ReCAPTCHA ईकॉमर्स स्क्रैपिंग में: एक अनुपालन-पहला गाइड

Rajinder Singh
Deep Learning Researcher
TL;DR
- ReCAPTCHA ईकॉमर्स साइट्स पर अधिक विश्वास जांच की आवश्यकता होने पर दिखाई देता है।
- ReCAPTCHA को एक प्लेसमेंट संकेत के रूप में देखें, न कि केवल एक पहेली के रूप में।
- पहले अनुमति, robots.txt, शर्तें, और डेटा स्कोप की जांच करें।
- गति और स्थिर सत्र के माध्यम से अवांछित चुनौतियों को कम करें।
- जहां भी आधिकारिक API या फीड मौजूद हो, उपयोग करें।
- CapSolver केवल वैध ऑटोमेशन और अनुमति डेटा कार्य के लिए उपयोग करें।
- प्रत्येक क्रॉलर के लिए लॉग, दर सीमा, और एग्लेशन नियमों को बनाए रखें।
परिचय
ईकॉमर्स स्क्रैपिंग में ReCAPTCHA को सुसंगतता-पहले प्रक्रिया के साथ निपटाया जाना चाहिए। सही उत्तर अधिक आक्रामक ड्रॉलिंग नहीं है। यह अनुमति के सम्मान, शोर ट्रैफिक को कम करना और अनुमति के साथ एक दस्तावेजीकृत हल करने वाला चरण का उपयोग करना है। यह गाइड डेटा इंजीनियर, SEO टीम, मूल्य विश्लेषक और विकास टीम के लिए है जो सार्वजनिक ईकॉमर्स डेटा को जिम्मेदारी से एकत्र करते हैं। यह बताता है कि ReCAPTCHA क्यों दिखाई देता है, जब धीमा होना चाहिए और जब CapSolver एक वैध प्रक्रिया के लिए फिट बैठता है।
क्यों ईकॉमर्स क्रॉलर ReCAPTCHA के साथ मिलते हैं
ReCAPTCHA इसलिए दिखाई देता है क्योंकि ईकॉमर्स साइट्स मूल्यवान ग्राहक और व्यावसायिक प्रवाहों की रक्षा करती हैं। उत्पाद पृष्ठ, खोज पृष्ठ, कार्ट और लॉगिन सभी वाणिज्यिक जोखिम लाते हैं। गूगल ने ReCAPTCHA को एक सेवा के रूप में वर्णित किया है जो उन्नत जोखिम विश्लेषण के माध्यम से मशीनों के बजाय मनुष्यों को अलग करके वेबसाइट्स को स्पैम और दुरुपयोग से सुरक्षित करती है गूगल ReCAPTCHA दस्तावेजीकरण।
ईकॉमर्स टीमें ReCAPTCHA जोड़ती हैं क्योंकि स्वचालित ट्रैफिक अब सामान्य हो गया है। थेल्स और इम्परवा ने 2024 में स्वचालित ट्रैफिक 51% वेब ट्रैफिक के बराबर बताया। उन्होंने यह भी रिपोर्ट किया कि हानिकारक स्वचालित गतिविधि इंटरनेट ट्रैफिक के 37% के बराबर रही, जबकि API-निर्देशित हमले उन्नत बॉट ट्रैफिक के 44% तक पहुंच गए 2025 इम्परवा बैड बॉट रिपोर्ट। इस संदर्भ ने यह समझाया कि साइटें असामान्य ड्रॉलिंग पैटर्न के लिए तेजी से चुनौतियां देती हैं।
ReCAPTCHA भुगतान और खाता प्रवाह के पास भी सामान्य होता है। गूगल क्लाउड कहता है कि ReCAPTCHA के लिए ट्रांजैक्शन डिफेंस भुगतान लेनदेन के खिलाफ कार्डिंग हमलों और धोखाधड़ी लेनदेन की रक्षा करता है गूगल क्लाउड ट्रांजैक्शन डिफेंस। एक क्रॉलर जो कार्ट, चेकआउट या खाता पृष्ठों को छूता है, सार्वजनिक उत्पाद निगरानी के मुकाबले सख्त जांच का सामना करता है।
पहला नियम: डेटा की अनुमति की पुष्टि करें
सुसंगतता तकनीकी बदलाव से पहले आती है। एक क्रॉलर केवल सार्वजनिक, अनुमति और आवश्यक डेटा का संग्रह करे। इसे लॉगिन-केवल पृष्ठों, निजी ग्राहक डेटा, चेकआउट चरणों और स्पष्ट अनुमति के बिना सीमित क्षेत्रों से बचना चाहिए।
रोबोट्स अपवर्जन प्रोटोकॉल भी महत्वपूर्ण है। RFC 9309 कहता है कि robots.txt सेवा मालिकों के लिए एक तरीका प्रदान करता है कि क्रॉलर कैसे URI अंतरिक्ष के लिए पहुंच कर सकते हैं, और क्रॉलरों को उन नियमों का अनुसरण करने के लिए कहा जाता है RFC 9309 रोबोट्स अपवर्जन प्रोटोकॉल। robots.txt एकमात्र कानूनी परीक्षण नहीं है। हालांकि, जिम्मेदार क्रॉलर चलाने से पहले इसका विश्लेषण करना चाहिए।
ReCAPTCHA के साथ निपटने से पहले, चार आइटमों का दस्तावेजीकरण करें। व्यवसाय उद्देश्य, स्रोत पृष्ठ, डेटा क्षेत्र, अनुमति पथ, शर्तें, अनुरोध सीमा, समानांतरता, और बनाए रखने की अवधि को परिभाषित करें। इससे ReCAPTCHA के साथ निपटना एक नियंत्रित डेटा प्रक्रिया बन जाता है।
CapSolver के ReCAPTCHA क्या है पर गाइड स्थानीय निर्णय लेने वालों की समझ में सुधार कर सकता है।
ReCAPTCHA के प्रकार का निदान करें
कोड बदलाव से पहले निदान होना चाहिए। ReCAPTCHA v2 आमतौर पर एक चेकबॉक्स या दृश्य चुनौति के रूप में दिखाई देता है। ReCAPTCHA v3 आमतौर पर उपयोगकर्ता अंतरक्रिया के बिना एक स्कोर लौटाता है, इसलिए पृष्ठ खराब हो सकता है, एक कार्य को ब्लॉक कर सकता है, या बाद में एक मजबूत जांच के लिए कह सकता है। गूगल नोट करता है कि ReCAPTCHA v3 एक स्कोर लौटाता है ताकि साइट मालिक उपयोगकर्ताओं के बिना एक कार्रवाई चुन सकें गूगल ReCAPTCHA v3 समीक्षा।
| स्थिति | संभावित अर्थ | सुझावित प्रतिक्रिया |
|---|---|---|
| कई तेज अनुरोध के बाद चुनौति दिखाई देती है | ट्रैफिक पैटर्न असामान्य लगता है | समानांतरता कम करें और गति जोड़ें |
| लॉगिन या चेकआउट पर ही चुनौति दिखाई देती है | पृष्ठ उच्च जोखिम वाला है | स्पष्ट अनुमति के बिना बंद कर दें |
| सार्वजनिक उत्पाद पृष्ठ पर चुनौति दिखाई देती है | सत्र या अनुरोध पैटर्न की समीक्षा करें | कुकीज़ स्थिर रखें और बर्स्ट कम करें |
| v3 स्कोर खाली या खराब पृष्ठ लौटाता है | विश्वास स्कोर कम है | ब्राउज़र संदर्भ और अनुरोध गति की समीक्षा करें |
| पुनर्निर्देशन के बाद चुनौति दिखाई देती है | प्रवाह स्थिति असंगत है | सत्र और पृष्ठ क्रम बरकरार रखें |
इस निदान ने लागत को भी नियंत्रित किया। एक शांत क्रॉलर आमतौर पर कम चुनौतियों को ट्रिगर करता है और साफ ईकॉमर्स डेटा लौटाता है।
तुलना सारांश
एक उपयोगी ईकॉमर्स क्रॉलर सबसे कम आक्रामक विकल्प से शुरू होता है। नीचे दी गई तालिका सामान्य विकल्पों की तुलना करती है।
| दृष्टिकोण | सबसे अच्छा उपयोग केस | सुसंगतता टिप्पणियाँ | ऑपरेशनल जोखिम | लागत प्रोफाइल |
|---|---|---|---|---|
| आधिकारिक API या व्यापारी फीड | साझेदार डेटा एक्सेस | उपलब्ध होने पर सबसे अच्छा विकल्प | कम | पूर्वानुमान योग्य |
| समय के साथ सार्वजनिक पृष्ठ क्रॉलिंग | सार्वजनिक उत्पाद और मूल्य निगरानी | robots.txt और शर्तों का सम्मान करें | मध्यम | कम से लेकर मध्यम |
| ब्राउज़र ऑटोमेशन | जावास्क्रिप्ट-भारित उत्पाद पृष्ठ | सीमित प्रवाहों से बचें | मध्यम | मध्यम |
| मानव समीक्षा अनुरोध | दुर्लभ उच्च-मूल्य जांच | मजबूत लेखा परीक्षा ट्रेल | कम | अधिक श्रम लागत |
| CapSolver एकीकरण | अनुमति ऑटोमेशन जो ReCAPTCHA के साथ मिलता है | कानूनी, उपयोग के लिए केवल उपयोग करें | मध्यम | उपयोग-आधारित |
तालिका एक व्यावहारिक बिंदु दिखाती है। ReCAPTCHA को एक क्रॉलर में एक अपवाद पथ के रूप में रखा जाना चाहिए जो नियमों और सीमाओं का सम्मान करता है।
एक स्पष्ट ईकॉमर्स स्क्रैपिंग वर्कफ्लो बनाएं
एक स्पष्ट वर्कफ्लो अवांछित ReCAPTCHA घटनाओं को कम करता है। पृष्ठ चयन से शुरू करें। केवल सार्वजनिक और अनुमति वाले श्रेणी या उत्पाद पृष्ठ क्रॉल करें। व्यवसाय के स्वामी और अनुमति के बिना आइटम जोड़ने, फॉर्म भरने, या खाता पृष्ठ खोलने के बाहर रहें।
अगला, ट्रैफिक के आकार को नियंत्रित करें। निर्धारित समानांतरता, बैकऑफ नियमों और स्थिर योजना का उपयोग करें। ईकॉमर्स साइट्स बिक्री, लॉन्च और छुट्टी के बूम के दौरान संवेदनशील होती हैं। इन खंडों का सम्मान करने वाला क्रॉलर ऑपरेशनल तनाव उत्पन्न करने की संभावना कम होती है।
सत्र प्रबंधन भी महत्वपूर्ण है। छोटे क्रॉल के दौरान कुकीज़ स्थिर रखें। एक सत्र में असंबंधित पृष्ठ प्रवाह को मिश्रित न करें। एक उत्पाद खोज पथ अचानक चेकआउट पृष्ठों के अनुरोध के साथ नहीं होना चाहिए। इस पैटर्न के कारण ReCAPTCHA दिखाई दे सकता है।
चुनौति दर, खाली पृष्ठ, HTTP कोड, मूल्य पार्सिंग विफलताएं और दोहराए गए लेखों की ट्रैकिंग करें। बढ़ती ReCAPTCHA दर एक शुरुआती चेतावनी है।
अगर आपकी टीम डायरेक्ट क्रॉलिंग और आधिकारिक डेटा एक्सेस के बीच चयन कर रही है, तो वेब स्क्रैपिंग और API के बीच अंतर पर इस CapSolver लेख का उपयोग आंतरिक चर्चा लिंक के रूप में कर सकते हैं।
CapSolver कहां फिट बैठता है
CapSolver तब फिट बैठता है जब एक वैध ऑटोमेशन प्रक्रिया के बाद सुसंगतता जांच के बाद ReCAPTCHA मिलता है। यह SEO ऑडिट, विज्ञापन सत्यापन और निर्दोष क्रॉलर के लिए उपयोगी है जब लक्ष्य डेटा अनुमति होता है। CapSolver की स्वयं की स्थिति बताती है कि अवैध, धोखाधड़ी या दुरुपयोग की गतिविधि निषेध है, और यह SEO, विज्ञापन सत्यापन, निर्दोष क्रॉलर और व्यावसायिक विकास अवसरों के रूप में उद्देश्य उपयोग के रूप में सूचीबद्ध करता है CapSolver सुसंगतता बयान।
इस स्थिति महत्वपूर्ण है। CapSolver एकीकरण कभी-भी निजी खातों, भुगतान चरणों, सीमित सामग्री या स्पष्ट रूप से अनुमति नहीं दिए गए डेटा के लक्ष्य के रूप में नहीं होना चाहिए।
CapSolver विशेष रूप से तब महत्वपूर्ण है जब आपका क्रॉलर पहले से ही सम्मान करता है लेकिन अनुमति वाले सार्वजनिक पृष्ठों पर ReCAPTCHA के साथ मिलता है। इसके साथ आपको प्रत्येक चुनौति के लिए हस्तक्षेप किए बिना स्थिर वर्कफ्लो बनाए रखने में मदद मिल सकती है। एक फोकस ईकॉमर्स स्थिति के लिए, ईकॉमर्स वेबसाइट्स के दौरान CAPTCHA को हल करने के बारे में CapSolver के गाइड देखें।
आधिकारिक CapSolver कोड संदर्भ
नीचे दिए गए कोड ReCAPTCHA v2 के लिए CapSolver आधिकारिक दस्तावेजीकरण के अनुसार है। वर्तमान दस्तावेज के बिना टास्क प्रकार या पैरामीटर नहीं बदलें। केवल अनुमति वाले वर्कफ्लो में इसका उपयोग करें और एक वैध API कुंजी के साथ।
python
# pip install requests
import requests
import time
# TODO: set your config
api_key = "YOUR_API_KEY" # your api key of capsolver
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # site key of your target site
site_url = "https://www.google.com/recaptcha/api2/demo" # page url of your target site
def capsolver():
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print("Failed to create task:", res.text)
return
print(f"Got taskId: {task_id} / Getting result...")
while True:
time.sleep(1) # delay
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
return resp.get("solution", {}).get('gRecaptchaResponse')
if status == "failed" or resp.get("errorId"):
print("Solve failed! response:", res.text)
return
token = capsolver()
print(token)आधिकारिक CapSolver दस्तावेजीकरण कहता है कि createTask के साथ टास्क बनाएं और getTaskResult के साथ परिणाम प्राप्त करें। यह भी स्पष्ट करता है कि websiteURL और websiteKey जैसे क्षेत्र टास्क के लिए आवश्यक हैं। अधिक कार्यान्वयन संदर्भ के लिए, पायथन का उपयोग करके वेब स्क्रैपिंग में ReCAPTCHA हल करने के बारे में CapSolver के आधिकारिक शैली गाइड पढ़ें।
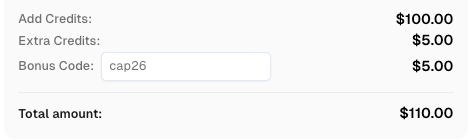
CapSolver बोनस कोड के साथ लाभ उठाएं
अपने स्वचालन बजट को तत्काल बढ़ाएं!
अपने CapSolver खाते में जमा करते समय बोनस कोड CAP26 का उपयोग करें ताकि प्रत्येक भुगतान पर 5% बोनस मिले — कोई सीमा नहीं।
अपने CapSolver डैशबोर्ड में अभी इसे रिडीम करें
उत्पादन के लिए व्यावहारिक नियंत्रण
उत्पादन ईकॉमर्स स्क्रैपिंग के लिए ऐसे नियंत्रण की आवश्यकता होती है जिन्हें अंग्रेजी नहीं बोलने वाले लोग जांच सकते हैं। डेप्लॉयमेंट से पहले एक क्रॉलर नीति बनाएं। नीति में डेटा मालिक, अनुमति डोमेन, अनुमति पथ, अधिकतम समानांतरता, अधिकतम दैनिक अनुरोध, बनाए रखने की अवधि और एग्लेशन संपर्क का उल्लेख करें।
ReCAPTCHA मुठभेड़ दर के रूप में एक महत्वपूर्ण मापदंड का उपयोग करें। यदि दर एक परिभाषित सीमा से ऊपर बढ़ जाती है, तो क्रॉल गति कम करें या रोक दें। यदि सीमित प्रवाह पर चुनौतियां दिखाई देती हैं, तो कार्य बंद कर दें। यदि लक्ष्य अपने robots.txt या शर्तों को बदल देता है, तो आगे बढ़ने से पहले क्रॉलर की समीक्षा करें।
डेटा को संकीर्ण रखें। मूल्य, उपलब्धता, शीर्षक, छवि URL, और सार्वजनिक समीक्षा संख्या कुछ व्यावसायिक मामलों के लिए वैध हो सकते हैं। ग्राहक नाम, लॉगिन के पीछे निजी समीक्षाएं, कार्ट टोकन और खाता डेटा अनुमति वाले साइट मालिक के बिना बाहर रखे जाने चाहिए।
यहीं पर एक फॉलबैक बैंक काम करता है। एक क्रॉलर अनसुलझे पृष्ठों को समीक्षा के लिए स्टोर कर सकता है बजाय बार-बार पुनः प्रयास करने के। एक ऐसा डिज़ाइन चयन लोड कम करता है, लागत कम करता है और ReCAPTCHA प्रबंधन को व्यावहारिक बनाता है।
अतिरिक्त इंजीनियरिंग पैटर्न के लिए, CapSolver के लेख तीन तरीके से CAPTCHA हल करें जब आप स्क्रैपिंग कर रहे हैं उपकरण योजना में समर्थन कर सकते हैं।
सामान्य त्रुटियां बचें
पहली गलती यह है कि ReCAPTCHA को केवल एक तकनीकी बाधा के रूप में माना जाता है। यह अक्सर यह संकेत देता है कि क्रॉलर बहुत व्यापक, बहुत तेज है या अपेक्षित प्रवाह के बाहर है। टूल्स जोड़ने से पहले वर्कफ्लो को सुधारें।
दूसरी गलती यह है कि पृष्ठ के संदर्भ को अनदेखा कर देना। ईकॉमर्स साइट्स खोज, उत्पाद, कार्ट, लॉगिन और चेकआउट पृष्ठों को अलग-अलग तरीके से लेती हैं। आपके क्रॉलर को भी ऐसा ही करना चाहिए। सार्वजनिक उत्पाद निगरानी के लिए अलग जोखिम प्रोफाइल होता है जबकि खाता स्वचालन से अलग होता है।
तीसरी गलती यह है कि एडिट लॉग छोड़ देना। प्रत्येक ReCAPTCHA घटना को URL समूह, समय-माप, क्रॉलर संस्करण, प्रतिक्रिया कोड और लिया गया कार्य के साथ दर्ज करना चाहिए।
चौथी गलती यह है कि जीरो कोड का उपयोग करना। ReCAPTCHA के कार्यान्वयन बदल जाते हैं। CapSolver दस्तावेजीकरण कोड संरचना, टास्क प्रकार और आवश्यक क्षेत्रों के लिए स्रोत होना चाहिए।
निष्कर्ष और CTA
ईकॉमर्स स्क्रैपिंग में ReCAPTCHA को नीति, निदान और सावधानीपूर्वक उपकरणों के माध्यम से निपटाया जाना चाहिए। पहले अनुमति जांच, robots.txt, शर्तें और डेटा न्यूनतम के साथ शुरू करें। फिर गति, स्थिर सत्र और सीमित स्कोप के साथ अवांछित चुनौतियों को कम करें। यदि ReCAPTCHA एक कानूनी और अनुमति वाले ऑटोमेशन वर्कफ्लो में अभी भी दिखाई देता है, CapSolver आधिकारिक दस्तावेजीकरण पर आधारित एक व्यावहारिक हल प्रदान कर सकता है।
यदि आपकी टीम को ईकॉमर्स डेटा संग्रह के दौरान ReCAPTCHA का निपटारा करने के लिए नियंत्रित तरीका चाहिए, तो CapSolver के दस्तावेजीकरण की समीक्षा करें, अपनी सुसंगतता नियमों को परिभाषित करें और पहले कम आवृत्ति वाले सार्वजनिक पृष्ठों पर परीक्षण करें। एक जिम्मेदार क्रॉलर केवल आवश्यकता के अनुसार डेटा एकत्र करे, नियमों में बदलाव होने पर रुक जाए और एक स्पष्ट एडिट ट्रेल छोड़ दे।
FAQ
ईकॉमर्स स्क्रैपिंग के दौरान ReCAPTCHA का प्रबंधन करना कानूनी है क्या?
इसका उत्तर अनुमति, डेटा प्रकार, जिला और साइट की शर्तों पर निर्भर करता है। एक सुरक्षित वर्कफ्लो सार्वजनिक अनुमति पृष्ठों का उपयोग करता है, robots.txt का सम्मान करता है, निजी डेटा से बचता है और दस्तावेजीकृत सीमाओं का पालन करता है। व्यावसायिक परियोजनाओं के लिए कानूनी समीक्षा उपयोगी हो सकती है।
उत्पाद पृष्ठ पर ReCAPTCHA क्यों दिखाई देता है?
ReCAPTCHA तब दिखाई दे सकता है जब अनुरोध की मात्रा, सत्र इतिहास, ब्राउज़र संदर्भ या ट्रैफिक समय असामान्य लगता है। यह भी तब दिखाई दे सकता है जब साइट मूल्य और उपलब्धता पृष्ठों के लिए सख्त सुरक्षा लागू करती है।
क्या मैं हर ReCAPTCHA जो मैं देखता हूं उसे हल करूं?
नहीं। उच्च ReCAPTCHA दर आमतौर पर क्रॉलर की समीक्षा के संकेत हैं। धीमा हो जाए, सीमा कम करें, अनुमति पथ की जांच करें, और अनुमति अपवाद मामलों के लिए हल करें।
क्या CapSolver ईकॉमर्स स्क्रैपिंग में मदद कर सकता है?
हाँ, CapSolver तब मदद कर सकता है जब एक वैध ई-कॉमर्स ऑटोमेशन वर्कफ़्लो रिकैपचा के सामना करता है। केवल कानूनी, उपयोगी और अनुमति प्राप्त डेटा कार्य के लिए इसका उपयोग करें, और आधिकारिक दस्तावेज़ का अनुसरण करें।
स्थापना के बाद मैं क्या निरीक्षण करूं?
रिकैपचा दर, स्थिति कोड, पार्स त्रुटियां, आयतन, पथ समूह और अनिर्णीत कतारें निरीक्षण करें। जब सीमा पार की जाती है तो क्राउलर रोकें।
और देखें
AIJun 26, 2026
CAPTCHA: AI एजेंट इंफ्रास्ट्रक्चर में अनुपस्थित घटक
जानें क्यों ट्रैफिक सत्यापन का निपटारा AI एजेंट इंफ्रास्ट्रक्चर में अनुपस्थित घटक है। स्वायत्त एजेंट के लिए मजबूत समाधान एकीकृत करना सीखें।
AIJun 26, 2026
एआई एजेंट्स कैप्चा को बड़े पैमाने पर कैसे संभालते हैं
- AI एजेंटों को स्वचालित वेब ऑपरेशन के दौरान कैप्चा को स्केल पर संभालने के लिए मजबूत बुनियादी ढांचा की आवश्यकता होती है। - आधुनिक ट्रैफिक सत्यापन प्रणालियां स्वचालित अनुरोधों की पहचान करने के लिए व्यवहार विश्लेषण और डिवाइस फिंगरप्रिंटिंग का उपयोग करती हैं। - एक भरोसेमंद कैप्चा हल करने वाला API एकीकृत करना स्वायत्त एजेंटों के लिए लगातार संचालन सुनिश्चित करता है। - वितरित आर्किटेक्चर और प्रॉक्सी घूर्णन उच्च आयतन के प्रबंधन के लिए आवश्यक हैं।