ブラウザなしでAWS WAFチャレンジを解決する方法: 技術的なガイド

Sora Fujimoto
AI Solutions Architect
TL;Dr:
- ブラウザなしでAWS WAFチャレンジを解決することで、Puppeteerなどのリソースを大量に消費するヘッドレスブラウザの必要性がなくなります。
- 405ステータスコードの応答から特定の暗号化パラメータを抽出する必要があります。
- CapSolverのAPIは、有効なaws-wafトークンを生成するために必要な複雑なJS実行と復号化を処理します。
- ブラウザレスソルバーを統合することで、インフラコストを最大80%削減し、自動化の速度を向上させることができます。
はじめに
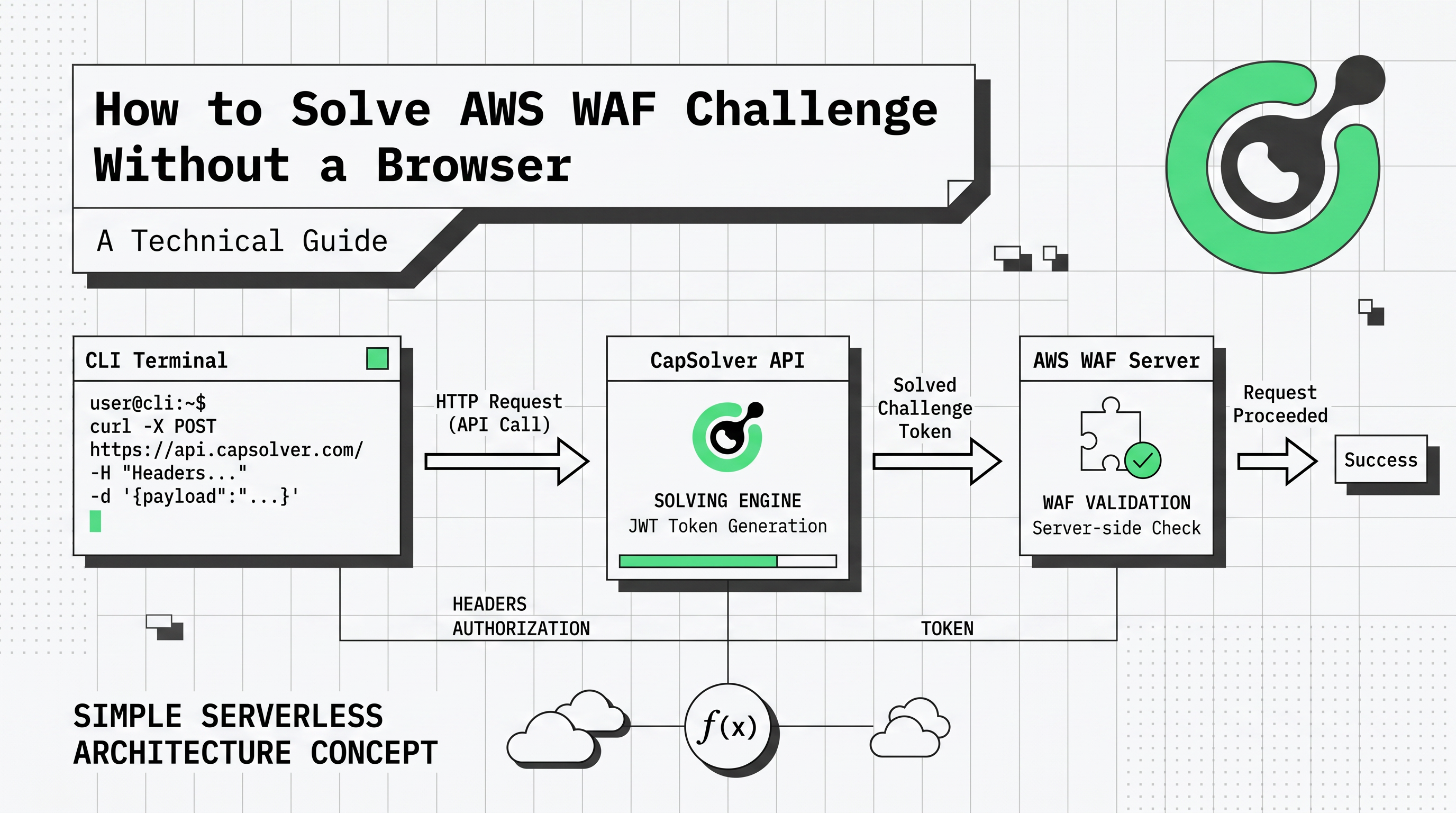
Amazon Web Servicesで保護されたウェブサイトからデータを自動収集する際、AWS WAFチャレンジは多くの技術的障壁になります。従来、開発者は必要なJavaScriptを実行してこれらのパズルを解決するためにヘッドレスブラウザに依存してきました。しかし、Impervaの「Bad Bot Report 2025」によると、現在のインターネット活動のほぼ50%がボットトラフィックであるため、セキュリティ対策はより厳しくなっています。すべてのリクエストでフルブラウザインスタンスを実行するのは、スケールにおいて遅く、非常に高コストです。このガイドでは、ブラウザなしでAWS WAFチャレンジを解決するより効率的なアプローチに焦点を当てています。ブラウザなしでAWS WAFチャレンジを解決する方法を理解することは、現代のウェブスクレイピングにおいて不可欠です。トークンベースのAPI戦略を使用することで、最小限のオーバーヘッドと最大限の信頼性でこれらのセキュリティ層をバイパスできます。
AWS WAFチャレンジのアーキテクチャ
ブラウザなしでチャレンジを解決するには、リクエストがブロックされたときに何が起こるかをまず理解する必要があります。ブラウザなしでAWS WAFチャレンジを解決するには、405ステータスコードの詳細な深掘りが必要です。AWS WAFは通常、トラフィックを検証するために2つの主要な方法を使用します。静かにJavaScriptチャレンジと、表示されるCAPTCHAです。スクレイパーが保護されたリソースにアクセスすると、サーバーは202または405ステータスコードを返すことがあります。それぞれのコードには解決に必要な異なるパラメータがあります。これらの応答を理解することが、ブラウザレスソリューションを構築する第一歩です。
ステータスコード202と405の比較
サーバーから返されるステータスコードは、解決するチャレンジの複雑さを決定します。202ステータスコードは通常、単純なJavaScriptチャレンジを示し、405ステータスコードは完全なCAPTCHAまたはより複雑な質問を意味します。
| ステータスコード | チャレンジタイプ | 必要パラメータ |
|---|---|---|
| 202 Accepted | サイレントJSチャレンジ | awsChallengeJS URL |
| 405 Method Not Allowed | 完全なCAPTCHA / 質問 | awsKey, awsIv, awsContext, awsChallengeJS |
スケーリングを目指す開発者にとって、これらのコードをプログラム的に識別することは必須です。これらの応答の詳細については、AWS WAF 405ステータスコードの処理方法に関する詳細ガイドをご覧ください。
ブラウザレスに移行する理由
ブラウザレスソルバーへのシフトは、効率性の向上に驱动されています。多くの開発者が、サーバーのコストを節約するためにAWS WAFチャレンジをブラウザなしで解決する方法を尋ねています。これは、AWS WAFチャレンジをブラウザなしで解決する方法を学ぶことが最優先事項になった理由です。ヘッドレスブラウザはCPUとメモリを大量に消費し、信頼性のある実行に専用のインフラが必要です。一方、ブラウザレスアプローチでは、PythonのrequestsやNode.jsのaxiosなどの標準的なHTTPクライアントを使用して、ソルビングAPIと直接通信します。この方法は、インフラコストを最大80%削減し、各リクエストサイクルの速度を向上させます。
JavaScript実行要件のバイパス
ブラウザレス環境での主な障壁は、AWSチャレンジスクリプトの実行です。このスクリプトは、ブラウザのファイngerprintを収集し、暗号化されたパズルを解決するように設計されています。CapSolverなどのサービスを使用することで、この実行を専門のサーバーにオフロードします。APIはAWS応答からのローパラメータを受け取り、ページをレンダリングすることなく最終的なaws-waf-tokenを返します。これは、現代のウェブスクレイピングツールの説明ガイドのコアコンポーネントです。
ステップバイステップのブラウザレス統合
ブラウザレスソリューションの実装には、3つの主要なフェーズがあります。これは、AWS WAFチャレンジをブラウザなしで解決するための標準ワークフローです。この方法に従うことで、AWS WAFチャレンジをブラウザなしで解決する方法を効果的に学ぶことができます。このワークフローにより、自動化スクリプトが厳しいAWS WAFルールに直面しても、有効なセッションを維持できるようになります。
ステップ1: チャレンジのキャプチャ
スクリプトが405応答を受け取った場合、HTMLを解析して暗号化されたチャレンジパラメータを抽出する必要があります。これらのパラメータは、通常スクリプトタグ内またはページ内のメタデータに含まれています。awsKey、awsIv、awsContext、およびawsChallengeJSファイルのURLを抽出する必要があります。
python
import requests
from bs4 import BeautifulSoup
def extract_aws_parameters(url):
response = requests.get(url)
if response.status_code == 405:
soup = BeautifulSoup(response.text, 'html.parser')
# 例の抽出ロジック(実際の実装はページ構造に依存)
aws_key = soup.find('input', {'id': 'aws-waf-key'})['value']
aws_iv = soup.find('input', {'id': 'aws-waf-iv'})['value']
aws_context = soup.find('input', {'id': 'aws-waf-context'})['value']
js_url = soup.find('script', {'src': True})['src']
return aws_key, aws_iv, aws_context, js_url
return Noneステップ2: ソルビングタスクの作成
パラメータを取得した後、CapSolver APIに送信します。ブラウザレス設定では、AntiAwsWafTaskProxylessが最適な選択肢であることがよくあります。これは、AWSに最適化された内部プロキシプールを使用するためです。
python
def create_capsolver_task(api_key, website_url, aws_key, aws_iv, aws_context, js_url):
payload = {
"clientKey": api_key,
"task": {
"type": "AntiAwsWafTaskProxyless",
"websiteURL": website_url,
"awsKey": aws_key,
"awsIv": aws_iv,
"awsContext": aws_context,
"awsChallengeJS": js_url
}
}
response = requests.post("https://api.capsolver.com/createTask", json=payload)
return response.json().get("taskId")このリクエストはtaskIdを返します。その後、getTaskResultエンドポイントをポーリングし、ステータスがreadyになるまで待ちます。このプロセスの技術的詳細については、AWS WAFトークン解決ガイドを参照してください。
ステップ3: 結果の取得
結果のポーリングはブラウザレスワークフローの重要な部分です。タスクのステータスを確認するために、短い遅延を含むループを実装する必要があります。
python
import time
def get_task_result(api_key, task_id):
payload = {
"clientKey": api_key,
"taskId": task_id
}
while True:
response = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
result = response.json()
if result.get("status") == "ready":
return result.get("solution").get("cookie")
time.sleep(3)ステップ4: トークンの挿入
最終ステップでは、APIから返されたトークンをHTTPクライアントのクッキージャーに追加します。クッキーの名前はaws-waf-tokenでなければなりません。このクッキーが存在すると、保護されたウェブサイトへの以降のリクエストは正当なトラフィックとして検証されます。
python
def make_protected_request(url, token):
cookies = {'aws-waf-token': token}
response = requests.get(url, cookies=cookies)
return response.text高容量自動化のための高度な戦略
企業レベルのスクレイピングでは、単にチャレンジを解決するだけでは不十分です。AWSの行動分析でブロックされないようにするため、ファイngerprintとプロキシの管理も必要です。
プロキシ管理とファイngerprint
ブラウザなしでも、AWS WAFはリクエストのヘッダーとTLSファイngerprintを分析できます。高品質な住宅用プロキシを使用し、ユーザー-agent文字列を頻繁にローテーションすることが推奨されます。他のセキュリティ層と取り組んでいる場合、最高のプロキシサービスに関するガイドが、包括的な自動化戦略を維持するのに役立ちます。
モニタリングとフィードバック
フィードバックループの実装は長期的な成功にとって不可欠です。feedbackTaskエンドポイントを使用することで、トークンが成功したかどうかをソルビングサービスに通知できます。このデータは、ソルビングアルゴリズムの改善に役立ち、特定のターゲットサイトの成功確率を向上させます。このレベルの統合は、プロフェッショナルなAWSソルバーの特徴です。
結論
ブラウザなしでAWS WAFチャレンジを解決する方法を学ぶことは、スケーリングが必要な開発者にとって画期的な変化です。ブラウザなしでAWS WAFチャレンジを解決する方法を知れば、数千もの並行タスクを実行できます。リソースを大量に消費するヘッドレスブラウザから離れ、トークンベースのAPIアプローチを採用することで、より高速でコスト効率の良い結果を得られます。CapSolverは、AWSが要求する複雑な復号化とJS実行を処理するための必要なツールを提供し、コアデータ収集タスクに集中できるようにします。
FAQ
-
Pythonのrequestsを使用してAWS WAFチャレンジを解決することは可能ですか?
はい、CapSolverなどのソルビングAPIを使用することで、チャレンジパラメータを抽出し、Pythonrequestsライブラリで使用できる有効なトークンを取得できます。これはブラウザの必要性を完全に排除します。 -
AntiAwsWafTaskとAntiAwsWafTaskProxylessの違いは何ですか?
AntiAwsWafTaskでは、ソルバーがAWSとやり取りするために独自のプロキシを提供する必要があります。一方、AntiAwsWafTaskProxylessはCapSolverの内部プロキシプールを使用し、ブラウザレス設定ではより便利です。 -
aws-waf-tokenを取得するにはどのくらい時間がかかりますか?
平均して、チャレンジの複雑さと現在のネットワーク遅延に応じて、5〜15秒かかります。 -
他のAWSサービスにもこの方法は適用できますか?
この方法は、AWS WAFで保護されたウェブサイトに特化しています。ターゲットサイトが他のAWSセキュリティ機能を使用している場合、パラメータとタスクタイプは異なる場合があります。 -
完全なAPIドキュメンテーションはどこで見つけることができますか?
すべてのタスクタイプとエンドポイントの完全な技術リファレンスは、CapSolver APIドキュメンテーションで利用可能です。
深く掘り下げる: トークン生成のメカニズム
ブラウザなしでAWS WAFチャレンジを解決する方法を完全にマスターするには、チャレンジフェーズ中に発生する暗号化された交換を掘り下げる必要があります。これは、ブラウザなしでAWS WAFチャレンジを解決する方法の最も技術的な側面です。AWS WAFは、有効なクッキーのみをチェックするのではなく、トークンの全ライフサイクルを検証します。これは、タイムスタンプ、トークンを生成したIPアドレス、およびリクエストの特定のコンテキストをチェックすることを含みます。ブラウザレスソルバーを使用する場合、APIはこのすべての環境をシミュレートして、AWSサーバーが正当なものとして受け入れるトークンを生成する必要があります。
ブラウザレス環境でのファイngerprintの役割
ブラウザレス環境でも、ファイngerprintは重要な要素のままです。AWS WAFは、HTTPスタックの異常を検出するために高度なヒューリスティクスを使用します。これは、ヘッダーの順序、使用されるTLSバージョンと暗号スイート、さらにはTCP/IPウィンドウサイズの分析を含みます。プロフェッショナルなソルビングサービスは、トークン生成プロセスが実際のブラウザのファイngerprintにできるだけ近づくようにするため、これらの細かい点を処理します。これは、カスタムスクリプトを書こうとするよりも、専門的なAWSソルバーを使用する方がはるかに効果的である理由です。
ブラウザレスソリューションのスケーリング
自動化のニーズが成長するにつれて、レート制限やより積極的なIPベースのブロッキングに直面する可能性があります。これを回避するには、ブラウザレスソルバーを堅牢なプロキシ管理システムと統合することが不可欠です。プロキシをローテーションし、ターゲットウェブサイトのオーディエンスと地理的に一致させることで、成功確率を大幅に向上させることができます。設定の最適化に関するヒントについては、最高のプロキシサービスに関する私たちの推奨事項をチェックしてください。
自動化の未来への準備
ウェブセキュリティの状況は常に変化しています。AWSは、自動化ツールに対抗するためにWAFルールとチャレンジロジックを頻繁に更新しています。これらの変更について知ることは、スクレイパーが引き続き動作し続けるために唯一の方法です。ソルビングエンジンを積極的に維持するサービスに依存することで、これらの更新に対抗するインフラを未来に向けて保護できます。新しいJSチャレンジのバージョンやより複雑なAWSインタロゲーションであっても、専門のAPIプロバイダーが技術的な重労働を処理し、データを収集する価値に集中できるようにします。