ReCAPTCHA na Raspagem de E-commerce: Um Guia Priorizando a Conformidade

Adélia Cruz
Neural Network Developer
TL;DR
- O reCAPTCHA aparece quando os sites de comércio eletrônico precisam de verificação de confiança mais rigorosa.
- Trate o recaptcha como um sinal de fluxo de trabalho, não apenas como um quebra-cabeça.
- Verifique permissões, robots.txt, termos e escopo de dados primeiro.
- Reduza desafios evitáveis com ritmo e sessões estáveis.
- Use APIs oficiais ou feeds sempre que existirem.
- Use o CapSolver apenas para automação legítima e trabalho com dados permitidos.
- Mantenha logs, limites de taxa e regras de escalonamento para cada raspador.
Introdução
O reCAPTCHA no scraping de comércio eletrônico deve ser tratado com um processo baseado em conformidade. A resposta correta não é um scraping mais agressivo. É um fluxo mais limpo que respeita permissões, reduz tráfego ruidoso e usa um passo documentado de resolução apenas quando permitido. Este guia é para engenheiros de dados, equipes de SEO, analistas de preços e equipes de crescimento que coletam dados de comércio eletrônico público de forma responsável. Ele explica por que o reCAPTCHA aparece, quando reduzir a velocidade e quando o CapSolver se encaixa em um processo legítimo.
Por que os raspadores de comércio eletrônico encontram reCAPTCHA
O reCAPTCHA aparece porque os sites de comércio eletrônico protegem fluxos valiosos de clientes e negócios. Páginas de produtos, páginas de busca, carrinhos e logins carregam risco comercial. O Google descreve o reCAPTCHA como um serviço que protege sites contra spam e abuso usando análise de risco avançada para distinguir humanos de robôs por meio de sinais e pontuações documentação do reCAPTCHA do Google.
As equipes de comércio eletrônico adicionam reCAPTCHA porque o tráfego automatizado é agora comum. Thales e Imperva relataram que o tráfego automatizado atingiu 51% do tráfego da web em 2024. Eles também relataram que atividades automatizadas prejudiciais representaram 37% do tráfego da internet, enquanto ataques direcionados por API atingiram 44% do tráfego de robôs avançados Relatório de Botões Maliciosos de 2025 da Imperva. Este contexto explica por que os sites desafiam padrões de raspagem incomuns rapidamente.
O reCAPTCHA também é comum perto de fluxos de pagamento e conta. O Google Cloud diz que a Defesa de Transação do reCAPTCHA ajuda a proteger transações de pagamento contra ataques de cartão e transações fraudulentas Defesa de Transação do Google Cloud. Um raspador que toca em páginas de carrinho, checkout ou conta enfrenta verificações mais rigorosas do que a monitoração de produtos públicos.
Primeira Regra: Confirme que os Dados são Permitidos
A conformidade vem antes das mudanças técnicas. Um raspador deve coletar apenas dados públicos, permitidos e necessários. Ele deve evitar páginas de login, dados privados de clientes, etapas de checkout e áreas restritas sem autorização explícita.
O Protocolo de Exclusão de Robôs também importa. O RFC 9309 diz que o robots.txt permite que os proprietários de serviços controlem como os raspadores acessam o espaço de URI, e os raspadores são solicitados a respeitar essas regras Protocolo de Exclusão de Robôs RFC 9309. O robots.txt não é o único teste legal. No entanto, raspadores responsáveis devem analisá-lo antes de executá-lo.
Antes de lidar com o reCAPTCHA, documente quatro itens. Defina o propósito comercial, as páginas fonte, os campos de dados, os caminhos permitidos, termos, limites de solicitação, concorrência e período de retenção. Isso torna o tratamento do reCAPTCHA um processo governado de dados.
O guia do CapSolver sobre o que é reCAPTCHA pode ajudar os stakeholders a entender o tipo de desafio.
Diagnóstico do Tipo de reCAPTCHA
O diagnóstico deve acontecer antes de mudanças no código. O reCAPTCHA v2 geralmente aparece como uma caixa de seleção ou desafio visual. O reCAPTCHA v3 geralmente retorna uma pontuação sem interação do usuário, então a página pode ser degradada, bloquear uma ação ou pedir uma verificação mais forte posteriormente. O Google observa que o reCAPTCHA v3 retorna uma pontuação para que os proprietários do site escolham uma ação sem mostrar um desafio aos usuários Visão geral do reCAPTCHA v3 do Google.
| Situação | Significado Provável | Resposta Recomendada |
|---|---|---|
| O desafio aparece após muitas solicitações rápidas | O padrão de tráfego parece anormal | Reduza a concorrência e adicione ritmo |
| O desafio aparece apenas em páginas de login ou checkout | A página é de alto risco | Pare a execução, a menos que autorizado explicitamente |
| O desafio aparece em páginas de produtos públicos | O padrão de sessão ou solicitação precisa de revisão | Estabilize cookies e reduza picos |
| A pontuação v3 causa páginas vazias ou degradadas | A pontuação de confiança é baixa | Revise o contexto do navegador e a frequência das solicitações |
| O desafio aparece após redirecionamentos | O estado do fluxo é inconsistente | Preserve a sessão e a ordem das páginas |
Este diagnóstico também controla o custo. Um raspador mais calmo geralmente dispara menos desafios e retorna dados de comércio eletrônico mais limpos.
Resumo da Comparação
Um raspador de comércio eletrônico útil começa com a opção menos invasiva. A tabela abaixo compara escolhas comuns.
| Abordagem | Caso de Uso Ideal | Notas de Conformidade | Risco Operacional | Perfil de Custo |
|---|---|---|---|---|
| API oficial ou feed do comerciante | Acesso a dados parceiro | Melhor opção quando disponível | Baixo | Previsível |
| Raspagem de páginas públicas com ritmo | Monitoramento de produtos e preços públicos | Respeite o robots.txt e os termos | Médio | Baixo a médio |
| Automação de navegador | Páginas de produtos com JavaScript pesado | Evite fluxos restritos | Médio | Médio |
| Fila de revisão humana | Verificações raras de alto valor | Trilha de auditoria forte | Baixo | Custo maior de mão de obra |
| Integração do CapSolver | Automação permitida que encontra reCAPTCHA | Use apenas para fluxos legais e benignos | Médio | Baseado no uso |
A tabela mostra um ponto prático. O reCAPTCHA deve ser um caminho de exceção dentro de um raspador que respeite regras e limites.
Construa um Fluxo de Scraping de Comércio Eletrônico Mais Limpo
Um fluxo mais limpo reduz desafios evitáveis de reCAPTCHA. Comece com a seleção de páginas. Raspagem apenas em páginas de categorias ou produtos públicos e permitidos. Evite adicionar itens ao carrinho, enviar formulários ou abrir páginas de conta, a menos que sua equipe possua a conta e tenha permissão.
Em seguida, controle a forma do tráfego. Use concorrência moderada, regras de backoff e agendamento estável. Os sites de comércio eletrônico são sensíveis durante vendas, lançamentos e picos de feriados. Um raspador que respeite essas janelas é menos propenso a causar sobrecarga operacional.
O gerenciamento de sessão também importa. Mantenha cookies consistentes durante uma raspagem curta. Não misture fluxos de páginas não relacionadas em uma mesma sessão. Um caminho de descoberta de produtos não deve subitamente solicitar páginas de checkout. Esse padrão pode fazer o reCAPTCHA aparecer.
Monitore a taxa de desafios, páginas vazias, códigos HTTP, falhas na análise de preços e duplicatas. Uma taxa crescente de reCAPTCHA é um sinal de alerta precoce.
Se sua equipe estiver escolhendo entre raspagem direta e acesso a dados oficiais, este artigo do CapSolver sobre raspagem de web versus APIs é um link útil para discussão interna.
Onde o CapSolver se Encaixa
O CapSolver se encaixa quando um processo de automação legítimo encontra reCAPTCHA após verificar conformidade. Ele é útil para auditorias de SEO, verificação de anúncios e raspadores benignos quando os dados alvo são permitidos. A posição própria do CapSolver afirma que atividades ilegais, fraudulentas ou abusivas são proibidas, e ele lista auditorias de SEO, verificação de anúncios, raspadores benignos e cenários de crescimento empresarial como usos intencionais declaração de conformidade do CapSolver.
Essa posição importa. Uma integração do CapSolver nunca deve alvejar contas privadas, etapas de pagamento, conteúdo restrito ou dados claramente proibidos.
O CapSolver é especialmente relevante quando seu raspador já segue um ritmo respeitoso, mas ainda assim encontra reCAPTCHA em páginas públicas permitidas. Ele pode ajudar a manter um fluxo estável sem forçar trabalho manual para cada desafio. Para um cenário focado em comércio eletrônico, veja o guia do CapSolver sobre como resolver CAPTCHAs ao raspar sites de comércio eletrônico.
Referência de Código Oficial do CapSolver
O código a seguir segue a documentação oficial do CapSolver para reCAPTCHA v2. Não altere o tipo de tarefa ou parâmetros sem verificar a documentação atual. Use apenas em fluxos permitidos e com uma chave de API válida.
python
# pip install requests
import requests
import time
# TODO: defina sua configuração
api_key = "SUA_CHAVE_DE_API" # sua chave de API do capsolver
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # chave do site do seu site alvo
site_url = "https://www.google.com/recaptcha/api2/demo" # URL da página do seu site alvo
def capsolver():
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print("Falha ao criar tarefa:", res.text)
return
print(f"Obteve taskId: {task_id} / Obtendo resultado...")
while True:
time.sleep(1) # atraso
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
return resp.get("solution", {}).get('gRecaptchaResponse')
if status == "failed" or resp.get("errorId"):
print("Falha na resolução! resposta:", res.text)
return
token = capsolver()
print(token)A documentação oficial do CapSolver diz para criar a tarefa com createTask e recuperar o resultado com getTaskResult. Ela também explica que campos como websiteURL e websiteKey são necessários para a tarefa. Para mais contexto de implementação, leia o guia oficial do CapSolver sobre como resolver reCAPTCHA no scraping web usando Python.
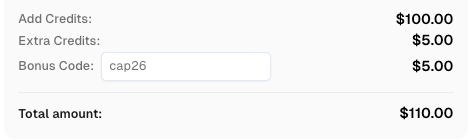
Resgate seu Código de Bônus do CapSolver
Aumente seu orçamento de automação instantaneamente!
Use o código de bônus CAP26 ao recarregar sua conta do CapSolver para obter um bônus adicional de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel do CapSolver
Controles Práticos para Produção
O scraping de comércio eletrônico em produção precisa de controles que não engenheiros possam auditar. Crie uma política de raspagem antes da implantação. A política deve nomear o proprietário dos dados, domínios permitidos, caminhos permitidos, concorrência máxima, solicitações diárias máximas, período de retenção e contato de escalonamento.
Use a taxa de ocorrência de reCAPTCHA como métrica-chave. Se a taxa ultrapassar um limite definido, reduza a velocidade de raspagem ou pause. Se desafios aparecerem em fluxos restritos, pare o trabalho. Se o alvo mudar seu robots.txt ou termos, revise o raspador antes de continuar.
Mantenha os dados restritos. Preços, disponibilidade, título, URL da imagem e contagem de avaliações públicas podem ser válidos para alguns casos de negócios. Nomes de clientes, avaliações privadas atrás de login, tokens de carrinho e dados de conta devem permanecer fora do escopo, a menos que o proprietário do site autorize o acesso.
Isso também é onde uma fila de recuperação ajuda. Um raspador pode armazenar páginas não resolvidas para revisão em vez de tentar repetidamente. Essa única escolha de design reduz a carga, reduz o custo e mantém o tratamento do reCAPTCHA defensável.
Para padrões adicionais de engenharia, o artigo do CapSolver sobre três formas de resolver CAPTCHA durante o scraping pode apoiar o planejamento da implementação.
Erros Comuns a Evitar
O primeiro erro é tratar o reCAPTCHA apenas como um obstáculo técnico. É frequentemente um sinal de que o raspador é muito amplo, muito rápido ou fora do fluxo pretendido. Corrija o fluxo antes de adicionar ferramentas.
O segundo erro é ignorar o contexto da página. Os sites de comércio eletrônico tratam páginas de busca, produtos, carrinho, login e checkout de forma diferente. Seu raspador deve fazer o mesmo. Monitoramento de produtos públicos tem um perfil de risco diferente da automação de contas.
O terceiro erro é não ter registros de auditoria. Cada evento de reCAPTCHA deve registrar o grupo de URL, horário, versão do raspador, código de resposta e ação tomada.
O quarto erro é usar código obsoleto. As implementações de reCAPTCHA mudam. A documentação do CapSolver deve ser a fonte para a estrutura do código, tipos de tarefa e campos necessários.
Conclusão e CTA
O reCAPTCHA no scraping de comércio eletrônico é melhor tratado com governança, diagnóstico e ferramentas cuidadosas. Comece com verificação de permissões, robots.txt, termos e minimização de dados. Em seguida, reduza desafios evitáveis com ritmo, sessões estáveis e escopo limitado. Se o reCAPTCHA ainda aparecer em um processo de automação legal e permitido, o CapSolver pode fornecer uma camada de resolução prática com base na documentação oficial.
Se sua equipe precisar de um método controlado para lidar com reCAPTCHA durante a coleta de dados de comércio eletrônico, revise a documentação do CapSolver, defina suas regras de conformidade e teste em páginas públicas de baixo volume primeiro. Um raspador responsável coleta apenas o que precisa, para quando as regras mudarem e deixa um histórico de auditoria claro.
Perguntas Frequentes
É legal lidar com reCAPTCHA durante o scraping de comércio eletrônico?
Depende da permissão, tipo de dados, jurisdição e termos do site. Um fluxo mais seguro usa páginas permitidas públicas, respeita o robots.txt, evita dados privados e segue limites documentados. Revisão legal é aconselhável para projetos comerciais.
Por que o reCAPTCHA aparece em páginas de produtos?
O reCAPTCHA pode aparecer quando o volume de solicitações, histórico de sessão, contexto do navegador ou horário do tráfego parecem incomuns. Também pode aparecer porque o site aplica proteção rigorosa às páginas de preços e disponibilidade.
Devo resolver todos os reCAPTCHAs que vejo?
Não. Uma taxa alta de reCAPTCHA geralmente significa que o raspador precisa de revisão. Reduza a velocidade, limite o escopo, verifique os caminhos permitidos e use a resolução apenas para casos de exceção permitidos.
O CapSolver pode ajudar com o scraping de comércio eletrônico?
Sim, o CapSolver pode ajudar quando um fluxo de trabalho de automação de comércio eletrônico legítimo enfrenta um recaptcha. Use-o apenas para trabalho de dados legal, benévolo e permitido, e siga a documentação oficial.
O que devo monitorar após a implantação?
Monitore a taxa de recaptcha, códigos de status, erros de parsing, volume, grupos de caminhos e filas não resolvidas. Pausar o crawler quando os limites forem excedidos.