Automatizando a resolução de CAPTCHA em navegadores sem cabeça: Guia completo do fluxo de trabalho

Emma Foster
Machine Learning Engineer

TL;Dr:
- Propósito: Automatizar a resolução de CAPTCHA em ambientes de navegadores headless para automação eficiente de web.
- Principais Etapas: Configuração do ambiente, integração da API (CapSolver), criação de tarefas, recuperação de resultados e integração nos scripts de automação.
- Benefícios: Reduz a intervenção manual, melhora a confiabilidade da automação e escala os esforços de coleta de dados.
- CapSolver: Um serviço recomendado para resolução de CAPTCHA confiável e eficiente, oferecendo vários tipos de tarefa e opções de integração.
- Otimização: Implementar proxies, gerenciar a frequência de solicitações e lidar com erros para automação robusta.
Introdução
A automação da web frequentemente enfrenta CAPTCHAs, projetados para diferenciar usuários humanos de bots automatizados. Ao operar navegadores headless para tarefas como raspagem de dados, monitoramento ou testes, esses desafios podem interromper o progresso. Este guia fornece um fluxo de trabalho completo e passo a passo para automatizar a resolução de CAPTCHA em navegadores headless, garantindo que seus processos de automação funcionem suavemente e eficientemente. Cobriremos tudo, desde a configuração do seu ambiente até a integração de um serviço confiável de resolução de CAPTCHA como CapSolver, processamento de resultados e solução de problemas comuns. Ao final deste tutorial, você terá o conhecimento e as ferramentas para gerenciar efetivamente CAPTCHAs em seus projetos de navegadores headless, melhorando a confiabilidade e a escalabilidade dos seus esforços de automação da web.
Compreendendo Navegadores Headless e CAPTCHAs
Navegadores headless são navegadores sem interface gráfica, comumente usados para testes automatizados, raspagem de dados e renderização do lado do servidor. Exemplos populares incluem Puppeteer para Chrome e Playwright para vários navegadores. Embora poderosos, sua natureza automatizada os torna suscetíveis à detecção por sites que utilizam CAPTCHAs. CAPTCHAs servem como uma camada de segurança crítica, impedindo o acesso automatizado e o uso indevido de recursos da web. O desafio está em integrar uma solução que possa resolver esses quebra-cabeças de forma confiável sem comprometer a eficiência das operações do seu navegador headless. É aí que a automação da resolução de CAPTCHA em navegadores headless se torna essencial.
Por que CAPTCHAs Aparecem em Navegadores Headless
Sites usam várias técnicas para detectar atividade automatizada, como analisar impressões digitais do navegador, padrões de comportamento do usuário e endereços IP. Quando esses sistemas identificam um navegador headless como não humano, um CAPTCHA é frequentemente apresentado. Este mecanismo é projetado para proteger contra spam, injeção de credenciais e extração de dados. Para uma automação eficaz, uma estratégia robusta para automatizar a resolução de CAPTCHA em navegadores headless é indispensável.
Fluxo de Trabalho Passo a Passo para Automatizar a Resolução de CAPTCHA
Esta seção descreve o processo completo para integrar um serviço de resolução de CAPTCHA em sua automação de navegador headless. Usaremos o CapSolver como exemplo devido à sua API abrangente e suporte a vários tipos de CAPTCHA.
Etapa 1: Preparação do Ambiente
Antes de começar, certifique-se de que seu ambiente de desenvolvimento esteja configurado com as ferramentas necessárias. Isso envolve a instalação de uma biblioteca de navegador headless e um ambiente Python para interagir com a API de resolução de CAPTCHA.
Propósito: Estabelecer uma base funcional para executar scripts de navegador headless e interagir com serviços externos.
Operação:
- Instalar Python: Certifique-se de que o Python 3.x esteja instalado no seu sistema.
- Instalar Biblioteca de Navegador Headless: Escolha entre Puppeteer (para Node.js) ou Playwright (suporta Python, Node.js, Java, .NET). Para este guia, assumiremos um ambiente Python com Playwright.
bash
pip install playwright playwright install - Instalar Biblioteca Requests: Esta será usada para interagir com a API do CapSolver.
bash
pip install requests - Obter Chave de API do CapSolver: Registre-se no site do CapSolver e obtenha sua chave de API no painel. Esta chave é crucial para autenticar suas solicitações ao serviço de resolução de CAPTCHA.
Precauções: Sempre mantenha sua chave de API segura e evite codificá-la diretamente em repositórios públicos. Use variáveis de ambiente para práticas de segurança melhores.
Etapa 2: Integração da API do CapSolver
Com seu ambiente pronto, a próxima etapa é integrar a API do CapSolver em seu script de automação. Isso envolve enviar detalhes de CAPTCHA para o CapSolver e receber o token resolvido.
Propósito: Enviar desafios de CAPTCHA para o CapSolver de forma programática e obter suas soluções.
Operação: A integração envolve geralmente duas chamadas de API principais: createTask para enviar o CAPTCHA e getTaskResult para recuperar a solução. Abaixo está um exemplo em Python usando a biblioteca requests.
python
import requests
import time
# TODO: defina sua configuração
api_key = "SUA_CHAVE_DE_API_DO_CAPSOLVER" # Substitua pela sua chave de API do CapSolver
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # Chave de site de exemplo para demonstração do reCAPTCHA v2
site_url = "https://www.google.com/recaptcha/api2/demo" # URL de exemplo de página com demonstração do reCAPTCHA v2
def solve_recaptcha_v2_capsolver():
print("Criando tarefa de CAPTCHA...")
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess', # Usando proxy integrado ao servidor
"websiteKey": site_key,
"websiteURL": site_url
}
}
try:
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print(f"Falha ao criar tarefa: {res.text}")
return None
print(f"Tarefa criada com ID: {task_id}. Aguardando resultado...")
while True:
time.sleep(3) # Aguardar 3 segundos antes de verificar o resultado
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
print("CAPTCHA resolvido com sucesso!")
return resp.get("solution", {}).get('gRecaptchaResponse')
elif status == "processing":
print("CAPTCHA ainda em processamento...")
elif status == "failed" or resp.get("errorId"):
print(f"Falha na resolução do CAPTCHA! Resposta: {res.text}")
return None
except requests.exceptions.RequestException as e:
print(f"Falha na solicitação da API: {e}")
return None
# Exemplo de uso em um script de navegador headless (conceitual)
# from playwright.sync_api import sync_playwright
# with sync_playwright() as p:
# browser = p.chromium.launch(headless=True)
# page = browser.new_page()
# page.goto(site_url)
# # Disparar CAPTCHA (ex.: clicando em um botão ou navegando para uma página protegida)
# # Quando o CAPTCHA aparecer, chame o solucionador
# captcha_token = solve_recaptcha_v2_capsolver()
# if captcha_token:
# print(f"Token CAPTCHA recebido: {captcha_token[:30]}...")
# # Injetar o token na página (ex.: via JavaScript ou preenchendo um campo de entrada oculto)
# # page.evaluate(f"document.getElementById(\'g-recaptcha-response\').value = \'{captcha_token}\';")
# # Submeter o formulário
# else:
# print("Falha em obter o token CAPTCHA.")
# browser.close()Precauções: Ajuste a duração de time.sleep() com base no tempo típico de resolução do tipo de CAPTCHA. Uma varredura excessiva pode levar a limitação de taxa. Sempre trate erros de API e problemas de rede de forma elegante.
Etapa 3: Tratando o Token de CAPTCHA Resolvido
Assim que o CapSolver retornar uma solução, você precisará injetar esse token de volta em sua sessão de navegador headless para completar o desafio do CAPTCHA.
Propósito: Submeter a solução do CAPTCHA ao site-alvo e prosseguir com a automação.
Operação: O método de injeção do token depende do tipo de CAPTCHA e como o site espera a solução. Para o reCAPTCHA v2, o token geralmente é colocado em um campo de texto oculto com o ID g-recaptcha-response.
python
# ... (código anterior para a função solve_recaptcha_v2_capsolver)
from playwright.sync_api import sync_playwright
# Exemplo de uso
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto(site_url)
# Aguardar o iframe do reCAPTCHA carregar e ficar visível (ajuste os seletores conforme necessário)
page.wait_for_selector("iframe[title='reCAPTCHA challenge']", timeout=30000)
captcha_token = solve_recaptcha_v2_capsolver()
if captcha_token:
print(f"Token CAPTCHA recebido: {captcha_token[:30]}...")
# Injetar o token no campo de entrada oculto
page.evaluate(f"document.getElementById('g-recaptcha-response').value = '{captcha_token}';")
print("Token CAPTCHA injetado. Tentando submeter o formulário...")
# Supondo que haja um botão de submissão, clique nele. Ajuste o seletor conforme necessário.
# page.click("button[type='submit']")
# Ou, se o formulário for submetido automaticamente após a injeção do token, não é necessário clicar.
page.wait_for_timeout(5000) # Dê algum tempo para o formulário processar
else:
print("Falha em obter o token CAPTCHA. Automação interrompida.")
browser.close()Precauções: Certifique-se de que seus seletores para o iframe do CAPTCHA e o campo de entrada oculto sejam precisos. Os sites podem mudar sua estrutura, exigindo atualizações nos seus seletores. Sempre verifique se a submissão do formulário foi bem-sucedida após injetar o token.
Solução de Problemas Comuns
Mesmo com uma configuração robusta, você pode enfrentar problemas. Aqui estão alguns problemas comuns e suas soluções ao automatizar a resolução de CAPTCHA em navegadores headless.
Problema: taskId Não Retornado ou Erros de API
Problema: A chamada da API createTask não retorna um taskId, ou retorna uma mensagem de erro.
Solução:
- Verificar Chave de API: Certifique-se de que sua
api_keyesteja correta e tenha saldo suficiente. - Revisar Payload da Solicitação: Certifique-se de que
websiteURL,websiteKeyetypeestejam corretamente especificados de acordo com a documentação da API do CapSolver para o tipo de CAPTCHA específico. - Problemas de Rede: Verifique sua conexão com a internet e certifique-se de que o endpoint da API do CapSolver seja acessível.
Problema: Token de CAPTCHA Inválido ou Rejeitado
Problema: O CapSolver retorna um token, mas o site-alvo o rejeita.
Solução:
- Verificar
websiteKeyewebsiteURLcorretos: Esses parâmetros devem corresponder exatamente aos do site-alvo. Mesmos pequenos desvios podem causar rejeição. - Uso de Proxy: Se o site for restrito por geolocalização ou tiver verificações rigorosas de IP, use um proxy com seu
ReCaptchaV2Task(ex.:ReCaptchaV2Taskcom parâmetroproxy) que corresponda ao endereço IP do navegador headless. O CapSolver oferece opções de proxy. - Consistência do User-Agent: Certifique-se de que a string do User-Agent usada pelo seu navegador headless corresponda à que o CapSolver pode usar internamente ou à que o site espera. Alguns CAPTCHAs avançados verificam a consistência.
- Mudanças no Site: Os sites atualizam frequentemente suas implementações de CAPTCHA. A
websiteKeyou outros parâmetros podem ter mudado. Use a Extensão do CapSolver para obter automaticamente os parâmetros necessários se você estiver com dúvidas.
Problema: Detecção de Navegador Headless
Problema: Mesmo resolvendo CAPTCHAs, o site ainda detecta o navegador headless e bloqueia o acesso.
Solução:
- Técnicas de Stealth: Implemente plugins ou configurações de stealth para seu navegador headless (ex.:
puppeteer-extra-plugin-stealthpara Puppeteer, ou configurações semelhantes para Playwright) para imitar o comportamento de um navegador humano. Isso inclui modificar o User-Agent, desativar flags de automação e lidar com propriedades comuns do navegador que revelam automação (consulte MDN Web Docs sobre Navegadores Headless). - Atrasos Realistas: Introduza atrasos semelhantes aos humanos entre as ações. Ações rápidas e consistentes são um forte indicador de automação.
- Gerenciamento de Cookies e Armazenamento Local: Mantenha e reutilize cookies e armazenamento local entre sessões para manter um perfil de navegação consistente.
- Cabeçalhos de Referer: Certifique-se de que os cabeçalhos de referer apropriados sejam enviados com as solicitações.
Sugestões de Otimização de Desempenho
Otimizar seu fluxo de resolução de CAPTCHA é crucial para automação eficiente e escalável. Considere estas sugestões para automatizar a resolução de CAPTCHA em navegadores headless.
1. Gerenciamento de Proxy
Usar proxies de alta qualidade é vital. Proxies residenciais ou móveis geralmente são mais eficazes do que proxies de datacenter, pois parecem tráfego legítimo de usuários. Gire seus proxies para evitar bloqueios de IP e distribua suas solicitações entre diferentes endereços IP. O CapSolver suporta integração de proxy diretamente dentro de sua API de criação de tarefa.
2. Concorrência e Frequência de Solicitações
Equilibre a concorrência com a frequência de solicitações. Embora executar múltiplas instâncias de navegadores headless simultaneamente possa acelerar tarefas, enviar muitas solicitações de resolução de CAPTCHA muito rapidamente pode levar a limitação de taxa da serviço de CAPTCHA ou detecção pelo site-alvo. Implemente backoff exponencial para tentativas e atrasos dinâmicos com base no comportamento observado do site.
3. Cache e Reutilização
Para certos tipos de CAPTCHA ou sessões de site, soluções podem ser reutilizáveis por um curto período. Se aplicável, cache tokens de CAPTCHA válidos e reutilize-os dentro de seu período de validade para reduzir solicitações redundantes e custos.
Resumo da Comparação: Métodos de Resolução de CAPTCHA
Escolher o método correto de resolução de CAPTCHA depende de vários fatores, incluindo custo, confiabilidade e complexidade. Aqui está uma comparação das abordagens comuns:
| Funcionalidade | Resolução Manual | Resolução Baseada em OCR | Resolução Baseada em API (ex.: CapSolver) | Aprendizado de Máquina (Auto-Hospedado) |
|---|---|---|---|---|
| Confiabilidade | Alta (humano) | Baixa a Média | Alta | Média a Alta |
| Velocidade | Variável | Rápida | Rápida | Rápida |
| Custo | Mão de obra humana | Baixo (configuração) | Taxa por resolução | Alto (configuração, manutenção) |
| Complexidade | Nenhum | Alto (desenvolvimento) | Baixo (integração de API) | Muito alto (conhecimento em ML) |
| Manutenção | Nenhum | Alto | Baixo | Muito alto |
| Tipos de CAPTCHA | Todos | Imagem simples | Todos os principais tipos | Tipos específicos (treinado em) |
| Escalabilidade | Baixo | Médio | Alto | Médio |
Soluções baseadas em API, como a CapSolver, oferecem um equilíbrio entre alta confiabilidade, velocidade e facilidade de integração, sendo ideais para automatizar a resolução de CAPTCHA em navegadores headless sem sobrecarga de desenvolvimento significativa.
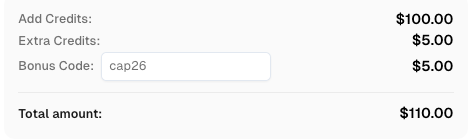
Use o código
CAP26ao se cadastrar no CapSolver para receber créditos extras!
Conclusão
Automatizar a resolução de CAPTCHA em navegadores headless é uma habilidade crítica para quem está envolvido em automação da web. Ao seguir o fluxo de trabalho estruturado descrito neste guia – desde a configuração do ambiente e integração de API até o tratamento de resultados e solução de problemas – você pode melhorar significativamente a eficiência e a robustez das suas tarefas automatizadas. Serviços como a CapSolver oferecem uma forma poderosa e confiável de superar desafios de CAPTCHA, permitindo que seus navegadores headless operem sem interrupções. Lembre-se de priorizar considerações éticas e seguir os termos de serviço dos sites ao implementar soluções de automação. Para mais insights sobre desafios de automação da web, explore artigos como Por que a automação da web falha constantemente com CAPTCHA e Como raspar sites protegidos por CAPTCHA.
Perguntas Frequentes (FAQ)
Q1: É legal automatizar a resolução de CAPTCHA?
A1: A legalidade de automatizar a resolução de CAPTCHA em navegadores headless depende fortemente dos termos de serviço do site e das regulamentações locais. Embora a própria ação de resolver um CAPTCHA não seja intrinsecamente ilegal, usar automação para acessar conteúdo ou realizar ações que violem as políticas de um site pode ser. Sempre revise os termos de serviço dos sites com os quais você interage.
Q2: Quais tipos de CAPTCHAs a CapSolver pode lidar?
A2: A CapSolver suporta uma ampla gama de tipos de CAPTCHA, incluindo reCAPTCHA v2, reCAPTCHA v3, ImageToText e vários CAPTCHAs corporativos. Essa ampla suporte a torna uma ferramenta versátil para automatizar a resolução de CAPTCHA em navegadores headless em diferentes plataformas.
Q3: Como posso reduzir o custo da resolução de CAPTCHA?
A3: Para reduzir os custos, otimize seus scripts de automação para solicitar soluções de CAPTCHA apenas quando absolutamente necessárias. Implemente cache para tokens reutilizáveis, use intervalos eficientes para verificação de resultados e certifique-se de que suas técnicas de disfarce de navegador headless sejam robustas para minimizar a geração de CAPTCHA desde o início. Monitore regularmente o uso da CapSolver e explore seus planos de preços.
Q4: Posso usar a CapSolver com outros idiomas de programação?
A4: Sim, a CapSolver fornece uma API RESTful, o que significa que pode ser integrada com praticamente qualquer linguagem de programação capaz de fazer solicitações HTTP. Embora este guia tenha usado Python, você pode facilmente adaptar os conceitos para Node.js, Java, C#, Go ou outras linguagens. Consulte a documentação da API CapSolver para exemplos específicos da linguagem ou especificações gerais da API.
Q5: Quais são as melhores práticas para manter a automação da web ética?
A5: A automação da web ética envolve respeitar os termos de serviço dos sites, evitar taxas de solicitação excessivas que possam sobrecarregar servidores e não envolver-se em atividades que possam ser consideradas maliciosas ou prejudiciais. Sempre busque transparência quando apropriado e considere o impacto da sua automação nos recursos e na experiência do usuário do site. Foque em casos de uso legítimos, como coleta de dados para pesquisa ou uso pessoal, em vez de atividades disruptivas.