Como resolver o desafio do Cloudflare no Crawl4AI com a integração do CapSolver

Aloísio Vítor
Image Processing Expert
Introdução
O desafio do Cloudflare é um mecanismo anti-bot sofisticado que frequentemente envolve verificações complexas, incluindo fingerprinting de navegador e validação do User-Agent, para distinguir usuários legítimos de tráfego automatizado. Esses desafios podem dificultar significativamente a raspagem de web e a extração de dados, tornando difícil para os crawlers acessarem os sites alvo. Superar o desafio do Cloudflare requer uma solução robusta e adaptativa que possa imitar o comportamento de um navegador real.
Este artigo fornece um guia completo sobre como integrar o Crawl4AI, um raspador avançado da web, com o CapSolver, um serviço de solução de CAPTCHA e anti-bot líder, para contornar com eficácia as proteções do Cloudflare Challenge. Focaremos no método de integração baseado em API, fornecendo exemplos de código detalhados e explicações para garantir que suas tarefas de automação da web possam prosseguir sem interrupções.
Compreendendo o Cloudflare Challenge e suas Complexidades para Raspagem de Web
O Cloudflare Challenge foi projetado para ser mais agressivo do que CAPTCHAs típicos, frequentemente empregando uma combinação de técnicas para identificar e bloquear bots:
- Fingerprinting de Navegador: Analisando características únicas do navegador para detectar automação.
- Validação do User-Agent: Exigindo strings de User-Agent específicas e consistentes que correspondam às versões reais dos navegadores.
- Execução de JavaScript: Executando JavaScript complexo em segundo plano para verificar as capacidades do navegador e a interação semelhante a de um humano.
- Gerenciamento de Cookies: Definindo e validando cookies específicos como parte do processo de resolução do desafio.
O CapSolver fornece o tipo de tarefa AntiCloudflareTask, especificamente projetado para lidar com esses desafios complexos, fornecendo os tokens, cookies necessários e até recomendando User-Agents específicos. Quando integrado ao Crawl4AI, isso permite que seus crawlers naveguem com sucesso por sites protegidos pelo Cloudflare.
Método de Integração: Integração da API do CapSolver com o Crawl4AI
O método de integração via API é essencial para lidar com o Cloudflare Challenge, pois permite controle preciso sobre as configurações do navegador e a injeção dos tokens e cookies necessários. Este método envolve o uso do CapSolver para obter a solução necessária do desafio (token, cookies e User-Agent) e, em seguida, configurar o Crawl4AI para usar esses parâmetros.
Como Funciona:
- Obter Solução do Cloudflare Challenge: Antes de iniciar o raspador, chame a API do CapSolver usando seu SDK, especificando o tipo de tarefa
AntiCloudflareTask. Você precisará fornecer awebsiteURL, umproxy(se aplicável) e umuserAgentque corresponda à versão do navegador que o CapSolver usa para resolver. - Configurar Navegador do Crawl4AI: Use a solução retornada pelo CapSolver (que inclui um
token,cookiese umuserAgentrecomendado) para configurar oBrowserConfigdo Crawl4AI. Isso garante que a instância do navegador do Crawl4AI imite o ambiente usado para resolver o desafio. - Iniciar o Raspador: O Crawl4AI então executa com o navegador configurado especialmente, que inclui os cookies e User-Agent necessários, permitindo que ele contorne o Cloudflare Challenge.
- Continuar as Operações: Com o Cloudflare Challenge contornado com sucesso, o Crawl4AI pode prosseguir com suas tarefas de extração de dados no site alvo.
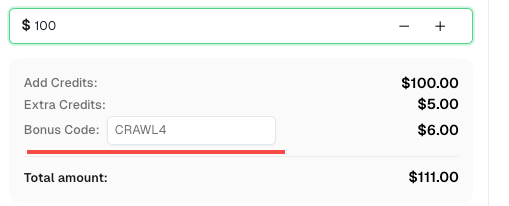
💡 Bônus Exclusivo para Usuários de Integração do Crawl4AI:
Para comemorar esta integração, oferecemos um código de bônus de 6% —CRAWL4para todos os usuários do CapSolver que se registrarem por meio deste tutorial.
Basta inserir o código durante o recarregamento no Painel para receber créditos extras de 6% instantaneamente.
Código de Exemplo: Integração via API para Cloudflare Challenge
O seguinte código Python demonstra como integrar a API do CapSolver ao Crawl4AI para resolver o Cloudflare Challenge. Este exemplo visa uma página de artigo de notícias protegida pelo Cloudflare.
python
import asyncio
import time
import capsolver
from crawl4ai import *
# TODO: defina sua configuração
api_key = "CAP-XXX" # sua chave de API do CapSolver
site_url = "https://www.tempo.co/hukum/polisi-diduga-salah-tangkap-pelajar-di-magelang-yang-dituduh-perusuh-demo-2070572" # URL da página do seu site alvo
captcha_type = "AntiCloudflareTask" # tipo de seu CAPTCHA alvo
api_proxy = "http://127.0.0.1:13120"
capsolver.api_key = api_key
user_data_dir = "./crawl4ai_/browser-profile/Default1493"
# ou
cdp_url = "ws://localhost:xxxx"
async def main():
print("iniciando solução do token")
start_time = time.time()
# obter token do Cloudflare usando o SDK do CapSolver
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"proxy": api_proxy,
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36"
})
token_time = time.time()
print(f"solução do token: {token_time - start_time:.2f} s")
# definir cookies
cookies = solution.get("cookies", [])
if isinstance(cookies, dict):
cookies_array = []
for name, value in cookies.items():
cookies_array.append({
"name": name,
"value": value,
"url": site_url,
})
cookies = cookies_array
elif not isinstance(cookies, list):
cookies = []
token = solution["token"]
print("token do desafio:", token)
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
user_data_dir=user_data_dir,
# cdp_url=cdp_url,
user_agent=solution["userAgent"],
cookies=cookies,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
print(result.markdown[:500])
if __name__ == "__main__":
asyncio.run(main())Análise do Código:
- Chamada do SDK do CapSolver: O método
capsolver.solveé central aqui, usando o tipoAntiCloudflareTask. Ele exigewebsiteURL,proxye umuserAgentespecífico. O CapSolver processa o desafio e retorna um objetosolutioncontendo umtoken,cookiese ouserAgentusado para resolver o desafio. - Configuração do Navegador: O
BrowserConfigdo Crawl4AI é configurado cuidadosamente com as informações da solução do CapSolver. Isso incluiuser_agentecookiespara garantir que a instância do navegador do Crawl4AI corresponda perfeitamente às condições em que o desafio do Cloudflare foi resolvido. Ouser_data_dirtambém é especificado para manter um perfil de navegador consistente. - Execução do Raspador: O Crawl4AI executa então seu método
aruncom estabrowser_configcuidadosamente configurada, permitindo que ele acesse com sucesso a URL alvo sem disparar novamente o Cloudflare Challenge.
Conclusão
Contornar o Cloudflare Challenge na raspagem de web é uma tarefa complexa que exige uma abordagem sofisticada. A integração do Crawl4AI com o CapSolver fornece uma solução poderosa e eficaz, permitindo que os desenvolvedores naveguem por essas proteções avançadas contra bots de forma tranquila. Ao utilizar o AntiCloudflareTask especializado do CapSolver para obter os tokens, cookies e User-Agent necessários, e configurar o navegador do Crawl4AI para corresponder a esses parâmetros, você pode garantir a estabilidade e o sucesso de suas operações de raspagem de web.
Essa sinergia entre as capacidades avançadas de raspagem do Crawl4AI e a tecnologia anti-bot robusta do CapSolver representa um grande passo à frente na extração automatizada de dados da web, permitindo que você se concentre em coletar dados valiosos sem ser impedido pelas medidas de proteção do Cloudflare.
Perguntas Frequentes (FAQ)
Q1: O que é Cloudflare Challenge e por que ele é usado?
A1: O Cloudflare Challenge é um mecanismo avançado anti-bot projetado para verificar se um visitante é um humano real ou um script automatizado. Ele emprega diversas técnicas como fingerprinting de navegador, validação do User-Agent e execução de JavaScript para proteger sites contra bots maliciosos, ataques DDoS e outras ameaças.
Q2: Por que o Cloudflare Challenge é particularmente difícil para raspadores da web?
A2: O Cloudflare Challenge é difícil para raspadores porque vai além de CAPTCHAs simples. Ele analisa ativamente as características do navegador, exige strings de User-Agent consistentes, executa JavaScript complexo e gerencia cookies específicos. Essa detecção sofisticada torna difícil para ferramentas automatizadas imitar a interação real de um humano sem soluções especializadas.
Q3: Como o CapSolver ajuda a contornar o Cloudflare Challenge?
A3: CapSolver fornece um tipo de tarefa especializado, AntiCloudflareTask, para resolver desafios do Cloudflare. Ele processa o desafio e retorna uma solução que inclui um token, cookies necessários e um User-Agent recomendado. Essas informações são então usadas para configurar o Crawl4AI para contornar com sucesso o desafio.
Q4: Quais são as considerações principais ao integrar o Crawl4AI e o CapSolver para o Cloudflare Challenge?
A5: As considerações principais incluem garantir que o userAgent usado na sua configuração do Crawl4AI corresponda ao fornecido pelo CapSolver, tratar e injetar corretamente os cookies retornados pelo CapSolver e fornecer um proxy se suas operações de raspagem exigirem. Essas etapas garantem que o ambiente do navegador do Crawl4AI reflita com precisão as condições em que o desafio foi resolvido.
Referências
Ver mais
CloudflareDec 10, 2025
Desafio do Cloudflare vs. Turnstile: Principais Diferenças e Como Identificá-los
Entenda as principais diferenças entre Cloudflare Challenge vs Turnstile e aprenda a identificá-los para automação web bem-sucedida. Obtenha dicas de especialistas e um solucionador recomendado.

CloudflareMar 26, 2026
Corrigir o Erro 1005 do Cloudflare: Guia de Web Scraping e Soluções
Aprenda a corrigir o Erro 1005 do Cloudflare acesso negado durante o web scraping. Descubra soluções como proxies residenciais, fingerprinting de navegador e CapSolver para CAPTCHA. Otimize sua extração de dados.


