AIによるブラウザの自動化:オンラインのプライバシーと個人情報の削除に関する実用的なガイド

Sora Fujimoto
AI Solutions Architect
TL;DR
- オンラインプライバシーおよび個人情報削除のためのAIブラウザ自動化は、監視付きワークフローとして最も効果的であり、盲目的なスクリーピングスクリプトよりも優れている。
- 安全なプロセスは、露出したデータを発見し、センシティブな記録を優先順位付け、法的リクエストを提出し、証拠を保存し、再出現を監視することである。
- 検索結果の削除、ウェブサイトの削除、アカウントの閉鎖、データブローカーからのオプトアウトは、異なるタスクである。
- プライベート、制限付き、または不正なデータは常に公平な対象ではないため、各ステップでコンプライアンスが重要である。
- 繰り返しオプトアウトを行う際にCAPTCHAやトラフィック検証のチャレンジが表示される可能性があるため、アクセスが許可されているドキュメント化されたツールのみを使用する。
イントロダクション
オンラインプライバシーおよび個人情報削除のためのAIブラウザ自動化は、プライバシーのクリーンアップが繰り返し、証拠が多く、追跡が難しい場合に役立ちます。これは、個人、プライバシーチーム、セキュリティオペレーションチームが、検索結果、公開ページ、アカウント設定、データブローカーのフォームで法的な削除リクエストを整理するのに役立ちます。コア価値はスピードそのものではなく、一貫性、監査可能性、そしてセンシティブなアクションの前に人間のレビューです。Googleは、検索結果から一部のプライベートな個人識別情報は削除できると述べていますが、ソースウェブサイト自体からは削除できません。この違いが全体のワークフローを形作ります。自動化は補助的に役立ちますが、法的権利、サイトルール、および承認が何をすべきかを定義します。
このプライバシー削除シナリオが自動化を必要とする理由
オンラインプライバシーおよび個人情報削除のためのAIブラウザ自動化は、実用的な調整問題を解決します。個人情報は、検索スニペット、キャッシュページ、公開ディレクトリ、ブローカープロフィール、古いアカウント、アーカイブコンテンツに表示されることがあります。各ソースには、異なるフォーム、証明、待機期間、フォローアップが必要です。
小さな範囲であれば、手動での削除は可能です。しかし、複数の名前、住所、電話番号、職務プロフィール、古いアカウントを持つ場合、脆弱になります。ブラウザ自動化は、フォームを開き、スクリーンショットを収集し、タイムスタンプを記録し、各リクエストをレビューキューに配置できます。ユーザーはそれでも何を提出するかを決定します。
これはまた、リスク削減のワークフローでもあります。FTCは、ウェブサイトやアプリがクッキー、ピクセル、デバイスファINGERプリント、広告識別子を使用してオンライン活動を追跡する可能性があると説明しています FTCオンラインプライバシーガイド。露出した記録の削除はプライバシーハイジーンの一部に過ぎません。チームは、ブラウザ設定、アカウント設定、データ最小化を通じて将来的な収集を減らすことも重要です。
競合がよく見落とすAIブラウザ自動化の点
多くのプライバシーガイドは削除すべきものを説明します。しかし、スケールで削除を実行する方法を説明するものは少ないです。一般的な記事は、Googleの削除リクエスト、サイトオーナーへのメール、データブローカーからのオプトアウト、ソーシャル設定、継続的なモニタリングをカバーしています。これらのセクションは役立ちますので、このガイドも含みます。
欠如しているのは運用設計です。オンラインプライバシーおよび個人情報削除のためのAIブラウザ自動化には、キュー、証拠の収集、人間の承認、リトライ制限、監査ログが必要です。
もう一つのギャップはチャレンジの処理です。繰り返しのプライバシーフォームはreCAPTCHA、Cloudflareチャレンジ、または他のトラフィック検証をトリガーする可能性があります。この制御されたブラウザ層のための背景として、CapSolverの開発者向けブラウザ自動化のガイドが役立ちます。
ステップ1: 個人情報が表示される場所をマッピングする
発見から始めます。オンラインプライバシーおよび個人情報削除のためのAIブラウザ自動化は、広範な収集ではなく、ユーザーが承認したクエリから始めるべきです。既知の名前、メールアドレス、電話番号、ユーザー名、古い雇用主、公開プロフィールURLを検索します。
発見を4つのバケットに分類します。検索結果はリンクとスニペットです。ソースページはコンテンツをホストしているウェブサイトです。アカウントシステムは、ユーザーがサインインしてデータを編集できるサービスです。データブローカーは、個人情報を収集、販売、または共有するエンティティです。
証拠を単純に保ちます。URL、表示されるデータフィールド、スクリーンショット、発見日、ソースタイプ、およびセキュリティレベルを保存します。自動化がそれをキャプチャできるからといって、追加の個人情報を保存しないでください。NISTは、プライバシーリスク管理を、個人のプライバシーを保護しながらデータの使用を管理する企業プロセスとして説明しています NISTプライバシーフレームワーク。この原則は、内部の削除ツールにおいても適用されます。
ステップ2: 適切な削除経路を選ぶ
各記録を実際のコントロールポイントにマッチさせます。オンラインプライバシーおよび個人情報削除のためのAIブラウザ自動化は、すべての露出を同じフォームのように扱うと失敗します。検索削除は可視性を低下させます。ソース削除はページを削除または編集します。アカウントの閉鎖はユーザーが制御するデータを削除します。ブローカーからのオプトアウトは、ブローカーシステムからの抑制または削除を依頼します。
Google検索の場合、リクエストを提出する前に正確なURLを収集してください。Googleは、リクエストフォームが特定のURLをレビューし、検索結果からコンテンツをホスティングサイト自体から削除しないと述べています <a これは、検索結果のタスクの後にソースページのタスクを作成する自動化が意味します。
データブローカーのリクエストの場合、資格と管轄が重要です。 カリフォルニア DROPプラットフォームは、資格のある住民が登録されたデータブローカーに一度のリクエストを送信でき、ブローカーがそのタイムラインに従ってリクエストを処理を開始すると述べています。同じコンセプトは他の場所でも適用されます。リクエストを送信する前に、ローカル法、証明要件、代表者への承認を確認してください。
比較要約
| アプローチ | 最適な使用ケース | 主な利点 | 主な制限 | コンプライアンス制御 |
|---|---|---|---|---|
| 手動削除 | 小さな個人的な範囲 | ユーザー全体のコントロール | 遅く、繰り返しづらい | ユーザーがすべての提出をレビュー |
| マネージドプライバシーサービス | 広範な消費者オプトアウト | 継続的なブローカー監視 | ワークフローの可視性が少ない | 承認とレポートのレビュー |
| AIアシスタントブラウザワークフロー | 繰り返しケースを持つチーム | 証拠、キュー、再現性 | 治理とテストが必要 | 人間の承認、ログ、範囲ルール |
| APIファースト削除 | 公式APIを持つサイト | 安定しており監査可能 | すべての場所で利用可能とは限らない | ドキュメント化されたエンドポイントのみを使用 |
ステップ3: 安全に自動化ワークフローを構築する
狭いワークフローを使用してください。オンラインプライバシーおよび個人情報削除のためのAIブラウザ自動化は、ウェブ全体をさまようべきではありません。承認されたURL、事前に定義されたフォームフィールド、ドキュメント化された決定ルールに従うべきです。
実用的なワークフローには6つのステージがあります。最初に、ユーザーがターゲットリストを承認します。第二に、ブラウザがクリーンなプロファイルで各ページを開きます。第三に、システムは必要なフィールドのみを抽出します。第四に、システムはリクエストドラフトを準備します。第五に、人間が提出を確認します。第六に、システムは確認ページ、メール受領証、またはスクリーンショットを保存します。
すべてのリクエストにはステータスが必要です。発見済み、ドラフト作成中、提出済み、待機中、検証済み、拒否、再確認などの値を使用してください。これにより、プロセスが読みやすくなり、サイトオーナーを煩わせたり、トラフィック検証をトリガーする繰り返しの提出を防ぐことができます。
技術チーム向けに、ツールの選択が重要です。このCapSolverの記事セレニウムとパペットーリーのCAPTCHA解決は、自動化環境の文脈を提供します。プライバシーの決定は依然として最優先されます。
ステップ4: プライバシー・バイ・デザインの制御を追加する
ガバナンスはスピードよりも先に来るべきです。オンラインプライバシーおよび個人情報削除のためのAIブラウザ自動化は、名前、住所、スクリーンショット、場合によってはアイデンティティ証拠を扱います。収集できるデータよりも少ないデータを保存してください。リクエスト記録を暗号化してください。ロールベースでアクセスを制限してください。保存期間後に証拠を削除してください。
偽のアイデンティティでフォームを提出しないでください。所有者の許可なしにプライベートアカウントにアクセスしないでください。ユーザーのリクエスト中に第三者データを収集しないでください。
ワークフローはまた、レートリミットを尊重すべきです。ノイズの多い自動化よりも、ゆっくりと追跡可能な実行が良いです。公式フォーム、明確なメール、ドキュメント化されたAPIを優先してください。
強力なレビュー画面は、ターゲットURL、要求されたアクション、個人フィールド、既知の法的根拠、添付証拠を表示すべきです。
ステップ5: CAPTCHAとトラフィック検証を責任を持って処理する
繰り返しのプライバシーワークフローではチャレンジが一般的です。オンラインプライバシーおよび個人情報削除のためのAIブラウザ自動化は、reCAPTCHA v2、reCAPTCHA v3、Cloudflareチャレンジ、画像クリックタスク、またはメール確認リンクに遭遇する可能性があります。これらを障害ではなくチェックポイントとして扱ってください。
安全なルールは単純です。ユーザーまたは組織がそのページにアクセスする正当な理由がある場合にのみ、続行してください。アクセスに失敗した場合、利用規約を確認し、頻度を減らすか、公式なチャネルを使用してください。
CapSolverは、チャレンジ処理が許可された自動化ワークフローの一部である場合に役立ちます。reCAPTCHA v2の場合、公式ドキュメントではcreateTaskを使用してタスクを作成し、getTaskResultで結果を取得する必要があります。reCAPTCHA v2ガイドに記載されています。reCAPTCHA v3の場合、reCAPTCHA v3ガイドにはReCaptchaV3TaskProxyLessなどのタスクタイプが記載されており、SDK例にpageActionが含まれています。
公式SDKスタイルのパターンは以下の通りです:
python
# pip install --upgrade capsolver
# export CAPSOLVER_API_KEY='...'
import capsolver
# capsolver.api_key = "..."
solution = capsolver.solve({
"type": "ReCaptchaV3TaskProxyLess",
"websiteURL": "https://www.google.com",
"websiteKey": "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_kl-",
"pageAction": "login",
})Cloudflareチャレンジの場合、CapSolverのCloudflareチャレンジガイドはAntiCloudflareTask、websiteURL、必要な静的またはスタックプロキシ、一貫したuserAgentの取り扱いを記載しています。プライバシーワークフローでヘッドレスブラウジングを使用する場合、ヘッドレスブラウザでのCAPTCHA解決の自動化のガイドは、より広範な実装の文脈を提供します。
ステップ6: 削除の確認と再出現のモニタリング
確認はワークフローを完了します。オンラインプライバシーおよび個人情報削除のためのAIブラウザ自動化は、待機期間後に提出されたURLを再訪し、表示されるフィールドを比較し、証拠とともに結果をマークすべきです。フォームを提出したからといって成功すると仮定しないでください。
データは再出現する可能性があります。ブローカーは記録を更新し、検索エンジンはページを再クロールし、古いアカウントはプロフィールフィールドを再暴露する可能性があります。ほとんどの人々にとって、月次または四半期ごとの再チェックは実用的です。高リスクの役割では、より頻繁なモニタリングが必要です。
モニタリングを範囲内に保ちます。承認されたURL、既知のクエリ用語、確認済みのブローカーリストのみを再チェックしてください。新しい個人情報が表示された場合、自動的に提出するのではなく、新しいレビュータスクを作成してください。これにより、ユーザーとワークフローを実行する組織を保護できます。
CapSolverのAIブラウザCAPTCHAソルバーに関する記事は、繰り返しのモニタリングが検証ページに達したときに関連しています。その使用は、法的、合理的、ドキュメント化された自動化に限定されるべきです。CapSolverのCAPTCHA解決がウェブスクレイピングで合法かどうかに関するFAQは、内部レビューをサポートします。
結論とCTA
オンラインプライバシーおよび個人情報削除のためのAIブラウザ自動化は、狭く、ドキュメント化され、監視されているときに最も効果的です。これは、露出した記録を発見し、正しい削除経路を選択し、法的なリクエストを準備し、証拠を収集し、再出現をモニタリングするのを支援すべきです。これは、承認、法的レビュー、または人間の判断を置き換えてはなりません。
最も良いプライバシーワークフローは、自動化と制限の組み合わせです。公式フォームを使用し、サイトルールを尊重し、最小限の証拠を保存し、敏感なリクエストを提出する前に人間の承認を求めてください。reCAPTCHA、Cloudflare、または画像クリックチャレンジが許可されたワークフローに表示された場合、CapSolverの公式ドキュメントを確認し、ドキュメント化されたパターンのみを使用してください。CapSolverは、プライバシーリモーブが繰り返しフォーム提出、ブラウザセッション、チャレンジ処理を含むため、この繰り返しシナリオに適合します。コンプライアンスプロセスから始め、そのプロセスをサポートする場所にCapSolverを追加してください。
CapSolverボーナスコードを獲得する
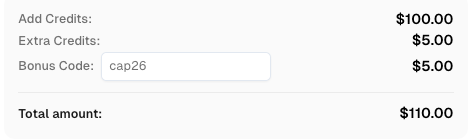
すぐに自動化予算を増やす。CapSolverアカウントにチャージする際にボーナスコード CAP26 を使用すると、すべてのチャージで追加の5%ボーナスを獲得できます。
今すぐCapSolverダッシュボードで獲得してください
FAQ
オンラインプライバシーおよび個人情報削除のためのAIブラウザ自動化は合法ですか?
適用可能な法律、サイトの利用規約、ユーザーの承認に従う場合、合法です。最も安全なワークフローは、承認されたターゲット、人間のレビュー、ドキュメント化されたリクエスト、および最小限のデータ収集を含みます。
自動化はインターネット上のすべての個人情報を削除できますか?
いいえ。オンラインプライバシーおよび個人情報削除のためのAIブラウザ自動化は、露出を減らすことができますが、完全な削除は現実的ではありません。検索結果の削除、ソース削除、ブローカーからのオプトアウト、アカウントのクリーンアップにはそれぞれ異なる制限があります。
ワークフローが保存すべきデータは何ですか?
リクエストを証明し、フォローアップをサポートするもののみを保存してください。通常、これはURL、スクリーンショット、日付、リクエストタイプ、ステータス、確認証拠を意味します。関係のない個人データを収集しないでください。
プライバシーリクエスト中にCAPTCHAチャレンジをチームがどのように処理すべきですか?
まず、アクセスが許可されているかを確認してください。ワークフローが正当であれば、CapSolverのreCAPTCHAおよびCloudflareガイドなどの公式ドキュメントを使用してください。非公式パラメータを追加しないでください。
個人情報はどのくらいの頻度で再チェックすべきですか?
ほとんどのユーザーは月次または四半期ごとに行うことができます。高いリスクを持つユーザーは、より頻繁なレビューが必要です。重要なのは、承認されたソースをモニタリングし、制御されていないスキャンを避けることです。