Segurança de Web Scraping: Melhores Práticas para Proteger os Dados & Evitar a Detecção

Adélia Cruz
Neural Network Developer

TL;Dr:
- Conformidade Legal e Ética: Observe o
robots.txte os termos de serviço para coleta de dados ética. - Imitar o Comportamento Humano: Implemente pausas, rotacione agentes do usuário e gerencie cookies para evitar detecção de robôs.
- Utilize Proxies: Empregue tipos diversos de proxies (residenciais, de datacenter) para distribuir solicitações e mascarar seu IP.
- Trate CAPTCHAs: Integre serviços de resolução automática de CAPTCHA para coleta de dados ininterrupta.
- Monitore e Adapte-se: Monitore continuamente o desempenho da raspagem e as mudanças no site para manter a eficácia.
Introdução
A raspagem de web, uma técnica poderosa de extração de dados, apresenta desafios significativos de segurança e riscos de detecção. Este guia apresenta melhores práticas para segurança de raspagem de web, ajudando profissionais de dados a proteger seus dados e navegar por sistemas anti-bot. Compreender mecanismos de detecção e implementar estratégias robustas garante coleta de dados eficiente, ética e ininterrupta. Clarificamos conceitos, estabelecemos conhecimento fundamental e oferecemos soluções práticas para melhorar suas operações de raspagem de web. Para uma análise mais aprofundada dos fundamentos, explore o que é raspagem de web.
Entendendo a Segurança da Raspagem de Web: O Que, Por Que e Como
A raspagem de web segura e eficaz requer compreensão de como os sites protegem suas informações. Segurança de raspagem de web envolve métodos e práticas para impedir que raspadores sejam detectados, bloqueados ou envolvidos em problemas legais. O objetivo é coletar dados respeitando as políticas do site e evitando gatilhos anti-bot. Isso equilibra eficiência com discrição, tornando as atividades de raspagem parecerem interações legítimas de usuários.
A Essência da Detecção de Raspagem de Web
Sites usam várias técnicas para identificar e dissuadir a raspagem automatizada. Mecanismos de detecção analisam padrões que se desviam do comportamento típico humano. Taxas de solicitação altas de um único IP ou cabeçalhos de navegador ausentes podem sinalizar rapidamente um raspador. Compreender esses gatilhos é crucial para estratégias de raspagem resistentes. Sistemas anti-bot evoluem constantemente, exigindo adaptação contínua das práticas de segurança de raspagem de web.
Como Funcionam os Sistemas Anti-Bot
Sistemas anti-bot analisam diversos pontos de dados das solicitações entrantes, construindo um perfil de visitante e procurando anomalias. Indicadores-chave incluem reputação de IP, fingerprinting de navegador, cabeçalhos de solicitação e padrões de comportamento. Desvios significativos do perfil humano podem acionar respostas como desafios de CAPTCHA ou bloqueio de IP. A segurança de raspagem de web eficaz visa se fundir com o tráfego legítimo, dificultando a diferenciação por esses sistemas.
Conhecimento Estruturado: Definições, Classificações e Cenários
Construir uma base sólida em segurança de raspagem de web requer categorizar componentes e compreender seus papéis. Essa abordagem estruturada ajuda a identificar medidas apropriadas para diferentes desafios de raspagem.
Conceitos Principais em Segurança de Raspagem de Web
- Rotação de IP: Alterar endereços IP para solicitações para evitar limites de taxa e bloqueios de IP, fazendo com que as solicitações pareçam vir de usuários distintos. Essa técnica é fundamental para distribuir a carga de solicitações e evitar que um único IP seja marcado.
- Gerenciamento de User-Agent: Definir cabeçalhos
User-Agentapropriados para imitar navegadores populares, pois sistemas anti-bot verificam isso para legitimidade. Rotacionar regularmente os User-Agents pode aumentar ainda mais a discrição. - Limitação de Solicitações: Introduzir pausas entre solicitações para simular padrões de navegação humana e evitar sobrecarga do servidor. Aleatorizar essas pausas torna a atividade de raspagem parecer mais natural.
- Fingerprinting de Navegador: Coletar características únicas do navegador (ex.: plug-ins, fontes, resolução da tela) para identificar e rastrear usuários. Sistemas anti-bot avançados usam isso para detectar navegadores sem interface gráfica. Os raspadores devem buscar apresentar fingerprints de navegador consistentes e comuns.
- CAPTCHA (Teste de Turing Automatizado Público para Distinguir Computadores e Humanos): Um teste de resposta para verificar usuários humanos. Existem vários tipos com lógica de reconhecimento diferente, representando uma barreira significativa para sistemas automatizados.
Classificação das Medidas Anti-Bot
Sites implementam defesas em camadas contra raspadores:
- Limitação de Taxa: Restringir solicitações de um único IP em um período. Exceder os limites geralmente resulta em bloqueios temporários ou permanentes.
- Listas Negras de IP: Bloquear endereços IP ou faixas conhecidos como maliciosos com base em dados históricos ou inteligência de ameaças. É por isso que o uso de proxies diversos é crítico.
- Desafios de CAPTCHA: Apresentar puzzles visuais ou interativos para verificar interação humana (ex.: reCAPTCHA, Cloudflare Turnstile). Esses são projetados para serem difíceis para bots resolverem automaticamente.
- Verificação de User-Agent e Cabeçalhos: Validar strings
User-Agente outros cabeçalhos HTTP para se assemelharem a navegadores legítimos. Cabeçalhos inconsistentes ou desatualizados podem sinalizar rapidamente um robô. - Armadilhas (Honeypots): Links ou elementos invisíveis projetados para capturar bots automatizados. Seguir esses sinaliza o raspador como não humano, levando ao bloqueio imediato.
- Desafios de JavaScript: Requerer execução de JavaScript para renderizar conteúdo ou resolver puzzles computacionais, desencorajando raspadores simples que não executam JavaScript.
- Fingerprinting de Navegador: Analisar características sutis do navegador para identificar ferramentas automatizadas. Isso inclui verificar inconsistências nas propriedades do navegador que possam indicar um navegador sem interface gráfica.
Cenários de Uso para Raspagem Segura
A raspagem segura é vital para várias aplicações, incluindo pesquisa de mercado, agregação de conteúdo e inteligência competitiva. Por exemplo, um negócio de comércio eletrônico raspando preços de concorrentes precisa de baixa visibilidade para evitar bloqueios e coletar dados precisos e em tempo real. Pesquisadores acadêmicos coletando dados públicos devem garantir métodos compatíveis para evitar problemas legais e éticos. Os princípios de segurança de raspagem de web se aplicam universalmente, independentemente dos objetivos de coleta de dados, enfatizando a necessidade de estratégias robustas para garantir integridade dos dados e continuidade operacional.
Fundamentos Técnicos: Tipos de CAPTCHA, Lógica de Reconhecimento e Controle de Risco
CAPTCHAs são um obstáculo significativo, projetados para diferenciar usuários humanos de bots. Compreender sua base técnica é essencial para superá-los. A tecnologia CAPTCHA evolui constantemente para combater solvers automatizados.
Tipos Comuns de CAPTCHA e Sua Lógica
- reCAPTCHA (Google): Evoluiu da reconhecimento de texto simples (v1) para análise comportamental e pontuação de risco (v2 "Não sou um robô" checkbox, reCAPTCHA invisível) e análise de fundo invisível (v3). A lógica para v2 e v3 depende fortemente de padrões de interação do usuário, fingerprinting de navegador e reputação de IP. Histórias de navegação limpas, movimentos do mouse típicos e comportamento consistente do usuário reduzem a probabilidade de ser desafiado.
- Cloudflare Turnstile: Uma alternativa reCAPTCHA focada na privacidade, frequentemente usando desafios baseados em imagens ou verificação passiva. Sua lógica se concentra na precisão e consistência das seleções do usuário ou sinais comportamentais sem exigir interação explícita do usuário em muitos casos.
- CAPTCHAs Baseados em Imagem: Esses exigem identificar objetos, caracteres ou padrões em um conjunto de imagens. A lógica de reconhecimento usa correspondência de padrões visuais, o que é desafiador para bots sem capacidades avançadas de visão computacional.
- CAPTCHAs de Áudio: Esses apresentam clips de áudio distorcidos de números ou letras para transcrição. Bots geralmente têm dificuldade com a distorção, ruído de fundo e sotaques variados, tornando-os eficazes contra solvers automatizados simples.
Lógica de Reconhecimento e Controle de Risco
Sistemas anti-bot, incluindo aqueles que implementam CAPTCHAs, usam mecanismos de controle de risco sofisticados. Eles analisam diversos fatores em tempo real para avaliar a probabilidade de uma solicitação vir de um robô:
- Análise de Comportamento: Isso envolve a análise de movimentos do mouse, entradas do teclado, padrões de rolagem e tempo gasto em uma página. Ações inconsistentes ou excessivamente precisas, ou ações que são muito rápidas ou muito lentas, podem sinalizar um robô.
- Características de Rede: Fatores como reputação de IP, país de origem e uso de VPNs ou proxies conhecidos são avaliados. IPs associados a atividades maliciosas ou centros de dados são frequentemente marcados mais rapidamente.
- Ambiente do Navegador: Discrepâncias nas strings
User-Agent, plug-ins ausentes, ambientes de execução de JavaScript incomuns ou inconsistências na resolução da tela relatada podem indicar um navegador sem interface gráfica ou um script automatizado. - Frequência e Volume de Solicitações: Solicitações excessivamente altas de uma única fonte em um curto período, muito além dos padrões típicos de navegação humana, são um forte indicador de atividade automatizada.
Fatores de risco acumulados elevam as respostas, levando a desafios de CAPTCHA mais rigorosos, limitação de taxa ou bloqueio direto de IP. Estratégias de segurança de raspagem de web visam minimizar esses fatores, fazendo com que os raspadores pareçam usuários humanos legítimos.
Fluxo de Processo Simples para Raspagem de Web Segura
Compreender o processo de raspagem de web segura em nível alto é benéfico para implementar contra-medidas eficazes.
-
Configuração Inicial e Configuração:
- Escolha um provedor de proxy confiável: Selecione um serviço que ofereça tipos diversos de IP (residenciais, móveis) e rotação. Isso é fundamental para segurança de raspagem de web, pois ajuda a distribuir solicitações e mascarar seu IP real.
- Configure a rotação de
User-Agent: Mantenha stringsUser-Agentatualizadas e as rotacione por solicitação ou sessão. Isso imita ambientes de usuário diversos e evita detecção com base em umUser-Agentestático. - Implemente pausas nas solicitações: Introduza pausas aleatórias entre solicitações (ex.: 2-10 segundos) para imitar a velocidade de navegação humana. Evite pausas previsíveis, fixas, que podem ser facilmente detectadas.
-
Verificações Antes da Raspagem:
- Revise o
robots.txt: Sempre verifique o arquivorobots.txtdo site-alvo (https://example.com/robots.txt) para políticas de raspagem. Respeitar essas diretrizes é crucial para conformidade ética e legal. Ignorar orobots.txtpode levar a problemas legais e bloqueios de IP. Isso é uma parte fundamental da segurança de raspagem de web responsável. - Analise a estrutura do site: Entenda a estrutura HTML e identifique armadilhas potenciais (ex.: elementos
display: noneouvisibility: hidden) para evitar interagir com eles. Interagir com armadilhas é um sinal claro de atividade automatizada.
- Revise o
-
Execução e Monitoramento:
- Raspe os dados: Execute seu script, seguindo as pausas configuradas e a rotação de proxy.
- Monitore os bloqueios: Monitore continuamente as taxas de sucesso das solicitações e os códigos de status HTTP. Se bloqueios ocorrerem (ex.: HTTP 403, 429 ou páginas de CAPTCHA), analise a resposta para identificar a causa. Para estratégias sobre como contornar o bloqueio de IP, consulte nosso guia detalhado.
- Adapte e refine: Ajuste os parâmetros de raspagem (ex.: aumente as pausas, mude os tipos de proxy, atualize as strings
User-Agent) com base no monitoramento em tempo real e feedback das respostas do site.
-
Pós-Raspagem e Tratamento de Dados:
- Validação de Dados: Verifique os dados extraídos quanto a precisão, completude e consistência. Implemente verificações para garantir que os dados sejam limpos e utilizáveis.
- Armazenamento e Segurança: Armazene os dados coletados de forma segura, seguindo regulamentações de proteção de dados relevantes, como LGPD e CCPA. Certifique-se de que os dados estejam criptografados e o acesso esteja restrito a pessoal autorizado.
Soluções para Segurança de Raspagem de Web Aprimorada
À medida que as tecnologias anti-bot avançam, as estratégias de raspagem de web segura também devem evoluir. Essas soluções abordam desafios comuns e oferecem caminhos para coleta de dados resiliente.
Imitar o Comportamento Humano
Fazer seu raspador se comportar como um usuário humano é altamente eficaz contra detecção:
- Pausas Aleatórias: Use intervalos aleatórios (ex.: 5-15 segundos) entre solicitações para uma aparência mais natural, aumentando a segurança de raspagem de web. Isso evita padrões previsíveis que os bots frequentemente exibem.
- Padrões de Clique Realistas: Para navegadores sem interface gráfica, simule movimentos e cliques do mouse com coordenadas e horários variados. Evite cliques diretos em elementos sem movimento prévio do mouse.
- Gerenciamento de Cookies: Mantenha e gerencie cookies entre sessões para manter o estado e reduzir suspeitas. Sites frequentemente usam cookies para rastrear sessões de usuários e identificar visitantes recorrentes.
- Cabeçalhos de Referer: Defina cabeçalhos
Refererapropriados para parecerem de uma fonte legítima (ex.: um motor de busca ou uma página anterior no mesmo site), adicionando legitimidade às solicitações e à segurança de raspagem de web.
Estratégias Avançadas de Proxy
Proxies são cruciais para segurança de raspagem de web. Uma mistura de tipos de proxy melhora o sucesso distribuindo solicitações e mascarando seu IP:
- Proxies Residenciais: Esses IPs são atribuídos por provedores de internet (ISPs) a usuários residenciais. Eles são altamente eficazes, pois parecem tráfego de usuário legítimo, tornando-os difíceis para sistemas anti-bot distinguirem de usuários reais. Proxies residenciais são cruciais para segurança de raspagem de web robusta, especialmente para alvos altamente protegidos.
- Proxies Móveis: IPs de operadoras móveis são ainda mais difíceis de detectar devido à sua natureza dinâmica e associação a dispositivos móveis reais. Eles oferecem maior anonimato e são excelentes para alvos com medidas anti-bot rigorosas.
- Proxies de Datacenter: Esses são mais rápidos e mais baratos, mas mais facilmente detectados, pois originam-se de centros de dados comerciais. Eles são adequados para sites menos protegidos ou fases iniciais de teste onde anonimato não é a principal preocupação.
Resumo Comparativo: Tipos de Proxy para Segurança de Raspagem de Web
| Característica | Proxies de Datacenter | Proxies Residenciais | Proxies Móveis |
|---|---|---|---|
| Nível de Anonimato | Baixo a Médio | Alto | Muito Alto |
| Risco de Detecção | Alto | Baixo | Muito Baixo |
| Velocidade | Alta | Média | Média |
| Custo | Baixo | Médio a Alto | Alto |
| Cenário de Uso | Sites menos protegidos | Sites moderadamente protegidos | Sites altamente protegidos |
| Fonte do IP | Centros de dados comerciais | ISPs | Operadoras móveis |
Superando Desafios CAPTCHA com o CapSolver
CAPTCHAs são uma defesa primária contra raspagem automatizada. A intervenção manual é inviável para operações em larga escala, tornando os serviços de resolução automatizada de CAPTCHA indispensáveis para a segurança da raspagem de web.
CapSolver oferece uma solução robusta para diversos tipos de CAPTCHA, incluindo reCAPTCHA, Cloudflare Turnstile e desafios baseados em imagens. Integrar o CapSolver automatiza a resolução de CAPTCHA, garantindo coleta de dados ininterrupta. A infraestrutura de inteligência artificial avançada do CapSolver reconhece e resolve CAPTCHAs complexos, permitindo que seu raspador prossiga como se um usuário humano tivesse completado o desafio. Isso é valioso quando a imitação de comportamento humano tradicional é insuficiente. Por exemplo, para o reCAPTCHA v3, o CapSolver fornece um token para contornar a verificação com base em avaliação de risco sofisticada, aumentando significativamente a segurança e a eficiência da raspagem de web.
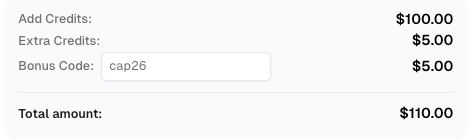
Use o código
CAP26ao se cadastrar no CapSolver para receber créditos bônus!
Os serviços do CapSolver se integram de forma transparente aos frameworks de raspagem existentes, fornecendo soluções para:
- reCAPTCHA v2/v3: Resolvendo desafios de reCAPTCHA de caixa e invisível, gerando tokens válidos.
- Cloudflare Turnstile: Resolvendo com precisão os quebra-cabeças do Cloudflare Turnstile, projetados para serem privados e eficazes contra bots.
- CAPTCHAs ImageToText: Transcrevendo texto distorcido de imagens usando tecnologia avançada de Reconhecimento Óptico de Caracteres (OCR).
Aproveitar esses serviços melhora a resiliência das operações de raspagem contra medidas anti-bot sofisticadas. Para detalhes de integração, consulte a documentação oficial, como Como Escolher uma API de Resolução de CAPTCHA? Guia do Comprador 2026 e Comparação.
Considerações Legais e Éticas
Entender o cenário legal e ético é fundamental para a segurança da raspagem de web a longo prazo. Ignorar esses aspectos pode levar a consequências graves. De acordo com um relatório da Zyte, a raspagem de web em si não é intrinsecamente ilegal, mas sua legalidade depende fortemente dos dados raspados e dos métodos usados. Sempre priorize considerações éticas para manter uma reputação positiva e evitar problemas legais.
Respeitando o robots.txt e os Termos de Serviço
robots.txt: Esse arquivo orienta os crawlers da web sobre quais partes de um site evitar. Sempre siga essas regras. É um forte guia ético, e ignorá-lo pode violar a política do site e comprometer a segurança da raspagem de web. Respeitar orobots.txté um aspecto fundamental da raspagem responsável.- Termos de Serviço (ToS): Os sites muitas vezes proíbem a coleta automatizada de dados em seus ToS. Violar esses termos pode levar à suspensão da conta, bloqueio de IP e disputas legais. Sempre revise os ToS antes de iniciar qualquer atividade de raspagem para garantir conformidade.
Privacidade de Dados e Conformidade
Ao raspar dados pessoais, a conformidade com regulamentações como o RGPD (Regulamento Geral de Proteção de Dados) e a CCPA (Lei de Privacidade do Consumidor da Califórnia) é crítica. Certifique-se de que os dados coletados sejam tratados de forma responsável, anonimizados, se necessário, e usados apenas para fins legítimos. A não conformidade pode resultar em multas significativas e consequências legais. Priorizar a privacidade dos dados é um componente essencial da segurança da raspagem de web. Por exemplo, a Associação Internacional de Profissionais de Privacidade (IAPP) destaca como as leis europeias de proteção de dados limitam significativamente o uso legal da raspagem de web, especialmente em relação a dados pessoais. Além disso, entender a conformidade com o RGPD e CCPA é essencial para raspadores que operam globalmente, pois essas regulamentações impõem requisitos rigorosos sobre coleta e processamento de dados.
Conclusão
A segurança da raspagem de web é um processo contínuo de adaptação. Ao compreender sistemas anti-bot, imitar comportamento humano, empregar estratégias avançadas de proxies e utilizar serviços de resolução automatizada de CAPTCHA como o CapSolver, você aumenta a resiliência da coleta de dados. Sempre priorize a conformidade legal e ética, respeitando o robots.txt, ToS e privacidade de dados. Ficar informado sobre técnicas anti-bot e monitorar o desempenho garante operações robustas e não detectadas. Essa abordagem proativa para a segurança da raspagem de web permite obter insights valiosos enquanto mantém uma estratégia de aquisição de dados responsável e sustentável.
Perguntas Frequentes
Q1: A raspagem de web é legal?
A legalidade da raspagem de web é complexa, dependendo dos dados raspados, dos Termos de Serviço (ToS) do site e das leis de proteção de dados (como RGPD, CCPA). Geralmente, a raspagem de dados publicamente disponíveis é frequentemente permitida, mas dados protegidos por direitos autorais ou dados pessoais sem consentimento explícito podem ser ilegais. Sempre é aconselhável consultar um advogado se você estiver em dúvida sobre a legalidade de suas atividades de raspagem específicas.
Q2: Como evitar que meu IP seja bloqueado durante a raspagem de web?
Para evitar o bloqueio do IP, implemente uma estratégia que inclua rotação de IPs com proxies diversos (residenciais, móveis), introduza intervalos aleatórios entre as solicitações para simular padrões de navegação humana e imite o comportamento do navegador humano com cabeçalhos apropriados de User-Agent e Referer. Monitorar continuamente os logs da raspagem para atividades incomuns ou códigos de erro (como 403 ou 429) é crucial para ajustes proativos e manter a segurança da raspagem de web.
Q3: O que é fingerprinting de navegador e como ele afeta a raspagem de web?
O fingerprinting de navegador coleta características únicas do navegador, como fontes instaladas, complementos, resolução da tela, sistema operacional e idioma, para criar um identificador único para um usuário. Sistemas anti-bot usam isso para detectar navegadores headless ou scripts automatizados que exibem fingerprints inconsistentes ou não humanos. Os raspadores avançados devem usar ferramentas e técnicas para simular fingerprints de navegador realistas e consistentes para evitar detecção.
Q4: Como serviços de resolução de CAPTCHA como o CapSolver funcionam?
O CapSolver usa algoritmos avançados de Inteligência Artificial (IA) e aprendizado de máquina para reconhecer automaticamente e resolver diversos tipos de CAPTCHA. Quando seu raspador se depara com um desafio de CAPTCHA, ele envia o desafio para a API do CapSolver. O CapSolver processa o desafio, gera uma solução e a retorna para seu raspador. Esse processo contorna o CAPTCHA para uma extração de dados ininterrupta, melhorando significativamente a eficiência e a confiabilidade das operações de raspagem de web e aumentando a segurança da raspagem de web.
Q5: O que são armadilhas (honeypots) e como evitar-as?
Armadilhas são links ou elementos invisíveis embutidos em uma página da web projetados para capturar bots automatizados. Um usuário humano não veria ou interagiria com esses elementos, mas um bot poderia. Para evitar armadilhas, seu raspador deve analisar as propriedades CSS dos links (ex.: display: none, visibility: hidden ou color: #fff em um fundo branco) e evitar seguir quaisquer links que estejam ocultos para o visual humano. Essa análise cuidadosa é crítica para manter a segurança da raspagem de web e evitar detecção imediata e bloqueio.
Ver mais
aws wafJul 23, 2026
Como resolver o AWS WAF em LangChain com CapSolver
Construa um fluxo de trabalho autorizado da AWS WAF LangChain com ferramentas CapSolver, detecção de respostas, portas de política, gerenciamento de sessão, tentativas de repetição e verificação.
AIJul 23, 2026
Como resolver o Cloudflare Turnstile nos agentes LangGraph
Construa um fluxo de trabalho solucionador do Cloudflare Turnstile com o CapSolver, gerenciamento de sessão do Playwright, portões de política, retries, verificação e revisão.