urllib3 と Requests: どの Python の HTTP ライブラリを使うべきですか?

Sora Fujimoto
AI Solutions Architect

TL;DR
- urllib3とRequestsの選択は、主に低レベルなコントロールと高レベルな開発者体験のどちらを重視するかにかかっています。
- APIクライアント、スクリプト、データワークフロー、読みやすいアプリケーションコードの場合は、Requestsが通常はより良いデフォルトです。
- 接続プールの明示的制御、リトライの挙動、TLS設定、ライブラリレベルのトランスポート制御が必要な場合、urllib3が適しています。
- 両方のライブラリは同期的であるため、重い非同期ワークロードにはHTTPX、aiohttp、または他の非同期クライアントが必要です。
- 合法的な自動化でCAPTCHAチャレンジに遭遇した場合、CapSolverはチャレンジ処理をサポートし、HTTPライブラリは通常のリクエスト処理を担当します。
イントロダクション
大多数のチームにとってRequestsは最適な出発点ですが、トランスポート制御がコードの簡潔さよりも重要である場合はurllib3がより適しています。このurllib3対Requestsのガイドは、API、スクレイピング、QA自動化、モニタリング、バックエンドサービス用のPython HTTPライブラリを選ぶPython開発者向けです。コアな価値は単純です:保守性と開発速度が重要であればRequestsを選択し、プールやリトライ、低レベルHTTP挙動の直接的な制御が必要であればurllib3を選択してください。自動化ワークフローがトラフィック検証やCAPTCHAチャレンジに直面している場合、CapSolverはコンプライアンスに合ったチャレンジ処理の選択肢となり、コードは依然としてサイトの利用規約やデータアクセスルールを尊重します。
簡潔な回答:まずRequestsを使用し、コントロールが必要な場合はurllib3を使用
urllib3対Requestsの選択には実用的なデフォルトがあります。直接理由を説明できる場合を除き、通常はRequestsを使用してください。RequestsはHTTPを普通のPythonメソッドとして扱います。ヘッダー、パラメータ、クッキー、セッション、リダイレクト、JSONレスポンス、ストリーミングダウンロード、プロキシなどの一般的なニーズをコンパクトなAPIで処理します。公式のRequestsドキュメントでは、Keep-AliveとHTTP接続プールが自動的に行われることを述べており、Requestsは内部でurllib3を使用していると記載されています Requestsドキュメント。
urllib3は劣ったツールではありません。多くのPythonプロジェクトが依存するトランスポートエンジンです。urllib3プロジェクトは、スレッドセーフな接続プール、リトライ、リダイレクト、SSL/TLS検証、圧縮サポート、プロキシサポートを備えたHTTPクライアントとして自己紹介しています PyPI上のurllib3。これは、接続挙動を可視化・設定する必要がある内部SDK、インフラサービス、高ボリュームクライアントにおいて強力な選択肢となります。
Requestsが得意とする点
Requestsは通常のHTTPタスクを簡単にします。これはurllib3対Requestsの決定において、主な利点です。典型的なAPIコールは数行で書け、レスポンスオブジェクトはステータスコード、テキスト、ヘッダー、JSONパースなどの明確な属性を提供します。これは、プロジェクトが複数の開発者によって保守される場合に重要です。最初のスクリプトを書いた人だけではなく、他の開発者にとっても。
Requestsには大きなエコシステムがあります。そのPyPIページには、週に約3億回のダウンロードと、プロジェクトの説明に400万以上の依存リポジトリが記載されています PyPI上のRequests。人気はアーキテクチャの決定要因にはなりませんが、トラブルシューティング、例、コードレビューの親しみやすさを向上させます。
urllib3が得意とする点
urllib3はトランスポート層へのより直接的なアクセスを提供します。これは、urllib3対Requestsが単純な初心者対エキスパートの比較ではない理由です。PoolManagerが中心的な概念として公開されています。ユーザーガイドでは、PoolManagerが接続プールとスレッドセーフを処理し、request()が任意のHTTPメソッドでリクエストを生成できることを説明しています urllib3ユーザーガイド。
この明示的なモデルは、HTTPクライアントがより大きなシステムの一部である場合に役立ちます。プールサイズ、ホスト固有の挙動、リトライポリシー、タイムアウト、リダイレクト、TLSの詳細、レスポンスのストリーミングを考慮できます。これは、再利用可能なSDKや、負荷下で予測可能な挙動が必要なサービスを構築する際に役立ちます。
比較要約
urllib3対Requestsの判断基準を比較すると、明確になります。以下の表は、一般的な機能リストではなく、実用的なスコアリングスタイルを使用しています。
| 決定要因 | Requests | urllib3 | より良い選択 |
|---|---|---|---|
| 初心者向けの可読性 | get()やpost()などの簡単なメソッドで非常に強力 | 設定がより明示的で、一般的には良いが | Requests |
| 接続プール | Sessionsを通じて自動的に行われ、内部でurllib3を使用 | PoolManagerを通じて直接的に行われる | 両方とも同等。urllib3はより多くのコントロールを提供 |
| リトライ設定 | urllib3ユーティリティを使用してアダプターを通じて利用可能 | 本格的で明示的 | urllib3 |
| JSONレスポンス処理 | 非常に使いやすい | 現代のurllib3ではサポートされていますが、低レベルな使用が一般的 | Requests |
| TLSとトランスポートチューニング | 可能ですが、抽象化されている | より直接的で可視性が高い | urllib3 |
| API統合 | 簡単に書け、レビューしやすい | トランスポートの詳細が重要である場合に良い | Requests |
| 内部SDK | 簡単なSDKには良い | トランスポート挙動を制御するには強い | urllib3 |
| 非同期ワークロード | デフォルトでは不適切 | デフォルトでは不適切 | 代替手段を検討 |
構文と開発者体験
Requestsは最初の読みやすさで勝っています。urllib3対Requestsの例では、Requestsは自然なPythonに近いです。基本的なコールは通常、直接的なアクションとして読み込まれます。例えば、requests.get(url)。同じurllib3のコールは、メソッド文字列、PoolManager、または直接的なレスポンスバイト処理が必要になる場合があります。
urllib3は読みにくいわけではありません。より明示的です。この違いは、本番環境において重要です。明示的なクライアントは隠れた状態の検査を容易にします。しかし、通常のAPIクライアントを書くチームにとっては、追加のコントロールが避けられないコードを生む可能性があります。最善のルールは明確です:トランスポートレイヤーがアプリケーション設計の一部でない限り、アプリケーションコードにはRequestsを使用してください。
パフォーマンス、プール、スケーラビリティ
パフォーマンスは単一のベンチマークに還元できません。urllib3対Requestsにおいて、両方のライブラリは十分に高速です。Requestsは内部でurllib3を使用しているためです。より重要なのは、接続をどのように再利用するか、タイムアウトをどのように設定するか、リトライをどのように処理するか、レスポンスをどのように閉じるかです。
小さなスクリプトでは、Requestsのオーバーヘッドは通常、主要な問題ではありません。ネットワーク遅延、サーバーの応答時間、レートリミット、DNS、TLSの交渉、ペイロードサイズが通常はより重要です。長時間実行されるワーカーでは、PoolManagerにより接続挙動がより可視化されるため、urllib3は調整がより簡単です。タイムアウトとリトライルールは、POST、PUT、または支払いのような操作において、どちらのライブラリでも明示的であるべきです。
ワイドスクラビング、自動化、責任ある使用
urllib3対Requestsの比較は、ワイドスクラビングの議論にも現れます。Requestsはヘッダー、クッキー、セッションを読みやすくするため一般的です。接続プールや低レベルトランスポート設定が重要である場合、urllib3は有用です。許可されたページや単純なレスポンスにおいて、ワイドスクラビングやモニタリングにはどちらのライブラリも機能します。
コンプライアンスは選択肢ではありません。技術的な能力は、プライベート、制限、機密、または許可されていないデータへのアクセスを許可しません。関連するrobots.txtを確認し、利用規約を読み、レートリミットを尊重し、適切な場合にクライアントを識別し、法的根拠がない限り個人情報や機密データを収集しないでください。CapSolverのワイドスクラビングFAQとAIと自動化FAQは、自動化ワークフローを設計するチームにとって有用な内部リソースです。
許可されたワークフローがCAPTCHAチャレンジに遭遇した場合、HTTPライブラリはシステムの一部にすぎません。Requestsやurllib3は通常のHTTPリクエストを送信できますが、チャレンジ処理には専用のサービスが必要になる場合があります。CapSolverは公式ドキュメントでAPIサーバーエンドポイントとcreateTaskフローをドキュメント化しています CapSolver APIサーバードキュメント CapSolver createTaskドキュメント。公式ドキュメントのみを使用し、タスクパラメーターやエンドポイントを自作しないでください。
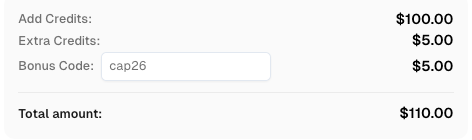
CapSolverのボーナスコードを引き換える
自動化予算を即座に増やす!
CapSolverアカウントにチャージする際にボーナスコード CAP26 を使用して、毎回 5%のボーナス を獲得してください — 制限なし。
CapSolverダッシュボードで今すぐ引き換える
追加の背景情報として、CapSolverのワイドスクラビングでのCAPTCHAの解決ガイドは、これらの問題を実際のPythonワークフローに結びつけます。
プロジェクトタイプ別の意思決定フレームワーク
urllib3対Requestsの選択は、個人の好みではなく、プロジェクトタイプによって決まります。ワンオフスクリプトでは、大多数の場合Requestsが正しい選択です。コード量を減らし、レビューの摩擦を減らします。多くのホストをカスタムリトライルールで呼び出す内部サービスでは、urllib3がより良い基盤となる可能性があります。
顧客に提供されるAPIクライアントライブラリでは、慎重に選ぶ必要があります。Requestsはユーザーにとってなじみのある依存関係とクリーンな例を提供します。urllib3はトランスポートレイヤーのより多くのコントロールとより少ない抽象化を提供します。スクレイピングやモニタリングでは、許可されたページや単純なレスポンスではRequestsが通常十分です。多くのホストを管理し、長時間実行されるワーカーとチューニングされたプールを扱う場合、urllib3を真剣に検討すべきです。
避けるべき一般的なミス
最初のミスは、urllib3対Requestsを純粋なスピード競争と見なすこと。ほとんどの実際のシステムはネットワーク条件、サーバー挙動、ワークフロー設計で制限されます。低レベルなライブラリに置き換える前に、まず明確なライブラリを測定してください。
2番目のミスはタイムアウトを省略すること。タイムアウトのないリクエストはワーカーをフリーズさせ、失敗を隠します。両方のライブラリはタイムアウトパターンをサポートしているため、タイムアウトは本番コードで標準です。
3番目のミスはidempotencyの計画なしに非可換な操作をリトライすること。失敗したレスポンスは必ずしもサーバーが操作を実行できなかったことを意味しません。HTTPメソッド、エンドポイント挙動、ビジネス上の影響に基づいてリトライルールを構築してください。
4番目のミスは自動化においてコンプライアンスを無視すること。PythonのHTTPライブラリはツールであり、権限ではありません。CAPTCHA関連のトピックでは、CapSolverのキャプチャ解決FAQなどのリソースを、広範な法的・運用レビューの一環として使用してください。
結論 / CTA
urllib3対Requestsには実用的な答えがあります。大多数のアプリケーションコードでは、読みやすさ、人気、urllib3上で構築されているため、Requestsから始めましょう。プール、リトライ、TLS挙動、トランスポートレベルの設計の直接的なコントロールが必要な場合、urllib3に移行してください。曖昧なパフォーマンスの理由でライブラリを変更しないでください。実際のワークロードをプロファイリングしてください。
コンプライアンスに合った自動化では、通常のHTTPアクセスとチャレンジ処理を分離してください。Requestsまたはurllib3はHTTP通信を管理し、ワークフローが許可され、合理的な場合、公式CapSolverドキュメントはCAPTCHA関連のタスクをガイドします。チームが自動化におけるCAPTCHAチャレンジ用の専用サービスが必要な場合、CapSolverを、責任あるPythonワークフローの一環として検討してください。
FAQ
Requestsはurllib3のラッパーですか?
Requestsは接続プールとHTTPトランスポートのためにurllib3を使用していますが、それ以上のものです。より簡単なAPI、セッション、クッキー、認証ヘルパー、レスポンスの利便性、そして大きなユーザーエコシステムを追加しています。
urllib3はRequestsより速いですか?
urllib3はより少ないラッパーのオーバーヘッドを持つ可能性がありますが、実際のパフォーマンスは接続の再利用、タイムアウト、ペイロードサイズ、DNS、TLS、サーバーの遅延に依存します。ほとんどのAPIクライアントではRequestsは十分に速いです。切り替える前に自身のワークロードを測定してください。
ワイドスクラビングにはurllib3とRequestsのどちらを使用すべきですか?
許可されたスクラビングタスクではRequestsを使用してください。読みやすさと保守性が向上します。プール、リトライ、トランスポート挙動のより厳密な制御が必要な場合、urllib3を使用してください。常にサイトの利用規約、レートリミット、データ保護ルールを守ってください。
urllib3とRequestsは非同期リクエストをサポートしていますか?
デフォルトでは同期ライブラリです。プロジェクトで非同期並行処理が必要な場合、urllib3やRequestsをその役割に強制するのではなく、HTTPX、aiohttp、または他の非同期HTTPクライアントを評価してください。
CapSolverはPython HTTPワークフローで使用できますか?
はい、CapSolverは許可された自動化ワークフローでのCAPTCHAチャレンジ処理をサポートします。通常のHTTPロジックはRequestsまたはurllib3で保持し、公式ドキュメントと適用可能なルールにのみCapSolverを使用してください。
もっと見る
Web ScrapingJul 22, 2026
サイテクニカルSEOレグレッション監視: 自動化パイプライン
技術的SEOの回帰モニタリングをバージョン付きのベースライン、セマンティックな差分、検証済みアラート、およびオプションの認証済みCAPTCHA復元ステップを用いて構築してください。
CloudflareJul 22, 2026
MCP CAPTCHAソルバー:Cloudflare Turnstile 統合ガイド
ポリシー制限付きのMCP Cloudflare TurnstileワークフローをCapSolver、制限付きリトライ、ロギングをマスキングしたセッションチェック、および結果の検証を含むように構築してください。