Automação de Navegador com IA para Privacidade Online e Remoção de Informações Pessoais: Um Guia Prático

Adélia Cruz
Neural Network Developer
TL;DR
- A Automação de Navegador de IA para Privacidade Online e Remoção de Informações Pessoais funciona melhor como um fluxo supervisionado, não como um script de raspagem cega.
- O processo mais seguro é descobrir dados expostos, priorizar registros sensíveis, enviar solicitações legais, salvar evidências e monitorar reaparecimentos.
- Remoção de resultados de busca, exclusão de site, encerramento de conta e opt-out de brokers de dados são tarefas diferentes.
- A conformidade é importante em cada etapa, pois dados privados, restritos ou não autorizados nunca são justos.
- CAPTCHA e desafios de validação de tráfego podem aparecer durante opt-outs repetidos, então use ferramentas documentadas apenas onde o acesso for permitido.
Introdução
A Automação de Navegador de IA para Privacidade Online e Remoção de Informações Pessoais é útil quando a limpeza de privacidade se torna repetitiva, com muitas evidências e difícil de rastrear. Pode ajudar indivíduos, equipes de privacidade e equipes de operações de segurança a organizar solicitações legais de remoção em resultados de busca, páginas públicas, configurações de conta e formulários de brokers de dados. O valor principal não é apenas a velocidade. O verdadeiro valor é consistência, rastreabilidade e revisão humana antes de ações sensíveis. O Google diz que pode remover alguns dados pessoais privados dos resultados de busca, mas não do próprio site de origem. Essa distinção define todo o fluxo de trabalho. A automação pode ajudar, mas direitos legais, regras do site e consentimento ainda definem o que deve ser feito.
Por que este cenário de remoção de privacidade precisa de automação
A Automação de Navegador de IA para Privacidade Online e Remoção de Informações Pessoais resolve um problema prático de coordenação. Informações pessoais podem aparecer em fragmentos de busca, páginas em cache, diretórios públicos, perfis de brokers, contas antigas e conteúdo arquivado. Cada fonte pode exigir um formulário, comprovação, período de espera e follow-up diferentes.
A remoção manual é possível para uma pequena quantidade de dados. Torna-se frágil quando uma pessoa tem múltiplos nomes, endereços, números de telefone, perfis de trabalho e contas antigas. A automação de navegador pode abrir formulários, coletar capturas de tela, registrar horários e colocar cada solicitação em uma fila de revisão. O usuário ainda decide o que enviar.
Este também é um fluxo de redução de risco. O FTC explica que sites e aplicativos podem usar cookies, pixels, fingerprinting de dispositivo e identificadores de publicidade para rastrear atividade online Orientação da FTC sobre privacidade online. Remover registros expostos é apenas uma parte da higiene de privacidade. As equipes também devem reduzir a coleta futura por meio de configurações de navegador, configurações de conta e minimização de dados.
O que os concorrentes frequentemente ignoram sobre a automação de navegador de IA
A maioria dos guias de privacidade explica o que remover. Poucos explicam como operar a remoção em escala. Artigos comuns cobrem solicitações de remoção do Google, e-mails do proprietário do site, opt-out de brokers de dados, configurações sociais e monitoramento contínuo. Essas seções são úteis, então este guia as inclui.
A camada faltante é o design operacional. A Automação de Navegador de IA para Privacidade Online e Remoção de Informações Pessoais precisa de uma fila, captura de evidências, aprovação humana, limites de tentativas e um registro de auditoria.
Outro vazio é o tratamento de desafios. Formulários repetidos de privacidade podem acionar reCAPTCHA, desafios do Cloudflare ou outros validadores de tráfego. O guia da CapSolver sobre automação de navegador para desenvolvedores é útil como fundamento para esta camada de navegador controlado.
Etapa 1: mapeie onde as informações pessoais aparecem
Comece com a descoberta. A Automação de Navegador de IA para Privacidade Online e Remoção de Informações Pessoais deve começar com consultas aprovadas pelo usuário, não com coleta ampla. Pesquise nomes conhecidos, endereços de e-mail, números de telefone, nomes de usuário, antigos empregadores e URLs de perfis públicos.
Separe os resultados em quatro categorias. Resultados de busca são links e fragmentos. Páginas de origem são os sites que hospedam o conteúdo. Sistemas de conta são serviços onde o usuário pode fazer login e editar dados. Brokers de dados são entidades que coletam, vendem ou compartilham informações pessoais.
Mantenha as evidências simples. Salve a URL, campos de dados visíveis, captura de tela, data da descoberta, tipo de fonte e nível de sensibilidade. Não armazene informações pessoais extras apenas porque a automação pode capturá-las. A NIST descreve a gestão de risco de privacidade como um processo corporativo para proteger a privacidade das pessoas enquanto gerencia o uso de dados Quadro de Privacidade da NIST. Esse princípio se aplica mesmo a ferramentas internas de remoção.
Etapa 2: escolha o caminho correto de remoção
Atribua cada registro ao seu ponto de controle real. A Automação de Navegador de IA para Privacidade Online e Remoção de Informações Pessoais falha quando cada exposição é tratada como o mesmo formulário. A remoção de resultados de busca pode reduzir a visibilidade. A exclusão da fonte remove ou edita a página. O encerramento da conta remove dados controlados pelo usuário. Opt-out de brokers solicita supressão ou exclusão dos sistemas de broker.
Para o Google Search, colete URLs exatas antes de enviar uma solicitação. O Google afirma que os formulários de solicitação revisam URLs específicas e que a remoção de resultados de busca não remove o conteúdo do site hospedador <a Isso significa que a automação deve criar uma tarefa de página de origem após cada tarefa de resultado de busca.
Para solicitações de brokers de dados, elegibilidade e jurisdição importam. A plataforma California DROP diz que residentes elegíveis podem enviar uma única solicitação a brokers de dados registrados e que os brokers começam a processar solicitações sob seu cronograma. O mesmo conceito se aplica em outros lugares. Verifique a lei local, requisitos de prova e autorização de representante antes de enviar solicitações.
Resumo da Comparação
| Abordagem | Caso de uso ideal | Principais vantagens | Principais limitações | Controle de conformidade |
|---|---|---|---|---|
| Remoção manual | Pequena pegada pessoal | Controle total do usuário | Lenta e difícil de repetir | Revisão do usuário em cada submissão |
| Serviço de privacidade gerenciado | Opt-outs amplos para consumidores | Monitoramento contínuo de brokers | Menos visibilidade no fluxo de trabalho | Revisão de autorização e relatórios |
| Fluxo de trabalho de navegador com assistência de IA | Equipes com casos repetidos | Evidências, filas e repetibilidade | Requer governança e testes | Aprovação humana, logs e regras de escopo |
| Remoção com API | Sites com APIs oficiais | Estável e auditável | Nem sempre disponível | Use endpoints documentados apenas |
Etapa 3: construa o fluxo de automação com segurança
Use um fluxo estreito. A Automação de Navegador de IA para Privacidade Online e Remoção de Informações Pessoais não deve se espalhar pela web. Deve seguir URLs aprovados, campos de formulário predefinidos e regras de decisão documentadas.
Um fluxo prático tem seis etapas. Primeiro, o usuário aprova a lista de alvos. Segundo, o navegador abre cada página em um perfil limpo. Terceiro, o sistema extrai apenas os campos necessários. Quarto, o sistema prepara o rascunho da solicitação. Quinto, um humano confirma a submissão. Sexto, o sistema salva a página de confirmação, comprovante de e-mail ou captura de tela.
Cada solicitação precisa de um status. Use valores como descoberto, rascunhado, submetido, aguardando, verificado, rejeitado e reanálise. Isso mantém o processo legível. Também evita submissões repetidas que podem incomodar os proprietários do site ou acionar validação de tráfego.
Para equipes técnicas, a escolha da ferramenta importa. Este artigo da CapSolver sobre solução de CAPTCHA do Selenium vs Puppeteer fornece contexto para ambientes de automação. A decisão de privacidade ainda vem primeiro.
Etapa 4: adicione controles de privacidade por design
Governança deve vir antes da velocidade. A Automação de Navegador de IA para Privacidade Online e Remoção de Informações Pessoais lida com nomes, endereços, capturas de tela e, às vezes, evidências de identidade. Armazene menos dados do que você pudesse coletar. Criptografe registros de solicitação. Limite o acesso por função. Exclua evidências após o período de retenção.
Não envie formulários sob identidade falsa. Não acesse contas privadas sem permissão do proprietário. Não colete dados de terceiros durante uma solicitação do usuário.
O fluxo também deve respeitar limites de taxa. Execução lenta e rastreável é melhor que automação barulhenta. Prefira formulários oficiais, e-mails claros e APIs documentadas.
Uma tela de revisão sólida deve mostrar a URL de destino, a ação solicitada, os campos pessoais, a base legal se conhecida e a evidência anexada.
Etapa 5: trate CAPTCHA e validação de tráfego de forma responsável
Desafios são comuns em fluxos de privacidade repetidos. A Automação de Navegador de IA para Privacidade Online e Remoção de Informações Pessoais pode encontrar reCAPTCHA v2, reCAPTCHA v3, desafios do Cloudflare, tarefas de clique em imagem ou links de verificação por e-mail. Trate esses como pontos de verificação, não como obstáculos.
A regra segura é simples. Continue apenas quando o usuário ou organização tiver um motivo legítimo para acessar aquela página. Se o acesso falhar, revise os termos, reduza a frequência ou use um canal oficial.
A CapSolver pode ajudar quando o tratamento de desafios faz parte de um fluxo de automação permitido. Para reCAPTCHA v2, a documentação oficial diz para criar uma tarefa com createTask e recuperar o resultado com getTaskResult no guia do reCAPTCHA v2. Para reCAPTCHA v3, o guia do reCAPTCHA v3 documenta tipos de tarefa como ReCaptchaV3TaskProxyLess e inclui pageAction no exemplo do SDK.
O padrão de SDK oficial é conciso:
python
# pip install --upgrade capsolver
# export CAPSOLVER_API_KEY='...'
import capsolver
# capsolver.api_key = "..."
solution = capsolver.solve({
"type": "ReCaptchaV3TaskProxyLess",
"websiteURL": "https://www.google.com",
"websiteKey": "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_kl-",
"pageAction": "login",
})Para desafios do Cloudflare, o guia da CapSolver sobre desafios do Cloudflare documenta AntiCloudflareTask, websiteURL, um proxy estático ou estável necessário e tratamento consistente de userAgent. Se seu fluxo de privacidade usar navegação headless, este guia sobre solução automática de CAPTCHA em navegadores headless fornece contexto de implementação mais amplo.
Etapa 6: verifique a remoção e monitore o reaparecimento
A verificação completa o fluxo de trabalho. A Automação de Navegador de IA para Privacidade Online e Remoção de Informações Pessoais deve revisitar URLs submetidas após o período de espera, comparar campos visíveis e marcar os resultados com evidências. Não assuma sucesso porque um formulário foi submetido.
Os dados podem reaparecer. Brokers atualizam registros, motores de busca recrawl páginas e contas antigas podem expor campos de perfil novamente. Uma reverificação mensal ou trimestral é prática para a maioria das pessoas. Pessoas com alto risco podem precisar de monitoramento mais frequente.
Mantenha o monitoramento escopo. Revisite apenas URLs aprovadas, termos de consulta conhecidos e listas de brokers confirmadas. Se novas informações pessoais aparecerem, crie uma nova tarefa de revisão em vez de submeter automaticamente. Isso protege o usuário e a organização que executa o fluxo.
O artigo da CapSolver sobre um solucionador de CAPTCHA de navegador de IA é relevante quando o monitoramento repetido atinge páginas de validação. Seu uso deve permanecer limitado a automação legal, razoável e documentada. A FAQ da CapSolver sobre se a solução de CAPTCHA é legal para raspagem de web pode apoiar a revisão interna.
Conclusão e CTA
A Automação de Navegador de IA para Privacidade Online e Remoção de Informações Pessoais é mais eficaz quando é estreita, documentada e supervisionada. Deve ajudar as pessoas a encontrar registros expostos, escolher o caminho correto de remoção, preparar solicitações legais, capturar evidências e monitorar reaparecimentos. Não deve substituir consentimento, revisão legal ou julgamento humano.
Os melhores fluxos de privacidade combinam automação com restrição. Use formulários oficiais, respeite as regras do site, armazene evidências mínimas e pause para aprovação humana antes de submeter solicitações sensíveis. Quando desafios de reCAPTCHA, Cloudflare ou clique em imagem aparecerem em um fluxo aprovado, revise a documentação oficial da CapSolver e use padrões documentados apenas. A CapSolver pode se encaixar nesse cenário recorrente porque a remoção de privacidade frequentemente envolve submissões repetidas de formulários, sessões de navegador e tratamento de desafios. Comece com um processo compatível, depois adicione a CapSolver onde ela apoia esse processo.
Resgate seu código promocional da CapSolver
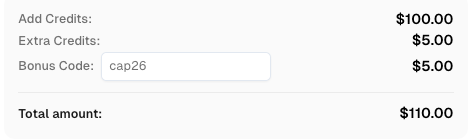
Aumente seu orçamento de automação instantaneamente. Use o código promocional CAP26 ao recarregar sua conta da CapSolver para obter um bônus adicional de 5% em cada recarga, sem limites.
Resgate-o agora no seu Painel da CapSolver
Perguntas Frequentes
A Automação de Navegador de IA para Privacidade Online e Remoção de Informações Pessoais é legal?
Pode ser legal quando segue a lei aplicável, termos do site e autorização do usuário. O fluxo mais seguro usa alvos aprovados, revisão humana, solicitações documentadas e coleta mínima de dados.
A automação pode remover todas as informações pessoais da internet?
Não. A Automação de Navegador de IA para Privacidade Online e Remoção de Informações Pessoais pode reduzir a exposição, mas a exclusão completa é irrealista. Remoção de resultados de busca, exclusão da fonte, opt-out de brokers e limpeza de conta têm limites diferentes.
Quais dados o fluxo deve armazenar?
Armazene apenas o que comprova a solicitação e apoia a continuidade. Normalmente, isso significa URL, captura de tela, data, tipo de solicitação, status e evidência de confirmação. Evite coletar dados pessoais não relacionados.
Como as equipes devem lidar com desafios de CAPTCHA durante solicitações de privacidade?
As equipes devem pausar primeiro e confirmar que o acesso é permitido. Se o fluxo for legítimo, use documentação oficial, como os guias da CapSolver sobre reCAPTCHA e Cloudflare, sem adicionar parâmetros não oficiais.
Com que frequência as informações pessoais devem ser verificadas novamente?
A maioria dos usuários pode verificar mensalmente ou trimestralmente. Usuários de alto risco podem precisar de revisões mais frequentes. A chave é monitorar fontes aprovadas e evitar varreduras não controladas.