Pustaka Java Web Scraping Terbaik untuk Ekstraksi Data yang Andal

Emma Foster
Machine Learning Engineer

TL;DR
- Pustaka web scraping Java sebaiknya dipilih berdasarkan jenis halaman, bukan popularitas.
- jsoup terbaik untuk parsing HTML statis dan ekstraksi berbasis selector.
- Selenium Java scraping cocok untuk halaman yang memerlukan tindakan browser nyata.
- Playwright untuk Java kuat untuk alur kerja JavaScript modern yang berat.
- HtmlUnit cocok untuk tugas yang lebih ringan dengan perilaku browser.
- Apache Nutch cocok untuk crawling dan indeksing perusahaan.
- API web scraping lebih baik ketika CAPTCHA, skala, dan operasi mendominasi.
Pendahuluan
Pustaka web scraping Java terbaik bergantung pada cara halaman target menyampaikan data. Halaman statis memerlukan parsing cepat. Halaman dinamis memerlukan otomatisasi browser. Program crawling besar memerlukan antrian, indeks, dan pemantauan. Alur CAPTCHA memerlukan layanan yang terdokumentasi, bukan logika kustom yang rapuh. Panduan ini membantu pengembang memilih antara jsoup, Selenium Java scraping, Playwright untuk Java, HtmlUnit, Apache Nutch, opsi framework crawler Java, dan API web scraping. Gunakan alat terkecil yang andal, ikuti aturan situs, dan pertahankan alur kerja yang dapat dipelihara.
Mengapa Java Digunakan untuk Web Scraping
Java adalah bahasa scraping yang kuat ketika proyek harus berjalan selama bulan, bukan menit. Java mendukung kode bertipe, manajemen dependensi yang stabil, klien HTTP yang matang, dan observabilitas yang ramah produksi. Oracle menggambarkan Java sebagai platform pengembangan utama untuk mengurangi waktu pengembangan dan menjalankan aplikasi di berbagai lingkungan melalui model Java Oracle Java.
Pustaka web scraping Java juga sesuai dengan kebiasaan perusahaan. Tim dapat menambahkan ulang coba, log, batas kecepatan, pengujian, dan kontrol akses. Java mungkin bukan yang tercepat untuk prototipe. Ia menjadi menarik ketika keandalan dan pemeliharaan penting.
Kuncinya adalah menyesuaikan alat dengan konten. Parser tidak dapat merender halaman React. Browser mungkin terlalu berat untuk HTML statis. Kerangka crawler mungkin terlalu berat untuk satu halaman produk. Pustaka web scraping Java terbaik menyelesaikan masalah yang didefinisikan.
Ringkasan Perbandingan
| Alat | Terbaik untuk | Penanganan JavaScript | Skala Cocok | Keterbatasan Utama |
|---|---|---|---|---|
| jsoup | Parsing HTML statis | Tidak | Menengah | Membutuhkan alat lain untuk rendering |
| HttpClient + jsoup | Scraping statis yang terkendali | Tidak | Menengah hingga Tinggi | Memerlukan logika pengambilan kustom |
| Selenium | Otomatisasi browser | Kuat | Rendah hingga Menengah | Runtime berat dan selector rapuh |
| Playwright untuk Java | Otomatisasi browser modern | Kuat | Menengah | Memerlukan manajemen runtime browser |
| HtmlUnit | Alur kerja browser ringan | Sebagian hingga Baik | Menengah | Bukan pengganti browser penuh |
| WebMagic atau Gecco | Proyek framework crawler Java | Terbatas | Menengah | Ekosistem yang lebih kecil |
| Apache Nutch | Crawling dan indeksing perusahaan | Terbatas | Tinggi | Setup dan operasi kompleks |
| API web scraping | Operasi scraping yang dikelola | Ditangani penyedia | Tinggi | Kontrol yang lebih sedikit |
Pustaka Web Scraping Statis dalam Java
Scraping statis sebaiknya dimulai dengan parser. Jika respons HTML pertama mengandung data yang diperlukan, otomatisasi browser menambah biaya tanpa meningkatkan akurasi. Pustaka web scraping Java dalam kategori ini cepat, dapat diuji, dan lebih mudah dioperasikan.
jsoup untuk Pemrosesan HTML
jsoup adalah pilihan pertama terbaik untuk HTML statis. Situs resmi jsoup menggambarkannya sebagai parser HTML untuk HTML dan XML dunia nyata, dengan pengambilan URL, parsing, metode DOM, pemilih CSS, dan pemilih XPath dokumentasi resmi jsoup.
Gunakan jsoup untuk halaman artikel, halaman kategori, halaman produk sederhana, tabel, dan fragmen HTML. Ia menangani markup yang tidak sempurna dengan baik. Hal ini penting karena banyak halaman dapat dibaca oleh browser tetapi tidak cukup bersih untuk alat XML yang ketat.
Alur kerja jsoup yang andal langsung. Minta halaman dengan header yang jelas. Parsing dokumen. Pilih bidang dengan pemilih CSS yang stabil. Validasi nilai kosong sebelum penyimpanan. Pola ini menjaga prediktabilitas pustaka web scraping Java.
jsoup bukan browser. Ia tidak mengeksekusi JavaScript. Jika konten hanya muncul setelah skrip berjalan, periksa panggilan jaringan terlebih dahulu. Jika endpoint yang diizinkan ada, gunakan klien HTTP. Jika perilaku browser diperlukan, gunakan Selenium atau Playwright untuk Java.
Pendekatan HttpClient + jsoup
HttpClient + jsoup ideal untuk scraping statis yang terkendali. Klien HTTP Java dapat mengelola header, timeout, redirect, dan tubuh respons. jsoup kemudian memproses HTML. Pemisahan ini menjaga pengambilan dan parsing tetap bersih.
Pendekatan ini bekerja untuk pemantauan harga, direktori publik, audit konten, dan dataset penelitian. Lebih baik daripada pengambilan jsoup langsung ketika Anda memerlukan pelacakan, aturan ulang coba, penundaan crawling, atau konfigurasi proxy.
Pustaka Web Scraping Dinamis dalam Java
Halaman dinamis memerlukan perilaku browser. Mereka mungkin memuat konten setelah menggulir, mengklik, otentikasi, atau permintaan latar belakang. Selenium Java scraping, Playwright untuk Java, dan HtmlUnit menyelesaikan ini secara berbeda.
Selenium untuk Otomatisasi Browser
Selenium sudah matang dan memiliki dokumentasi yang luas. Situs resmi proyek menggambarkan Selenium sebagai alat dan pustaka yang memungkinkan otomatisasi browser, dengan WebDriver sebagai antarmuka inti untuk menjalankan instruksi di browser utama dokumentasi Selenium.
Selenium Java scraping bekerja ketika situs memerlukan tindakan browser nyata. Ia dapat mengklik tombol, menunggu elemen, mengirim formulir, dan membaca DOM yang dirender. Ia juga cocok untuk tim yang sudah menggunakan Selenium untuk pengujian QA.
Perbedaannya adalah biaya. Sesi browser menghabiskan CPU dan memori. Selector dapat rusak ketika antarmuka berubah. Gunakan Selenium Java scraping ketika keakuratan browser lebih penting daripada kecepatan.
Jika CAPTCHA muncul dalam pengujian yang diizinkan atau otomatisasi yang diperbolehkan, jangan sembunyikan di dalam skrip rapuh. Tinjau aturan target terlebih dahulu. Lalu gunakan alur kerja yang terdokumentasi seperti integrasi CAPTCHA Selenium dari CapSolver.
Playwright untuk Java
Playwright untuk Java kuat untuk otomatisasi modern. Situs resmi Java Playwright menyatakan bahwa Playwright dapat menggerakkan Chromium, Firefox, dan WebKit melalui satu API, dengan dukungan Java tersedia dokumentasi Playwright untuk Java.
Playwright untuk Java sering mengurangi otomatisasi yang tidak stabil. Menunggu otomatis, konteks browser, pelacakan, dan pencari yang tangguh membantu menjaga alur kerja stabil. Ia cocok untuk proyek pustaka web scraping Java yang memerlukan tangkapan layar, unduhan, navigasi halaman multi, atau penundaan yang dapat diandalkan.
Pilih Playwright untuk Java ketika halaman berat JavaScript dan konteks browser yang dapat diulang penting. Hindari itu ketika permintaan HTTP sederhana mengembalikan data yang sama. Browser seharusnya menjadi lapisan terakhir yang diperlukan, bukan kebiasaan pertama.
Untuk CAPTCHA dalam otomatisasi yang diizinkan, kaitkan alur kerja dengan panduan resmi. CapSolver mempublikasikan integrasi CAPTCHA Playwright yang lebih aman daripada menyalin potongan kode acak.
HtmlUnit untuk Penanganan JS Ringan
HtmlUnit berada di antara parsing dan otomatisasi browser penuh. Situs resmi menggambarkannya sebagai "browser tanpa antarmuka GUI untuk program Java." Ia dapat memanggil halaman, mengisi formulir, mengklik tautan, mengelola cookie, dan menyediakan dukungan JavaScript untuk banyak alur kerja AJAX dokumentasi HtmlUnit.
Gunakan HtmlUnit untuk situs lama, alur formulir sederhana, alat internal, dan sistem pengujian. Ia lebih ringan daripada otomatisasi browser penuh. Hal ini dapat mengurangi biaya infrastruktur untuk beban kerja menengah.
HtmlUnit bukan pengganti penuh untuk Chrome, Firefox, atau WebKit. Kerangka frontend modern mungkin mengungkap kelemahan. Jika rendering visual atau peristiwa kompleks penting, Selenium atau Playwright untuk Java lebih aman.
Kerangka Crawler Java untuk Crawling Skala Besar
Crawling skala besar berbeda dari ekstraksi halaman. Ia memerlukan manajemen frontir, deduplikasi, aturan ulang coba, kontrol kesopanan, parsing, indeks, dan pemantauan. Kerangka crawler Java membantu ketika scraper menjadi sistem.
WebMagic dan Gecco
WebMagic dan Gecco adalah opsi kerangka crawler Java yang praktis untuk proyek menengah. Mereka mengatur logika downloader, pemroses halaman, pipeline, dan model data. Hal ini membuat kode lebih mudah dibagi di antara tim.
Gunakan mereka untuk katalog publik, cerminan dokumentasi, pencarian konten berulang, dan halaman yang serupa. Mereka kurang cocok untuk halaman yang sangat dinamis kecuali dikombinasikan dengan lapisan rendering. Kekuatan utama mereka adalah pemeliharaan. Kekurangan utama adalah ekosistem yang lebih kecil dibanding jsoup, Selenium, atau Playwright.
Apache Nutch untuk Crawling Perusahaan
Apache Nutch dibangun untuk program crawling besar. Halaman utamanya menggambarkannya sebagai crawler web yang sangat dapat diperluas, sangat skalabel, matang, dan siap produksi proyek Apache Nutch. Ia mendukung parsing, indeks, skoring, dan integrasi dengan sistem pencarian yang dapat dipasang.
Gunakan Apache Nutch ketika crawling adalah kebutuhan platform. Ia cocok untuk indeks pencarian, pencarian perusahaan, dan pengumpulan data skala besar berulang. Ia tidak ideal untuk scraper kecil yang sekali pakai. Setup dan operasi memerlukan waktu insinyur nyata.
Sebelum memperluas kerangka crawler Java, tentukan domain yang diizinkan, frekuensi pembaruan, aturan penyimpanan, dan batas permintaan. Panduan CapSolver tentang kelegalan web scraping dan aturan utama berguna untuk perencanaan.
Tantangan CAPTCHA dalam Web Scraping Java
CAPTCHA adalah sinyal alur kerja, bukan hanya masalah teknis. Ia mungkin menunjukkan tekanan kecepatan, risiko login, aturan akses, atau izin yang hilang. Tangani dengan hati-hati. Pastikan kasus penggunaan Anda diizinkan, kurangi volume permintaan, dan kumpulkan hanya data yang diperlukan.
Pustaka web scraping Java tidak menyelesaikan CAPTCHA sendirian. jsoup tidak dapat berinteraksi dengan tantangan. Selenium dan Playwright dapat menampilkan CAPTCHA, tetapi tetap memerlukan proses penanganan yang valid. HtmlUnit jarang menjadi lapisan yang tepat untuk tugas ini.
CapSolver relevan ketika proses otomatisasi yang sah memerlukan penyelesaian CAPTCHA. Contohnya termasuk pengujian QA, alur kerja yang dimiliki akun, dan scraping yang diizinkan. Dokumentasi API resmi CapSolver menyebutkan createTask dan getTaskResult sebagai titik akhir inti untuk pembuatan tugas dan pengambilan hasil dokumentasi API CapSolver. Gunakan dokumen resmi secara langsung untuk detail implementasi.
Proses yang aman sederhana. Dokumentasikan target, pastikan izin, batasi kecepatan permintaan, dan simpan hanya bidang yang diperlukan. FAQ CapSolver tentang API web scraping dan penyelesaian CAPTCHA adalah sumber perencanaan yang berguna.
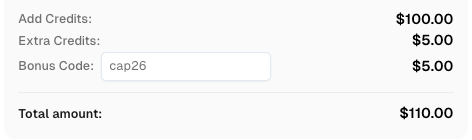
Dapatkan Kode Bonus CapSolver Anda
Tingkatkan anggaran otomatisasi Anda secara instan!
Gunakan kode bonus CAP26 saat menambahkan dana ke akun CapSolver untuk mendapatkan bonus tambahan 5% pada setiap penambahan dana — tanpa batas.
Dapatkan sekarang di Dashboard CapSolver
Kapan Menggunakan API Web Scraping Daripada Pustaka
Gunakan API web scraping ketika operasi lebih penting daripada kontrol kode. Pustaka web scraping Java fleksibel, tetapi tim harus mengelola runtime browser, ulang coba, pemantauan, drift parser, dan alur kerja CAPTCHA.
API web scraping masuk akal untuk pengumpulan volume tinggi, antarmuka yang tidak stabil, halaman berat JavaScript, dan tim tanpa infrastruktur scraping. Ia juga dapat mengurangi kebutuhan untuk farm browser. Perbedaannya adalah ketergantungan vendor, jadi tinjau kualitas data, harga, log, dan ketentuan kepatuhan.
Model hibrid sering kali terbaik. Gunakan jsoup untuk halaman statis yang stabil. Gunakan Selenium Java scraping atau Playwright untuk Java untuk alur kerja dinamis yang kecil. Gunakan Apache Nutch ketika crawling menjadi platform pencarian. Gunakan API web scraping ketika beban infrastruktur menjadi utama. Panduan CapSolver tentang tantangan web scraping umum dapat membantu tim mempersiapkan diri.
Kesimpulan dan CTA
Pustaka web scraping Java terbaik diperingkat berdasarkan kesesuaian, bukan hype. jsoup terbaik untuk HTML statis. HttpClient plus jsoup menambah kontrol. Selenium Java scraping dan Playwright untuk Java menangani halaman dinamis. HtmlUnit menangani alur kerja browser ringan. WebMagic, Gecco, dan Apache Nutch mendukung arsitektur crawler. API web scraping membantu ketika beban infrastruktur meningkat.
Mulai kecil dan tetap patuh. Baca aturan situs, hormati batas kecepatan, minimalisasi pengumpulan, dan pertahankan log. Jika CAPTCHA muncul dalam alur kerja yang diizinkan, gunakan dokumentasi resmi dan penyedia khusus seperti CapSolver.
FAQ
Apa pustaka web scraping Java terbaik?
jsoup adalah pilihan pertama terbaik untuk HTML statis. Playwright untuk Java atau Selenium lebih baik untuk halaman berat JavaScript. Apache Nutch lebih baik untuk crawling perusahaan.
Apakah Selenium Java scraping lebih baik daripada Playwright untuk Java?
Selenium memiliki sejarah dan dukungan ekosistem yang lebih luas. Playwright untuk Java sering menawarkan fitur otomatisasi modern yang lebih kuat, termasuk menunggu otomatis dan konteks browser.
Apakah jsoup dapat mengambil situs dinamis?
jsoup dapat memproses HTML yang dikembalikan, tetapi tidak mengeksekusi JavaScript. Gunakan otomatisasi browser ketika konten hanya muncul setelah skrip berjalan.
Apakah Apache Nutch cocok untuk proyek scraping kecil?
Biasanya tidak. Apache Nutch kuat, tetapi lebih baik untuk sistem crawling besar, indeks pencarian, dan pengadaan data perusahaan.
Kapan saya harus menggunakan CapSolver dengan web scraping Java?
Gunakan CapSolver hanya untuk otomatisasi yang sah dan terdokumentasi di mana penyelesaian CAPTCHA diizinkan. Ikuti dokumen API resmi CapSolver dan aturan situs target.
Lihat Lebih Banyak
AIJun 23, 2026
SDK Pengurai Captcha Asli untuk Agen AI
Panduan yang fokus pada pengembang untuk SDK penyelesaian CAPTCHA native untuk agen AI, dengan batas wrapper, contoh resmi, pemeriksaan sesi, dan penanganan kegagalan.
AIJun 23, 2026
Memilih Layanan Pemecah CAPTCHA untuk Otomasi Agen
Checklist praktis untuk pembeli dan insinyur dalam memilih layanan penyelesaian CAPTCHA untuk otomatisasi agen dalam alur kerja yang terkontrol dan terdokumentasi.