Cómo resolver captchas al realizar scraping web con Scrapling y CapSolver

Ethan Collins
Pattern Recognition Specialist

Puntos clave
- Scrapling es una biblioteca de raspado web de Python poderosa con funciones anti-bot integradas y seguimiento de elementos adaptativo
- CapSolver proporciona resolución automática de captchas para ReCaptcha v2, v3 y Cloudflare Turnstile con tiempos de resolución rápidos (1-20 segundos)
- Combinar Scrapling con CapSolver crea una solución de raspado robusta que maneja la mayoría de los sitios web protegidos por captchas
- StealthyFetcher agrega anti-detección a nivel de navegador cuando las solicitudes HTTP básicas no son suficientes
- Todos los tres tipos de captchas usan el mismo flujo de trabajo de CapSolver: crear tarea → consultar resultados → inyectar token
- El código de producción debe incluir manejo de errores, limitación de velocidad y respetar los términos de servicio del sitio web
Introducción
El raspado web se ha convertido en una herramienta esencial para la recolección de datos, investigación de mercado y análisis competitivo. Sin embargo, a medida que las técnicas de raspado han evolucionado, también lo han hecho las defensas que utilizan los sitios web para proteger sus datos. Entre los obstáculos más comunes que enfrentan los raspadores están los captchas — esos desafíos molestos diseñados para distinguir entre humanos y bots.
Si alguna vez intentó raspar un sitio web y se encontró con un mensaje "Por favor, verifique que es humano", sabe la frustración. ¡La buena noticia? Existe una combinación poderosa que puede ayudar: Scrapling para el raspado inteligente de web y CapSolver para la resolución automática de captchas.
En esta guía, le explicaremos todo lo que necesita saber para integrar estas herramientas y raspear con éxito sitios web protegidos por captchas. Ya sea que esté lidiando con ReCaptcha v2 de Google, ReCaptcha v3 invisible o Turnstile de Cloudflare, lo tenemos cubierto.
¿Qué es Scrapling?
Scrapling es una biblioteca moderna de raspado web de Python que se describe como "la primera biblioteca de raspado adaptativa que aprende de los cambios en los sitios web y evoluciona con ellos". Está diseñada para facilitar la extracción de datos, mientras proporciona capacidades poderosas anti-bot.
Características clave
- Seguimiento de elementos adaptativo: Scrapling puede localizar contenido incluso después de rediseños de sitio web usando algoritmos de similitud inteligentes
- Múltiples métodos de obtención: Solicitud HTTP con impersonación de huella dactilar TLS, automatización de navegadores y modo stealth
- Bypass anti-bot: Soporte integrado para evitar Cloudflare y otros sistemas anti-bot usando Firefox modificado y suplantación de huella dactilar
- Alto rendimiento: Las pruebas de extracción de texto muestran ~2ms para 5000 elementos anidados, significativamente más rápido que muchas alternativas
- Selección flexible: Selectores CSS, XPath, operaciones de búsqueda estilo BeautifulSoup y búsqueda basada en texto
- Soporte asíncrono: Soporte completo para async/await para operaciones de raspado concurrentes
Instalación
Para capacidades de análisis básicas:
bash
pip install scraplingPara funciones completas incluyendo automatización de navegadores:
bash
pip install "scrapling[fetchers]"
scrapling installPara todo incluyendo funciones de inteligencia artificial:
bash
pip install "scrapling[all]"
scrapling installUso básico
Scrapling utiliza métodos de clase para solicitudes HTTP:
python
from scrapling import Fetcher
# Solicitud GET
response = Fetcher.get("https://example.com")
# Solicitud POST con datos
response = Fetcher.post("https://example.com/api", data={"key": "value"})
# Acceder a la respuesta
print(response.status) # Código de estado HTTP
print(response.body) # Bytes sin procesar
print(response.body.decode()) # Texto decodificado¿Qué es CapSolver?
CapSolver es un servicio de resolución de captchas que utiliza inteligencia artificial avanzada para resolver automáticamente diversos tipos de captchas. Proporciona una API simple que se integra sin problemas con cualquier lenguaje de programación o marco de raspado.
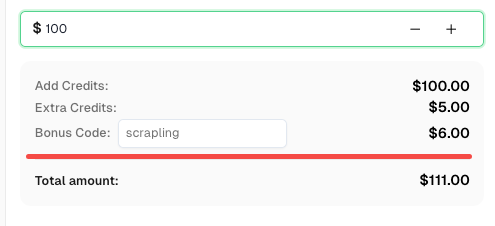
¡Aumente su presupuesto de automatización de inmediato!
Use el código de bonificación SCRAPLING al recargar su cuenta de CapSolver para obtener un 6% adicional en cada recarga — especialmente para usuarios de integración con Scrapling.
Recójalo ahora en su Tablero de CapSolver
Tipos de captcha soportados
- ReCaptcha v2 (casilla y invisible)
- ReCaptcha v3 (basado en puntuación)
- ReCaptcha Enterprise (v2 y v3)
- Cloudflare Turnstile
- AWS WAF Captcha
- Y muchos más...
Obtener su clave de API
- Regístrese en CapSolver
- Navegue hasta su tablero de control
- Copie su clave de API desde la configuración de la cuenta
- Añada fondos a su cuenta (precio por resolución)
Puntos finales de API
CapSolver utiliza dos puntos finales principales:
- Crear tarea:
POST https://api.capsolver.com/createTask - Obtener resultados:
POST https://api.capsolver.com/getTaskResult
Configuración de la función auxiliar de CapSolver
Antes de adentrarnos en tipos específicos de captchas, creemos una función auxiliar reutilizable que maneje el flujo de trabajo de la API de CapSolver:
python
import requests
import time
CAPSOLVER_API_KEY = "SU_CLAVE_DE_API"
def solve_captcha(task_type, website_url, website_key, **kwargs):
"""
Solucionador de captchas genérico usando la API de CapSolver.
Args:
task_type: El tipo de tarea de captcha (por ejemplo, "ReCaptchaV2TaskProxyLess")
website_url: La URL de la página con el captcha
website_key: La clave del sitio para el captcha
**kwargs: Parámetros adicionales específicos del tipo de captcha
Returns:
dict: La solución que contiene el token y otros datos
"""
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": task_type,
"websiteURL": website_url,
"websiteKey": website_key,
**kwargs
}
}
# Crear la tarea
response = requests.post(
"https://api.capsolver.com/createTask",
json=payload
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"Falló la creación de la tarea: {result.get('errorDescription')}")
task_id = result.get("taskId")
print(f"Tarea creada: {task_id}")
# Consultar resultados
max_attempts = 60 # Máximo 2 minutos de consulta
for attempt in range(max_attempts):
time.sleep(2)
response = requests.post(
"https://api.capsolver.com/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
)
result = response.json()
if result.get("status") == "ready":
print(f"Captcha resuelto en {(attempt + 1) * 2} segundos")
return result.get("solution")
if result.get("errorId") != 0:
raise Exception(f"Error: {result.get('errorDescription')}")
print(f"Esperando... (intentos {attempt + 1})")
raise Exception("Tiempo de espera agotado: La resolución del captcha tomó demasiado tiempo")Esta función maneja todo el flujo de trabajo: crear una tarea, consultar resultados y devolver la solución. La usaremos a lo largo de esta guía.
Resolviendo ReCaptcha v2 con Scrapling + CapSolver
ReCaptcha v2 es el clásico captcha de casilla "No soy un robot". Cuando se activa, puede pedir a los usuarios que identifiquen objetos en imágenes (semáforos, cruces de peatones, etc.). Para los raspadores, necesitamos resolverlo de forma programática.
Cómo funciona ReCaptcha v2
- El sitio web carga un script de ReCaptcha con una clave del sitio única
- Al enviar, el script genera un token g-recaptcha-response
- El sitio web envía este token a Google para verificación
- Google confirma si el captcha fue resuelto correctamente
Encontrar la clave del sitio
La clave del sitio normalmente se encuentra en el HTML de la página:
html
<div class="g-recaptcha" data-sitekey="6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABCD"></div>O en una etiqueta script:
html
<script src="https://www.google.com/recaptcha/api.js?render=6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABCD"></script>Implementación
python
from scrapling import Fetcher
def scrape_with_recaptcha_v2(target_url, site_key, form_url=None):
"""
Rascar una página protegida por ReCaptcha v2.
Args:
target_url: La URL de la página con el captcha
site_key: La clave del sitio de ReCaptcha
form_url: La URL para enviar el formulario (por defecto target_url)
Returns:
La respuesta de la página protegida
"""
# Resolver el captcha usando CapSolver
print("Resolviendo ReCaptcha v2...")
solution = solve_captcha(
task_type="ReCaptchaV2TaskProxyLess",
website_url=target_url,
website_key=site_key
)
captcha_token = solution["gRecaptchaResponse"]
print(f"Token obtenido: {captcha_token[:50]}...")
# Enviar el formulario con el token de captcha usando Scrapling
# Nota: Usar Fetcher.post() como método de clase (no como método de instancia)
submit_url = form_url or target_url
response = Fetcher.post(
submit_url,
data={
"g-recaptcha-response": captcha_token,
# Añadir cualquier otro campo del formulario requerido por el sitio web
}
)
return response
# Ejemplo de uso
if __name__ == "__main__":
url = "https://example.com/página-protegida"
site_key = "6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABCD"
result = scrape_with_recaptcha_v2(url, site_key)
print(f"Estado: {result.status}")
print(f"Longitud del contenido: {len(result.body)}") # Usar .body para los bytes sin procesarReCaptcha v2 Invisible
Para ReCaptcha v2 Invisible (sin casilla, activado al enviar el formulario), añada el parámetro isInvisible:
python
solution = solve_captcha(
task_type="ReCaptchaV2TaskProxyLess",
website_url=target_url,
website_key=site_key,
isInvisible=True
)Versión Enterprise
Para ReCaptcha v2 Enterprise, use un tipo de tarea diferente:
python
solution = solve_captcha(
task_type="ReCaptchaV2EnterpriseTaskProxyLess",
website_url=target_url,
website_key=site_key,
enterprisePayload={
"s": "valor_s_del_payload_si es necesario"
}
)Resolviendo ReCaptcha v3 con Scrapling + CapSolver
ReCaptcha v3 es diferente del v2 — funciona en segundo plano y asigna una puntuación (0.0 a 1.0) basada en la actividad del usuario. Una puntuación más cercana a 1.0 indica actividad probablemente humana.
Diferencias clave con el v2
| Aspecto | ReCaptcha v2 | ReCaptcha v3 |
|---|---|---|
| Interacción del usuario | Casilla/retos de imágenes | Ninguna (invisible) |
| Salida | Aprobado/rechazado | Puntuación (0.0-1.0) |
| Parámetro de acción | No es necesario | Es necesario |
| Cuándo usarlo | Formularios, inicios de sesión | Todos los cargamientos de página |
Encontrar el parámetro de acción
La acción se especifica en el JavaScript del sitio web:
javascript
grecaptcha.execute('6LcxxxxxxxxxxxxxxxxABCD', {action: 'submit'})Acciones comunes incluyen: submit, login, register, homepage, contact.
Implementación
python
from scrapling import Fetcher
def scrape_with_recaptcha_v3(target_url, site_key, page_action="submit", min_score=0.7):
"""
Rascar una página protegida por ReCaptcha v3.
Args:
target_url: La URL de la página con el captcha
site_key: La clave del sitio de ReCaptcha
page_action: El parámetro de acción (encontrado en grecaptcha.execute)
min_score: Puntuación mínima solicitada (0.1-0.9)
Returns:
La respuesta de la página protegida
"""
print(f"Resolviendo ReCaptcha v3 (acción: {page_action})...")
solution = solve_captcha(
task_type="ReCaptchaV3TaskProxyLess",
website_url=target_url,
website_key=site_key,
pageAction=page_action
)
captcha_token = solution["gRecaptchaResponse"]
print(f"Token obtenido con puntuación: {solution.get('score', 'N/A')}")
# Enviar la solicitud con el token usando el método de clase de Scrapling
response = Fetcher.post(
target_url,
data={
"g-recaptcha-response": captcha_token,
},
headers={
"User-Agent": solution.get("userAgent", "Mozilla/5.0")
}
)
return response
# Ejemplo de uso
if __name__ == "__main__":
url = "https://example.com/api/datos"
site_key = "6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABCD"
result = scrape_with_recaptcha_v3(url, site_key, page_action="obtenerDatos")
print(f"Respuesta: {result.body.decode()[:200]}") # Usar .body para el contenidoReCaptcha v3 Enterprise
python
solution = solve_captcha(
task_type="ReCaptchaV3EnterpriseTaskProxyLess",
website_url=target_url,
website_key=site_key,
pageAction=page_action,
enterprisePayload={
"s": "parámetro_s opcional"
}
)Resolviendo Cloudflare Turnstile con Scrapling + CapSolver
Cloudflare Turnstile es una alternativa más reciente de captcha diseñada como reemplazo "amigable para el usuario y de preservación de privacidad" de los captchas tradicionales. Está cada vez más presente en sitios web que utilizan Cloudflare.
Entendiendo Turnstile
Turnstile tiene tres modos:
- Gestionado: Muestra un widget solo cuando es necesario
- No interactivo: Se ejecuta sin interacción del usuario
- Invisible: Completamente invisible para los usuarios
La buena noticia es que CapSolver maneja los tres automáticamente.
Encontrar la clave del sitio
Busque Turnstile en el HTML de la página:
html
<div class="cf-turnstile" data-sitekey="0x4xxxxxxxxxxxxxxxxxxxxxxxxxx"></div>O en JavaScript:
javascript
turnstile.render('#container', {
sitekey: '0x4xxxxxxxxxxxxxxxxxxxxxxxxxx',
callback: function(token) { ... }
});Implementación
python
from scrapling import Fetcher
def scrape_with_turnstile(target_url, site_key, action=None, cdata=None):
"""
Rascar una página protegida por Cloudflare Turnstile.
Args:
target_url: La URL de la página con el captcha
site_key: La clave del sitio de Turnstile (comienza con 0x4...)
action: Parámetro de acción opcional
cdata: Parámetro cdata opcional
Returns:
La respuesta de la página protegida
"""
print("Resolviendo Cloudflare Turnstile...")
# Construir metadatos si se proporcionan
metadata = {}
if action:
metadata["action"] = action
if cdata:
metadata["cdata"] = cdata
task_params = {
"task_type": "AntiTurnstileTaskProxyLess",
"website_url": target_url,
"website_key": site_key,
}
if metadata:
task_params["metadata"] = metadata
solution = solve_captcha(**task_params)
turnstile_token = solution["token"]
user_agent = solution.get("userAgent", "")
print(f"Token de Turnstile obtenido: {turnstile_token[:50]}...")
# Enviar con el token usando el método de clase de Scrapling
headers = {}
if user_agent:
headers["User-Agent"] = user_agent
response = Fetcher.post(
target_url,
data={
"cf-turnstile-response": turnstile_token,
},
headers=headers
)
return response
# Ejemplo de uso
if __name__ == "__main__":
url = "https://example.com/protected"
site_key = "0x4AAAAAAAxxxxxxxxxxxxxx"
result = scrape_with_turnstile(url, site_key)
print(f"¡Éxito! Obtuve {len(result.body)} bytes") # Usa .body para el contenidoTurnstile con acción y CData
Algunas implementaciones requieren parámetros adicionales:
python
solution = solve_captcha(
task_type="AntiTurnstileTaskProxyLess",
website_url=target_url,
website_key=site_key,
metadata={
"action": "login",
"cdata": "session_id_or_custom_data"
}
)Uso de StealthyFetcher para protección mejorada contra bots
A veces las solicitudes HTTP básicas no son suficientes. Los sitios web pueden usar detección de bots sofisticada que verifica:
- Huellas dactilares del navegador
- Ejecución de JavaScript
- Movimientos del mouse y timing
- Huellas dactilares TLS
- Encabezados de solicitud
Scrapling's StealthyFetcher proporciona protección contra detección de bots a nivel de navegador utilizando un motor de navegador real con modificaciones de stealth.
¿Qué es StealthyFetcher?
StealthyFetcher utiliza un navegador Firefox modificado con:
- Huellas dactilares del navegador reales
- Capacidad para ejecutar JavaScript
- Manejo automático de desafíos de Cloudflare
- Suplantación de huellas dactilares TLS
- Gestión de cookies y sesiones
Cuándo usar StealthyFetcher
| Escenario | Usar Fetcher | Usar StealthyFetcher |
|---|---|---|
| Formularios simples con CAPTCHA | Sí | No |
| Páginas con mucho JavaScript | No | Sí |
| Múltiples capas de protección contra bots | No | Sí |
| La velocidad es crítica | Sí | No |
| Modo "Under Attack" de Cloudflare | No | Sí |
Combinar StealthyFetcher con CapSolver
Así es como se usa ambos juntos para mayor efectividad:
python
from scrapling import StealthyFetcher
import asyncio
async def scrape_with_stealth_and_recaptcha(target_url, site_key, captcha_type="v2"):
"""
Combina las funciones anti-detección de StealthyFetcher con CapSolver para ReCaptcha.
Args:
target_url: La URL a raspar
site_key: La clave del CAPTCHA
captcha_type: "v2" o "v3"
Returns:
El contenido de la página después de resolver el CAPTCHA
"""
# Primero, resolver el CAPTCHA usando CapSolver
print(f"Resolviendo ReCaptcha {captcha_type}...")
if captcha_type == "v2":
solution = solve_captcha(
task_type="ReCaptchaV2TaskProxyLess",
website_url=target_url,
website_key=site_key
)
token = solution["gRecaptchaResponse"]
elif captcha_type == "v3":
solution = solve_captcha(
task_type="ReCaptchaV3TaskProxyLess",
website_url=target_url,
website_key=site_key,
pageAction="submit"
)
token = solution["gRecaptchaResponse"]
else:
raise ValueError(f"Tipo de CAPTCHA desconocido: {captcha_type}")
print(f"Obtuve token: {token[:50]}...")
# Usar StealthyFetcher para comportamiento de navegador
fetcher = StealthyFetcher()
# Navegar a la página
page = await fetcher.async_fetch(target_url)
# Inyectar la solución de ReCaptcha usando JavaScript
await page.page.evaluate(f'''() => {{
// Encontrar el campo g-recaptcha-response y establecer su valor
let field = document.querySelector('textarea[name="g-recaptcha-response"]');
if (!field) {{
field = document.createElement('textarea');
field.name = "g-recaptcha-response";
field.style.display = "none";
document.body.appendChild(field);
}}
field.value = "{token}";
}}''')
# Encontrar y hacer clic en el botón de envío
submit_button = page.css('button[type="submit"], input[type="submit"]')
if submit_button:
await submit_button[0].click()
# Esperar a que se cargue
await page.page.wait_for_load_state('networkidle')
# Obtener el contenido final de la página
content = await page.page.content()
return content
# Envoltura sincrónica para un uso más fácil
def scrape_stealth(target_url, site_key, captcha_type="v2"):
"""Envoltura sincrónica para el raspador asincrónico."""
return asyncio.run(
scrape_with_stealth_and_recaptcha(target_url, site_key, captcha_type)
)
# Ejemplo de uso
if __name__ == "__main__":
url = "https://example.com/página-altamente-protegida"
site_key = "6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABCD"
content = scrape_stealth(url, site_key, captcha_type="v2")
print(f"Obtuve {len(content)} bytes de contenido")Ejemplo completo: Raspado de múltiples páginas con sesión
python
from scrapling import StealthyFetcher
import asyncio
class StealthScraper:
"""Un raspador que mantiene la sesión entre múltiples páginas."""
def __init__(self, api_key):
self.api_key = api_key
self.fetcher = None
async def __aenter__(self):
self.fetcher = StealthyFetcher()
return self
async def __aexit__(self, *args):
if self.fetcher:
await self.fetcher.close()
async def solve_and_access(self, url, site_key, captcha_type="v2"):
"""Resolver CAPTCHA y acceder a la página."""
global CAPSOLVER_API_KEY
CAPSOLVER_API_KEY = self.api_key
# Resolver el CAPTCHA
task_type = f"ReCaptcha{captcha_type.upper()}TaskProxyLess"
solution = solve_captcha(
task_type=task_type,
website_url=url,
website_key=site_key
)
token = solution["gRecaptchaResponse"]
# Navegar e inyectar token
page = await self.fetcher.async_fetch(url)
# ... continuar con la interacción en la página
return page
# Uso
async def main():
async with StealthScraper("su_api_key") as scraper:
page1 = await scraper.solve_and_access(
"https://example.com/iniciar-sesión",
"site_key_aquí",
"v2"
)
# La sesión se mantiene para solicitudes posteriores
page2 = await scraper.solve_and_access(
"https://example.com/tablero",
"otra_site_key",
"v3"
)
asyncio.run(main())Mejores prácticas y consejos
1. Límites de velocidad
No golpees los sitios web con solicitudes. Implementa retrasos entre solicitudes:
python
import time
import random
def raspado-respetuoso(urls, min_delay=2, max_delay=5):
"""Raspar con retrasos aleatorios para parecer más humano."""
results = []
for url in urls:
result = scrape_page(url)
results.append(result)
# Retraso aleatorio entre solicitudes
delay = random.uniform(min_delay, max_delay)
time.sleep(delay)
return results2. Manejo de errores
Siempre maneja las fallas de manera elegante:
python
def resolver_captcha-de-forma-robusta(task_type, website_url, website_key, max_retries=3, **kwargs):
"""Resolver CAPTCHA con reintentos automáticos."""
for attempt in range(max_retries):
try:
return solve_captcha(task_type, website_url, website_key, **kwargs)
except Exception as e:
print(f"Intento {attempt + 1} falló: {e}")
if attempt < max_retries - 1:
time.sleep(5) # Esperar antes del reintent
else:
raise3. Respetar robots.txt
Verifica el robots.txt del sitio antes de raspar:
python
from urllib.robotparser import RobotFileParser
def permitir_raspar(url):
"""Verificar si el raspo es permitido por robots.txt."""
rp = RobotFileParser()
rp.set_url(f"{url}/robots.txt")
rp.read()
return rp.can_fetch("*", url)4. Usar proxies para escalar
Al raspar a gran escala, rota los proxies para evitar bloqueos de IP:
python
# CapSolver soporta tareas con proxies
solution = solve_captcha(
task_type="ReCaptchaV2Task", # Nota: sin "ProxyLess"
website_url=target_url,
website_key=site_key,
proxy="http://user:pass@proxy.example.com:8080"
)5. Almacenar en caché las soluciones cuando sea posible
Los tokens de CAPTCHA suelen ser válidos por 1-2 minutos. Si necesitas hacer múltiples solicitudes, reutiliza el token:
python
import time
class Caché-de-CAPTCHAs:
def __init__(self, ttl=120): # TTL predeterminado de 2 minutos
self.cache = {}
self.ttl = ttl
def get_or_solve(self, key, solve_func):
"""Obtener token en caché o resolver uno nuevo."""
if key in self.cache:
token, timestamp = self.cache[key]
if time.time() - timestamp < self.ttl:
return token
token = solve_func()
self.cache[key] = (token, time.time())
return tokenTabla de comparación de tipos de CAPTCHA
| Característica | ReCaptcha v2 | ReCaptcha v3 | Turnstile de Cloudflare |
|---|---|---|---|
| Interacción del usuario | Casilla + posible desafío | Ninguna | Mínima o ninguna |
| Formato de clave del sitio | 6L... |
6L... |
0x4... |
| Campo de respuesta | g-recaptcha-response |
g-recaptcha-response |
cf-turnstile-response |
| Parámetro de acción | No | Sí (requerido) | Opcional |
| Tiempo de resolución | 1-10 segundos | 1-10 segundos | 1-20 segundos |
| Tarea de CapSolver | ReCaptchaV2TaskProxyLess |
ReCaptchaV3TaskProxyLess |
AntiTurnstileTaskProxyLess |
Tabla de comparación de Fetchers de Scrapling
| Característica | Fetcher | StealthyFetcher |
|---|---|---|
| Velocidad | Muy rápida | Más lenta |
| Soporte de JavaScript | No | Sí |
| Huella dactilar del navegador | Ninguna | Firefox real |
| Uso de memoria | Bajo | Alto |
| Bypass de Cloudflare | No | Sí |
| Ideal para | Solicitudes simples | Anti-bot complejo |
Preguntas frecuentes
P: ¿Cuánto cuesta CapSolver?
Consulta la página de precios de CapSolver para las tarifas actuales.
P: ¿Cómo encuentro la clave del sitio en una página web?
Busca en el código fuente de la página (Ctrl+U) por:
- Atributo
data-sitekey - Llamadas JavaScript
grecaptcha.execute - Parámetro
render=en URLs de scripts de ReCaptcha class="cf-turnstile"para Turnstile
P: ¿Qué pasa si el token de CAPTCHA expira antes de usarlo?
Los tokens suelen expirar después de 1-2 minutos. Resuelve el CAPTCHA lo más cerca posible de la presentación del formulario. Si obtienes errores de validación, resuélvelo de nuevo con un token fresco.
P: ¿Puedo usar CapSolver con código asincrónico?
Sí! Envuelve la función de resolución en un ejecutor asincrónico:
python
import asyncio
async def async_solve_captcha(*args, **kwargs):
loop = asyncio.get_event_loop()
return await loop.run_in_executor(
None,
lambda: solve_captcha(*args, **kwargs)
)P: ¿Cómo manejar múltiples ReCaptchas en una sola página?
Resuelve cada CAPTCHA por separado e incluye todos los tokens en tu envío:
python
# Resolver múltiples ReCaptchas
solution_v2 = solve_captcha("ReCaptchaV2TaskProxyLess", url, key1)
solution_v3 = solve_captcha("ReCaptchaV3TaskProxyLess", url, key2, pageAction="submit")
# Enviar con tokens usando el método de la clase Scrapling
response = Fetcher.post(url, data={
"g-recaptcha-response": solution_v2["gRecaptchaResponse"],
"g-recaptcha-response-v3": solution_v3["gRecaptchaResponse"],
})Conclusión
Combinar Scrapling y CapSolver proporciona una solución poderosa para raspar sitios web protegidos con CAPTCHA. Aquí está un resumen rápido:
- Usar Fetcher de Scrapling para solicitudes simples donde importa la velocidad
- Usar StealthyFetcher cuando enfrentes sistemas anti-bot sofisticados
- Usar CapSolver para resolver ReCaptcha v2, v3 y Turnstile de Cloudflare
- Implementar mejores prácticas como límites de velocidad, manejo de errores y rotación de proxies
Recuerda siempre raspar de manera responsable:
- Respetar los términos de servicio del sitio web
- No sobrecargar los servidores con solicitudes
- Usar los datos éticamente
- Considera contactar a los dueños del sitio para acceso a API
¿Listo para comenzar a raspar? Consigue tu clave de API de CapSolver en capsolver.com e instala Scrapling con pip install "scrapling[all]".
Ver más
Web ScrapingApr 22, 2026
Arquitectura de raspado de web para extracción de datos escalable
Aprende una arquitectura de raspado web escalable en Rust con reqwest, scraper, raspado asíncrono, raspado con navegador sin cabeza, rotación de proxies y manejo de CAPTCHA conforme.

Web ScrapingFeb 17, 2026
Cómo resolver Captcha en Nanobot con CapSolver
Automatiza la resolución de CAPTCHA con Nanobot y CapSolver. Utiliza Playwright para resolver reCAPTCHA y Cloudflare autónomamente.


