क्रोम क्यों वेबसाइटें ब्लॉक करता है: सुरक्षा विरुद्ध स्वचालन पहुंच समझाए गए

Ethan Collins
Pattern Recognition Specialist
TL;Dr:
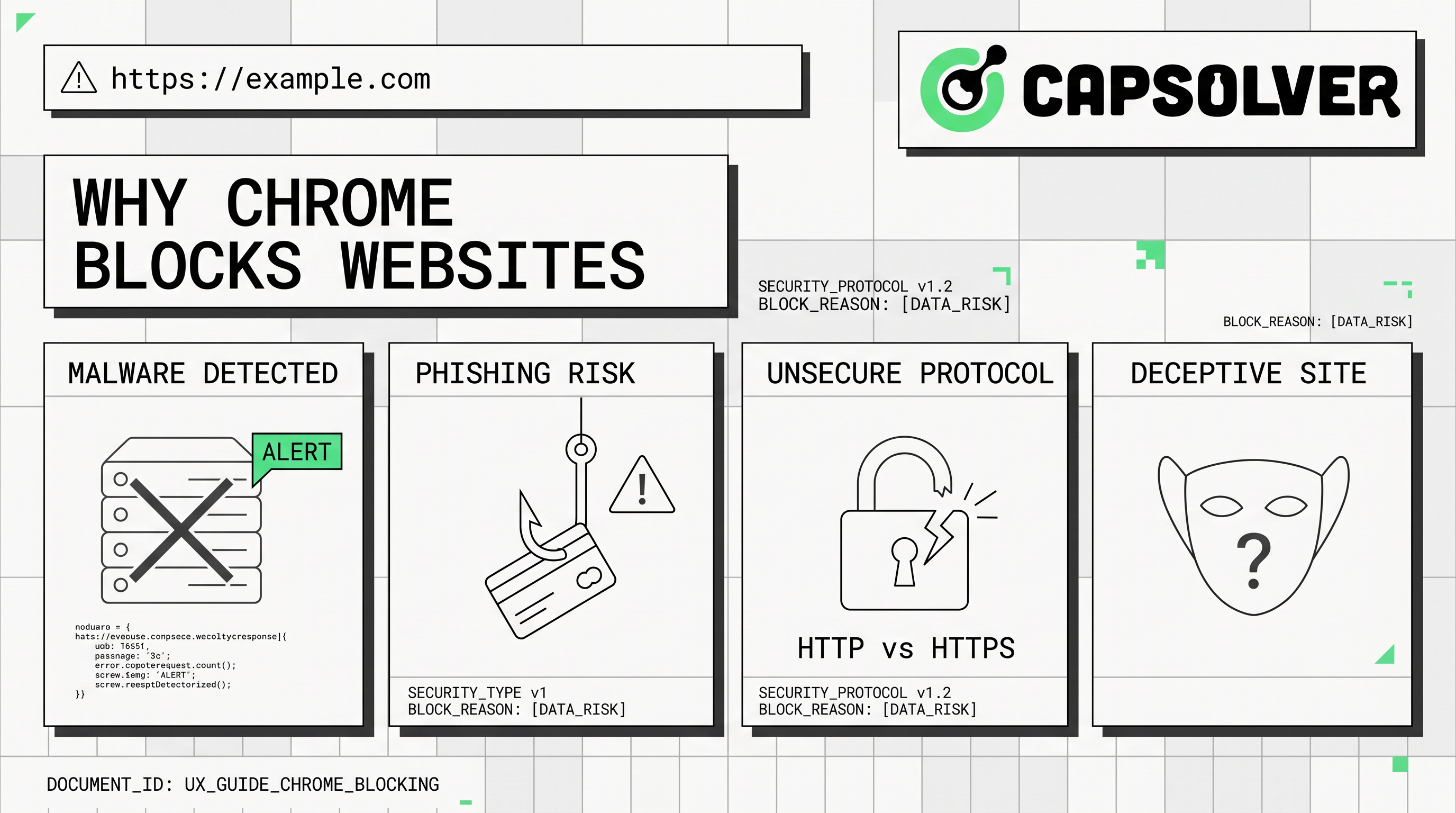
- क्रोम वेबसाइट्स को मुख्य रूप से उपयोगकर्ता सुरक्षा के लिए ब्लॉक करता है, मैलवेयर, फिशिंग और असुरक्षित कनेक्शन के खिलाफ लड़ाई लड़ता है।
- ऑटोमेशन टूल्स अक्सर इन ब्लॉक्स का सामना करते हैं, जिसके कारण
ERR_CONNECTION_REFUSEDया CAPTCHA चुनौतियां जैसी त्रुटियां होती हैं। - लॉजिकल वेब ऑटोमेशन के लिए क्रोम के सुरक्षा विशेषताओं की समझ आवश्यक है।
- प्रॉक्सी और वीपीएन भू-सीमा अवरोधों को दूर करने में मदद कर सकते हैं, लेकिन सभी ब्राउजर-स्तरीय सुरक्षा ब्लॉक्स को नहीं दूर कर सकते हैं।
- CapSolver CAPTCHA चुनौतियों के लिए प्रभावी समाधान प्रदान करता है, जिससे ऑटोमेशन वर्कफ़्लो चलता रहता है।
परिचय
गूगल क्रोम इंटरनेट के सबसे लोकप्रिय प्रवेश द्वार के रूप में कार्य करता है, जो दिन-रात बिलियन उपयोगकर्ताओं को नेविगेट करता है। इस व्यापक उपयोग के कारण क्रोम के उपयोगकर्ता सुरक्षा के लिए एक महत्वपूर्ण जिम्मेदारी होती है। यह वेबसाइट्स को ब्लॉक करता है ताकि उपयोगकर्ताओं को विभिन्न ऑनलाइन खतरों से बचाया जा सके। हालांकि, ये मजबूत सुरक्षा मापदंड लॉजिकल वेब ऑटोमेशन प्रक्रियाओं के लिए बाधाएं बन जाते हैं। इस लेख में क्रोम के आवश्यक ब्राउजर सुरक्षा और बिना रुके ऑटोमेशन एक्सेस की बढ़ती आवश्यकता के बीच संतुलन की खोज की जाएगी। हम क्रोम द्वारा वेबसाइट्स को क्यों ब्लॉक करता है और इन मैकेनिज्म कैसे ऑटोमेटेड कार्यों पर प्रभाव डालते हैं, इसके बारे में जानकारी प्रदान करेंगे, जो सामान्य उपयोगकर्ताओं और विकासकर्ताओं दोनों के लिए उपयोगी होगी।
क्रोम की मुख्य सुरक्षा तकनीकें
क्रोम अपने उपयोगकर्ताओं की सुरक्षा के लिए एक बहु-स्तरीय सुरक्षा दृष्टिकोण का उपयोग करता है। इन मैकेनिज्म नए खतरों के खिलाफ लगातार विकसित हो रहे हैं। इन मुख्य विशेषताओं की समझ क्रोम द्वारा वेबसाइट्स को क्यों ब्लॉक किया जाता है, इसके बारे में स्पष्टता प्रदान करती है।
सुरक्षित ब्राउज़िंग
क्रोम के सुरक्षित ब्राउज़िंग विशेषता इसके सुरक्षा ढांचे का एक मुख्य घटक है। यह उपयोगकर्ताओं को खतरनाक वेबसाइट्स के बारे में सतर्क करता है। इसमें मैलवेयर, फिशिंग और अवांछित सॉफ्टवेयर वाले साइट्स शामिल हैं। जब आपको क्रोम वेबसाइट्स को ब्लॉक करता है के चेतावनी मिलती है, तो सुरक्षित ब्राउज़िंग आमतौर पर काम कर रहा होता है। यह असुरक्षित साइट्स की सूची बनाए रखता है और इन सूचियों के विरुद्ध वेब पेज की जांच करता है गूगल सुरक्षित ब्राउज़िंग। इससे खतरनाक डोमेन पर अकारण जाने से बचा जा सकता है।
SSL/TLS सर्टिफिकेट्स
सुरक्षित सॉकेट लेयर (SSL) और ट्रांसपोर्ट लेयर सुरक्षा (TLS) सर्टिफिकेट्स सुरक्षित संचार के लिए महत्वपूर्ण हैं। क्रोम इन सर्टिफिकेट्स की कठोर जांच करता है ताकि डेटा की अखंडता और गोपनीयता सुनिश्चित की जा सके। SSL सर्टिफिकेट त्रुटि क्रोम एक समस्या के संकेत के रूप में दिखाई देता है। इसका कारण समाप्त हो गई सर्टिफिकेट, गलत सेटिंग या अवैध जारीकर्ता हो सकता है। क्रोम NET::ERR_CERT_AUTHORITY_INVALID चेतावनी प्रदर्शित करता है, जो सुरक्षित न होने वाले साइट्स तक पहुंच को रोकता है। इससे अप्रासंगिक जानकारी के अवरोध से बचा जा सकता है।
मिश्रित सामग्री ब्लॉकिंग
आधुनिक वेबसाइट्स सभी संसाधनों को सुरक्षित HTTPS कनेक्शन के माध्यम से लोड करने चाहिए। मिश्रित सामग्री तब होती है जब एक सुरक्षित HTTPS पृष्ठ असुरक्षित HTTP संसाधनों को लोड करने का प्रयास करता है। क्रोम इस मिश्रित सामग्री को ब्लॉक करता है ताकि विवरण खतरे के खिलाफ सुरक्षित रहे। असुरक्षित संसाधनों का उपयोग एक पूर्ण सुरक्षित पृष्ठ को कमजोर करने के लिए किया जा सकता है। इस ब्लॉकिंग से वेब ब्राउजिंग की सुरक्षा स्थिति में सुधार होता है।
सैंडबॉक्स आर्किटेक्चर
क्रोम एक सैंडबॉक्स आर्किटेक्चर पर काम करता है, जो विभिन्न ब्राउजर प्रक्रियाओं को अलग करता है। इसका मतलब यह है कि यदि एक टैब या एक्सटेंशन हैक हो जाता है, तो यह अन्य टैब या आपके ऑपरेटिंग सिस्टम को प्रभावित नहीं कर सकता है। इस अलगाव नुकसान के संभावित नुकसान को सीमित करता है। यह एक मूल सुरक्षा डिज़ाइन चयन है जो क्रोम के हमलों के खिलाफ प्रतिरोधक क्षमता के आधार के रूप में कार्य करता है।
क्रोम द्वारा वेबसाइट्स को ब्लॉक करने के सामान्य कारण
अपनी मुख्य सुरक्षा विशेषताओं के अलावा, कई विशिष्ट समस्याएं क्रोम को वेबसाइट्स के एक्सेस को ब्लॉक करने के लिए प्रेरित कर सकती हैं। ये समस्याएं सर्वर-स्तरीय समस्याओं से लेकर उपयोगकर्ता-विशिष्ट सेटिंग्स तक फैली हुई हैं। प्रत्येक कारण वेबसाइट्स को क्रोम द्वारा क्यों ब्लॉक किया जाता है, इसके योगदान को समझाता है।
ERR_CONNECTION_REFUSED
ERR_CONNECTION_REFUSED एक सामान्य संदेश है जो एक कनेक्शन विफलता का संकेत देता है। इसका अर्थ है कि आपके ब्राउज़र ने वेबसाइट के सर्वर से कनेक्शन करने का प्रयास किया, लेकिन सर्वर ने कनेक्शन को अस्वीकृत कर दिया। यह तब हो सकता है जब सर्वर ऑफलाइन हो, अत्यधिक भारित हो, या आपके आईपी पते को ब्लॉक करने के लिए सेट किया गया हो। दोनों ओर के नेटवर्क सेटिंग्स या फ़ायरवॉल नियम इस त्रुटि के कारण हो सकते हैं गूगल क्रोम सहायता। ऑटोमेशन के लिए, यह आमतौर पर आईपी बैन या दर सीमा के संकेत के रूप में कार्य करता है।
ERR_NAME_NOT_RESOLVED
जब क्रोम ERR_NAME_NOT_RESOLVED प्रदर्शित करता है, तो यह डीएनएस अनुवाद में समस्या का संकेत देता है। ब्राउज़र वेबसाइट के डोमेन नाम को आईपी पते में अनुवाद नहीं कर सकता है। यह गलत डीएनएस सेटिंग्स, अस्थायी डीएनएस सर्वर बाधा, या यूआरएल में टाइप त्रुटि के कारण हो सकता है। इसका अर्थ है कि क्रोम इंटरनेट पर वेबसाइट को नहीं खोज पा रहा है।
भू-सीमा अवरोध
कुछ वेबसाइट्स भू-स्थिति के आधार पर एक्सेस को सीमित करती हैं। इसे भू-सीमा अवरोध कहा जाता है। सामग्री प्रदाता लाइसेंस समझौतों या क्षेत्रीय वितरण नीतियों के कारण इन ब्लॉक्स को लागू कर सकते हैं। यदि आपके आईपी पता एक सीमित क्षेत्र में है, तो क्रोम एक्सेस को ब्लॉक कर देगा। इसे एक सामान्य चुनौति के रूप में देखा जाता है जब क्रोम के लिए भू-सीमा अवरोध हल करें सामग्री एक्सेस के लिए किया जाता है।
प्रशासक या माता-पिता नियंत्रण
स्कूलों या कार्यस्थलों जैसे प्रबंधित वातावरण में नेटवर्क प्रबंधक आमतौर पर सामग्री फ़िल्टर लगा सकते हैं। माता-पिता नियंत्रण सॉफ्टवेयर भी विशिष्ट वेबसाइट्स को ब्लॉक कर सकता है। इन ब्लॉक्स को ब्राउज़र की सुरक्षा विशेषताओं के बजाय प्रणाली या नेटवर्क स्तर पर लागू किया जाता है। हालांकि, क्रोम अभी भी ब्लॉक किए गए पृष्ठ संदेश प्रदर्शित करेगा। यह नीति के लिए जानबूझकर सीमा है।
क्रोम एक्सटेंशन हस्तक्षेप
कुछ ब्राउज़र एक्सटेंशन अप्रत्यक्ष रूप से वेबसाइट्स को ब्लॉक कर सकते हैं। एड ब्लॉकर, गोपनीयता टूल्स या सुरक्षा एक्सटेंशन गैर-खतरनाक सामग्री को खतरनाक मान सकते हैं। वे पृष्ठों को सही तरह से लोड करने से रोक सकते हैं या विशिष्ट तत्वों को ब्लॉक कर सकते हैं। यदि आप अप्रत्याशित ब्लॉकिंग का सामना कर रहे हैं, तो एक्सटेंशन को एक-एक करके अक्षम करके दोषी को खोजने में मदद मिल सकती है।
फ़ायरवॉल ब्लॉकिंग
आपके कंप्यूटर के फ़ायरवॉल या एंटीवायरस सॉफ्टवेयर के कारण क्रोम वेबसाइट्स तक पहुंच नहीं कर सकता है। अत्यधिक सख्त फ़ायरवॉल नियम वैध आउटगोइंग कनेक्शन को ब्लॉक कर सकते हैं। इससे ERR_CONNECTION_REFUSED या अन्य कनेक्शन त्रुटियां हो सकती हैं। अपनी सुरक्षा सॉफ्टवेयर में क्रोम को व्हाइटलिस्ट करना अनिवार्य है ताकि ब्राउजिंग अवरुद्ध होने से बचा जा सके।
ऑटोमेशन के लिए चुनौती
क्रोम की मजबूत सुरक्षा, मानव उपयोगकर्ताओं के लिए लाभदायक है, लेकिन वेब ऑटोमेशन के लिए विशिष्ट चुनौतियां प्रदान करती है। ऑटोमेशन स्क्रिप्ट आमतौर पर मानव व्यवहार की नकल करते हैं लेकिन अक्सर आशंकित चिह्न के रूप में चिह्नित किए जाते हैं। इसके परिणामस्वरूप, ऑटोमेशन टूल्स के लिए क्रोम वेबसाइट्स को ब्लॉक करता है।
वेब स्क्रैपिंग, ऑटोमेटेड टेस्टिंग और डेटा संग्रह सामान्य ऑटोमेशन कार्य हैं। इन गतिविधियों के लिए वेब संसाधनों तक निरंतर एक्सेस की आवश्यकता होती है। हालांकि, वेबसाइट्स जटिल बॉट डिटेक्शन तकनीकों का उपयोग करती हैं। ये प्रणालियां मानव उपयोगकर्ताओं और ऑटोमेशन स्क्रिप्ट के बीच अंतर करने के लिए डिज़ाइन की गई हैं। जब ऑटोमेशन की पहचान हो जाती है, तो वेबसाइट्स एक्सेस को ब्लॉक कर सकती हैं, CAPTCHA प्रदान कर सकती हैं या मात्रा सीमा लगा सकती हैं। इससे ऑटोमेशन विकासकर्ता और वेबसाइट सुरक्षा के बीच एक लगातार बर्बर खेल बन जाता है।
उदाहरण के लिए, एक ऑटोमेशन स्क्रिप्ट यदि बहुत तेजी से बहुत सारे प्रश्न पूछता है, तो ERR_CONNECTION_REFUSED त्रुटि उत्पन्न कर सकता है। यह सर्वर-स्तरीय रक्षा है जो संभावित डिनाई ऑफ सर्विस हमलों के खिलाफ है। इसी तरह, SSL सर्टिफिकेट त्रुटि क्रोम ऑटोमेशन को बाधित कर सकता है यदि स्क्रिप्ट सही तरह से सीएलएस सत्यापन के साथ सेट नहीं है। वैध ऑटोमेशन का लक्ष्य असावधानी से और सम्मान से काम करना है, इन सुरक्षा मापदंडों के द्वारा उत्पन्न ट्रिगर से बचना।
वैध ऑटोमेशन एक्सेस के लिए रणनीतियां
वैध ऑटोमेशन के लिए क्रोम के ब्लॉकिंग मैकेनिज्म को पार करने के लिए रणनीतिक दृष्टिकोण की आवश्यकता होती है। इन विधियां मानव ब्राउज़िंग पैटर्न की नकल करने और सामान्य डिटेक्शन तकनीकों के समाधान के लिए डिज़ाइन की गई हैं। क्रोम के लिए वेबसाइट्स अनब्लॉक करें के लिए प्रभावी रणनीतियां लगातार ऑटोमेशन के लिए महत्वपूर्ण हैं।
प्रॉक्सी और वीपीएन का उपयोग करें
प्रॉक्सी और वीपीएन नेटवर्क-स्तरीय सीमा के प्रबंधन के लिए आवश्यक उपकरण हैं। एक वीपीएन आपके इंटरनेट ट्रैफिक को एनक्रिप्ट करता है और एक अलग स्थान पर सर्वर के माध्यम से राउट करता है। इससे क्रोम के लिए भू-सीमा अवरोध हल करें के माध्यम से आपको अन्य देश में ब्राउज़िंग करने की तरह लगता है। प्रॉक्सी एक मध्यस्थ के रूप में कार्य करते हैं, आपके मूल आईपी पते को छिपाते हैं। प्रॉक्सी वीपीएन क्रोम के बीच चयन विशिष्ट ऑटोमेशन आवश्यकताओं पर निर्भर करता है। प्रॉक्सी आमतौर पर वेबसाइट्स स्क्रैपिंग के लिए पसंद किए जाते हैं क्योंकि वे लचीलेपन और आईपी पते के घूर्णन की क्षमता के कारण होते हैं। हालांकि, वे वीपीएन की तरह ट्रैफिक को एनक्रिप्ट नहीं करते क्लाउडफ़्लेर शिक्षा।
SSL त्रुटि का प्रबंधन करें
ऑटोमेशन के लिए, SSL सर्टिफिकेट त्रुटि क्रोम समस्यापूर्ण हो सकता है। स्क्रिप्ट को एसएलएस सर्टिफिकेट की सही तरह से सत्यापन करने के लिए सेट किया जाना चाहिए या नियंत्रित वातावरण में वैधता के समाधान के लिए। उत्पादन वातावरण में SSL त्रुटि अनदेखा करना सुरक्षा अनुपालन के कारण सिफारिश नहीं की जाती है। अपने ऑटोमेशन वातावरण में अपडेट रूट सर्टिफिकेट होने से बहुत सी NET::ERR_CERT_AUTHORITY_INVALID समस्याओं को रोका जा सकता है।
ब्राउज़र फिंगरप्रिंट का प्रबंधन करें
वेबसाइट्स ब्राउज़र फिंगरप्रिंट का उपयोग उपयोगकर्ताओं की पहचान और ट्रैकिंग के लिए करती हैं, जिसमें ऑटोमेशन बॉट भी शामिल हैं। इसमें आपके ब्राउज़र, ऑपरेटिंग सिस्टम और उपकरण के बारे में डेटा का एकत्रीकरण शामिल है। ऑटोमेशन टूल्स को अपने ब्राउज़र फिंगरप्रिंट के प्रबंधन के तकनीकों का उपयोग करना आवश्यक है। इसमें उपयोगकर्ता एजेंट के घूर्णन, कुकीज़ का प्रबंधन और वास्तविक माउस गतियों और कीबोर्ड इनपुट के नकल करना शामिल है। अपर्याप्त फिंगरप्रिंट प्रबंधन के बिना, ऑटोमेशन स्क्रिप्ट आसानी से पहचाने जाते हैं और ब्लॉक कर दिए जाते हैं।
CAPTCHA चुनौतियों के लिए CapSolver
वेब ऑटोमेशन में सबसे आम बाधा CAPTCHA चुनौतियां हैं। इन परीक्षणों का उद्देश्य मानव उपयोगकर्ताओं और बॉट के बीच अंतर करना है। जब क्रोम वेबसाइट्स को ब्लॉक करता है, या जब वेबसाइट की बॉट डिटेक्शन ट्रिगर होती है, तो CAPTCHA आमतौर पर दिखाई देते हैं। इस स्थिति में CapSolver अमूल्य हो जाता है। CapSolver ऑटोमेशन के लिए एक ऑटोमेटेड CAPTCHA समाधान प्रदान करता है, जिससे आपके ऑटोमेशन स्क्रिप्ट बिना किसी रुकावट के आगे बढ़ सकते हैं। यह विभिन्न CAPTCHA प्रकारों, जैसे reCAPTCHA v2, reCAPTCHA v3, Cloudflare Turnstile आदि का समर्थन करता है। इससे आपके ऑटोमेशन को इन सुरक्षा चेकपॉइंट्स के माध्यम से दक्षता से गुजरने में सक्षम बनाया जाता है। CAPTCHA पर ऑटोमेशन के विफल होने के कारणों के बारे में अधिक जानकारी के लिए CAPTCHA पर ऑटोमेशन के बारे में क्यों बार-बार विफल होता है देखें।
यहां reCAPTCHA v2 के लिए एक Python उदाहरण है जो aiohttp और CapSolver के साथ काम करता है:
python
import aiohttp
import json
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY"
PAGE_URL = "https://example.com/recaptcha_page"
SITE_KEY = "YOUR_RECAPTCHA_SITE_KEY"
async def create_capsolver_task(api_key, website_url, website_key):
url = "https://api.capsolver.com/createTask"
headers = {"Content-Type": "application/json"}
payload = {
"clientKey": api_key,
"task": {
"type": "ReCaptchaV2TaskProxyless",
"websiteURL": website_url,
"websiteKey": website_key
}
}
async with aiohttp.ClientSession() as session:
async with session.post(url, headers=headers, data=json.dumps(payload)) as response:
return await response.json()
async def get_capsolver_result(api_key, task_id):
url = "https://api.capsolver.com/getTaskResult"
headers = {"Content-Type": "application/json"}
payload = {
"clientKey": api_key,
"taskId": task_id
}
async with aiohttp.ClientSession() as session:
async with session.post(url, headers=headers, data=json.dumps(payload)) as response:
return await response.json()
async def solve_recaptcha_v2():
# Create task
create_task_response = await create_capsolver_task(CAPSOLVER_API_KEY, PAGE_URL, SITE_KEY)
if create_task_response.get("errorId") != 0:
print(f"Error creating task: {create_task_response.get('errorDescription')}")
return None
task_id = create_task_response.get("taskId")
print(f"Task created with ID: {task_id}")
# Poll for result
while True:
get_result_response = await get_capsolver_result(CAPSOLVER_API_KEY, task_id)
if get_result_response.get("errorId") != 0:
print(f"Error getting result: {get_result_response.get('errorDescription')}")
return None
status = get_result_response.get("status")
if status == "ready":
g_recaptcha_response = get_result_response["solution"]["gRecaptchaResponse"]
print("reCAPTCHA solved successfully!")
return g_recaptcha_response
elif status == "processing":
print("Solving reCAPTCHA... waiting...")
await asyncio.sleep(5) # Wait for 5 seconds before polling again
else:
print(f"Unknown status: {status}")
return None
async def main():
# Example usage: solve reCAPTCHA and then submit to a page
recaptcha_token = await solve_recaptcha_v2()
if recaptcha_token:
print(f"Received reCAPTCHA token: {recaptcha_token}")
# Now you can use this token to submit a form or access the protected page
# For example:
# async with aiohttp.ClientSession() as session:
# data = {'g-recaptcha-response': recaptcha_token, 'other_form_field': 'value'}
# async with session.post(PAGE_URL, data=data) as response:
# print(await response.text())
if __name__ == "__main__":
import asyncio
asyncio.run(main())इस कोड टुकड़ा के माध्यम से आप CapSolver को अपने Python ऑटोमेशन वर्कफ़्लो में एकीकृत कर सकते हैं ताकि reCAPTCHA v2 चुनौतियों का प्रबंधन किया जा सके। अधिक जटिल स्क्रैपिंग तकनीकों के लिए, n8n, CapSolver और OpenClaw के साथ CAPTCHA सुरक्षित साइट्स को स्क्रैप कैसे करें जैसे संसाधनों की खोज करें।
CapSolver बोनस कोड के साथ लाभ उठाएं
अपने ऑटोमेशन बजट को तत्काल बढ़ाएं!
CapSolver खाता में जमा करते समय बोनस कोड CAP26 का उपयोग करके प्रत्येक भुगतान पर 5% बोनस प्राप्त करें — कोई सीमा नहीं।
अपने CapSolver डैशबोर्ड में अभी बोनस कोड का उपयोग करें
ब्राउजर सुरक्षा और ऑटोमेशन एक्सेस की तुलना सारांश
| विशेषता/पहलू | ब्राउजर सुरक्षा परिप्रेक्ष्य | ऑटोमेशन एक्सेस परिप्रेक्ष्य |
|---|---|---|
| मुख्य लक्ष्य | मानव उपयोगकर्ताओं को खतरों (मैलवेयर, फिशिंग, डेटा ब्रेच) से सुरक्षित रखें। | वेब डेटा/कार्यक्षमता के प्रभावी और विश्वसनीय रूप से पहुंच। |
| ब्लॉकिंग मैकेनिज्म | सुरक्षित ब्राउजिंग, SSL प्रमाणीकरण, मिश्रित सामग्री, सैंडबॉक्स। | IP बैन, दर सीमा, CAPTCHA, ब्राउजर फिंगरप्रिंट डिटेक्शन। |
| आम त्रुटियां | SSL सर्टिफिकेट त्रुटि क्रोम, ERR_CONNECTION_REFUSED, NET::ERR_CERT_AUTHORITY_INVALID। |
ERR_CONNECTION_REFUSED, CAPTCHA प्रॉम्प्ट, HTTP 403 अनुमति नहीं। |
| भू-सीमा बाधाएं | लाइसेंसिंग/क्षेत्रीय नीतियों के लिए लागू। | प्रॉक्सी/वीपीएन के साथ भू-सीमा बाधाओं को हल करें (जियो बाधाओं को हल करना क्रोम)। |
| स्वचालन प्रभाव | वैध स्वचालन को अवैध गतिविधि के रूप में गलती से पहचाना जा सकता है। | मानव व्यवहार के अनुकरण के लिए जटिल तकनीकों की आवश्यकता होती है। |
| स्वचालन के लिए समाधान | सीधे लागू नहीं होता; सुरक्षा मानव अंतरक्रिया के लिए होती है। | प्रॉक्सी, वीपीएन, यूजर-एजेंट घूर्णन, CAPTCHA हल करने वाली सेवाएं (उदाहरण: CapSolver)। |
निष्कर्ष
क्रोम के उपयोगकर्ता सुरक्षा के प्रति प्रतिबद्धता स्पष्ट है। सुरक्षित ब्राउजिंग और कठोर SSL प्रमाणीकरण जैसे विशेषताएं सुरक्षित ऑनलाइन अनुभव के लिए महत्वपूर्ण हैं। हालांकि, ये ही सुरक्षा वेब स्वचालन के लिए गंभीर चुनौतियां पैदा करती हैं। स्वचालन में लगे विकासकर्ता और व्यवसायों को समझना आवश्यक है कि क्रोम वेबसाइटों को क्यों ब्लॉक करता है ताकि इन बाधाओं को पार करने में सक्षम हो सकें। प्रॉक्सी का उपयोग करना, ब्राउजर फिंगरप्रिंट प्रबंधित करना और CapSolver जैसी CAPTCHA हल करने वाली सेवाओं के साथ एकीकरण अनुकूल अनुकूलन पहुंच बनाए रखने के लिए आवश्यक है। वेबसाइट की नीतियों के सम्मान और ईथिक स्वचालन अभ्यासों के साथ, ब्राउजर सुरक्षा और ऑटोमेटेड वेब कार्यों के मांगों के बीच संतुलन संभव है। आज ही CapSolver का उपयोग करें ताकि आप अपने स्वचालन वर्कफ़्लो को बेहतर बना सकें और CAPTCHA चुनौतियों को बिना किसी कठिनाई के समाप्त कर सकें।
अक्सर पूछे जाने वाले प्रश्न
ERR_CONNECTION_REFUSED क्या है?
ERR_CONNECTION_REFUSED का अर्थ है कि आपके ब्राउजर को वेबसाइट के सर्वर से जुड़ने में विफलता हुई। इसका अक्सर अर्थ होता है कि सर्वर बंद है, आपकी मांग को अस्वीकार कर रहा है, या आपके पास नेटवर्क समस्या है। यह तब एक सामान्य त्रुटि होती है जब क्रोम वेबसाइट को ब्लॉक करता है सर्वर-साइड समस्याओं के कारण।
क्रोम सुरक्षित ब्राउजिंग कैसे काम करता है?
क्रोम सुरक्षित ब्राउजिंग आपकी सुरक्षा के लिए ज्ञात अवैध वेबसाइटों (मैलवेयर, फिशिंग) की सूचियां बनाए रखता है। जब आप किसी साइट पर जाने की कोशिश करते हैं, तो क्रोम इसे इन सूचियों के साथ जांचता है। यदि कोई मेल खाता है, तो यह आपको खतरनाक पृष्ठ तक पहुंचने से रोकने के लिए एक चेतावनी दिखाता है। यह क्रोम सुरक्षित ब्राउजिंग के लिए एक महत्वपूर्ण विशेषता है।
क्या वीपीएन सभी वेबसाइटों को अनब्लॉक कर सकता है?
एक वीपीएन क्रोम वेबसाइट को अनब्लॉक कर सकता है जो भू-सीमा बाधाओं या स्थानीय नेटवर्क फ़िल्टर के कारण ब्लॉक कर दिए गए हैं। हालांकि, यह सभी प्रकार के ब्लॉक को हल नहीं कर सकता है। उदाहरण के लिए, यदि एक वेबसाइट में मजबूत बॉट डिटेक्शन है या क्रोम किसी साइट को गंभीर मैलवेयर के कारण ब्लॉक करता है, तो वीपीएन अकेले पर्याप्त नहीं हो सकता है। यह जियो बाधाओं को हल करना क्रोम के लिए प्रभावी है लेकिन सभी सुरक्षा ब्लॉक के लिए नहीं।
मुझे SSL सर्टिफिकेट त्रुटि क्रोम क्यों मिलती है?
SSL सर्टिफिकेट त्रुटि क्रोम का अर्थ है कि एक वेबसाइट के सुरक्षा सर्टिफिकेट में कोई समस्या है। इसका मतलब हो सकता है कि सर्टिफिकेट समाप्त हो गया है, एक भरोसेमंद प्राधिकरण द्वारा जारी नहीं किया गया है, या गलत तरीके से सेट किया गया है। क्रोम आपके डेटा की सुरक्षा के लिए एक असुरक्षित कनेक्शन पर पहुंच को ब्लॉक करता है। हमेशा अपने सिस्टम की तारीख और समय सुनिश्चित करें, क्योंकि इस त्रुटि के कारण हो सकता है।
स्वचालन टूल कैसे क्रोम ब्लॉकिंग का सामना कर सकते हैं?
स्वचालन टूल क्रोम ब्लॉकिंग का सामना करने के लिए प्रॉक्सी या वीपीएन का उपयोग कर सकते हैं जो आईपी रोटेशन और भू-अनब्लॉकिंग के लिए होता है। उन्हें ब्राउजर फिंगरप्रिंट प्रबंधित करना चाहिए ताकि वे अधिक मानव जैसे लगें। CAPTCHA चुनौतियों के लिए, विशेष रूप से हल करने वाली सेवाओं के साथ एकीकरण अत्यधिक प्रभावी होता है। इन रणनीतियों के माध्यम से क्रोम वेबसाइट को अनब्लॉक कर सकता है वैध स्वचालित कार्यों के लिए।