Como raspar vagas de emprego sem ser bloqueado

Lucas Mitchell
Automation Engineer
TL;Dr:
- Rotacionar proxies residenciais: Use IPs residenciais de alta qualidade para evitar ser marcado por grandes placas de emprego ou plataformas de networking profissional.
- Impersonar impressões digitais de navegador: Alinhe sua impressão digital TLS e cabeçalhos HTTP a perfis de navegador reais usando ferramentas como
curl_cffi. - Gerenciar CAPTCHAs automaticamente: Integre um solucionador confiável como CapSolver para lidar com desafios Cloudflare Turnstile e reCAPTCHA.
- Respeitar o robots.txt e os limites de taxa: Implemente atrasos aleatórios e siga diretrizes éticas de scraping para manter o acesso a longo prazo.
Introdução
O scraping de vagas de emprego tornou-se uma peça-chave para agências de recrutamento, pesquisadores de mercado e agregadores de empregos. No entanto, grandes placas de emprego implementaram medidas de segurança sofisticadas que podem interromper sua coleta de dados em segundos. Se você já enfrentou banimentos de IP imediatos ou ciclos infinitos de verificação ao tentar coletar anúncios de emprego, você não está sozinho. O desafio está em tornar seus scripts automatizados indistinguíveis do comportamento de navegação humana. Este guia fornece um plano técnico abrangente para ajudá-lo a coletar vagas de emprego de forma eficaz, mantendo um perfil de detecção baixo.
Por que as placas de emprego bloqueiam seus scrapers
Plataformas de empregos e sites de networking profissional investem pesado em segurança para proteger seus dados proprietários e garantir a estabilidade do site. Eles usam principalmente quatro camadas de detecção para identificar e bloquear scrapers.
Reputação de IP e limitação de taxa
A maioria das placas de emprego rastreia o número de solicitações vindas de um único endereço IP. Se você ultrapassar um certo limite, seu IP é temporariamente ou permanentemente bloqueado. IPs de datacenter são particularmente vulneráveis, pois são facilmente identificados como pertencentes a centros de dados, em vez de usuários reais.
Impressão digital do navegador e TLS
Sistemas antibot modernos como Cloudflare e DataDome analisam além do seu User-Agent. Eles analisam o handshake TLS (Transport Layer Security), verificando suites de criptografia e extensões específicas. Se seu script Python usar a biblioteca requests padrão, sua impressão digital JA3 será imediatamente sinalizada como um robô.
Análise de comportamento
Os usuários humanos não clicam em links a cada 0,5 segundos ou navegam em padrões linearmente perfeitos. Scrapers que exibem comportamento robótico, como intervalos de solicitação fixos ou carregamento ausente de CSS/imagens, são rapidamente marcados por motores de análise de comportamento.
CAPTCHAs e desafios JavaScript
Quando um site suspeita, mas não tem certeza, ele dispara um desafio. Isso pode ser uma verificação simples de execução JavaScript ou um CAPTCHA complexo. Sem uma maneira automatizada de resolver esses desafios, seu fluxo de trabalho de scraping será interrompido por completo.
Técnicas Essenciais para Scraping de Empregos sem Detecção
Para construir um scraper resistente, você deve abordar cada camada de detecção com contra-medidas técnicas específicas.
1. Implementação de rotação de proxies residenciais
Usar um único IP é a forma mais rápida de ser bloqueado. Em vez disso, você deve usar um pool de proxies residenciais. Ao contrário dos IPs de datacenter, os IPs residenciais são atribuídos por provedores de internet (ISP) a casas reais, tornando-os muito mais difíceis de distinguir do tráfego legítimo.
| Tipo de Proxy | Risco de Detecção | Custo | Caso de Uso Ideal |
|---|---|---|---|
| Datacenter | Alto | Baixo | Sites de baixa segurança, testes |
| Residencial | Baixo | Médio | Placas de emprego e motores de busca de alta segurança |
| Móvel (4G/5G) | Muito Baixo | Alto | Sistemas anti-bot altamente agressivos |
Ao escanear vagas de emprego, certifique-se de que seu provedor de proxy suporte rotação automática. Isso garante que cada solicitação ou sessão venha de uma localização geográfica e IP diferentes.
2. Dominando a impressão digital TLS
Como mencionado anteriormente, bibliotecas padrão como requests ou urllib têm impressões digitais TLS distintas. Para resolver isso, você deve usar curl_cffi, que permite que seu script imite o handshake TLS de um navegador real, como Chrome ou Firefox.
python
from curl_cffi import requests
# Imitando a impressão digital TLS do Chrome 120
response = requests.get(
"https://www.target-job-board.com/jobs?q=software+engineer",
impersonate="chrome120",
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
}
)
print(response.status_code)Ao alinhar seu User-Agent com o perfil TLS correspondente, você reduz significativamente as chances de ser bloqueado por Cloudflare ou Akamai.
3. Lidando com CAPTCHAs com CapSolver
Mesmo com cabeçalhos e proxies perfeitos, você eventualmente encontrará um desafio. Placas de emprego frequentemente usam Cloudflare Turnstile ou reCAPTCHA para verificar usuários. Resolver manualmente esses é impossível em escala. É aí que CapSolver se torna parte essencial da sua pilha de automação.
CapSolver fornece uma API sem esforço para resolver vários tipos de CAPTCHA. Por exemplo, se você encontrar um desafio Cloudflare Turnstile ao usar uma API de busca de empregos ou ao escanear plataformas de emprego principais, você pode usar a seguinte implementação oficial:
python
import requests
import time
api_key = "SUA_CHAVE_API_CAPSOLVER"
site_key = "0x4XXXXXXXXXXXXXXXXX" # Encontrado no HTML do site alvo
site_url = "https://www.target-job-board.com"
def solve_turnstile():
payload = {
"clientKey": api_key,
"task": {
"type": 'AntiTurnstileTaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
task_id = res.json().get("taskId")
if not task_id:
return None
while True:
time.sleep(1)
result_res = requests.post("https://api.capsolver.com/getTaskResult", json={"clientKey": api_key, "taskId": task_id})
result = result_res.json()
if result.get("status") == "ready":
return result.get("solution", {}).get('token')
if result.get("status") == "failed":
return None
token = solve_turnstile()Integrar isso ao seu fluxo de trabalho garante que seu scraper possa continuar sua tarefa sem intervenção humana, mantendo efetivamente a disponibilidade da sua pipeline de dados.
Resgate seu código de bônus do CapSolver
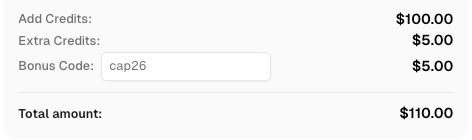
Aumente seu orçamento de automação instantaneamente!
Use o código de bônus CAP26 ao recarregar sua conta do CapSolver para obter um bônus adicional de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel do CapSolver
4. Otimizando cabeçalhos e referências de solicitação
Um erro comum é enviar solicitações "naked". Navegadores reais sempre enviam um cabeçalho Referer e vários cabeçalhos Sec-CH-UA (Client Hints). Ao escanear vagas de emprego, sempre defina o referer para a página inicial do site ou uma página de resultados anteriores.
- User-Agent: Use uma string recente e popular.
- Referer:
https://www.google.com/ou o próprio domínio do site. - Accept-Encoding:
gzip, deflate, br(certifique-se de que seu código possa descomprimir esses).
Resumo da comparação: Estratégias de scraping
| Estratégia | Eficácia | Esforço de implementação | Recomendado para |
|---|---|---|---|
| Python Básico Requests | Muito Baixo | Baixo | Blogs pessoais não protegidos |
| Navegadores sem cabeça (Selenium) | Médio | Médio | Sites com JavaScript pesado |
| Navegadores de stealth + proxies | Alto | Alto | Plataformas de emprego de alta segurança |
| API de scraping web | Muito Alto | Baixo | Extração de dados de empregos em escala empresarial |
Considerações Éticas e Legais
Embora o sucesso técnico seja importante, você também deve priorizar o scraping ético. Sempre verifique o arquivo robots.txt do site e os termos de serviço. De acordo com as diretrizes do Conselho Mundial da Web (W3C), a coleta ética de dados envolve respeitar a saúde do servidor de destino, evitando sobrecarregá-lo com solicitações excessivas. Além disso, a Electronic Frontier Foundation destaca que o scraping de dados publicamente disponíveis geralmente é protegido, mas você deve evitar acessar informações de usuários privados ou resolver paredes de login sem permissão.
Conclusão
O sucesso ao coletar vagas de emprego sem ser bloqueado exige uma abordagem de múltiplas camadas. Combinando rotação de proxies residenciais, impressão digital TLS e resolução automática de CAPTCHA via CapSolver, você pode construir um sistema robusto que imite o comportamento humano. Lembre-se de que o cenário de scraping da web está em constante evolução; manter-se atualizado com as últimas tendências em gestão de segurança é essencial para manter sua vantagem competitiva.
Perguntas Frequentes
1. É legal fazer scraping de anúncios de emprego?
Geralmente, o scraping de anúncios de emprego disponíveis publicamente é legal em muitas jurisdições, desde que você não viole a Lei de Fraude e Acesso Computacional (CFAA) ou leis de direitos autorais. Sempre consulte um advogado para casos específicos.
2. Quão frequentemente devo rotacionar meus proxies?
Para sites de alta segurança, é melhor rotacionar seu IP a cada solicitação ou a cada alguns minutos para evitar detecção de padrões.
3. Posso escanear sites de networking profissional sem uma conta?
Muitas plataformas profissionais são altamente restritivas. Embora alguns perfis públicos e vagas sejam visíveis, a maioria dos dados está atrás de uma parede de login. O scraping atrás de um login carrega riscos legais e técnicos maiores.
4. Por que meu navegador sem cabeça ainda está sendo pego?
Navegadores sem cabeça padrão como Puppeteer ou Selenium deixam "impressões digitais" como navigator.webdriver = true. Você deve usar plugins como stealth para ocultar essas propriedades.
5. Qual é a melhor forma de evitar banimentos de IP?
A forma mais eficaz de evitar banimentos de IP é uma combinação de proxies residenciais e intervalos de solicitação aleatórios (jitter).