AIエージェント対チャットボット:オートメーション機能における主要な違い

Sora Fujimoto
AI Solutions Architect
要約
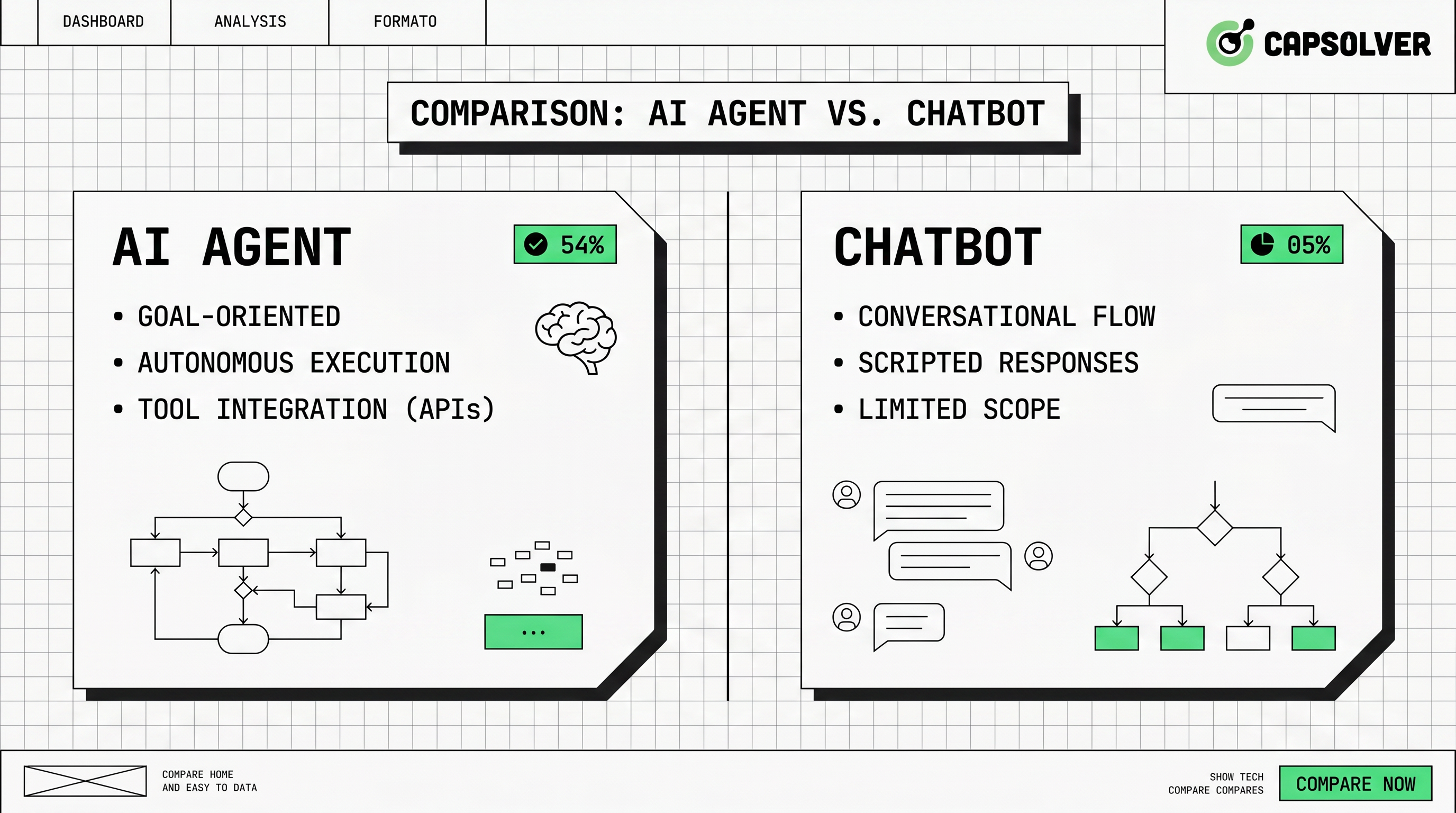
- コア的な違い: チャットボットは反応型で、スクリプト駆動の会話インターフェースで単純なQ&Aを目的としているのに対し、AIエージェントは能動的で自律的なシステムで、複数ステップの推論と複雑なワークフローの実行が可能である。
- エージェント型AIと従来のAI: 従来のAI(標準的なチャットボットを含む)はユーザーのプロンプトを待って事前に定義されたパスに従う。エージェント型AIはサブゴールを設定し、外部ツールを使用し、人間の介入なしに動的環境に適応する。
- 自動化への影響: チャットボットは通常のカスタマーサービスを担当するが、AIエージェントはデータ抽出からサプライチェーン最適化に至るまで、エンドツーエンドのビジネスプロセスを調整できる。
- CAPTCHAの課題: 即使は最高レベルのAIエージェントも、ウェブ自動化中のセキュリティメカニズムであるCAPTCHAに苦労する。中断されないエージェントワークフローのために、CapSolverなどの専門的なソリューションを統合することが不可欠である。
はじめに
長年にわたり、企業は日常的な顧客問い合わせや基本的なタスクを処理するためにデジタルアシスタントに依存してきました。しかし、企業の自動化のニーズがより複雑になるにつれて、これらの初期システムの限界が明確になってきました。今日では、単純な会話インターフェースから実際に作業を遂行できる自律的なシステムへの会話が移行しています。AIエージェントとチャットボットの違いを理解することは、今や技術的な作業だけでなく、運用規模拡大を目指す組織にとって戦略的な必須事項です。この記事では、AIエージェントとチャットボットの基本的な違い、エージェント型AIと従来のAIの台頭、そしてこれらの技術が現実世界の自動化能力に与える影響について探ります。最後には、ご自身のビジネスニーズに合ったシステムを理解し、一般的な自動化の課題を乗り越える方法がわかります。
何がチャットボットですか?会話型AIの基盤
チャットボットは、テキストまたは音声の相互作用を通じて人間の会話をシミュレートするソフトウェアアプリケーションです。伝統的なチャットボットのコアは、事前に定義されたルール、意思決定ツリー、およびスクリプトされた応答に基づいて動作します。ユーザーが質問をすると、チャットボットは基本的な自然言語処理(NLP)を使用してキーワードを識別し、事前にプログラミングされた答えを提供します。
チャットボットの仕組み
チャットボットは、デジタル自動販売機のように機能します。固定された応答の在庫を持ち、特定の入力を必要として正しい情報を提供します。これらは単純で繰り返しのタスクに対して非常に効果的ですが、深い文脈を理解したり、プログラムされた会話フローから逸脱したりする能力は持っていません。
一般的なチャットボットの使用例
- カスタマーサービスのFAQ: 店舗の営業時間、返品ポリシー、配送状況に関する一般的な質問への回答。
- 基本的なITサポート: 従業員がパスワードリセットやソフトウェアインストールのステップをガイドする。
- リードの質問: ウェブサイトの訪問者から基本的な連絡先情報を収集し、人間の販売担当者にルーティングする。
グローバルなチャットボット市場は2034年までに602億1000万ドルに達する見込みと予測されていますが、その役割は依然として反応型で単一の対話に限定されています。
何がAIエージェントですか?自律的行動の進化
AIエージェントは、人工知能の大きな飛躍を表します。チャットボットとは異なり、AIエージェントは自律的なシステムで、推論、計画、特定の目標を達成するための独立した行動が可能です。単に質問に答えているだけでなく、さまざまなアプリケーションやデータソースを横断して複雑なマルチステップのワークフローを実行します。
AIエージェントのメカニズム
AIエージェントは、継続的な「知覚-推論-行動」のループで動作します。環境を知覚(ウェブページの読み込みやデータベースの分析など)、目標を達成するための最善の行動を推論し、外部ツールやAPIを使用してその行動を実行します。障害に遭遇した場合、動的に計画を調整します。
エージェント型AIと従来のAI
エージェント型AIと従来のAIの違いはここに重要です。従来のAI(標準的なチャットボットを含む)は反応型であり、プロンプトを待ってトレーニングデータに基づいて出力を生成します。一方、エージェント型AIは能動的です。例えば、「当社の上位3社の競合を調査し、価格モデルを要約する」という高レベルのコマンドを、論理的なステップに分解し、ウェブ検索を実行し、データをスクレイピングし、最終的なレポートを生成するなど、人間の指導なしに実行できます。
最近の業界の研究によると、90%の企業がAIエージェントを積極的に採用して運用を効率化し、手作業の負荷を減らしています。これらのシステムがどのように動作するかのより深い技術的説明については、エージェント型AIとは何か、そしてどのように動作するのかを参照してください。
AIエージェントとチャットボットの違い: 詳細な比較
AIエージェントとチャットボットのダイナミクスを完全に理解するには、自動化のいくつかの重要な次元においてどのように異なるかを検討する必要があります。
1. 自律性と意思決定
チャットボットは常に人間の指示を必要とします。スクリプトに従って動作し、会話が事前に定義されたパラメータを超えると動作を停止します。AIエージェントは高い自律性を持っています。独立した意思決定を行い、どのツールを使用するかを選び、曖昧な状況に適応して割り当てられたタスクを完了できます。
2. タスクの複雑さとワークフローの調整
チャットボットは単一の対話—一度に1つの質問に答える—ために設計されています。AIエージェントは複数ステップの調整に優れています。例えば、チャットボットはユーザーに飛行機の予約方法を説明するかもしれませんが、AIエージェントは複数の航空会社のウェブサイトをチェックし、価格を比較し、ユーザーの好みに基づいて最適なオプションを選択し、予約プロセスを自律的に完了できます。
3. 学習と記憶
従来のチャットボットは限られた記憶を持ち、セッションが終了すると会話の文脈を忘れてしまいます。AIエージェントは短期記憶と長期記憶の両方を使用します。過去の相互作用を覚え、成功や失敗から学び、継続的にパフォーマンスを向上させます。
比較要約表
| 特徴 | チャットボット | AIエージェント |
|---|---|---|
| 主な機能 | 会話のシミュレーションと質問への回答 | 複雑なタスクの実行と目標の達成 |
| 運用モード | 反応型(ユーザー入力を待つ) | 能動型(独立した行動を取る) |
| 意思決定 | ルールベース、事前に定義されたスクリプトに従う | 自律的な推論と動的な計画 |
| タスクの複雑さ | 単純で単一ステップの相互作用 | 複雑で複数ステップのワークフロー調整 |
| ツールの統合 | 内部データベースに限定 | 外部APIやウェブツールの広範な使用 |
| 適応性 | 未知のシナリオに遭遇すると失敗する | 変化に対応し、代替ソリューションを見つける |
AIエージェントのウェブ自動化における役割
AIエージェントの最も強力な応用の1つは、ウェブ自動化とデータ抽出の分野です。従来のウェブスクレイピングは、ウェブサイトのレイアウトが変更されるとすぐに破損する厳密なスクリプトに依存しています。一方、エージェント型AIシステムは、ウェブページを視覚的に解析し、必要な要素を識別し、構造的な変更に即座に対応できます。
この能力は、企業が知的財産を収集する方法を変革しています。エージェント型AIの概要: ウェブ自動化における利用事例を活用することで、エンジニアは大幅にメンテナンスが少ないデータパイプラインを構築できます。競合価格のモニタリング、財務データの集約、サプライチェーンロジスティクスの自動化など、あらゆる分野でAIエージェントは従来の自動化ツールでは到底かなわない耐久性を提供します。
隠れた障壁: エージェントワークフローにおけるCAPTCHA
エージェント型AIがウェブと相互作用する際には、技術的な障壁に直面します。CAPTCHAは、人間のユーザーと自動化されたボットを区別するように設計されたセキュリティメカニズムであり、最も高度なエージェントシステムでも継続的な課題となっています。
エージェント型AIがCAPTCHAに苦労する理由
AIエージェントが保護されたウェブサイトでデータをスクレイピングしたり、プロセスを自動化しようとすると、しばしばCAPTCHA(完全自動化された公開テスターでコンピュータと人間を区別する)に遭遇します。エージェント型システムがここであまりうまくいかない理由は以下の通りです:
- 精度の要件: スライダーパズルや複雑な画像認識タスクなどの多くのCAPTCHAは、マルチモーダルAIモデルがしばしば欠く、細かい空間制御とピクセル単位の正確さを必要とします。
- 行動分析: 現代のCAPTCHA(reCAPTCHA v3やCloudflare Turnstileなど)は、マウスの動き、クリックパターン、タイプ速度などのユーザー行動を分析します。AIエージェントは機械的で予測可能なパターンを示すことが多く、すぐにセキュリティブロックをトリガーします。
- 動的なリスクスコアリング: ボット防止システムは継続的にリスクスコアリングアルゴリズムを更新しています。今日サイトをスムーズに通過できるAIエージェントが、明日そのデジタルフィンガープリントがブロックされる可能性があります。
組織がデータ収集の努力を拡大するにつれて、CAPTCHA解決APIの選び方を理解することが、中断されない自動化パイプラインを維持するために不可欠になります。
CapSolverで自動化のギャップを埋める
エージェント型AIをウェブ自動化で最大限に活かすには、CAPTCHAのボトルネックに対処する必要があります。これはCapSolverなどの専門的なソリューションが不可欠になる理由です。
CapSolverは、自動化ワークフローにシームレスに統合できる強力でAI駆動のインフラストラクチャを提供します。複雑なセキュリティの課題をバックグラウンドで処理することで、AIエージェントが主な目的—データ抽出、市場調査、プロセス自動化—に集中できるようにします。
CapSolverに登録する際にはコード
CAP26を使用してボーナスクレジットを取得してください!
CapSolverがエージェントワークフローをどのように強化するか
- 包括的なカバー範囲: CapSolverはreCAPTCHA、hCaptcha、Cloudflare Turnstile、AWS WAFなど、幅広いセキュリティメカニズムをサポートし、エージェントが多様なウェブ環境をナビゲートできるようにします。
- 高い成功確率: 高度な機械学習アルゴリズムを使用して、高い正確性と高速な応答時間を提供し、ワークフローの中断を最小限に抑えます。
- シームレスな統合: CapSolverは既存の自動化フレームワークに簡単に統合できます。開発者向けに、ヘッドレスブラウザでのCAPTCHA解決の自動化に関する実用的な実装戦略を提供します。
CapSolverにCAPTCHA解決の負担を委譲することで、組織はAIエージェントがピーク効率で動作し、信頼性がありスケーラブルな自動化を提供できることを保証できます。
CapSolverのコード例
Pythonの自動化スクリプトにCapSolverを統合するのは簡単です。以下は、CapSolver APIを使用してreCAPTCHA v2チャレンジを解決する基本的な例です:
python
import requests
import time
API_KEY = "YOUR_CAPSOLVER_API_KEY"
SITE_KEY = "PAGE_SITE_KEY"
PAGE_URL = "PAGE_URL"
def solve_recaptcha():
payload = {
"clientKey": API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": PAGE_URL,
"websiteKey": SITE_KEY
}
}
# タスクを作成
res = requests.post("https://api.capsolver.com/createTask", json=payload)
task_id = res.json().get("taskId")
if not task_id:
print("タスクの作成に失敗しました:", res.text)
return None
print(f"タスクを作成しました: {task_id}. 解決を待っています...")
# 結果をポーリング
while True:
time.sleep(3)
res = requests.post("https://api.capsolver.com/getTaskResult", json={
"clientKey": API_KEY,
"taskId": task_id
})
status = res.json().get("status")
if status == "ready":
print("CAPTCHAが正常に解決しました!")
return res.json().get("solution").get("gRecaptchaResponse")
elif status == "failed":
print("CAPTCHAの解決に失敗しました:", res.text)
return None
# ソルバーを実行
response_token = solve_recaptcha()結論
反応型チャットボットから能動型AIエージェントへの移行は、企業技術における根本的な変化を示しています。Gartnerは、2028年までに33%の企業ソフトウェアアプリケーションにエージェント型AIが含まれると予測しています。これは2024年の1%を上回るものです。チャットボットは基本的なスクリプト駆動の相互作用に役立ちますが、AIエージェントは複雑なビジネスワークフローを調整するために必要な自律性、推論、適応性を提供します。AIエージェントとチャットボットの違いを理解することで、組織は適切なツールを適切なタスクに配置できます。
しかし、エージェント型AIがより高度なウェブ自動化タスクを担うにつれて、複雑なボット防止セキュリティメカニズムに必ず遭遇します。スケーラブルで耐障害性のあるデータパイプラインを維持するには、信頼できるCAPTCHA解決サービスを統合することが不可欠です。CapSolverを活用することで、企業はAIエージェントがウェブをシームレスにナビゲートできるようにし、自律的な自動化の真の潜在能力を解放できます。
FAQ
1. AIエージェントとチャットボットの主な違いは何ですか?
主な違いは自律性と能力にあります。チャットボットは、事前に定義されたスクリプトやトレーニングデータに基づいて質問に答える反応型インターフェースです。AIエージェントは、推論、複数ステップのワークフローの計画、外部ツールの使用、特定の目標を達成するための独立した行動が可能な能動的なシステムです。
自律性を備えたAIとは、独自に行動できる能力を持つ人工知能システムを指します。従来のAIがユーザーの指示を待つのに対し、自律性を備えたAIはサブゴールを設定し、変化する環境に適応し、継続的な人間の介入なしに複雑なタスクを実行できます。
3. AIエージェントはチャットボットを完全に置き換えることができるのか?
必ずしもそうとは限りません。チャットボットは、基本的なカスタマーサービスのFAQのような単純で大量の問い合わせを処理するうえで非常にコスト効率が良く効率的です。AIエージェントは、推論や外部システムとの統合が必要な複雑で多段階のプロセスに適しています。企業はおそらくハイブリッドアプローチを採用し、それぞれの技術を最も適した場面で展開するでしょう。
4. ウェブオートメーション中にAIエージェントがCAPTCHAに苦労する理由は?
AIエージェントがCAPTCHAに苦労するのは、これらのセキュリティ対策が人間以外の行動を検出することを目的としているためです。エージェントは複雑な画像パズルに必要なピクセル単位の正確さを欠いており、一様な入力速度や直線的なマウスの動きなどの機械的なブラウジングパターンを示しがちで、それによりボット防止システムが作動してしまうからです。
5. CapSolverはAIエージェントのオートメーションワークフローにおいてどのように役立ちますか?
CapSolverは、再CAPTCHA、Turnstile、AWS WAFなどさまざまなタイプのCAPTCHAを自動で解くAPIを提供します。CapSolverを統合することで、AIエージェントはこれらのセキュリティの障壁をスムーズに回避でき、データ抽出やウェブオートメーションプロセスを途切れることなく実行できます。
もっと見る
AIMar 27, 2026
企業自動化の向上:LLMを駆動とするインフラによるシームレスなCAPTCHA認識と運用効率
LLMを駆動するAIオートメーションインフラがCAPTCHA認識をどのように変革するかを発見してください。ビジネスプロセスの効率を向上させ、手動の介入を削減します。高度な検証ソリューションで自動化されたオペレーションを最適化してください。
AIMar 27, 2026
LLMトレーニングのためのデータ収集のスケーリング: CAPTCHAをスケールで解く
大規模言語モデルのトレーニングのためのデータ収集をスケールする方法を学びましょう。大規模にCAPTCHAを解くことで、AIモデル用の高品質なデータセットを構築するための自動化された戦略を発見しましょう。
