हेडलेस ब्राउज़र्स में CAPTCHA हल करना स्वचालित करें: पूर्ण कार्य प्रवाह गाइड

Emma Foster
Machine Learning Engineer

TL;Dr:
- उद्देश्य: प्रभावी वेब ऑटोमेशन के लिए हेडलेस ब्राउजर वातावरण में CAPTCHA हल करना स्वचालित करें।
- मुख्य चरण: वातावरण सेटअप, API एकीकरण (CapSolver), कार्य बनाना, परिणाम प्राप्त करना, और ऑटोमेशन स्क्रिप्ट में एकीकरण।
- लाभ: हस्तक्षेप कम करें, ऑटोमेशन की विश्वसनीयता में सुधार करें, और डेटा संग्रह प्रयासों को पैमाने पर बढ़ाएं।
- CapSolver: विश्वसनीय और कुशल CAPTCHA हल करने के लिए एक सिफारिश की गई सेवा, विभिन्न कार्य प्रकार और एकीकरण विकल्प प्रदान करती है।
- अनुकूलन: प्रॉक्सी का उपयोग करें, अनुरोध आवृत्ति का प्रबंधन करें, और त्रुटियों का निपटान करें ताकि ऑटोमेशन विश्वसनीय हो।
परिचय
वेब ऑटोमेशन के दौरान CAPTCHA का सामना आमतौर पर होता है, जो एक ऑटोमेटेड बॉट से मानव उपयोगकर्ता के बीच अंतर करने के लिए डिज़ाइन किया गया है। हेडलेस ब्राउजर का उपयोग डेटा स्क्रैपिंग, मॉनिटरिंग या परीक्षण के लिए किया जाता है, लेकिन इन चुनौतियां प्रगति को रोक सकती हैं। इस गाइड में हेडलेस ब्राउजर में CAPTCHA हल करने के लिए एक व्यापक, चरण-दर-चरण वर्कफ़्लो को प्रदान किया गया है, जिससे आपके ऑटोमेशन प्रक्रियाएं चलती रहेंगी और दक्ष होंगी। हम वातावरण सेटअप से लेकर CapSolver जैसी विश्वसनीय CAPTCHA हल करने वाली सेवा के साथ एकीकरण, परिणाम प्रक्रिया और सामान्य समस्याओं के निपटान के बारे में सब कुछ कवर करेंगे। इस पाठ्य पुस्तक के अंत में, आपके हेडलेस ब्राउजर परियोजनाओं में CAPTCHA के प्रबंधन के लिए ज्ञान और साधन प्राप्त होंगे, जिससे आपके वेब ऑटोमेशन प्रयासों की विश्वसनीयता और पैमाने को बढ़ाया जा सके।
हेडलेस ब्राउजर और CAPTCHA के बारे में समझ
हेडलेस ब्राउजर एक ग्राफिकल उपयोगकर्ता इंटरफ़ेस के बिना वेब ब्राउजर होते हैं, जिनका आमतौर पर ऑटोमेटेड परीक्षण, वेब स्क्रैपिंग और सर्वर-साइड रेंडरिंग के लिए उपयोग किया जाता है। लोकप्रिय उदाहरण Puppeteer चरम के लिए और Playwright विभिन्न ब्राउजर के लिए हैं। ये शक्तिशाली होते हैं, लेकिन उनकी ऑटोमेटेड प्रकृति उन्हें CAPTCHA का उपयोग करने वाली वेबसाइटों द्वारा डिटेक्ट करने के लिए अक्सर असुरक्षित बना देती है। CAPTCHA एक महत्वपूर्ण सुरक्षा परत होती है, जो ऑटोमेटेड एक्सेस और वेब संसाधनों के दुरुपयोग को रोकने के लिए डिज़ाइन की गई होती है। चुनौती यह है कि एक समाधान के साथ एकीकृत करें जो इन पहेलियों को बिना ऑटोमेशन प्रक्रियाओं के दक्षता को प्रभावित किए हल कर सके। यहां तक कि हेडलेस ब्राउजर में CAPTCHA हल करने के लिए स्वचालन महत्वपूर्ण हो जाता है।
हेडलेस ब्राउजर में CAPTCHA क्यों दिखाई देते हैं
वेबसाइटें ऑटोमेटेड गतिविधि की जांच के लिए विभिन्न तकनीकों का उपयोग करती हैं, जैसे ब्राउजर फिंगरप्रिंट्स, उपयोगकर्ता व्यवहार पैटर्न और IP पते के विश्लेषण। जब इन प्रणालियां हेडलेस ब्राउजर को गैर-मानव के रूप में चिन्हित करती हैं, तो आमतौर पर एक CAPTCHA प्रस्तुत किया जाता है। यह योजना स्पैम, ऑटोमेटेड लॉगिन और डेटा निकासी के खिलाफ सुरक्षा के लिए डिज़ाइन की गई है। प्रभावी वेब ऑटोमेशन के लिए, हेडलेस ब्राउजर में CAPTCHA हल करने के लिए एक विश्वसनीय रणनीति अनिवार्य हो जाती है।
CAPTCHA हल करने के लिए हेडलेस ब्राउजर में स्वचालन के लिए चरण-दर-चरण वर्कफ़्लो
इस खंड में हम हेडलेस ब्राउजर ऑटोमेशन में CAPTCHA हल करने वाली सेवा के साथ एकीकरण की पूर्ण प्रक्रिया के बारे में बताएंगे। हम CapSolver का उदाहरण के रूप में उपयोग करेंगे क्योंकि इसका पूर्ण API है और विभिन्न CAPTCHA प्रकारों का समर्थन करता है।
चरण 1: वातावरण तैयार करें
शुरू करने से पहले, आपके विकास वातावरण को आवश्यक उपकरणों के साथ सेटअप करना सुनिश्चित करें। इसमें हेडलेस ब्राउजर लाइब्रेरी और CAPTCHA हल करने वाले API के साथ बातचीत करने के लिए एक पायथन वातावरण के साथ स्थापित करना शामिल है।
उद्देश्य: हेडलेस ब्राउजर स्क्रिप्ट चलाने और बाहरी सेवाओं के साथ बातचीत करने के लिए एक कार्यक्षम आधार स्थापित करना।
ऑपरेशन:
- Python स्थापित करें: अपने सिस्टम में Python 3.x सुनिश्चित करें।
- हेडलेस ब्राउजर लाइब्रेरी स्थापित करें: Puppeteer (Node.js के लिए) या Playwright (पायथन, Node.js, जावा, .NET के लिए) चुनें। इस गाइड के लिए हम पायथन वातावरण के साथ Playwright के अपेक्षा करते हैं।
bash
pip install playwright playwright install - Requests लाइब्रेरी स्थापित करें: इसका उपयोग CapSolver API के साथ बातचीत करने के लिए किया जाएगा।
bash
pip install requests - CapSolver API कुंजी प्राप्त करें: CapSolver वेबसाइट पर पंजीकरण करें और डैशबोर्ड से अपना API कुंजी प्राप्त करें। यह कुंजी आपके CAPTCHA हल करने वाली सेवा के लिए आपके अनुरोधों की प्रमाणीकरण के लिए महत्वपूर्ण है।
सावधानी: हमेशा अपना API कुंजी सुरक्षित रखें और निजी रिपॉजिटरी में सीधे कोड में न डालें। बेहतर सुरक्षा अभ्यास के लिए वातावरण चर का उपयोग करें।
चरण 2: CapSolver API का एकीकरण
आपके वातावरण के तैयार होने के बाद, अगला चरण अपने ऑटोमेशन स्क्रिप्ट में CapSolver API के साथ एकीकरण करना है। इसमें CAPTCHA विवरण को CapSolver के साथ भेजना और समाधान प्राप्त करना शामिल है।
उद्देश्य: CAPTCHA चुनौतियां CapSolver के साथ प्रोग्रामेटिक रूप से भेजें और उनके समाधान प्राप्त करें।
ऑपरेशन: एकीकरण में आमतौर पर दो मुख्य API कॉल होते हैं: createTask CAPTCHA को भेजने के लिए और getTaskResult समाधान प्राप्त करने के लिए। नीचे पायथन का एक उदाहरण है जिसका उपयोग requests लाइब्रेरी के साथ किया गया है।
python
import requests
import time
# TODO: set your config
api_key = "YOUR_CAPSOLVER_API_KEY" # Replace with your CapSolver API key
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # Example site key for reCAPTCHA v2 demo
site_url = "https://www.google.com/recaptcha/api2/demo" # Example page URL with reCAPTCHA v2 demo
def solve_recaptcha_v2_capsolver():
print("Creating CAPTCHA task...")
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess', # Using server's built-in proxy
"websiteKey": site_key,
"websiteURL": site_url
}
}
try:
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print(f"Failed to create task: {res.text}")
return None
print(f"Task created with ID: {task_id}. Waiting for result...")
while True:
time.sleep(3) # Wait for 3 seconds before checking the result
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
print("CAPTCHA solved successfully!")
return resp.get("solution", {}).get('gRecaptchaResponse')
elif status == "processing":
print("CAPTCHA still processing...")
elif status == "failed" or resp.get("errorId"):
print(f"CAPTCHA solving failed! Response: {res.text}")
return None
except requests.exceptions.RequestException as e:
print(f"API request failed: {e}")
return None
# Example usage in a headless browser script (conceptual)
# from playwright.sync_api import sync_playwright
# with sync_playwright() as p:
# browser = p.chromium.launch(headless=True)
# page = browser.new_page()
# page.goto(site_url)
# # Trigger CAPTCHA (e.g., by clicking a button or navigating to a protected page)
# # When CAPTCHA appears, call the solver
# captcha_token = solve_recaptcha_v2_capsolver()
# if captcha_token:
# print(f"Received CAPTCHA token: {captcha_token[:30]}...")
# # Inject the token into the page (e.g., via JavaScript or filling a hidden input field)
# # page.evaluate(f"document.getElementById(\'g-recaptcha-response\').value = \'{captcha_token}\';")
# # Submit the form
# else:
# print("Failed to get CAPTCHA token.")
# browser.close()सावधानी: CAPTCHA प्रकार के लिए सामान्य हल करने के समय के आधार पर time.sleep() अवधि को समायोजित करें। अत्यधिक पॉलिंग दर सीमा लगाने के कारण हो सकता है। हमेशा संभावित API त्रुटियां और नेटवर्क समस्याओं के साथ निपटें।
चरण 3: हल किए गए CAPTCHA टोकन का प्रबंधन
जब CapSolver समाधान लौटाता है, तो आपको इस टोकन को अपने हेडलेस ब्राउजर सत्र में वापस डालना होता है ताकि CAPTCHA चुनौति पूरा हो सके।
उद्देश्य: लक्षित वेबसाइट पर CAPTCHA समाधान प्रस्तुत करें और ऑटोमेशन के साथ आगे बढ़ें।
ऑपरेशन: टोकन के डालने की विधि CAPTCHA प्रकार और वेबसाइट के द्वारा समाधान की अपेक्षा के आधार पर अलग-अलग होती है। reCAPTCHA v2 के लिए, टोकन आमतौर पर g-recaptcha-response आईडी वाले छिपे टेक्स्ट एरिया में रखा जाता है।
python
# ... (previous code for solve_recaptcha_v2_capsolver function)
from playwright.sync_api import sync_playwright
# Example usage
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto(site_url)
# Wait for the reCAPTCHA iframe to load and become visible (adjust selectors as needed)
page.wait_for_selector("iframe[title='reCAPTCHA challenge']", timeout=30000)
captcha_token = solve_recaptcha_v2_capsolver()
if captcha_token:
print(f"Received CAPTCHA token: {captcha_token[:30]}...")
# Inject the token into the hidden input field
page.evaluate(f"document.getElementById('g-recaptcha-response').value = '{captcha_token}';")
print("CAPTCHA token injected. Attempting to submit form...")
# Assuming there's a submit button, click it. Adjust selector as needed.
# page.click("button[type='submit']")
# Or, if the form submits automatically after token injection, no click is needed.
page.wait_for_timeout(5000) # Give some time for the form to process
else:
print("Failed to get CAPTCHA token. Automation halted.")
browser.close()सावधानी: CAPTCHA फ्रेम और छिपे इनपुट फ़ील्ड के लिए अपने सेलेक्टर सटीक होने की जांच करें। वेबसाइटें अपनी संरचना बदल सकती हैं, जिसके लिए आपके सेलेक्टर के अपडेट की आवश्यकता हो सकती है। टोकन डालने के बाद फॉर्म सबमिशन की सफलता की जांच करें।
सामान्य समस्याओं के निपटान के लिए समस्याएं
सुदृढ़ सेटअप के बावजूद, आपको समस्याओं का सामना करना पड़ सकता है। नीचे हेडलेस ब्राउजर में CAPTCHA हल करने के दौरान सामान्य समस्याओं और उनके समाधानों के बारे में कुछ सामान्य समस्याएं हैं।
समस्या: taskId नहीं लौटाया गया या API त्रुटियां
समस्या: createTask API कॉल taskId नहीं लौटाता है, या एक त्रुटि संदेश लौटाता है।
समाधान:
- API कुंजी जांचें: अपने
api_keyसही और पर्याप्त बैलेंस के साथ है कि जांचें। - अनुरोध पेलोड की समीक्षा करें:
websiteURL,websiteKey, औरtypeके लिए सही विवरण सुनिश्चित करें, जो CapSolver API दस्तावेज़ीकरण के अनुसार विशिष्ट CAPTCHA प्रकार के लिए निर्दिष्ट हैं। - नेटवर्क समस्याएं: अपना इंटरनेट कनेक्शन जांचें और यह सुनिश्चित करें कि CapSolver API एंडपॉइंट तक पहुंच योग्य है।
समस्या: CAPTCHA टोकन अमान्य या अस्वीकृत
समस्या: CapSolver एक टोकन लौटाता है, लेकिन लक्षित वेबसाइट इसे अस्वीकृत कर देती है।
समाधान:
- सही
websiteKeyऔरwebsiteURL: ये पैरामीटर लक्षित वेबसाइट पर ठीक से मेल खाना चाहिए। यहां तक कि छोटे अंतर अस्वीकृति के कारण हो सकते हैं। - प्रॉक्सी का उपयोग करें: यदि वेबसाइट भू-स्थिति बाधा लगाती है या ठीक IP जांच है, तो
ReCaptchaV2Taskके साथ प्रॉक्सी का उपयोग करें (जैसे,ReCaptchaV2Taskके साथproxyपैरामीटर) जो हेडलेस ब्राउजर के IP पते के साथ मेल खाता है। CapSolver प्रॉक्सी विकल्प प्रदान करता है। - उपयोगकर्ता-एजेंट सामंजस्य: आपके हेडलेस ब्राउजर द्वारा उपयोग किए गए उपयोगकर्ता-एजेंट स्ट्रिंग के लिए आपके द्वारा उपयोग किए गए उपयोगकर्ता-एजेंट के साथ मेल खाना चाहिए या वेबसाइट द्वारा अपेक्षित हो। कुछ उन्नत CAPTCHA अनुक्रमण के लिए सामंजस्य की जांच करते हैं।
- वेबसाइट परिवर्तन: वेबसाइटें अपने CAPTCHA अनुक्रमण अक्सर बदल देती हैं।
websiteKeyया अन्य पैरामीटर बदल सकते हैं। अगर आप अनिश्चित हैं, तो CapSolver एक्सटेंशन का उपयोग करके आवश्यक पैरामीटर स्वचालित रूप से प्राप्त करें।
समस्या: हेडलेस ब्राउजर की पहचान
समस्या: CAPTCHA हल करने के बावजूद, वेबसाइट हेडलेस ब्राउजर की पहचान कर लेती है और पहुंच अस्वीकृत कर देती है।
समाधान:
- स्टील्थ तकनीकें: अपने हेडलेस ब्राउजर के लिए स्टील्थ प्लगइन या कॉन्फ़िगरेशन का उपयोग करें (जैसे, Puppeteer के लिए
puppeteer-extra-plugin-stealth, या समान Playwright कॉन्फ़िगरेशन) जो मानव ब्राउजर व्यवहार के अनुरूप हो। इसमें उपयोगकर्ता-एजेंट, ऑटोमेशन फ्लैग के निष्क्रिय करने और सामान्य ब्राउजर गुणों के प्रबंधन के साथ शामिल हो सकता है जो ऑटोमेशन के बारे में जानकारी देते हैं (मूल्यांकन के लिए MDN वेब डॉक्स पर हेडलेस ब्राउजर देखें)। - वास्तविक देरी: कार्यों के बीच मानव-जैसी देरी जोड़ें। तेज़ और नियमित क्रियाएं ऑटोमेशन के संकेत होती हैं।
- कुकीज़ और स्थानीय भंडारण प्रबंधन: सत्रों के बीच कुकीज़ और स्थानीय भंडारण के पुनः उपयोग के साथ एक संगत ब्राउजिंग प्रोफ़ाइल बनाएं।
- रेफरर हेडर्स: अनुरोधों के साथ उचित रेफरर हेडर्स भेजें।
प्रदर्शन अनुकूलन सुझाव
आपके CAPTCHA हल करने के कार्
| लागत | मानव श्रम | कम (सेटअप) | प्रति-हल की फीस | उच्च (सेटअप, रखरखाव) |
| जटिलता | कोई नहीं | उच्च (विकास) | कम (एपीआई एकीकरण) | बहुत उच्च (एमएल विशेषज्ञता) |
| रखरखाव | कोई नहीं | उच्च | कम | बहुत उच्च |
| CAPTCHA प्रकार | सभी | सरल छवि | सभी प्रमुख प्रकार | विशिष्ट प्रकार (प्रशिक्षित किए गए) |
| स्केलेबिलिटी | कम | मध्यम | उच्च | मध्यम |
एपीआई-आधारित समाधान जैसे कैपसॉल्वर उच्च विश्वसनीयता, गति और एकीकरण में सुविधा के बीच संतुलन प्रदान करते हैं, जो हेडलेस ब्राउजर में CAPTCHA हल करने के लिए ऑटोमेशन के लिए आदर्श हैं बिना महत्वपूर्ण विकास बोझ के।
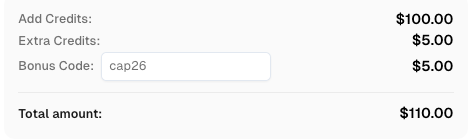
CapSolver पर पंजीकरण करते समय कोड
CAP26का उपयोग करें ताकि बोनस क्रेडिट प्राप्त करें!
निष्कर्ष
हेडलेस ब्राउजर में CAPTCHA हल करने के ऑटोमेशन वेब ऑटोमेशन में शामिल किसी भी व्यक्ति के लिए एक महत्वपूर्ण कौशल है। इस गाइड में वर्णित संरचित वर्कफ़्लो के अनुसार-परिस्थिति सेटअप और एपीआई एकीकरण से परिणाम निपटान और समस्या निवारण तक-आप अपने स्वयं के ऑटोमेटेड कार्यों की दक्षता और सुदृढ़ता में महत्वपूर्ण सुधार कर सकते हैं। कैपसॉल्वर जैसी सेवाएं CAPTCHA चुनौतियों को पार करने के लिए एक शक्तिशाली और विश्वसनीय तरीका प्रदान करती हैं, जिससे आपके हेडलेस ब्राउजर बिना किसी अड़चन के काम कर सकते हैं। ध्यान रखें कि ऑटोमेशन समाधान लागू करते समय आचार संहिता के महत्व को ध्यान में रखें और वेबसाइट की सेवा की शर्तों का पालन करें। वेब ऑटोमेशन चुनौतियों के बारे में अधिक जानकारी के लिए, क्यों वेब ऑटोमेशन CAPTCHA पर विफल रहता है और CAPTCHA सुरक्षित साइटों को कैसे स्क्रैप करें जैसे लेखों का अध्ययन करें।
अक्सर पूछे जाने वाले प्रश्न (FAQ)
Q1: क्या हेडलेस ब्राउजर में CAPTCHA हल करना कानूनी है?
A1: हेडलेस ब्राउजर में CAPTCHA हल करने की कानूनिकता वेबसाइट की सेवा की शर्तों और स्थानीय नियमों पर बहुत अधिक निर्भर करती है। CAPTCHA हल करना खुद में अवैध नहीं है, लेकिन वेबसाइट की नीतियों के उल्लंघन करने के लिए ऑटोमेशन का उपयोग करके सामग्री तक पहुंचना या कार्य करना अवैध हो सकता है। हमेशा आपके द्वारा अंतरक्रिया की जा रही वेबसाइट की सेवा की शर्तों की समीक्षा करें।
Q2: कैपसॉल्वर किन प्रकार के CAPTCHA को संभाल सकता है?
A2: कैपसॉल्वर कई प्रकार के CAPTCHA को समर्थन करता है, जैसे कि reCAPTCHA v2, reCAPTCHA v3, ImageToText और विभिन्न उद्योग विशिष्ट CAPTCHA। इस व्यापक समर्थन के कारण यह हेडलेस ब्राउजर में CAPTCHA हल करने के लिए एक विविध उपकरण बन जाता है जो विभिन्न प्लेटफॉर्म पर काम करता है।
Q3: CAPTCHA हल करने की लागत कम कैसे करें?
A3: लागत कम करने के लिए, अपने ऑटोमेशन स्क्रिप्ट को केवल आवश्यकता होने पर CAPTCHA समाधान के लिए मांग करने के लिए अनुकूलित करें। दोहराए जाने वाले टोकन के लिए कैशिंग का उपयोग करें, परिणामों के लिए दक्ष जांच अंतराल का उपयोग करें, और आवश्यकता से पहले CAPTCHA ट्रिगर को कम करने के लिए अपने हेडलेस ब्राउजर स्टील्थ तकनीकों का सुनिश्चित करें। नियमित रूप से अपने कैपसॉल्वर उपयोग की निगरानी करें और उनके मूल्य श्रेणियों की खोज करें।
Q4: क्या मैं कैपसॉल्वर के साथ अन्य प्रोग्रामिंग भाषाओं का उपयोग कर सकता हूं?
A4: हां, कैपसॉल्वर एक RESTful API प्रदान करता है, जिसका अर्थ है कि यह किसी भी प्रोग्रामिंग भाषा के साथ एपीआई के साथ एकीकृत किया जा सकता है जो HTTP मांग करने में सक्षम है। यह गाइड में पायथन का उपयोग किया गया है, लेकिन आप इन अवधारणाओं को नोड.जेएस, जावा, सी#, गो या अन्य भाषाओं में आसानी से अनुकूलित कर सकते हैं। कैपसॉल्वर API दस्तावेज़ीकरण के लिए भाषा-विशिष्ट उदाहरणों या सामान्य API विवरण के लिए रूपांतरित करें।
Q5: नैतिक वेब ऑटोमेशन के लिए सबसे अच्छी प्रथाएं क्या हैं?
A5: नैतिक वेब ऑटोमेशन वेबसाइट की सेवा की शर्तों के सम्मान करने, सर्वर को अत्यधिक मांग के बिना बोझ न डालने और खतरनाक या हानिकारक गतिविधियों में शामिल न होने पर ध्यान केंद्रित करता है। जहां उचित हो, पारदर्शिता के लिए प्रयास करें और अपने ऑटोमेशन के वेबसाइट के संसाधनों और उपयोगकर्ता अनुभव पर प्रभाव के बारे में सोचें। विनाशकारी गतिविधियों के बजाय अनुसंधान या व्यक्तिगत उपयोग के लिए वैध उपयोग मामलों पर ध्यान केंद्रित करें।