Bagaimana AI Pengenalan Gambar Bekerja? | Panduan Teknis

Emma Foster
Machine Learning Engineer
TL;Dr
- AI pengenalan gambar mengubah pixel visual menjadi data numerik untuk interpretasi mesin.
- Jaringan Saraf Konvolusional (CNN) adalah arsitektur inti yang digunakan untuk mengidentifikasi pola seperti tepi dan bentuk.
- Proses melibatkan pipa terstruktur dari pengumpulan data dan penandaan hingga pelatihan dan evaluasi model.
- Aplikasi dunia nyata mencakup diagnostik medis hingga sistem keamanan otomatis seperti Vision Engine CapSolver.
- Sumber data etis dan kepatuhan teknis penting untuk pengembangan AI yang berkelanjutan.
Pendahuluan
AI pengenalan gambar bekerja dengan mengubah informasi visual menjadi array matematis yang dianalisis jaringan saraf untuk pola tertentu. Teknologi ini memungkinkan mesin mengidentifikasi objek, orang, dan tindakan dalam gambar digital dengan kecepatan dan akurasi yang luar biasa. Bagi pengembang dan penggemar data, memahami cara kerja AI pengenalan gambar adalah langkah pertama menuju pembuatan sistem visi komputer lanjutan.
Dengan kesimpulan ini, efektivitas pengenalan gambar bergantung pada kualitas data pelatihan dan kesulitan arsitektur neural. Panduan ini mengungkap lapisan teknis AI visual, mulai dari pemrosesan pixel mentah hingga klasifikasi objek kompleks. Kami akan mengeksplorasi bagaimana sistem modern menggunakan matematika untuk "melihat" dan memahami dunia sekitar kita.
Memahami Dasar: Pixel dan Data Numerik
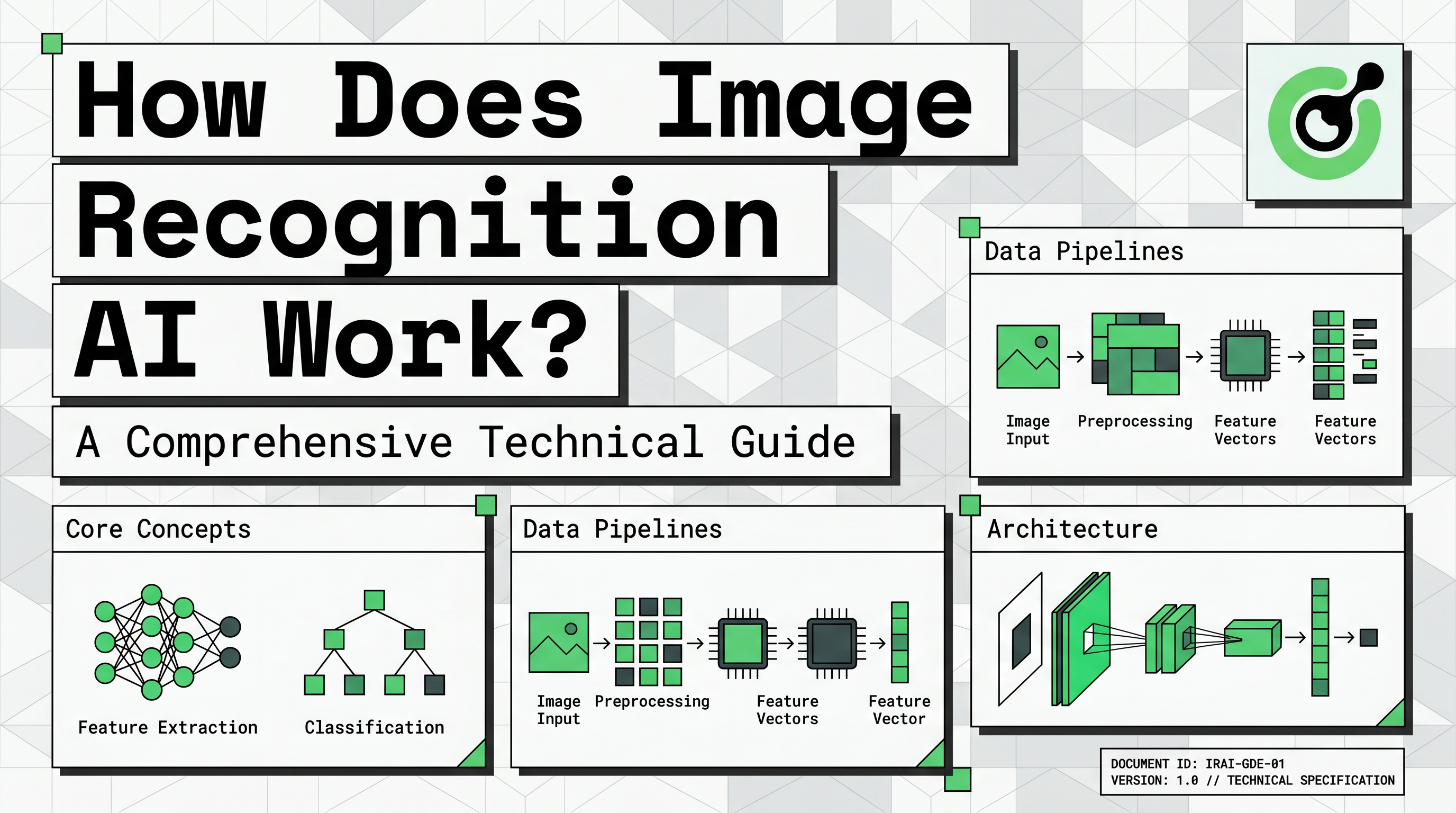
Untuk memahami cara kerja AI pengenalan gambar, kita harus terlebih dahulu melihat bagaimana komputer memahami gambar. Gambar digital pada dasarnya adalah kisi besar dari elemen kecil yang disebut pixel. Setiap pixel berisi nilai numerik yang merepresentasikan intensitas cahaya atau tingkat warna.
Dalam gambar berwarna standar, setiap pixel direpresentasikan oleh tiga nilai: merah, hijau, dan biru (RGB). Nilai-nilai ini biasanya berkisar dari 0 hingga 255. Mesin melihat foto mobil bukan sebagai kendaraan, tetapi sebagai matriks besar angka. Representasi numerik ini adalah input mentah yang diproses sistem pengenalan gambar untuk menemukan pola yang bermakna.
| Komponen | Representasi Mesin | Fungsi |
|---|---|---|
| Pixel | Nilai Numerik (0-255) | Unit dasar data visual |
| Saluran Warna | Matriks RGB | Menyediakan informasi warna dan kedalaman |
| Gambar Tensor | Array Multidimensi | Struktur data lengkap untuk input AI |
Perpindahan dari input visual ke tensor yang dapat dibaca mesin sangat penting. Ini memungkinkan AI melakukan operasi matematis pada data untuk mengidentifikasi fitur yang secara alami dikenali manusia.
Mesin AI Visual: Jaringan Saraf Konvolusional (CNN)
Teknologi utama di balik sistem visual modern adalah Jaringan Saraf Konvolusional (CNN). Arsitektur ini dirancang khusus untuk memproses struktur data berbentuk grid seperti gambar. Ketika menjelajahi cara kerja AI pengenalan gambar, CNN adalah komponen teknis yang paling penting untuk dipahami.
CNN terdiri dari beberapa lapisan yang melakukan fungsi berbeda. Lapisan pertama adalah lapisan konvolusional, yang menerapkan filter pada gambar untuk mengekstrak fitur tingkat rendah. Fitur-fitur ini termasuk elemen sederhana seperti garis horizontal, tepi vertikal, dan tekstur dasar.
Berikutnya, lapisan pooling mengurangi dimensi data sambil mempertahankan informasi paling penting. Langkah ini membuat sistem lebih efisien dan membantu fokus pada fitur paling relevan. Akhirnya, lapisan terhubung penuh mengambil informasi yang diproses dan melakukan klasifikasi akhir. Ini adalah tempat AI memutuskan apakah fitur yang dikenali merepresentasikan kucing, mobil, atau jenis teks tertentu.
Menurut IBM: Apa itu Pengenalan Gambar?, lapisan-lapisan ini bekerja sama untuk membangun pemahaman hierarkis terhadap gambar. Sistem mulai dari garis sederhana dan secara bertahap membangun ke objek kompleks. Pendekatan hierarkis ini adalah alasan mengapa CNN sangat efektif dalam menangani tugas visual yang beragam.
Pipa Pengenalan Gambar: Dari Data ke Pengembangan
Membangun sistem yang sukses melibatkan pipa terstruktur yang melebihi hanya jaringan saraf. Tahap pertama adalah pengumpulan data, di mana pengembang mengumpulkan ribuan gambar yang relevan dengan tugas target mereka. Misalnya, sistem yang dirancang untuk mengidentifikasi kelainan medis memerlukan dataset besar dari scan klinis.
Penandaan data adalah langkah kritis berikutnya. Anotator manusia harus menandai gambar dengan klasifikasi yang benar atau menggambar kotak pembatas di sekitar objek tertentu. Data yang diberi label ini berfungsi sebagai "kebenaran sejati" yang digunakan AI untuk belajar selama fase pelatihan. Tanpa label berkualitas tinggi, bahkan CNN terbaik akan gagal menghasilkan hasil yang akurat.
Pra-pemrosesan dan augmentasi juga penting. Ini melibatkan penyesuaian ukuran gambar, normalisasi nilai warna, dan pembuatan variasi dari data yang ada. Augmentasi membantu model menjadi lebih tangguh dengan melatihnya pada versi gambar asli yang diputar, dibalik, atau sedikit kabur. Ini memastikan AI dapat mengenali objek dalam kondisi nyata yang berbeda.
Akhirnya, model dievaluasi menggunakan metrik seperti presisi, recall, dan akurasi. Tahap pengujian ini menentukan apakah sistem siap untuk pengembangan. Pengembang harus memastikan AI berkinerja andal pada data baru yang tidak pernah dilihat sebelumnya sebelum diintegrasikan ke dalam aplikasi langsung.
Aplikasi Praktis: Menyelesaikan Tantangan Visual Kompleks
Pengenalan gambar digunakan di banyak industri untuk mengotomasi tugas yang sebelumnya manual. Dalam kesehatan, ini membantu radiolog mengidentifikasi tanda awal penyakit dalam X-ray. Dalam ritel, ini menggerakkan sistem checkout otomatis dan alat pencarian visual yang membantu pelanggan menemukan produk menggunakan foto.
Aplikasi khusus dari teknologi ini ditemukan dalam keamanan dan otomatisasi. Misalnya, CapSolver menggunakan pengenalan gambar lanjutan untuk menyelesaikan tantangan visual kompleks seperti CAPTCHAs. Engine Vision-nya adalah contoh utama bagaimana pengenalan gambar AI bekerja dalam lingkungan akurasi tinggi.
Dengan menggunakan CapSolver Vision Engine, pengembang dapat mengotomasi pengenalan teka-teki visual dengan presisi ekstrem. Ini sangat berguna untuk tugas penggalian data dan ekstraksi di mana otomatisasi tradisional mungkin terblokir. Untuk mereka yang ingin menerapkan teknologi ini, panduan praktis tentang AI dan LLM dalam otomatisasi dapat memberikan strategi implementasi yang bernilai. Berikut adalah contoh konseptual cara berinteraksi dengan API pengenalan visual:
python
import requests
# Contoh penggunaan mesin pengenalan gambar untuk pengenalan gambar
def solve_visual_task(image_path, api_key):
url = "https://api.capsolver.com/createTask"
payload = {
"clientKey": api_key,
"task": {
"type": "ImageToTextTask",
"body": "string_base64_gambar"
}
}
response = requests.post(url, json=payload)
return response.json()
# Ini menunjukkan penggunaan praktis pengenalan gambar dalam otomatisasiPeran AI dalam penyelesaian CAPTCHA menyoroti kematangan teknis pengenalan gambar modern. Ini menunjukkan bahwa AI sekarang dapat menangani tugas visual subjektif yang dulu dianggap hanya dapat diselesaikan manusia. Perkembangan ini adalah bagian dari tren yang lebih luas di mana AI dan LLM mengubah lingkungan CAPTCHA dengan memberikan kemampuan pemikiran yang lebih canggih.
Tugas Objektif vs. Subjektif dalam AI Visual
Tidak semua tugas pengenalan gambar sama dalam kompleksitasnya. Pengembang sering mengklasifikasikan tugas berdasarkan tingkat subjektivitas dan presisi yang diperlukan.
| Kategori Tugas | Deskripsi | Contoh |
|---|---|---|
| Objektif | Kriteria jelas dengan jawaban biner | Apakah ada anjing dalam foto ini? |
| Subjektif | Membutuhkan interpretasi yang halus | Apakah scan medis ini menunjukkan pertumbuhan jinak atau ganas? |
| Kuantitatif | Melibatkan perhitungan atau pengukuran | Berapa banyak mobil dalam tempat parkir ini? |
| Kualitatif | Menilai kualitas gambar | Apakah foto produk cukup jelas untuk situs e-commerce? |
Memahami kategori ini membantu pengembang memilih model dan strategi pelatihan yang tepat. Tugas objektif biasanya lebih mudah dikuasai AI, sementara tugas subjektif memerlukan dataset yang lebih luas dan pengawasan manusia.
FAQ
Apa perbedaan antara pengenalan gambar dan deteksi objek?
Pengenalan gambar mengidentifikasi subjek utama gambar, sementara deteksi objek menemukan dan menandai objek banyak dalam satu frame. Deteksi objek biasanya lebih kompleks karena memerlukan mengidentifikasi lokasi setiap objek.
Mengapa CNN lebih disukai untuk tugas terkait gambar?
CNN lebih disukai karena dapat secara otomatis belajar hierarki spasial fitur. Mereka menggunakan lapisan konvolusional untuk mengidentifikasi pola sederhana seperti tepi dan secara bertahap menggabungkannya menjadi objek kompleks. Ini membuatnya lebih efisien daripada jaringan saraf tradisional untuk data visual.
Berapa banyak data yang dibutuhkan untuk melatih model pengenalan gambar yang andal?
Jumlah data tergantung pada kompleksitas tugas. Untuk klasifikasi sederhana, beberapa ribu gambar mungkin cukup. Namun, untuk sistem akurasi tinggi di bidang seperti kendaraan otonom, jutaan gambar yang diberi label sering diperlukan untuk memastikan keselamatan dan keandalan.
Apakah AI pengenalan gambar dapat bekerja secara real-time?
Ya, perangkat keras modern dan arsitektur neural yang dioptimalkan memungkinkan pengenalan gambar secara real-time. Ini penting untuk aplikasi seperti pengenalan wajah keamanan dan navigasi kendaraan otonom, di mana keputusan harus dibuat dalam milisekon.
Kesimpulan
Menguasai cara kerja AI pengenalan gambar membutuhkan pemahaman mendalam tentang arsitektur neural dan manajemen data. Dengan menggabungkan CNN yang kuat dengan dataset berkualitas tinggi, pengembang dapat menciptakan sistem yang menginterpretasi dunia visual dengan presisi yang luar biasa. Teknologi ini terus berkembang, membuka kemungkinan baru untuk otomatisasi dan pengambilan keputusan cerdas.
Jika Anda mencari untuk mengintegrasikan visual AI lanjutan ke dalam alur kerja Anda, eksplorasi CapSolver hari ini. Solusi kami dirancang untuk menangani tugas pengenalan gambar paling menantang dengan mudah.
Lihat Lebih Banyak
aws wafJul 23, 2026
Cara Menyelesaikan AWS WAF di LangChain dengan CapSolver
Bangun alur kerja AWS WAF LangChain yang terotorisasi dengan alat CapSolver, deteksi respons, penghalang kebijakan, penanganan sesi, pengulangan, dan verifikasi.
AIJul 23, 2026
Cara Menyelesaikan Cloudflare Turnstile dalam Agen LangGraph
Bangun alur kerja solver Cloudflare Turnstile LangGraph dengan CapSolver, penanganan sesi Playwright, tahapan kebijakan, pengulangan, verifikasi, dan ulasan.