Como os Navegadores Agêntes Resolvem CAPTCHAS: Infraestrutura de Resolução de CAPTCHA com IA

Adélia Cruz
Neural Network Developer
Em nosso artigo anterior, exploramos como o Agentic Browser se transforma de uma "ferramenta de exibição passiva" em um "agente de ação ativa". Examinamos sua arquitetura central: compreensão de intenção, percepção ambiental e execução de ação. No entanto, à medida que esses agentes digitais navegam pela web do mundo real, eles enfrentam um portão de entrada formidável: o CAPTCHA. Este artigo se concentra no "motor invisível" — a infraestrutura de resolução de CAPTCHA — que garante que esses agentes possam trabalhar de forma proativa para você sem interrupções. Vamos explorar por que os CAPTCHAs são o principal obstáculo para a IA e como serviços especializados como CapSolver fornecem a infraestrutura crítica necessária para a próxima geração de automação da web.
Capítulo 1: O "Motor Invisível" — Infraestrutura de Resolução de CAPTCHA
Imaginando esta situação: você pede ao Agentic Browser para ajudá-lo a comprar ingressos para um show popular. Ele abre corretamente o site, localiza o botão de compra e, assim que está prestes a clicar em "Comprar Agora", um quebra-cabeça deslizante ou nove imagens de semáforos turvas aparecem subitamente. Seu assistente digital é imediatamente bloqueado. O CAPTCHA, este "teste de Turing" nascido nos primeiros dias da Internet, tornou-se o adversário mais direto — e mais problemático — para os agentes de IA.
1.1 Por que o CAPTCHA é o principal obstáculo para os agentes de IA
CAPTCHA significa "Completely Automated Public Turing Test to Tell Computers and Humans Apart". Seu propósito original era simples: manter bots fora e permitir que humanos entrem. Mas, à medida que a IA evoluiu, os CAPTCHAs também evoluíram continuamente — de letras distorcidas simples para sliders complexos, tarefas de seleção de imagens e sistemas de análise comportamental. Eles já não são apenas um problema de reconhecimento de caracteres.

Para scripts de automação tradicionais, os CAPTCHAs são quase uma sentença de morte. Mas para os Agentic Browsers, eles representam um desafio igualmente grave por três razões principais:
-
Aumento drástico da dificuldade de percepção: Mesmos os modelos multimodais mais avançados têm dificuldade em reconhecer com confiança texto fortemente distorcido, objetos de imagem turvos ou lacunas de slider escondidas em fundos complexos. A IA pode simplesmente "ver errado", e um único erro pode quebrar todo o fluxo de trabalho.
-
Mecanismos de incentivo antifalhas em camadas: CAPTCHAs modernos não são mais apenas desafios na interface. Os sites monitoram trajetórias do mouse, ritmos de digitação, tempo de permanência na página e até impressões digitais do navegador. Se o sistema determinar que o operador não "se comporta como um humano", a dificuldade do CAPTCHA pode aumentar instantaneamente — de simplesmente marcar uma caixa para resolver dez tarefas consecutivas de reconhecimento de imagem.
-
Sensibilidade ao tempo e interrupção contextual: CAPTCHAs geralmente têm limites de expiração. Quando um Agentic Browser fica preso em um CAPTCHA por muito tempo durante uma tarefa de múltiplas etapas, as sessões de login podem expirar, os produtos podem se esgotar e toda a cadeia de tarefas pode colapsar. É como um colapso súbito de uma ponte em uma estrada, parando todo o pipeline de automação.
Em outras palavras, sem a capacidade de superar os CAPTCHAs, os Agentic Browsers só podem viajar pelas "estradas de fundo sem proteção" da web, em vez de verdadeiramente navegar pelo sistema completo de sites do mundo real. É exatamente por isso que infraestruturas de resolução de CAPTCHA como a CapSolver existem.
1.2 Como a CapSolver abre caminho para os agentes de IA
A CapSolver não é uma ferramenta voltada para usuários comuns, mas sim um "motor de CAPTCHA" escondido profundamente nas ferramentas dos desenvolvedores. No núcleo, é uma plataforma de resolução de CAPTCHA inteligente que fornece interfaces de API especificamente projetadas para ajudar programas de automação e agentes de IA a lidar com diversos tipos de CAPTCHAs.
Podemos pensar nela como uma equipe de resolução de CAPTCHA disponível 24/7 que nunca se cansa e opera a uma velocidade extremamente alta — exceto que seus "membros da equipe" não consistem apenas em modelos de IA sofisticados, mas também em algoritmos de estratégia altamente otimizados.
Para entender melhor suas capacidades, a seguinte tabela compara as diferenças entre abordagens tradicionais e a CapSolver ao enfrentar os mesmos desafios de CAPTCHA:
| Dimensão de Comparação | OCR Local / Modelos Simples | Plataformas de Resolução de CAPTCHA por Humanos | CapSolver |
|---|---|---|---|
| Tipos de CAPTCHA Suportados | Apenas CAPTCHAs de texto simples; seleção de imagem é quase ineficaz | Teoricamente suporta todos os tipos, mas lento e caro | Cobre os principais tipos de CAPTCHA |
| Velocidade de Reconhecimento | Milissegundos, mas com baixas taxas de sucesso | 5–15 segundos por tentativa | 1–3 segundos por tentativa |
| Taxa de Sucesso | Baixa (pior em CAPTCHAs complexos) | Relativamente alta, mas afetada pelo cansaço dos trabalhadores e pela latência da rede | Alta e estável |
| Estrutura de Custo | Custo único de desenvolvimento | Pagamento por tarefa com altos custos de mão de obra | Pagamento por tarefa com preços baixos e custos marginais baixos |
| Capacidade de Anti-Detecção | Quase nenhuma | Não consegue lidar com sistemas de análise comportamental | Pode se integrar a ambientes de navegador e retornar tokens ou instruções compatíveis com risco |
Tabela 1-1 Comparação entre Métodos Tradicionais de Resolução de CAPTCHA e Capacidades da CapSolver
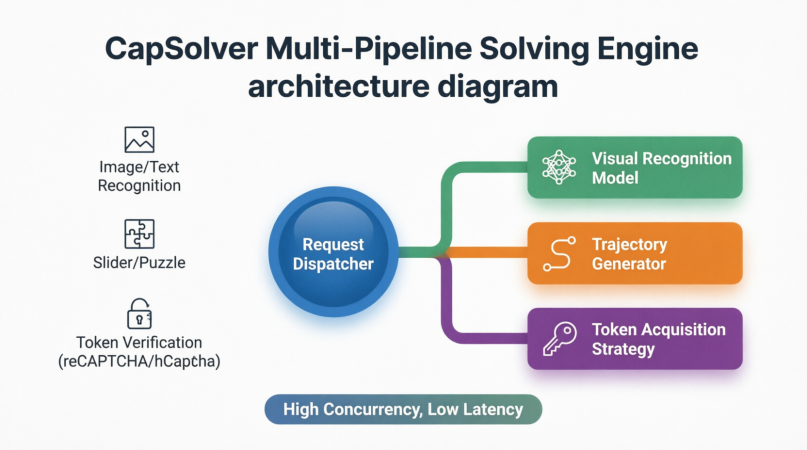
O princípio operacional central da CapSolver é essencialmente "IA contra IA, estratégia contra estratégia". Para diferentes tipos de CAPTCHAs, ela incorpora pipelines de resolução especializados:
-
CAPTCHAs de reconhecimento de imagem e texto: Usando modelos de visão proprietários combinados com grandes conjuntos de dados de treinamento, a CapSolver pode reconhecer com precisão texto distorcido, sobreposto ou com ruído.
-
CAPTCHAs de slider e quebra-cabeça: Em vez de saídas diretas de coordenadas de lacuna, ela gera trajetórias de movimento suave com base na análise ambiental, simulando tremores sutis, aceleração e desaceleração dos padrões de interação humana. Esses parâmetros comportamentais permitem que os programas de automação arrastem os sliders naturalmente por meio da verificação.
-
Sistemas de verificação baseados em tokens (reCAPTCHA v2/v3, Cloudflare, etc.): Esses CAPTCHAs não exigem entrada explícita do usuário. Em vez disso, avaliam o comportamento do navegador em segundo plano e retornam um token único. A CapSolver combina impressões digitais do navegador, reputação de IP, trajetórias do mouse e outros dados contextuais para obter tokens de verificação válidos por meio de interfaces de resolução dedicadas. O Agentic Browser simplesmente insere o token na página para passar pela verificação.
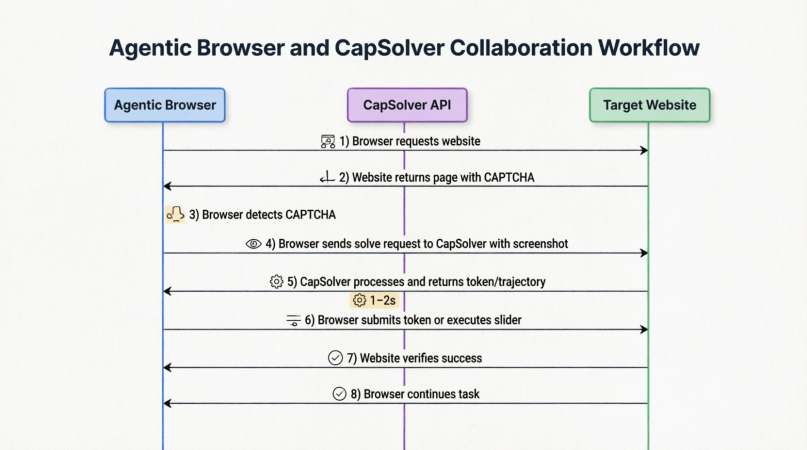
Como a CapSolver e os Agentic Browsers colaboram na prática? O seguinte diagrama ilustra o processo completo:
Desde o momento em que o navegador envia uma solicitação a um site, encontra um CAPTCHA, captura telas, chama a API da CapSolver, recebe um token ou trajetória comportamental, submete a verificação e retoma a tarefa original — todo o fluxo de trabalho está integrado de forma apertada e geralmente concluído em 1–2 segundos.
Isso significa que, para os Agentic Browsers, os CAPTCHAs já não são problemas que a IA precisa "ver" e "adivinhar" por si mesma. Em vez disso, tornam-se tarefas padronizadas terceirizadas para provedores de infraestrutura especializados. O navegador precisa apenas capturar o desafio, embalar o contexto, enviá-lo, esperar pela "chave" e continuar sua jornada.
1.3 O Fluxo de Trabalho Colaborativo Entre Agentic Browsers e CapSolver
Agora vamos conectar o módulo de adaptação dinâmica de um Agentic Browser com a CapSolver e examinar como eles trabalham juntos em uma "execução de superação de obstáculos" sem empecilhos.
Enquanto o Agentic Browser executa tarefas, sua camada de percepção ambiental monitora continuamente a página da web. Assim que um elemento de CAPTCHA for detectado (por exemplo, um pop-up contendo um iframe reCAPTCHA), a execução de ação pausa imediatamente e dispara um sub-processo dedicado à resolução de CAPTCHA.
Este processo é altamente sofisticado e geralmente inclui os seguintes passos:
-
Coleta de Contexto: O Agentic Browser captura telas da região do CAPTCHA e coleta informações contextuais, como a URL atual, sitekey, dimensões da janela do navegador e User-Agent.
-
Envio da Tarefa: As telas e os parâmetros são embalados juntos e enviados à CapSolver via API, especificando o tipo de CAPTCHA.
-
Resolução em Segundo Plano: Após receber a tarefa, a CapSolver a redireciona para o pipeline de resolução correspondente. Por exemplo, ao encontrar o reCAPTCHA v2, ela invoca um solucionador dedicado para retornar um token
g-recaptcha-responseválido. O processo de resolução geralmente é concluído em 1–2 segundos. -
Retorno de Instruções: O Agentic Browser recebe o resultado retornado — que pode ser uma string de token ou um conjunto de coordenadas de trajetória do mouse.
-
Execução no Local: O Agentic Browser insere o token em campos ocultos do formulário e submete o formulário, ou simula o movimento do slider humano de acordo com os dados de trajetória retornados. A camada do CAPTCHA desaparece e o fluxo de tarefa original retoma sem interrupções.
-
Verificação de Estado: O navegador verifica se a página passou com sucesso na validação e se os elementos de destino reapareceram antes de continuar com o fluxo de trabalho interrompido.
É importante notar que os CAPTCHAs modernos vêm em muitas formas com níveis variados de complexidade. O seguinte diagrama categoriza os principais tipos de CAPTCHA e marca seus níveis de complexidade correspondentes:
Para os usuários finais, todo o processo permanece completamente transparente. No log de tarefas do Agentic Browser, os usuários podem ver apenas uma mensagem simples, como:
"reCAPTCHA v2 detectado. Resolvido automaticamente em 1,2 segundos."
Um obstáculo que antes traria toda a cadeia de automação ao colapso é silenciosamente resolvido em segundo plano.
Isso também representa um salto crítico nas capacidades dos agentes de IA: o agente já não se assusta com sistemas de defesa especificamente projetados para bloquear a automação. Com a infraestrutura de resolução de CAPTCHA funcionando como um "motor invisível", os Agentic Browsers finalmente ganham a liberdade operacional necessária para executar tarefas de forma autônoma na Internet aberta.
Sem este motor, todas as promessas em torno dos agentes inteligentes poderiam facilmente colapsar no primeiro pop-up de CAPTCHA.
Capítulo 2: Onde os Agentic Browsers estão sendo aplicados hoje?
Se os capítulos anteriores fizeram essa tecnologia parecer distante, os seguintes exemplos podem mudar completamente sua perspectiva. Os Agentic Browsers não são conceitos abstratos flutuando no futuro — eles estão entrando rapidamente em três domínios principais: produtividade pessoal, automação empresarial e coleta de dados. Em cada área, eles estão resolvendo problemas práticos em diferentes níveis.
O seguinte diagrama resume os cenários principais de aplicação dos Agentic Browsers:
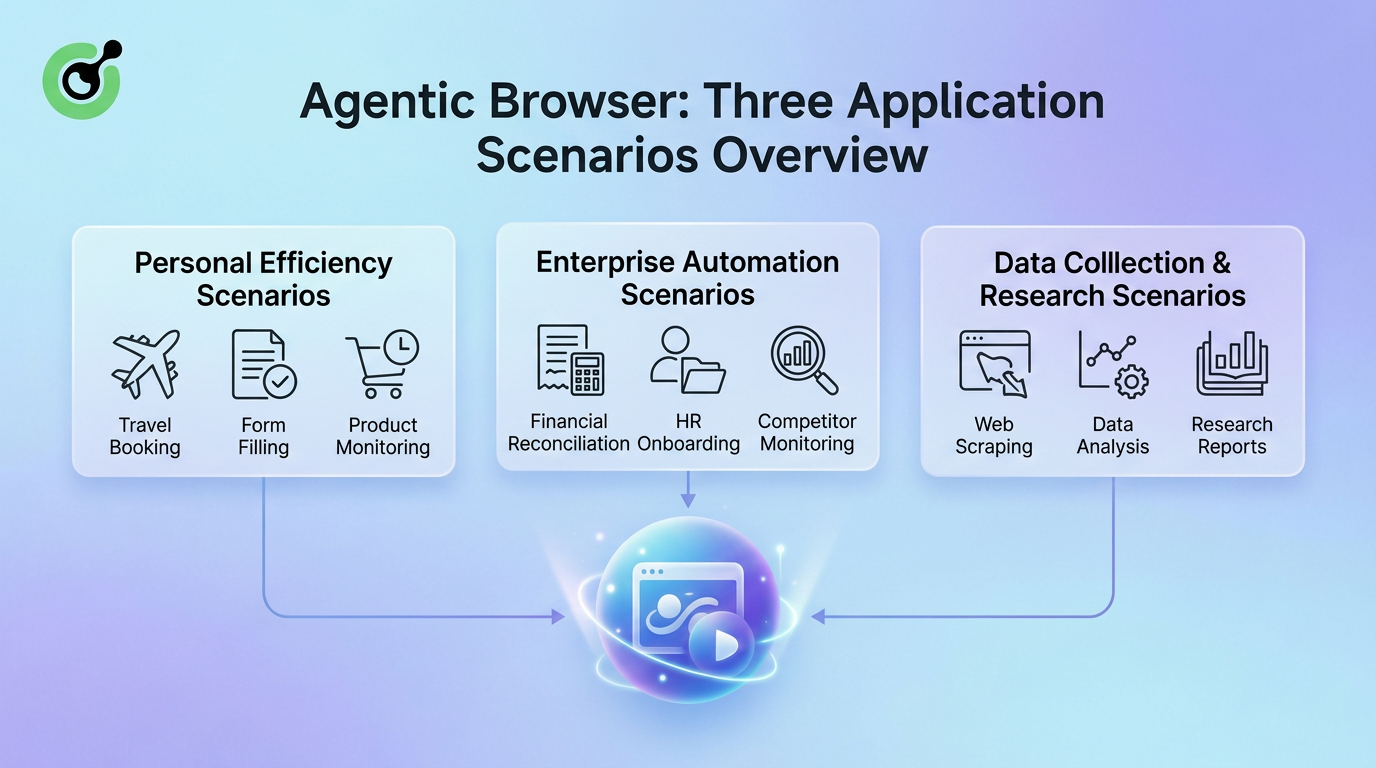
As aplicações dos Agentic Browsers se estendem desde usuários individuais até grandes empresas, desde tarefas diárias até fluxos de trabalho de pesquisa profissional. Na produtividade pessoal, eles ajudam os usuários a reservar viagens, preencher formulários repetitivos e monitorar flutuações de preços de produtos. Na automação empresarial, eles lidam com conciliação financeira, onboarding de funcionários e monitoramento de concorrentes. Na coleta de dados e pesquisa, servem como crawlers incansáveis e assistentes de análise inteligente.
A seguir, examinaremos esses três cenários em detalhes para entender como os Agentic Browsers "executam o trabalho" de fato.
2.1 Produtividade Pessoal: Delegação Inteligente de Tarefas Diárias
Para usuários comuns, o valor imediato de um Agentic Browser é simples: economizar tempo.
Todo dia, as pessoas realizam incontáveis tarefas repetitivas e de múltiplas etapas dentro dos navegadores. Essas tarefas geralmente compartilham três características:
- O objetivo é claro
- As regras são fixas
- As operações são tediosas
Os Agentic Browsers se destacam em assumir exatamente esses tipos de tarefas — situações em que os usuários sabem o que querem fazer, mas não querem realizar as operações manualmente.
Em cenários de produtividade pessoal, os Agentic Browsers podem ajudar com as seguintes tarefas típicas:
Reserva e Compra Automatizadas
Por exemplo, reservar voos, hotéis ou comprar produtos de lançamento limitado. Os usuários precisam apenas descrever seus requisitos em linguagem natural — como data, preferências ou orçamento — e o Agentic Browser pode comparar automaticamente preços entre sites, filtrar opções, preencher informações e apresentar o resultado ideal.
Integração de Informações e Preenchimento de Formulários Entre Sites
Tarefas como solicitações de visto, inscrições em escolas ou reembolsos de despesas frequentemente exigem que os usuários insiram informações repetidas em múltiplos formulários.
Um Agentic Browser atua como um "gerente de informações" ao lembrar de forma segura os dados do usuário, identificar automaticamente os campos de formulário e mapear inteligentemente. Por exemplo, ele pode dividir um nome completo em "Nome" e "Sobrenome" automaticamente.
Monitoramento Diário de Informações
Os Agentic Browsers podem monitorar estoque de produtos, mudanças de preço ou lançamentos de novos produtos em segundo plano. Assim que condições pré-definidas forem atendidas — como uma queda de preço ou reposição de estoque — o navegador notifica imediatamente o usuário ou até mesmo faz um pedido automaticamente.
Para ilustrar melhor a transformação na experiência do usuário, a seguinte tabela compara fluxos de trabalho tradicionais com fluxos de trabalho do Agentic Browser:
| Tipo de Tarefa | Tempo Gasto no Fluxo Tradicional | Fluxo de Trabalho do Agentic Browser | Transformação do Papel do Usuário |
|---|---|---|---|
| Comparar e reservar um voo | 15–30 minutos (navegando manualmente em vários sites) | 1 minuto (descrever requisitos e confirmar recomendações) | Do executor → tomador de decisão |
| Preencher formulários online complexos | 20–40 minutos (entrando repetidamente informações idênticas) | 2 minutos (revisar resultados de preenchimento automático e corrigir pequenas diferenças) | Do operador de entrada de dados → revisor |
| Monitorar reposições de produtos ou quedas de preço | Muito tempo (atualizações manuais e atenção constante) | 0 minutos (monitoramento em segundo plano com notificações automáticas) | Do monitor → receptor |
| Organização de dados multiplataforma | 1–2 horas (cópia e colagem e formatação) | 5 minutos (extração e formatação automáticas) | Do operador manual → analista |
Quadro 2-1 Comparação entre Tarefas Pessoais Tradicionais e Eficiência do Agentic Browser
Como mostrado acima, o Agentic Browser atua efetivamente como um assistente pessoal. Ele liberta os usuários de serem "operadores de fluxos de trabalho" e os transforma em "definidores de objetivos" e "revisores de resultados".
2.2 Automação Empresarial: Coordenação Inteligente entre Sistemas
Se as melhorias na produtividade pessoal se tratam de "reduzir o esforço", o valor dos Browsers Agenticos em ambientes empresariais está relacionado a conexão.
Organizações grandes frequentemente dependem de diversos sistemas legados, plataformas SaaS e portais de fornecedores que não se integram facilmente por meio de APIs. Os funcionários são forçados a se tornarem "colas humanas", transferindo manualmente informações entre sistemas repetidamente.
É exatamente nesse ponto que os Browsers Agenticos demonstram suas maiores vantagens.
Casos de uso empresarial típicos
- Reconciliação Financeira e de Cadeia de Suprimentos
Um Browser Agentic pode se autenticar automaticamente em portais bancários, baixar extratos, compará-los com sistemas ERP, gerar relatórios de discrepâncias e até redigir e-mails de notificação.
- Fluxos de Onboarding de Funcionários Completos
As organizações podem definir pacotes pré-definidos de tarefas de onboarding. O Browser Agentic cria automaticamente contas em sistemas de RH, sistemas de TI, listas de e-mails e sistemas de controle de acesso, garantindo que não haja omissões ou atrasos.
- Monitoramento de Concorrentes e Inteligência de Mercado
Os Browsers Agenticos podem funcionar como sistemas de "radar de mercado" ao visitar automaticamente sites de concorrentes, lojas de e-commerce e páginas de redes sociais, identificando mudanças na informação crítica e armazenando-as em bancos de dados estruturados.
Para ilustrar melhor a posição única dos Browsers Agenticos na automação empresarial, a tabela a seguir compara-os com operações manuais e integrações tradicionais por API:
| Dimensão | Operações Manuais | Desenvolvimento de Integração por API | Agentic Browser |
|---|---|---|---|
| Sistemas Aplicáveis | Qualquer sistema | Apenas sistemas com APIs abertas | Qualquer sistema baseado na web, incluindo sistemas legados internos |
| Ciclo de Implementação | Não é necessário desenvolvimento, mas é trabalhoso | Semanas a meses (depende dos recursos de desenvolvimento) | Horas a dias (configuração e teste de tarefas) |
| Flexibilidade | Alta (humanos se adaptam dinamicamente) | Baixa (reescrita de interfaces é necessária após mudanças) | Alta (IA se adapta dinamicamente às mudanças nas páginas) |
| Tratamento de CAPTCHA/Logon | Tratamento manual necessário | Geralmente difícil de lidar diretamente | Invoca automaticamente motores de resolução de forma transparente |
| Escalabilidade | Pobre | Extremamente forte | Forte (execução de tarefas paralelas possível) |
| Cenários de Falha Comuns | Fadiga humana e omissões | Limites de taxa de API ou incompatibilidade de versão | Pode exigir confirmação humana em condições de página extremamente caóticas |
Quadro 2-2 Comparação das Soluções de Automação Empresarial entre Sistemas
Como mostrado acima, os Browsers Agenticos não são projetados para substituir APIs. Em vez disso, eles fornecem uma camada de integração leve em situações onde APIs estão indisponíveis ou são muito caras para implementar.
Ao aproveitar a flexibilidade e adaptabilidade da IA, os Browsers Agenticos preenchem as lacunas deixadas pelos métodos tradicionais de automação, permitindo que as empresas alcancem coordenação inteligente entre sistemas sem reconstruir a infraestrutura legada.
2.3 Coleta de Dados e Pesquisa: Da Coleta Manual à Extração Inteligente
Dados são frequentemente descritos como o "óleo da era digital", no entanto, coletar dados públicos limpos da web de forma eficiente sempre foi difícil.
Crawladores tradicionais dependem de regras fixas de análise. Assim que os sites-alvo redesenharem seus layouts ou introduzirem medidas anti-scraping, os crawladores frequentemente falham completamente. Pesquisadores acadêmicos, empresas de pesquisa de mercado e equipes de jornalismo investigativo frequentemente precisam extrair informações específicas de um grande número de páginas web heterogêneas, tornando os métodos tradicionais caros e demorados.
Os Browsers Agenticos introduzem um paradigma totalmente novo para coleta de dados:
Uma mudança da extração baseada em "regras de código" para extração baseada em "objetivos semânticos".
Seu fluxo de trabalho geralmente opera da seguinte forma:
Os pesquisadores descrevem as dimensões de dados necessárias e os intervalos de amostras usando linguagem natural. Por exemplo:
"Extraia títulos de produtos, preços, avaliações e contagens de avaliações das 100 primeiras páginas de produtos de e-commerce, excluindo produtos patrocinados."
O Browser Agentic navega autonomamente pelas páginas da web, identifica blocos de informações relevantes por meio da percepção ambiental, extrai e estrutura os dados de forma inteligente e lida com interações complexas como paginação, rolagem infinita e popups.
Quando os sites-alvo redesenham seus layouts, os crawladores tradicionais colapsam imediatamente. Em contraste, os Browsers Agenticos tentam localizar informações visualmente e continuam a execução.
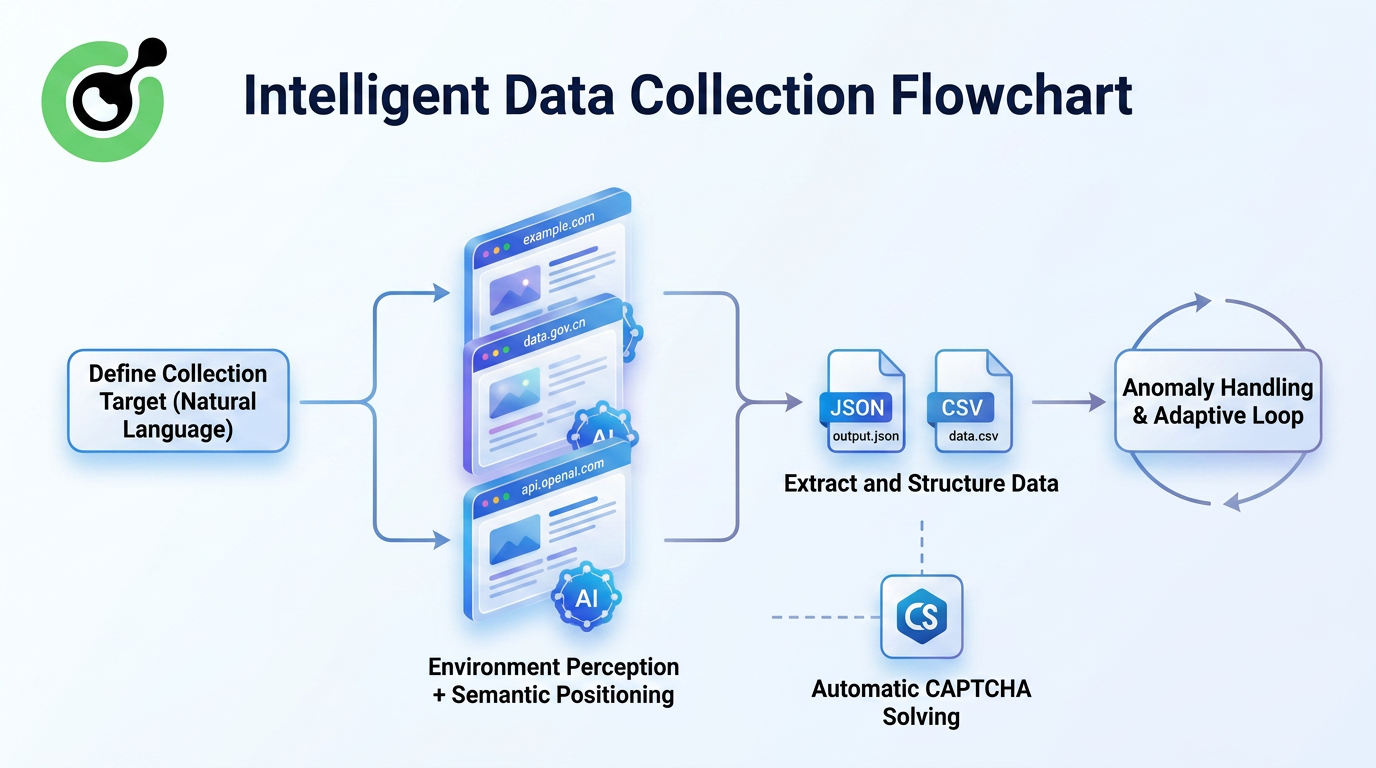
Essa abordagem introduz várias melhorias fundamentais:
- Não há necessidade de manter regras de análise
A IA entende o que é um "preço" semanticamente, em vez de depender de nomes de classes HTML fixos.
- Maior robustez contra redesenhos de sites
Mudanças menores nos layouts não quebram imediatamente os pipelines de extração.
- Capacidade de lidar com interações complexas
Para sites que exigem login, rolagem infinita ou troca de abas, os Browsers Agenticos interagem com a interface como usuários reais antes de extrair informações.
- Fluxos de trabalho de pesquisa reprodutíveis
Configurações de tarefas podem ser salvas e compartilhadas, tornando a coleta de dados padronizada e reprodutível.
Para demonstrar melhor as vantagens de resiliência dos Browsers Agenticos em tarefas de coleta de dados, a figura a seguir compara crawladores tradicionais e Browsers Agenticos após múltiplos redesenhos de sites:
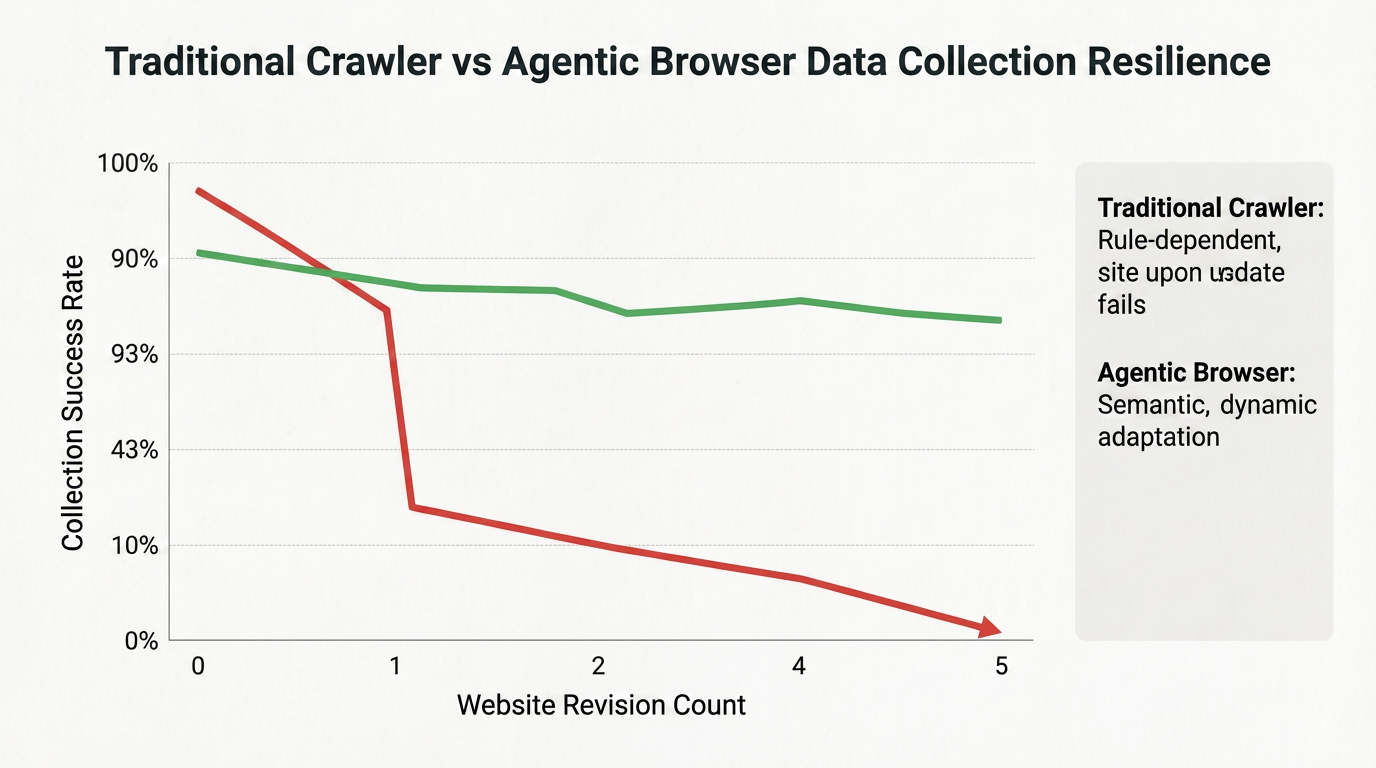
Crawladores tradicionais experimentam quedas drásticas na taxa de sucesso após o primeiro redesenho do site, enquanto os Browsers Agenticos mantêm taxas relativamente altas de extração mesmo após múltiplos redesenhos, graças às suas capacidades de localização visual e compreensão semântica.
Essa resiliência os torna ideais para projetos de coleta de dados de longo prazo e de grande escala.
Por exemplo, imagine uma equipe de pesquisa em ciências sociais que precisa comparar cláusulas específicas de políticas em 200 sites de políticas em 30 países. Tradicionalmente, isso exigiria que assistentes de pesquisa gastassem meses copiando e organizando informações manualmente.
Agora, os pesquisadores podem configurar uma tarefa do Agentic Browser que percorra automaticamente esses sites, localize páginas de políticas contendo palavras-chave alvo, extraia as cláusulas relevantes e as categorize automaticamente.
Os pesquisadores precisam apenas revisar e analisar os resultados coletados posteriormente, permitindo que o esforço humano valioso se concentre na "pesquisa" real, em vez de trabalho repetitivo de "transporte manual".
Conclusão
O Agentic Browser não representa apenas um novo produto, mas uma nova filosofia de estar online. Sua lógica central é: o navegador não deve ser apenas uma interface esperando que você clique, mas um agente inteligente que entende seu intuito e o ajuda a completar tarefas. Do ponto de vista da implementação técnica, ele depende da capacidade de raciocínio de modelos de linguagem de grande porte para planejar tarefas, percepção multimodal para entender páginas da web, um ambiente de navegador real para executar operações e infraestrutura como CapSolver para eliminar obstáculos no caminho da automação. A fusão dessas tecnologias está transformando a "janela de informação" que usamos há trinta anos em uma verdadeira "plataforma de ação".
Perguntas Frequentes
Q1: Por que modelos de IA gerais não conseguem resolver CAPTCHAs por conta própria?
A1: Embora modelos de IA gerais sejam poderosos, CAPTCHAs são especificamente projetados para serem adversários e mudarem constantemente. Resolver de forma confiável e rápida requer infraestrutura especializada como o CapSolver, que se dedica exclusivamente a essa tarefa.
Q2: Como o CapSolver ajuda os Browsers Agenticos?
A2: O CapSolver atua como um "motor invisível" que lida com desafios de CAPTCHA por meio de uma simples API. Isso permite que o Agentic Browser contorne obstáculos de segurança de forma transparente e continue sua tarefa sem intervenção humana.
Q3: Os Browsers Agenticos substituirão empregos humanos?
A3: Eles são projetados para substituir "tarefas", não "empregos". Ao lidar com trabalho digital repetitivo, eles libertam os humanos para se concentrarem em criatividade e tomada de decisões estratégicas de nível superior.
Q4: Como posso começar a usar um Agentic Browser hoje?
A4: Muitos navegadores e extensões experimentais já estão disponíveis. No entanto, para a melhor experiência, certifique-se de ter um serviço de resolução de CAPTCHA confiável como o CapSolver integrado para lidar com os obstáculos de segurança da web.
Ver mais
Web ScrapingJul 22, 2026
Monitoramento de Regressão do SEO Técnico: Pipeline de Automação
Construa um monitoramento de regressão de SEO técnico com bases versionadas, diferenças semânticas, alertas verificados e uma etapa opcional de recuperação CAPTCHA autorizada.
CloudflareJul 22, 2026
Solução de CAPTCHA MCP: Guia de Integração do Cloudflare Turnstile
Construa um fluxo de trabalho MCP Cloudflare Turnstile com gate de política, retries limitados, logs redatados, verificações de sessão e validação de resultados.