वेब स्क्रैपिंग सुरक्षा: डेटा की रक्षा करें और पता लगाने से बचें के लिए शीर्ष विधियां

Rajinder Singh
Deep Learning Researcher

TL;Dr:
- कानूनी एवं नैतिक पालन:
robots.txtऔर उपयोग की शर्तों का पालन करें ताकि नैतिक डेटा संग्रह हो सके। - मानव व्यवहार की नकल करें: बोट डिटेक्शन से बचने के लिए देरी के उपयोग, उपयोगकर्ता एजेंट के घूर्णन और कुकीज के प्रबंधन के लिए उपयोग करें।
- प्रॉक्सी का उपयोग करें: अपने आईपी को छिपाने और अनुरोधों के वितरण के लिए विविध प्रॉक्सी प्रकार (रिज़ीडेंशियल, डेटासेंटर) का उपयोग करें।
- CAPTCHA का प्रबंधन करें: अवरोध बिना डेटा संग्रह के लिए स्वचालित CAPTCHA हल करने सेवाओं के साथ एकीकृत करें।
- मॉनिटर एवं अनुकूलित करें: डेटा संग्रह के प्रभावी रखने के लिए निरंतर रूप से रॉबोट निरीक्षण के प्रदर्शन और वेबसाइट परिवर्तनों की निगरानी करें।
परिचय
वेब स्क्रैपिंग, एक शक्तिशाली डेटा निकालने की तकनीक, सुरक्षा चुनौतियों और डिटेक्शन जोखिमों के साथ आती है। इस गाइड वेब स्क्रैपिंग सुरक्षा के शीर्ष अभ्यासों को सूचीबद्ध करती है, जो डेटा विशेषज्ञों की डेटा सुरक्षा और एंटी-बॉट प्रणालियों के माध्यम से निर्देशन में मदद करती है। डिटेक्शन मैकेनिज्म की समझ और मजबूत रणनीति के लागू करने से दक्ष, नैतिक और अविच्छिन्न डेटा संग्रह सुनिश्चित होता है। हम अवधारणाओं को स्पष्ट करते हैं, मूलभूत ज्ञान स्थापित करते हैं और आपके वेब स्क्रैपिंग ऑपरेशन को बढ़ाने के लिए व्यावहारिक समाधान प्रदान करते हैं। मूल बातों में गहराई से जानने के लिए, वेब स्क्रैपिंग क्या है का अध्ययन करें।
वेब स्क्रैपिंग सुरक्षा: क्या, क्यों और कैसे
सुरक्षित और प्रभावी वेब स्क्रैपिंग के लिए वेबसाइटों के जानकारी के संरक्षण के तरीकों और अभ्यासों की समझ आवश्यक है। वेब स्क्रैपिंग सुरक्षा एक ऐसा तरीका है जो स्क्रैपर के डिटेक्शन, ब्लॉकिंग या कानूनी समस्याओं से बचाने के लिए उपयोग किया जाता है। लक्ष्य डेटा के संग्रह के साथ वेबसाइट की नीतियों के सम्मान और एंटी-बॉट ट्रिगर के बिना रहना है। इसका उद्देश्य दक्षता के साथ छिपाव का संतुलन करना है, जिससे स्क्रैपिंग गतिविधियां वास्तविक उपयोगकर्ता अंतरक्रियाओं के रूप में दिखाई दें।
वेब स्क्रैपिंग डिटेक्शन की आत्मा
वेबसाइटें एक अस्वाभाविक स्क्रैपिंग की पहचान करने और रोकने के लिए विभिन्न तकनीकों का उपयोग करती हैं। डिटेक्शन मैकेनिज्म व्यावहारिक मानव व्यवहार से विचलन के पैटर्न का विश्लेषण करते हैं। एक आईपी से उच्च अनुरोध दर या ब्राउजर-विशिष्ट हेडर की कमी तेजी से एक स्क्रैपर को चिह्नित कर सकती है। इन ट्रिगर की समझ निर्भर रूप से स्क्रैपिंग रणनीतियों के लिए आवश्यक है। एंटी-बॉट प्रौद्योगिकी लगातार विकसित हो रही है, जिसके कारण वेब स्क्रैपिंग सुरक्षा अभ्यासों के लगातार अनुकूलन की आवश्यकता होती है।
एंटी-बॉट प्रणालियां कैसे काम करती हैं
एंटी-बॉट प्रणालियां आगमन अनुरोधों से कई डेटा बिंदुओं का विश्लेषण करती हैं, एक उपयोगकर्ता प्रोफाइल बनाती हैं और असामान्यताओं की खोज करती हैं। महत्वपूर्ण संकेतों में आईपी प्रतिष्ठा, ब्राउजर फिंगरप्रिंटिंग, अनुरोध हेडर और व्यवहार पैटर्न शामिल हैं। मानव प्रोफाइल से महत्वपूर्ण विचलन के कारण कैप्चा चुनौतियों से आईपी ब्लॉकिंग तक के प्रतिक्रियाएं उत्पन्न हो सकती हैं। प्रभावी वेब स्क्रैपिंग सुरक्षा वास्तविक ट्रैफिक के साथ मिल जाने के लक्ष्य के साथ बनाई जाती है, जिससे इन प्रणालियों के लिए अंतर बनाना कठिन हो जाता है।
संरचित ज्ञान: परिभाषाएं, वर्गीकरण और परिस्थितियां
वेब स्क्रैपिंग सुरक्षा में एक ठोस आधार बनाने के लिए घटकों के वर्गीकरण और उनके कार्यों की समझ आवश्यक है। इस संरचित दृष्टिकोण में विभिन्न स्क्रैपिंग चुनौतियों के लिए उपयुक्त उपायों की पहचान करना आसान हो जाता है।
वेब स्क्रैपिंग सुरक्षा में मुख्य अवधारणाएं
- आईपी घूर्णन: एक आईपी के बजाय अलग-अलग आईपी के उपयोग से अनुरोधों के लोड के वितरण के लिए आईपी बदलें और एक आईपी के चिह्नित होने से बचें। यह तकनीक आईपी बैंड के बजाय अलग-अलग उपयोगकर्ताओं के रूप में अनुरोधों के उत्पादन के लिए महत्वपूर्ण है।
- उपयोगकर्ता-एजेंट प्रबंधन: लोकप्रिय ब्राउजर के समान दिखने वाले
User-Agentहेडर को सेट करें, क्योंकि एंटी-बॉट प्रणालियां इसकी वैधता की जांच करती हैं। नियमित रूप से उपयोगकर्ता-एजेंट के घूर्णन से अधिक छिपाव बढ़ सकती है। - अनुरोध धीमा करें: मानव ब्राउजिंग पैटर्न के समान अनुरोधों के बीच देरी डालें और सर्वर ओवरलोड से बचें। इन देरियों को यादृच्छिक बनाने से स्क्रैपिंग गतिविधि अधिक प्राकृतिक दिखाई देती है।
- ब्राउजर फिंगरप्रिंटिंग: ब्राउजर के अद्वितीय विशेषताओं (जैसे, प्लगइन, फॉन्ट, स्क्रीन रिज़ॉल्यूशन) के एकत्रीकरण के माध्यम से उपयोगकर्ताओं की पहचान और ट्रैक करना। उन्नत एंटी-बॉट प्रणालियां इसका उपयोग हेडलेस ब्राउजर की पहचान करने के लिए करती हैं। स्क्रैपर को सामान्य और स्थिर ब्राउजर फिंगरप्रिंट के प्रस्तुत करने का प्रयास करना चाहिए।
- CAPTCHA (पूर्ण रूप से स्वचालित सार्वजनिक ट्यूरिंग परीक्षा जो कंप्यूटर और मनुष्यों के बीच अंतर बताने के लिए है): एक चुनौति-उत्तर परीक्षा जो मानव उपयोगकर्ताओं की पुष्टि करती है। विभिन्न प्रकार के होते हैं जिनमें अलग-अलग स्वीकृति तर्क होते हैं, जो स्वचालित प्रणालियों के लिए एक महत्वपूर्ण बाधा बन जाते हैं।
एंटी-बॉट उपायों का वर्गीकरण
वेबसाइटें स्क्रैपर के खिलाफ एक परतदार रक्षा प्रणाली लगाती हैं:
- दर सीमा लगाना: एक समय अंतराल में एक आईपी से अनुरोधों की सीमा लगाना। अपनी सीमा के बाहर जाने पर अस्थायी या स्थायी ब्लॉकिंग हो सकती है।
- आईपी ब्लैकलिस्टिंग: ऐतिहासिक डेटा या खतरा जानकारी के आधार पर ज्ञात खतरनाक आईपी पते या श्रृंखलाओं को ब्लॉक करना। इसलिए विविध प्रॉक्सी के उपयोग की आवश्यकता होती है।
- CAPTCHA चुनौतियां: मानव अंतरक्रिया की पुष्टि के लिए दृश्य या अंतरक्रियात्मक पहेलियां प्रस्तुत करना (जैसे, reCAPTCHA, Cloudflare Turnstile)। इनका डिज़ाइन बॉट्स के लिए स्वचालित रूप से हल करना कठिन होता है।
- उपयोगकर्ता-एजेंट और हेडर जांच:
User-Agentस्ट्रिंग और अन्य HTTP हेडर की पुष्टि करें ताकि वे वैध ब्राउजर के समान दिखाई दें। असंगत या पुराने हेडर एक बॉट के रूप में चिह्नित कर सकते हैं। - होनीपॉट्स: एक अस्पष्ट लिंक या तत्व जो एक अस्वाभाविक बॉट को फंसाने के लिए डिज़ाइन किए गए हैं। इनका अनुसरण एक गैर-मानव के रूप में स्क्रैपर की पहचान करता है, जिसके परिणामस्वरूप तत्काल ब्लॉकिंग होती है।
- जावास्क्रिप्ट चुनौतियां: अंतर्निहित सामग्री या गणितीय पहेलियां हल करने के लिए जावास्क्रिप्ट निष्पादन की आवश्यकता होती है, जो सरल HTTP स्क्रैपर को रोकती है जो जावास्क्रिप्ट के निष्पादन के बिना काम करते हैं।
- ब्राउजर फिंगरप्रिंटिंग: ब्राउजर के छोटे विशेषताओं के विश्लेषण के माध्यम से एक अस्वाभाविक उपकरण की पहचान करना। इसमें एक हेडलेस ब्राउजर के संकेत देखने के लिए ब्राउजर के गुणों में असंगतियों की जांच शामिल है।
सुरक्षित स्क्रैपिंग के उपयोग के मामले
सुरक्षित वेब स्क्रैपिंग विभिन्न एप्लिकेशन, जैसे बाजार अनुसंधान, सामग्री संग्रह और प्रतिस्पर्धी जानकारी के लिए आवश्यक है। उदाहरण के लिए, एक ई-कॉमर्स व्यवसाय जो प्रतिद्वंद्वी मूल्य निर्धारण के लिए स्क्रैप करता है, ब्लॉकिंग से बचने के लिए एक कम प्रोफाइल की आवश्यकता होती है और वास्तविक समय में सटीक डेटा एकत्र करता है। अकादमिक अनुसंधानकर्ता जो सार्वजनिक डेटा के एकत्रीकरण करते हैं, नियमित विधियों के साथ निश्चित करते हैं ताकि कानूनी और नैतिक समस्याओं से बचा जा सके। वेब स्क्रैपिंग सुरक्षा के सिद्धांत सभी डेटा संग्रह लक्ष्यों के लिए व्यापक रूप से लागू होते हैं, जो डेटा अखंडता और ऑपरेशनल निरंतरता सुनिश्चित करने के लिए मजबूत रणनीतियों की आवश्यकता को बल देते हैं।
तकनीकी पृष्ठभूमि: CAPTCHA प्रकार, स्वीकृति तर्क और जोखिम नियंत्रण
CAPTCHA एक महत्वपूर्ण बाधा है, जो मानव उपयोगकर्ताओं को बॉट से अलग करने के लिए डिज़ाइन किए गए हैं। इनके तकनीकी आधार की समझ इनके उत्तर देने के लिए महत्वपूर्ण है। CAPTCHA प्रौद्योगिकी लगातार विकसित हो रही है ताकि इनके स्वचालित हल करने के खिलाफ रक्षा की जा सके।
सामान्य CAPTCHA प्रकार और उनकी तार्किकता
- reCAPTCHA (गूगल): सरल पाठ स्वीकृति (v1) से विकसित हुआ है, जो व्यवहार विश्लेषण और जोखिम स्कोर पर आधारित है (v2 "मैं एक रोबोट नहीं हूं" चेकबॉक्स, अदृश्य reCAPTCHA) और अदृश्य पृष्ठभूमि विश्लेषण (v3)। v2 और v3 के लिए तार्किकता उपयोगकर्ता अंतरक्रिया पैटर्न, ब्राउजर फिंगरप्रिंटिंग और आईपी प्रतिष्ठा पर भारी आधारित है। साफ ब्राउजिंग इतिहास, सामान्य माउस गतिविधि और स्थिर उपयोगकर्ता व्यवहार चुनौती के लिए कम संभावना कम करते हैं।
- Cloudflare Turnstile: एक गोपनीयता-केंद्रित reCAPTCHA विकल्प, जो आमतौर पर छवि-आधारित चुनौतियां या अप्रत्यक्ष सत्यापन का उपयोग करता है। इसकी तार्किकता उपयोगकर्ता चयनों या व्यवहार संकेतों की सटीकता और स्थिरता पर केंद्रित है, बिना अक्सर सीधे उपयोगकर्ता अंतरक्रिया के।
- छवि-आधारित CAPTCHA: छवि के भीतर वस्तुओं, अक्षरों या पैटर्न की पहचान करने की आवश्यकता होती है। स्वीकृति तार्किकता छवि पैटर्न मिलान का उपयोग करती है, जो बॉट के लिए उन्नत कंप्यूटर दृष्टि क्षमता के बिना कठिन होती है।
- ऑडियो CAPTCHA: नंबर या अक्षरों के विकृत ऑडियो क्लिप प्रस्तुत करता है जिनका टाइपिंग करना होता है। बॉट आमतौर पर विकृति, पृष्ठभूमि शोर और अलग-अलग उच्चारण के कारण इनके साथ कठिनाई महसूस करते हैं, जो इनके लिए सरल स्वचालित हल करने के लिए प्रभावी होता है।
स्वीकृति तार्किकता और जोखिम नियंत्रण
एंटी-बॉट प्रणालियां, जिनमें CAPTCHA के उपयोग शामिल हैं, जटिल जोखिम नियंत्रण तंत्र का उपयोग करती हैं। वे वास्तविक समय में बहुत सारे कारकों का विश्लेषण करती हैं ताकि अनुरोध के एक बॉट से आने की संभावना का आकलन किया जा सके:
- व्यवहार विश्लेषण: इसमें माउस गतिविधि, कीबोर्ड इनपुट, स्क्रॉल पैटर्न और पृष्ठ पर बिताए गए समय की जांच शामिल है। असंगत या अत्यधिक सटीक क्रियाएं, या बहुत तेज या बहुत धीमी क्रियाएं बॉट के रूप में चिह्नित कर सकती हैं।
- नेटवर्क विशेषताएं: आईपी प्रतिष्ठा, मूल देश और ज्ञात वीपीएन या प्रॉक्सी के उपयोग के साथ फैक्टर का मूल्यांकन किया जाता है। खतरनाक गतिविधि या डेटा सेंटर से जुड़े आईपी अक्सर अधिक आसानी से चिह्नित किए जाते हैं।
- ब्राउजर पर्यावरण:
User-Agentस्ट्रिंग में असंगतियां, अनुपस्थित प्लगइन, असामान्य जावास्क्रिप्ट निष्पादन परिस्थितियां या रिपोर्ट की गई स्क्रीन रिज़ॉल्यूशन में असंगतियां एक हेडलेस ब्राउजर या एक स्वचालित स्क्रिप्ट के संकेत हो सकती हैं। - अनुरोध आवृत्ति और आयतन: एक छोटे समय अंतराल में एक स्रोत से असामान्य रूप से उच्च अनुरोध, जो सामान्य मानव ब्राउजिंग पैटर्न से बहुत अधिक होते हैं, एक स्वचालित गतिविधि के लिए एक मजबूत संकेत हैं।
संचित जोखिम कारक उत्तर को बढ़ा देते हैं, जिसके परिणामस्वरूप अधिक कठिन CAPTCHA चुनौतियां, दर सीमा लगाना या आईपी ब्लॉकिंग हो सकती है। वेब स्क्रैपिंग सुरक्षा रणनीतियां इन कारकों को कम करने के लिए डिज़ाइन की जाती हैं, ताकि स्क्रैपर वास्तविक मानव उपयोगकर्ताओं के रूप में दिखाई दें।
सुरक्षित वेब स्क्रैपिंग के लिए सरल प्रक्रिया बहुत आसान है
सुरक्षित वेब स्क्रैपिंग प्रक्रिया के एक उच्च स्तर की समझ दक्ष उपायों के लागू करने में मदद करती है।
-
प्रारंभिक सेटअप और कॉन्फ़िगरेशन:
- एक विश्वसनीय प्रॉक्सी प्रदाता चुनें: विविध आईपी प्रकार (रिज़ीडेंशियल, मोबाइल) और घूर्णन प्रदान करने वाली सेवा का चयन करें। यह वेब स्क्रैपिंग सुरक्षा के लिए आधारभूत है, क्योंकि यह अनुरोधों के वितरण और अपने वास्तविक आईपी पते को छिपाने में मदद करता है।
User-Agentघूर्णन कॉन्फ़िगर करें: अपडेट करेंUser-Agentस्ट्रिंग और प्रत्येक अनुरोध या सत्र के लिए घूर्णन करें। इससे विविध उपयोगकर्ता वातावरण की नकल करके डिटेक्शन के बारे में बात की जा सकती है।- अनुरोध देरी लागू करें: अनुरोधों के बीच यादृच्छिक देरी (उदाहरण के लिए, 2-10 सेकंड) डालें ताकि मानव ब्राउजिंग गति के समान दिखाई दे। अकेले निश्चित, नियमित देरी के बजाय बॉट के लिए आसानी से डिटेक्शन के लिए बनाए रखें।
-
स्क्रैपिंग से पहले जांच:
robots.txtकी समीक्षा करें: लक्ष्य वेबसाइट केrobots.txtफ़ाइल (https://example.com/robots.txt) की जांच करें जो स्क्रैपिंग नीतियों के लिए है। नैतिक और कानूनी पालन के लिए इन निर्देशों का पालन करना आवश्यक है।robots.txtको अनदेखा करने से कानूनी समस्याओं और आईपी बैन के कारण हो सकता है। यह उत्तरदायी वेब स्क्रैपिंग सुरक्षा के लिए एक मूलभूत पहलू है।- वेबसाइट संरचना का विश्लेषण करें: HTML संरचना की समझ और संभावित होनीपॉट्स (जैसे,
display: noneयाvisibility: hiddenतत्व) की पहचान करें ताकि आप उनके साथ अंतरक्रिया न करें। होनीपॉट्स के साथ अंतरक्रिया एक स्वचालित गतिविधि के स्पष्ट संकेत हैं।
-
कार्यान्वयन और निगरानी:
- डेटा निकालें: अपने स्क्रिप्ट को निष्पादित करें, जो कॉन्फ़िगर की गई देरी और प्रॉक्सी घूर्णन का पालन करता है।
- ब्लॉक की निगरानी करें: अनुरोध सफलता दर और HTTP स्थिति कोड की निरंतर निगरानी करें। यदि ब्लॉक होते हैं (उदाहरण के लिए, HTTP 403, 429, या CAPTCHA पृष्ठ), उत्तर के कारण की जांच करें। कैसे आईपी बैन को पार करें के लिए हमारे विस्तृत गाइड के लिए रुचि रखें।
- अनुकूलित और सुधारित करें: वास्तविक समय की निगरानी और वेबसाइट के उत्तरों से प्राप्त प्रतिक्रिया के आधार पर अनुरोध के आयोजन (उदाहरण के लिए, देरी बढ़ाएं, प्रॉक्सी प्रकार बदलें,
User-Agentस्ट्रिंग अपडेट करें) के अनुकूलित करें।
-
स्क्रैपिंग के बाद और डेटा का प्रबंधन:
- डेटा की जांच करें: निकाले गए डेटा की सटीकता, पूर्णता और संगतता की जांच करें। सुनिश्चित करें कि डेटा साफ और उपयोग के लिए तैयार है।
- संग्रह और सुरक्षा: संगृहीत डेटा को सुरक्षित रूप से संग्रहीत करें, जो जीडीपीआर और सीसीपीए के समान संबंधित डेटा सुरक्षा नियमों के अनुपालन करते हैं। सुनिश्चित करें कि डेटा एन्क्रिप्ट किया गया है और केवल अनुमति प्राप्त व्यक्ति तक पहुंच है।
वेब स्क्रैपिंग सुरक्षा के लिए समाधान
जैसे-जैसे एंटी-बॉट प्रौद्योगिकी विकसित होती है, वैसे-वैसे सुरक्षित वेब स्क्रैपिंग रणनीतियां भी विकसित होनी चाहिए। ये समाधान सामान्य चुनौतियों का समाधान करते हैं और टिकाऊ डेटा संग्रह के मार्ग प्रदान करते हैं।
मानव व्यवहार की नकल करें
अपने स्क्रैपर को मानव उपयोगकर्ता के रूप में बर्ताव करने के लिए बहुत प्रभावी है:
- यादृच्छिक देरी: अनुरोधों के बीच यादृच्छिक अंतराल (उदाहरण के लिए, 5-15 सेकंड) का उपयोग करें जो एक अधिक प्राकृतिक दिखाई देता है, जो वेब स्क्रैपिंग सुरक्षा में सुधार करता है। इससे बॉट आमतौर पर प्रस्तुत करते हैं विवरण पैटर्न को बचाया जाता है।
- वास्तविक ज्ञान वाले क्लिक पैटर्न: हेडलेस ब्राउजर के लिए, विविध निर्देशांक और समय के साथ प्राकृतिक माउस गतिविधि और क्लिक के समान अंतरक्रिया के साथ अंतरक्रिया करें। बिना पहले माउस गतिविधि के तत्वों पर सीधे क्लिक करने से बचें।
- कुकीज का प्रबंधन: सत्रों के माध्यम से कुकीज को बरकरार रखें और प्रबंधित करें ताकि स्थिति बनाए रखी जा सके और संदेह कम हो सके। वेबसाइटें आमतौर पर कुकीज का उपयोग उपयोगकर्ता सत्रों की ट्रैकिंग और वापस आए उपयोगकर्ताओं की पहचान करने के लिए करती हैं।
- रिफरर हेडर: एक वैध स्रोत (उदाहरण के लिए, एक खोज इंजन या उसी साइट पर पिछला पृष्ठ) से आने वाले
Refererहेडर को सेट करें, जो अनुरोध की वैधता और वेब स्क्रैपिंग सुरक्षा में अतिरिक्त वैधता जोड़ता है।
उन्नत प्रॉक्सी रणनीतियां
प्रॉक्सी वेब स्क्रैपिंग सुरक्षा के लिए महत्वपूर्ण हैं। एक विविध प्रॉक्सी प्रकार के उपयोग से अनुरोधों के वितरण और आईपी पते के छिपाव में सुधार होता है:
- रिज़ीडेंशियल प्रॉक्सी: इन आईपी पते इंटरनेट सेवा प्रदाता (आईएसपी) द्वारा रिज़ीडेंशियल उपयोगकर्ताओं के लिए आवंटित किए जाते हैं। वे एंटी-बॉट प्रणालियों के लिए वास्तविक उपयोगकर्ता ट्रैफिक के रूप में अधिक प्रभावी हैं, जो वास्तविक उपयोगकर्ताओं से अलग करने में कठिन होते हैं। रिज़ीडेंशियल प्रॉक्सी अत्यधिक सुरक्षित लक्ष्यों के लिए मजबूत वेब स्क्रैपिंग सुरक्षा के लिए आवश्यक हैं।
- मोबाइल प्रॉक्सी: मोबाइल ऑपरेटरों से आईपी पते अधिक गुप्त होते हैं क्योंकि उनकी गतिशील प्रकृति और वास्तविक मोबाइल उपकरणों से जुड़े होते हैं। वे उच्च गोपनीयता प्रदान करते हैं और अत्यधिक सुरक्षित लक्ष्यों के लिए उत्कृष्ट विकल्प हैं।
- डेटासेंटर प्रॉक्सी: ये तेज और सस्ते होते हैं लेकिन वे व्यावसायिक डेटा केंद्रों से आते हैं जिन्हें आसानी से पहचाना जा सकता है। वे कम सुरक्षित वेबसाइटों के लिए उपयुक्त हैं या प्रारंभिक परीक्षण चरणों में जहां गोपनीयता मुख्य चिंता नहीं है।
संक्षिप्त समाप्ति: प्रॉक्सी प्रकार के लिए वेब स्क्रैपिंग सुरक्षा
| विशेषता | डेटासेंटर प्रॉक्सी | रिज़ीडेंशियल प्रॉक्सी | मोबाइल प्रॉक्सी |
|---|---|---|---|
| गोपनीयता स्तर | कम से लेकर मध्यम | उच्च | बहुत उच्च |
| पहचान जोखिम | उच्च | कम | बहुत कम |
| गति | उच्च | मध्य | मध्य |
| लागत | कम | मध्य से उच्च | उच्च |
| उपयोग केस | कम सुरक्षित साइटें | मध्यम सुरक्षित साइटें | उच्च सुरक्षित साइटें |
| आईपी स्रोत | व्यावसायिक डेटा केंद्र | आईएसपी | मोबाइल ऑपरेटर |
कैप्चा चुनौतियों का निपटारा कैपसॉल्वर के साथ कैसे करें
कैप्चा एक ऑटोमेटेड स्क्रैपिंग के खिलाफ मुख्य रक्षा है। बड़े पैमाने पर ऑपरेशन के लिए हस्तक्षेप अव्यावहारिक है, जिसके कारण ऑटोमेटेड कैप्चा समाधान सेवाएं वेब स्क्रैपिंग सुरक्षा के लिए अनिवार्य हो जाती हैं।
CapSolver विभिन्न कैप्चा प्रकार के लिए एक मजबूत समाधान प्रदान करता है, जिसमें reCAPTCHA, Cloudflare Turnstile और छवि-आधारित चुनौतियां शामिल हैं। CapSolver के साथ एकीकरण कैप्चा समाधान को स्वचालित करता है, जिससे डेटा संग्रह अविरत रहता है। CapSolver की उन्नत AI-आधारित बुनियादी ढांचा जटिल कैप्चा की पहचान करता है और हल करता है, जिससे आपका स्क्रैपर मानव उपयोगकर्ता द्वारा चुनौती पूरी कर देने के रूप में आगे बढ़ता है। इसकी उपयोगिता तब होती है जब पारंपरिक मानव व्यवहार की नकल पर्याप्त नहीं होती है। उदाहरण के लिए, reCAPTCHA v3 के लिए, CapSolver एक टोकन प्रदान करता है जो जटिल जोखिम मूल्यांकन पर आधारित वेरिफिकेशन को पार करता है, जो वेब स्क्रैपिंग सुरक्षा और दक्षता को बहुत अधिक बढ़ाता है।
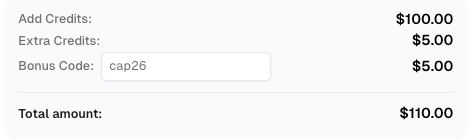
CapSolver पर पंजीकरण करते समय कोड
CAP26का उपयोग करें CapSolver बोनस क्रेडिट प्राप्त करने के लिए!
CapSolver की सेवाएं मौजूदा स्क्रैपिंग फ्रेमवर्क में बिना किसी समस्या के एकीकृत होती हैं, जो निम्नलिखित के लिए समाधान प्रदान करती हैं:
- reCAPTCHA v2/v3: कैप्चा टोकन जनरेट करके बॉक्स और अदृश्य reCAPTCHA चुनौतियों को हल करें।
- Cloudflare Turnstile: जो बॉट्स के खिलाफ गोपनीयता-संरक्षित और प्रभावी है, Cloudflare Turnstile पहेलियों को सटीक रूप से हल करें।
- ImageToText कैप्चा: उन्नत ऑप्टिकल कैरेक्टर रिकग्निशन (OCR) तकनीक का उपयोग करके छवियों से विकृत पाठ को टाइप करें।
इस तरह की सेवाओं का उपयोग जटिल एंटी-बॉट उपायों के खिलाफ वेब स्क्रैपिंग ऑपरेशन की प्रतिरोधक क्षमता में सुधार करता है। एकीकरण विवरण के लिए, आधिकारिक डॉक्यूमेंटेशन के लिए रुचि रखें, जैसे कैप्चा समाधान API कैसे चुनें? 2026 खरीददार का गाइड और तुलना।
कानूनी और नैतिक मुद्दे
लंबे समय तक वेब स्क्रैपिंग सुरक्षा के लिए कानूनी और नैतिक वातावरण की समझ महत्वपूर्ण है। इन पहलुओं को अनदेखा करने से गंभीर परिणाम हो सकते हैं। Zyte द्वारा एक रिपोर्ट के अनुसार, वेब स्क्रैपिंग स्वयं अकानूनी नहीं है, लेकिन इसकी कानूनीता डेटा के खास तरीके और उपयोग किए गए तरीकों पर बहुत अधिक निर्भर करती है। हमेशा नैतिक मुद्दों को प्राथमिकता दें ताकि एक सकारात्मक प्रतिष्ठा बनाए रखा जा सके और कानूनी बाधाओं से बचा जा सके।
robots.txt और शर्तों के सेवा का सम्मान करें
robots.txt: यह फ़ाइल वेब क्रॉलर्स को बताती है कि वेबसाइट के किन हिस्सों को बचाना है। हमेशा इन नियमों का पालन करें। यह एक मजबूत नैतिक दिशा-निर्देश है, और इसका अनदेखा करना वेबसाइट की नीति के विरुद्ध हो सकता है और वेब स्क्रैपिंग सुरक्षा को खतरा पहुंचा सकता है।robots.txtका सम्मान करना जिम्मेदार स्क्रैपिंग का मूल भाग है।- सेवा की शर्तें (ToS): वेबसाइट अक्सर अपने ToS में ऑटोमेटेड डेटा संग्रह के खिलाफ होती हैं। इन शर्तों के उल्लंघन के कारण खाता समाप्त हो सकता है, IP बैन हो सकता है, और कानूनी विवाद हो सकता है। किसी भी स्क्रैपिंग गतिविधि शुरू करने से पहले अपने ToS की समीक्षा करें ताकि सुसंगतता सुनिश्चित की जा सके।
डेटा गोपनीयता और सुसंगतता
जब व्यक्तिगत डेटा के स्क्रैपिंग के लिए, GDPR (सामान्य डेटा सुरक्षा नियम) और CCPA (कैलिफोर्निया उपभोक्ता गोपनीयता अधिनियम) जैसे नियमों के अनुपालन महत्वपूर्ण है। सुनिश्चित करें कि एकत्रित डेटा का उचित रूप से उपयोग किया जाता है, आवश्यकता पड़ने पर एनॉनिमाइज किया जाता है, और केवल वैध उद्देश्यों के लिए उपयोग किया जाता है। असुसंगतता के कारण बड़े दंड और कानूनी परिणाम हो सकते हैं। डेटा गोपनीयता का ध्यान रखना वेब स्क्रैपिंग सुरक्षा का महत्वपूर्ण घटक है। उदाहरण के लिए, अंतरराष्ट्रीय गोपनीयता पेशेवरों के संघ (IAPP) यूरोपीय संघ के डेटा सुरक्षा कानूनों के बारे में बताता है कि वे विशेष रूप से व्यक्तिगत डेटा के संबंध में वेब स्क्रैपिंग के कानूनी उपयोग को बहुत कम कर देते हैं। इसके अलावा, GDPR और CCPA के साथ सुसंगतता के बारे में समझ वैश्विक रूप से काम कर रहे वेब स्क्रैपर्स के लिए आवश्यक है, क्योंकि इन नियमों के डेटा एकत्रण और प्रसंस्करण पर कठोर आवश्यकताएं होती हैं।
निष्कर्ष
कुशल वेब स्क्रैपिंग सुरक्षा एक लगातार अनुकूलन प्रक्रिया है। एंटी-बॉट प्रणालियों के बारे में समझ, मानव व्यवहार की नकल, उन्नत प्रॉक्सी रणनीतियों का उपयोग करना, और CapSolver जैसे ऑटोमेटेड कैप्चा समाधान सेवाओं का उपयोग करके आप डेटा संग्रह की प्रतिरोधक क्षमता में सुधार करते हैं। हमेशा कानूनी और नैतिक सुसंगतता को प्राथमिकता दें, robots.txt, ToS और डेटा गोपनीयता का सम्मान करें। एंटी-बॉट तकनीकों के बारे में जागरूक रहें और प्रदर्शन की निगरानी करें ताकि एक मजबूत, अपरिचित ऑपरेशन हो। वेब स्क्रैपिंग सुरक्षा के लिए इस प्रक्रिया के माध्यम से आप मूल्यवान अंतर्दृष्टि प्राप्त कर सकते हैं और जिम्मेदार और स्थायी डेटा अधिग्रहण रणनीति बनाए रख सकते हैं।
एफ़क्यू (FAQ)
प्रश्न 1: क्या वेब स्क्रैपिंग कानूनी है?
वेब स्क्रैपिंग की कानूनीता जटिल है, जो खास डेटा के खास तरीके, वेबसाइट की सेवा की शर्तें (ToS) और डेटा सुरक्षा कानूनों (जैसे GDPR, CCPA) पर बहुत अधिक निर्भर करती है। आमतौर पर, सार्वजनिक रूप से उपलब्ध डेटा के स्क्रैपिंग की अनुमति हो सकती है, लेकिन संपादित या व्यक्तिगत डेटा के बिना स्पष्ट अनुमति के उपयोग कानूनी हो सकता है। अपने विशिष्ट स्क्रैपिंग गतिविधियों की कानूनीता के बारे में असुरक्षित होने पर हमेशा कानूनी सलाह लेना सलाह दी जाती है।
प्रश्न 2: वेब स्क्रैपिंग के दौरान अपने IP ब्लॉक होने से कैसे बचें?
IP ब्लॉक होने से बचने के लिए, एक रणनीति बनाएं जो विविध प्रॉक्सी (आवासीय, मोबाइल) के साथ IP घूर्णन के साथ जुड़े हों, अपने अनुरोधों के बीच यादृच्छिक देरी डालें ताकि मानव ब्राउजिंग पैटर्न की नकल की जा सके, और उपयुक्त User-Agent और Referer हेडर के साथ मानव ब्राउजर व्यवहार की नकल करें। अपने स्क्रैपिंग लॉग की असामान्य गतिविधि या त्रुटि कोड (जैसे 403 या 429) की निगरानी करना एक सक्रिय अनुकूलन और वेब स्क्रैपिंग सुरक्षा बनाए रखने के लिए महत्वपूर्ण है।
प्रश्न 3: ब्राउजर फिंगरप्रिंटिंग क्या है और वेब स्क्रैपिंग पर कैसे प्रभाव डालता है?
ब्राउजर फिंगरप्रिंटिंग विशिष्ट ब्राउजर विशेषताओं जैसे स्थापित फॉन्ट, प्लगइन, स्क्रीन रिजॉल्यूशन, ऑपरेटिंग सिस्टम और भाषा सेटिंग्स के संग्रह के माध्यम से एक विशिष्ट पहचानकर्ता बनाता है। एंटी-बॉट प्रणालियां इसका उपयोग एक असंगत या अमानवीय ब्राउजर फिंगरप्रिंट वाले हेडलेस ब्राउजर या स्क्रिप्ट की पहचान करने के लिए करती हैं। उन्नत स्क्रैपर्स को वास्तविक और संगत ब्राउजर फिंगरप्रिंट के साथ टूल और तकनीक का उपयोग करना चाहिए ताकि पहचान न हो।
प्रश्न 4: CapSolver जैसी कैप्चा समाधान सेवाएं कैसे काम करती हैं?
CapSolver विशिष्ट कैप्चा प्रकारों की पहचान और हल करने के लिए उन्नत कृत्रिम बुद्धिमत्ता (AI) और मशीन लर्निंग एल्गोरिदम का उपयोग करता है। जब आपके स्क्रैपर को कैप्चा चुनौती मिलती है, तो यह चुनौती CapSolver के API पर भेज देता है। CapSolver फिर चुनौती का प्रसंस्करण करता है, एक समाधान जनरेट करता है, और इसे आपके स्क्रैपर को वापस भेज देता है। इस प्रक्रिया से कैप्चा को पार कर लिया जाता है और अवरोध बिना डेटा निकाला जाता है, जो आपके वेब स्क्रैपिंग ऑपरेशन की दक्षता और विश्वसनीयता में बहुत अधिक वृद्धि करता है और वेब स्क्रैपिंग सुरक्षा में सुधार करता है।
प्रश्न 5: होनीपॉट्स क्या हैं और मैं उनसे कैसे बच सकता हूं?
होनीपॉट्स एक अदृश्य लिंक या तत्व होते हैं जो एक ऑटोमेटेड बॉट को फंसाने के लिए एक वेबपेज में एम्बेड किए जाते हैं। एक मानव उपयोगकर्ता इन तत्वों को देखेगा या इनके साथ अंतर करेगा, लेकिन एक बॉट इनके साथ अंतर कर सकता है। होनीपॉट्स से बचने के लिए, आपके स्क्रैपर को लिंक के CSS गुणों (जैसे display: none, visibility: hidden, या color: #fff एक सफेद पृष्ठभूमि पर) का विश्लेषण करना चाहिए और विशिष्ट रूप से दृश्यमान नहीं होने वाले किसी भी लिंक का अनुसरण नहीं करना चाहिए। इस ध्यानपूर्वक विश्लेषण के माध्यम से वेब स्क्रैपिंग सुरक्षा बनाए रखना और तुरंत पहचान और ब्लॉकिंग से बचना आवश्यक है।
और देखें
aws wafJul 23, 2026
AWS WAF को LangChain में CapSolver के साथ कैसे हल करें
एक अधिकृत AWS WAF LangChain वर्कफ़्लो बनाएं, जिसमें CapSolver टूल्स, प्रतिक्रिया निर्णय, नीति गेट्स, सत्र प्रबंधन, पुनः प्रयास और सत्यापन हों।
AIJul 23, 2026
कैसे हल करें क्लाउडफ़ेयर टर्नस्टाइल लैंगग्राफ एजेंट्स में
एक LangGraph Cloudflare Turnstile सॉल्वर वर्कफ़्लो बनाएं, जिसमें CapSolver, Playwright सेशन हैंडलिंग, नीति गेट्स, पुनर्प्रयास, सत्यापन और समीक्षा शामिल हैं।