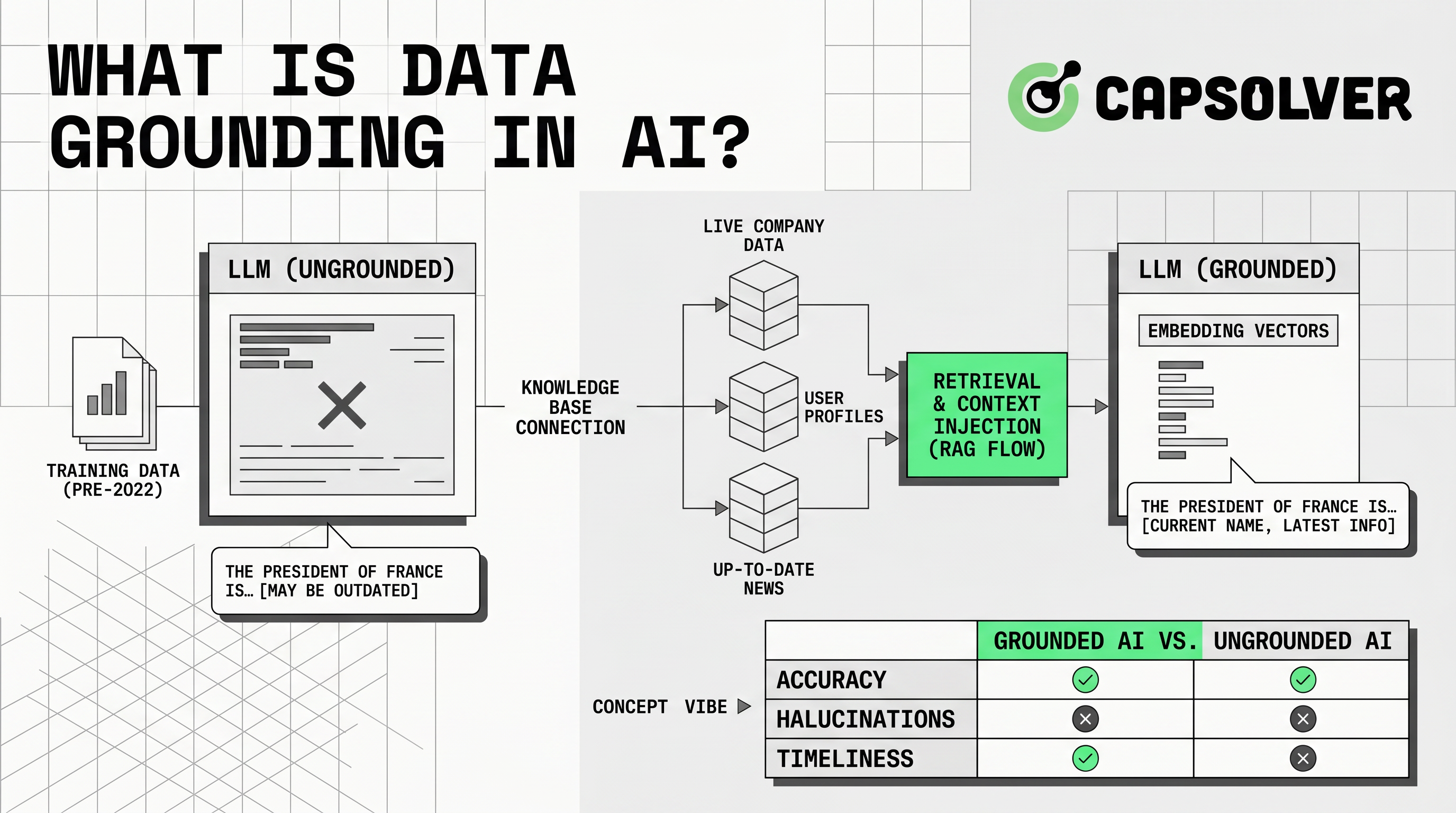
Fundamentação de dados significa ancorar as respostas da IA em contexto externo confiável. O aplicativo fornece informações relevantes a um modelo quando um usuário faz uma pergunta. A Microsoft define dados de fundamentação como informações fornecidas a um modelo de linguagem no momento da inferência para melhorar a precisão e a relevância por meio da orientação Azure Well-Architected.
A fundamentação de dados importa porque LLMs predizem linguagem. Eles não sabem automaticamente os seus preços mais recentes, políticas, documentos, registros de clientes ou dados de mercado público. Sem contexto confiável, uma resposta pode soar confiante enquanto ignora fatos. Com fundamentação de dados, o sistema pode recuperar material de origem, inseri-lo no prompt e pedir ao modelo que responda com base nesse material.
A fundamentação de dados da IA não é apenas um truque de prompt. É um padrão de design de dados. Inclui seleção de fontes, limpeza, indexação, controle de acesso, recuperação, geração de resposta, citação, avaliação e monitoramento.
Por que a Fundamentação de Dados Importa para a Precisão da IA
A fundamentação de dados melhora a confiabilidade da IA ao reduzir o espaço de respostas do modelo. A Google Cloud descreve a fundamentação empresarial como conectar modelos a informações da web, dados empresariais, bancos de dados, aplicações e fontes confiáveis para melhorar a completude e a precisão por meio da verdade empresarial da Google Cloud.
Isso é útil para domínios que mudam rapidamente. Estoque, políticas de suporte, documentação, preços e agendas de eventos mudam com frequência. Um modelo treinado há meses não pode saber todas as atualizações. A fundamentação de dados fornece ao aplicativo um caminho para informações atualizadas sem retrainar o modelo todos os dias.
A fundamentação de dados também ajuda as equipes a explicar as respostas. Citações, datas e campos de fonte apoiam QA, revisão de conformidade e confiança do usuário.
Como a Fundamentação de Dados Funciona
A fundamentação de dados funciona por meio de um fluxo de recuperação e geração. O sistema primeiro identifica quais fontes são confiáveis. Em seguida, prepara essas fontes para busca. Fontes comuns incluem centros de ajuda, manuais, APIs, bancos de dados SQL, índices vetoriais, feeds de produtos e páginas públicas aprovadas.
O próximo passo é ingestão. As equipes limpam documentos, removem duplicatas, padronizam metadados, dividem o conteúdo em fragmentos e armazenam-no em um índice de busca. O índice pode usar busca por palavras-chave, busca vetorial, busca híbrida ou busca por grafos. A Microsoft recomenda externalizar dados de fundamentação em um índice de busca quando melhora a recuperação, desempenho e proteção do sistema de origem por meio da design de dados de fundamentação da IA.
Quando um usuário faz uma pergunta, o sistema recupera registros relevantes. Ele filtra por permissões, frescor, idioma, região ou linha de produto. Em seguida, adiciona o contexto recuperado ao prompt do modelo. O modelo responde com base nesse contexto e pode retornar citações de fontes.
A fundamentação de dados tem sucesso quando a recuperação é precisa. Sistemas fortes medem relevância, fidelidade, latência e cobertura de fontes.
Resumo da Comparação
A fundamentação de dados se sobrepõe a vários métodos de IA. A tabela abaixo mostra a diferença prática.
| Método | Propósito Principal | Caso de Uso Ideal | Limitação Principal |
|---|---|---|---|
| Fundamentação de dados | Ancorar respostas em contexto confiável | Respostas atuais e com base em fontes | Requer recuperação e governança fortes |
| RAG | Recuperar documentos antes da geração | Perguntas e respostas de base de conhecimento e agentes de suporte | Pode recuperar contexto irrelevante ou obsoleto |
| Fine-tuning | Alterar o comportamento do modelo por meio de exemplos | Comportamento de estilo, formato ou domínio | Não é ideal para fatos em mudança |
| Engenharia de prompt | Guiar o comportamento com instruções | Tarefas pequenas e formatação de resposta | Não pode fornecer fatos ausentes sozinho |
| Guardrails | Impor políticas e controles de saída | Verificação de segurança, formato e conformidade | Não pode substituir contexto de fonte verificada |
Essa comparação mostra por que a fundamentação de dados é mais abrangente que o RAG. O RAG é um padrão de implementação comum. A fundamentação de dados é a disciplina completa de conectar a saída do modelo a evidências confiáveis.
Fontes Comuns de Fundamentação de Dados
A fundamentação de dados começa com a qualidade da fonte. As equipes devem classificar as fontes por autoridade, frescor, propriedade e nível de permissão.
Fontes internas geralmente fornecem o maior valor comercial. Essas incluem registros de CRM, tickets, políticas, sistemas de estoque, especificações de produtos e bases de conhecimento. Eles exigem controle de acesso rigoroso.
Fontes externas adicionam frescor e amplitude. Essas incluem documentação oficial, orientações governamentais, conjuntos de dados públicos, corpos de normas e dados de mercado reputáveis. A NIST afirma que seu Quadro de Gestão de Riscos de IA ajuda as organizações a gerenciar riscos para indivíduos, organizações e sociedade por meio da NIST AI RMF. Essas fontes são úteis ao escrever políticas para sistemas de IA confiáveis.
Dados da web pública podem apoiar monitoramento de mercado, pesquisa de SEO e análise competitiva. As equipes devem mantê-los legais e razoáveis. Devem respeitar os termos do site, limites de taxa, orientações aplicáveis de robôs e obrigações de privacidade. Os recursos do CapSolver sobre IA e automação e fluxos de automação são bons pontos de partida para processos responsáveis.
Um Fluxo de Produção para Fundamentação de Dados
A fundamentação de dados funciona melhor com um modelo operacional claro. Primeiro, defina o limite da resposta. Decida o que a IA pode responder, quais fontes ela pode usar e quando deve recusar ou escalonar.
Segundo, prepare os dados. Remova duplicatas, registros obsoletos, campos privados e texto ruidoso. Adicione metadados como proprietário, data, região, produto, idioma e nível de permissão. Isso torna a recuperação mais precisa.
Terceiro, projete a recuperação. Use busca por palavras-chave para termos exatos, busca vetorial para similaridade semântica e filtros para registros permitidos.
Quarto, avalie o desempenho. Crie um conjunto de testes de perguntas reais. Pontue a relevância da recuperação, a fidelidade da resposta, a precisão das citações e a latência. Revise casos extremos com especialistas em domínio. Não dependa apenas da confiança do modelo.
Quinto, monitore o desvio. A fundamentação de dados pode falhar quando documentos ficam obsoletos, índices quebram, permissões mudam ou o intuito do usuário muda. Sistemas críticos precisam de verificações automatizadas de frescor e caminhos de revisão humana.
Considerações de Conformidade e Segurança
A fundamentação de dados deve respeitar limites legais, privacidade e segurança. Acesso técnico não significa permissão. Sistemas de IA fundamentados devem evitar dados privados, restritos, sensíveis ou não autorizados, a menos que a organização tenha uma base legal clara e permissão do usuário.
Riscos de segurança também importam. A OWASP lista injeção de prompt, divulgação de informações sensíveis, agência excessiva e dependência excessiva entre os principais riscos para aplicações de LLM por meio da OWASP Top 10 for LLM Applications. A fundamentação de dados pode reduzir afirmações não suportadas, mas pode introduzir riscos se a recuperação aceitar conteúdo malicioso ou expor registros protegidos.
As equipes devem usar recuperação consciente de permissões. Devem sanitizar texto não confiável, registrar IDs de fonte em vez de registros sensíveis e separar dados por classificação.
Equipes de automação precisam de cuidado extra. A coleta de dados da web deve focar em dados públicos permitidos, taxas de solicitação razoáveis e propósitos comerciais documentados. Quando desafios CAPTCHA aparecem em QA, monitoramento ou fluxos de dados autorizados, as equipes devem tratá-los como parte da validação de tráfego. O artigo do CapSolver sobre coleta de dados da web pública e seu guia sobre desafios CAPTCHA podem ajudar as equipes a entender o contexto operacional.
Onde o CapSolver se Encaixa em Fluxos de IA Responsável
O CapSolver é relevante quando a fundamentação de dados depende de fluxos de automação legais. Algumas equipes coletam dados públicos para monitoramento de preços, verificação de SEO, verificação de anúncios, testes de QA ou pesquisa. Esses fluxos podem enfrentar desafios CAPTCHA durante navegação ou testes normais.
O CapSolver pode ajudar as equipes a lidar com esses desafios por meio de um serviço projetado para ambientes de automação. A recomendação é estreita e focada em conformidade. Use-o apenas onde você tenha autorização, respeite as regras aplicáveis e evite dados restritos ou sensíveis. As equipes podem revisar os produtos do CapSolver para entender cenários apoiados e correspondê-los a fluxos aprovados.
Resgate seu código promocional do CapSolver
Aumente seu orçamento de automação instantaneamente!
Use o código promocional CAP26 ao recarregar sua conta do CapSolver para obter um bônus adicional de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel do CapSolver
A fundamentação de dados e o tratamento de CAPTCHA não devem ser misturados casualmente. A camada de fundamentação decide quais evidências a IA pode usar. A camada de automação coleta ou verifica dados sob regras aprovadas. Manter essas camadas separadas facilita auditorias e reduz risco operacional.
Métricas Práticas para Sistemas de IA Fundamentados
A fundamentação de dados precisa de padrões de qualidade mensuráveis. A relevância da recuperação pergunta se o contexto recuperado responde à pergunta. Uma pontuação baixa significa que o modelo está trabalhando com evidências frágeis.
A fidelidade da resposta pergunta se a resposta permanece dentro das fontes recuperadas. Isso importa porque respostas fluentes ainda podem adicionar detalhes não suportados.
A precisão das citações verifica se cada fonte citada apoia a frase que segue. A frescor rastreia a idade do documento, o horário da atualização do índice e a frequência de atualização da fonte. A qualidade da recusa verifica se o sistema diz quando a evidência está ausente.
Conclusão e CTA
A fundamentação de dados é uma das formas mais práticas de tornar sistemas de IA mais confiáveis. Conecta respostas a contextos confiáveis, melhora a frescor, apoia citações e ajuda as equipes a gerenciar riscos. O RAG frequentemente faz parte da solução, mas a fundamentação de dados de grau de produção também precisa de dados limpos, permissões fortes, avaliação, monitoramento e práticas responsáveis de automação.
Se seu fluxo de IA depende de monitoramento de dados públicos, automação do navegador, testes de QA ou pesquisa, planeje a pipeline de dados com cuidado. Mantenha o acesso às fontes legal. Mantenha dados sensíveis protegidos. Revise as saídas antes de usá-las para decisões importantes. Para fluxos aprovados que enfrentam desafios CAPTCHA, considere avaliar CapSolver como parte de uma pilha de automação conforme.
Perguntas Frequentes
O que é fundamentação de dados na IA?
A fundamentação de dados é o processo de conectar respostas da IA a contexto confiável. O contexto pode vir de documentos, bancos de dados, APIs, índices de busca ou fontes públicas aprovadas. Ajuda o modelo a responder com base em evidências em vez de depender apenas dos dados de treinamento.
A fundamentação de dados é a mesma que RAG?
Não. RAG é uma forma comum de implementar a fundamentação de dados. A fundamentação de dados é mais abrangente. Inclui governança de fontes, indexação, permissões, avaliação da recuperação, citações, monitoramento e regras de escalonamento.
Por que a fundamentação de dados reduz respostas não suportadas da IA?
A fundamentação de dados reduz respostas não suportadas porque fornece ao modelo evidências relevantes no momento da inferência. O modelo pode responder com base no contexto atual em vez de preencher lacunas com padrões estatísticos.
Quais dados devem ser usados para fundamentação de dados para LLMs?
Use dados que sejam precisos, permitidos, atuais e relevantes. Boas exemplos incluem documentação oficial, registros de produtos, políticas de suporte, bases de conhecimento, conjuntos de dados públicos e bancos de dados empresariais aprovados. Evite dados privados ou restritos sem autorização adequada.
Como as equipes devem aplicar a fundamentação de dados de forma responsável?
As equipes devem definir regras de fonte, impor controles de acesso, monitorar a qualidade da recuperação e revisar saídas de alto impacto. Equipes de automação devem coletar dados de forma legal, respeitar as regras do site e usar serviços relacionados a CAPTCHA apenas em fluxos autorizados.