ブロックされずに求人情報をスクレイピングする方法

Lucas Mitchell
Automation Engineer
TL;Dr:
- リゾーデンシャルプロキシのローテーション: 主な求人掲載サイトやプロフェッショナルネットワーキングプラットフォームでブロックされないために、高品質なリゾーデンシャルIPを使用してください。
- ブラウザフィンガープリントの模倣:
curl_cffiなどのツールを使用して、TLSのフィンガープリントとHTTPヘッダーを実際のブラウザプロファイルに一致させます。 - CAPTCHAの自動処理: Cloudflare TurnstileやreCAPTCHAのチャレンジを処理する信頼できるソルバーとしてCapSolverを統合してください。
- Robots.txtとレートリミットを尊重する: ランダムな遅延を実装し、倫理的なスクレイピングガイドラインに従って、長期的なアクセスを維持してください。
はじめに
求人情報のウェブスクレイピングは、採用代理店、市場研究者、および求人アグリゲーターにとって重要な柱となっています。しかし、主要な求人掲載サイトは、データ収集を数秒で停止する高度なセキュリティチェックを導入しています。求人情報のスクレイピングを試みた際に即座にIPアドレスがブロックされたり、無限の認証ループに陥ったりした経験がある人は少なくありません。課題は、自動スクリプトを人間のブラウジング行動と区別できないようにすることにあります。このガイドでは、低検出性を維持しながら効果的に求人情報をスクレイピングするための包括的な技術的なロードマップを提供します。
求人掲載サイトがスクレイパーをブロックする理由
求人プラットフォームやプロフェッショナルネットワーキングサイトは、独自のデータを保護し、サイトの安定性を確保するために大幅な投資を行っています。彼らは主に4つの検出層を使用してスクレイパーを識別し、ブロックします。
IPベースの信頼性とレートリミット
ほとんどの求人掲載サイトは、単一のIPアドレスからのリクエスト数を追跡します。一定のしきい値を超えると、IPアドレスは一時的または永続的にブラックリストに追加されます。データセンターIPは特に脆弱で、サーバーファームに属するものと簡単に識別されるためです。
ブラウザとTLSフィンガープリント
現代のアンチボットシステムであるCloudflareやDataDomeは、User-Agentだけに注目するのではなく、TLS(トランスポート層セキュリティ)ハンドシェイクを分析します。特定の暗号スイートや拡張機能をチェックします。Pythonスクリプトでデフォルトのrequestsライブラリを使用すると、JA3フィンガープリントがすぐにボットであることを示します。
行動分析
人間のユーザーは0.5秒ごとにリンクをクリックしたり、完全に直線的なパターンでナビゲートしたりしません。固定されたリクエスト間隔やCSS/画像の読み込みが欠如しているスクレイパーは、行動分析エンジンによってすぐにブロックされます。
CAPTCHAとJavaScriptチャレンジ
サイトが疑わしいが確信できない場合、チャレンジがトリガーされます。これは単純なJavaScript実行チェックまたは複雑なCAPTCHAである可能性があります。これらのチャレンジを自動的に解決する方法がない場合、スクレイピングワークフローは完全に停止します。
検出されない求人スクレイピングの必須技術
信頼性の高いスクレイパーを構築するには、各検出層に対して特定の技術的対策を講じる必要があります。
1. リゾーデンシャルプロキシのローテーションの実装
単一のIPアドレスを使用するのは、ブロックされる最も速い方法です。代わりに、リゾーデンシャルプロキシのプールを使用する必要があります。データセンターIPとは異なり、リゾーデンシャルIPはインターネットサービスプロバイダー(ISP)によって実際の家庭に割り当てられ、正当なトラフィックから区別するのが非常に困難です。
| プロキシタイプ | 検出リスク | コスト | 最適な使用ケース |
|---|---|---|---|
| データセンター | 高 | 低 | 低セキュリティサイト、テスト |
| リゾーデンシャル | 低 | 中 | 高セキュリティの求人掲載サイトや検索エンジン |
| モバイル(4G/5G) | 非常に低 | 高 | 高度なアンチボットシステム |
求人情報をスクレイピングする際は、プロキシプロバイダーが自動ローテーションをサポートしていることを確認してください。これにより、すべてのリクエストまたはセッションが異なる地理的場所とIPアドレスから発信されるようになります。
2. TLSフィンガープリントの模倣の習得
前述したように、requestsやurllibなどの標準ライブラリには特徴的なTLSフィンガープリントがあります。これを解決するには、curl_cffiを使用し、実際のブラウザ(ChromeやFirefoxなど)のTLSハンドシェイクを模倣する必要があります。
python
from curl_cffi import requests
# Chrome 120のTLSフィンガープリントを模倣
response = requests.get(
"https://www.target-job-board.com/jobs?q=software+engineer",
impersonate="chrome120",
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
}
)
print(response.status_code)User-Agentを対応するTLSプロファイルと一致させることで、CloudflareやAkamaiによるブロックの可能性を大幅に低減できます。
3. CapSolverによるCAPTCHAの処理
完全なヘッダーとプロキシを使用しても、最終的にはチャレンジに遭遇します。求人掲載サイトは頻繁にCloudflare TurnstileやreCAPTCHAを使用してユーザーを確認します。スケールで手動で解決することは不可能です。ここではCapSolverが自動化スタックの必須要素になります。
CapSolverは、さまざまなCAPTCHAタイプを解決するシームレスなAPIを提供します。たとえば、求人検索APIを使用している場合や、主要な雇用プラットフォームをスクレイピングしている場合にCloudflare Turnstileチャレンジに遭遇した場合、次の公式実装を使用できます:
python
import requests
import time
api_key = "YOUR_CAPSOLVER_API_KEY"
site_key = "0x4XXXXXXXXXXXXXXXXX" # ターゲットサイトのHTMLに記載
site_url = "https://www.target-job-board.com"
def solve_turnstile():
payload = {
"clientKey": api_key,
"task": {
"type": 'AntiTurnstileTaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
task_id = res.json().get("taskId")
if not task_id:
return None
while True:
time.sleep(1)
result_res = requests.post("https://api.capsolver.com/getTaskResult", json={"clientKey": api_key, "taskId": task_id})
result = result_res.json()
if result.get("status") == "ready":
return result.get("solution", {}).get('token')
if result.get("status") == "failed":
return None
token = solve_turnstile()このコードをワークフローに統合することで、人間の介入なしでスクレイパーがタスクを継続できるようになり、データパイプラインの運用時間を効果的に維持できます。
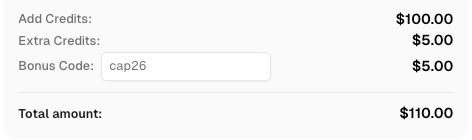
CapSolverのボーナスコードを取得する
自動化予算を即座に増やす!
CapSolverアカウントにチャージする際にボーナスコードCAP26を使用すると、すべてのチャージで5%のボーナスが追加されます—制限なし。
今すぐCapSolverダッシュボードで取得してください
4. リクエストヘッダーとリファラーの最適化
「裸の」リクエストを送信するのは一般的なミスです。実際のブラウザは常にRefererヘッダーとさまざまなSec-CH-UA(クライアントヒント)ヘッダーを送信します。求人情報をスクレイピングする際は、リファラーをサイトのホームページまたは以前の検索結果ページに設定してください。
- User-Agent: 最新で人気のある文字列を使用してください。
- Referer:
https://www.google.com/またはサイトのドメイン自体。 - Accept-Encoding:
gzip, deflate, br(コードがこれらの圧縮を解凍できるようにしてください)。
スクレイピング戦略の比較概要
| 戦略 | 効果 | 実装の難易度 | 推奨対象 |
|---|---|---|---|
| 基本的なPython requests | 非常に低 | 低 | 保護されていない個人ブログ |
| ヘッドレスブラウザ(Selenium) | 中程度 | 中程度 | ジャバスクリプトが重いサイト |
| ステルスブラウザ+プロキシ | 高 | 高 | 高セキュリティの雇用プラットフォーム |
| ウェブスクレイピングAPI | 非常に高 | 低 | 企業規模の求人データ抽出 |
倫理的および法的な考慮事項
技術的な成功だけでなく、倫理的なスクレイピングも優先する必要があります。常にサイトのrobots.txtファイルと利用規約を確認してください。W3C(World Wide Web Consortium)のガイドラインによると、World Wide Web Consortium (W3C)は、ターゲットサーバーの健全性を尊重するために過度なリクエストでサーバーを過負荷にしないことが推奨されています。さらに、Electronic Frontier Foundationは、公開されているデータをスクレイピングすることは一般的に保護されているが、許可なしにプライベートなユーザー情報やログイン壁を回避してアクセスすることは避けるべきであると強調しています。
結論
ブロックされずに求人情報を成功裏にスクレイピングするには、多層的なアプローチが必要です。リゾーデンシャルプロキシのローテーション、TLSフィンガープリントの模倣、およびCapSolverを通じた自動CAPTCHA解決を組み合わせることで、人間の行動を模倣する堅牢なシステムを構築できます。ウェブスクレイピングの環境は常に進化しているため、最新のセキュリティ管理のトレンドを把握することが、競争力を維持する鍵であることを忘れないでください。
FAQ
1. 求人情報のスクレイピングは合法ですか?
多くの管轄区域内では、公開されている求人情報をスクレイピングすることは合法です。ただし、コンピュータ詐欺および不正アクセス法(CFAA)や著作権法に違反しないことを確認してください。特定の使用ケースについては法的アドバイスを受けてください。
2. プロキシをどのくらいの頻度でローテーションする必要がありますか?
高セキュリティサイトの場合、リクエストごとまたは数分ごとにIPをローテーションするのが最も良いです。パターン検出を避けるためです。
3. アカウントなしでプロフェッショナルネットワーキングサイトをスクレイピングできますか?
多くのプロフェッショナルプラットフォームは非常に制限されています。一部の公開プロフィールや求人は表示されますが、多くのデータはログイン壁の向こうにあります。ログイン後にスクレイピングすると、法的および技術的なリスクが高まります。
4. ヘッドレスブラウザでもまだ検出されるのはなぜですか?
PuppeteerやSeleniumなどの標準的なヘッドレスブラウザは、navigator.webdriver = trueなどの「フィンガープリント」を残します。これらのプロパティを隠すためにstealthなどのプラグインを使用する必要があります。
5. IPブロックを避ける最善の方法は何ですか?
IPブロックを避ける最も効果的な方法は、リゾーデンシャルプロキシとランダムなリクエスト間隔(ジャイタ)の組み合わせです。
もっと見る
AIJul 23, 2026
クラウドフレア トゥルネスティールを解決する方法 ラングラフ エージェントで
LangGraph Cloudflare Turnstileソルバーのワークフローを構築するには、CapSolver、Playwrightセッション処理、ポリシーゲート、リトライ、検証、およびレビューを用いてください。

Web ScrapingJul 23, 2026
Schemaリッチ結果をモニタリングする方法: 自動化ガイド
JSON-LD抽出、意味的基準、検証、サーチコンソールデータ、および有用なアラートを使用して、スキーマリッチ結果のモニタリングを自動化する方法を学びましょう。