Mejor elección de web scraping vs API para equipos de automatización

Aloísio Vítor
Image Processing Expert
TL;DR
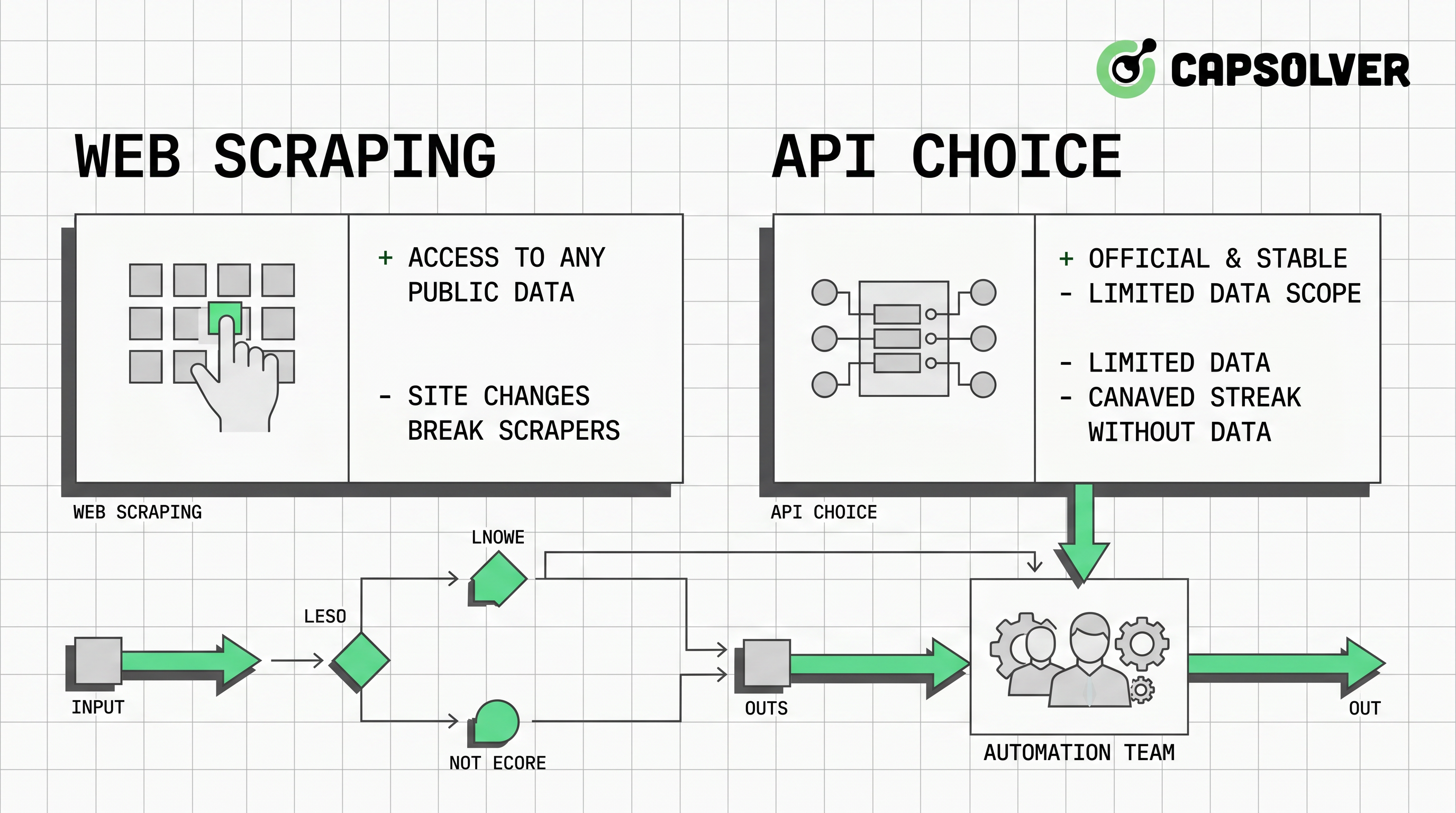
- Las decisiones de raspado web frente a API deben comenzar con los derechos de datos, la disponibilidad de la fuente, los requisitos de confiabilidad y los costos de mantenimiento.
- Las APIs suelen ser mejores para sistemas de producción gobernados porque los esquemas, los límites de tasa, la autenticación y la versionación son más fáciles de documentar.
- El raspado web es útil cuando los datos públicos permitidos no tienen una API adecuada, pero requiere revisar robots.txt, controlar la tasa, monitorear cambios en las páginas y verificar el cumplimiento.
- La automatización del navegador agrega valor para páginas dinámicas, y CapSolver puede ayudar a los flujos aprobados a manejar desafíos de CAPTCHA o validación de tráfico cuando aparezcan.
- La arquitectura más resistente utiliza primero APIs, luego raspado, solo automatización del navegador cuando sea necesario, y la resolución de CAPTCHA como un camino de excepción controlado.
Introducción
Las mejores elecciones entre raspado web y API rara vez se tratan de qué método es más poderoso. Se trata de qué método es más confiable, permitido, mantenible y auditable para los datos que necesita su equipo. Las APIs suelen ser la primera opción cuando proporcionan los campos necesarios, la frescura y los términos adecuados. El raspado web se vuelve útil cuando las páginas públicas permitidas son la única fuente práctica o cuando los equipos necesitan monitorear cambios en la capa de presentación. Si un flujo de raspado o automatización del navegador aprobado se encuentra con un desafío de CAPTCHA, la guía de CapSolver para resolución de CAPTCHA durante el raspado puede proporcionar un camino de resolución documentado que se integre en un proceso de automatización más amplio.
Priorizar APIs como decisión predeterminada
Las APIs suelen ser la elección predeterminada porque expresan un contrato respaldado por el proveedor. Una API bien diseñada ofrece a los equipos campos predecibles, autenticación, límites de tasa, códigos de error y versionado. Estas propiedades hacen que las revisiones de ingeniería sean más fáciles y reduzcan la necesidad de parsing frágil. Las APIs también simplifican la trazabilidad de los datos porque cada registro puede vincularse a un punto final, una marca de tiempo, un ID de solicitud o un esquema documentado.
El tutorial y referencia de API REST explica ideas comunes de diseño de API como recursos, métodos y representaciones. El documentación de límites de tasa de la API REST de GitHub muestra por qué los límites de tasa no son un obstáculo, sino un contrato operativo. En muchos programas de automatización, una API oficial más lenta es mejor que un raspador más rápido porque la API es más fácil de defender en auditorías y más fácil de mantener cuando crecen los consumidores de datos.
| Factor de decisión | Ventaja de API | Ventaja de raspado web |
|---|---|---|
| Contrato de datos | Esquemas estables y errores documentados | Puede recopilar campos visibles no expuestos por un punto final |
| Mantenimiento | Versionado y canales de soporte | Funciona cuando no existe una API adecuada |
| Frescura | Sondeos predecibles y límites de tasa | Puede reflejar actualizaciones a nivel de página rápidamente |
| Páginas dinámicas | Menor sobrecarga del navegador | La automatización del navegador puede inspeccionar estados renderizados |
| Eventos de desafío | Normalmente evitados | Puede requerir flujos de resolución de CAPTCHA controlados |
La clave no es rechazar el raspado. La clave es demostrar que el raspado es necesario antes de agregar complejidad operativa.
Cuándo el raspado web es la mejor opción
El raspado web es la mejor opción cuando los datos son públicos, permitidos, no están disponibles a través de una API adecuada y son lo suficientemente valiosos como para justificar su monitoreo. Ejemplos comunes incluyen páginas de precios públicas, páginas de disponibilidad de productos, listados de empleos públicos, directorios públicos y monitoreo de cambios en sitios web. Incluso entonces, el equipo debe documentar los campos de datos, las páginas de origen, la frecuencia de rastreo, las reglas de exclusión y al responsable del flujo de trabajo.
El Protocolo de Exclusión de Robots RFC 9309 define cómo los sitios web pueden comunicar reglas de rastreo a clientes automatizados. La referencia de URL de MDN es útil para la normalización de URLs, que es un requisito básico para deduplicación y límites de rastreo. Estas referencias respaldan una regla práctica: el raspado web debe tratarse como un sistema de ingeniería con permisos y límites, no como un script informal.
El raspado web también se beneficia de un diseño en capas. Las páginas estáticas pueden manejarse con solicitudes HTTP y analizadores. Las páginas con mucho JavaScript pueden requerir automatización del navegador. Las páginas con validación de tráfico pueden necesitar una política documentada para manejar desafíos. La guía de integración de CapSolver con Playwright es útil cuando la capa de automatización necesita tanto extracción como manejo controlado de desafíos.
Dónde pertenece la resolución de CAPTCHA en la decisión
La resolución de CAPTCHA pertenece al final del árbol de decisiones de mejor raspado web frente a API. Si existe una API y cumple con los requisitos, úsela. Si se puede recopilar la página pública mediante extracción estática permitida, úsela. Si es necesario automatizar el navegador, agregue controles de renderizado e interacción. Solo después de tomar esas decisiones, el equipo debe decidir cómo manejar un desafío de CAPTCHA o validación de tráfico apoyado.
La glosario de reCAPTCHA de CapSolver y la guía de terminología de CAPTCHA ayudan a los equipos a identificar familias comunes de desafíos antes de elegir un camino de resolución. La decisión debe incluir el alcance de aprobación, los dominios admitidos, los límites de reintentos, el registro de logs, la política de proxies y una verificación a nivel de página. Una resolución de desafío no es suficiente; el flujo de trabajo debe confirmar que la tarea aprobada se completó correctamente.
Código adicional para pilotos de automatización de datos aprobados
Canjear su código de bonificación de CapSolver
Aumente instantáneamente su presupuesto de automatización!
Use el código de bonificación CAP26 al recargar su cuenta de CapSolver para obtener un 5% adicional en cada recarga — sin límites.
Canjéalo ahora en su Panel de CapSolver
Patrones de arquitectura para equipos de automatización
Una arquitectura sólida separa el método de acceso, la ejecución, la validación y el gobierno. El método de acceso puede ser una API, un raspador estático, un script de automatización del navegador o un flujo híbrido. La ejecución debe aplicar límites de tasa, reintentos y condiciones de parada seguras. La validación debe comparar la cantidad de registros, los campos necesarios, las marcas de tiempo de origen y los cambios en el esquema. El gobierno debe registrar quién aprobó la fuente, qué datos están permitidos y cuándo debe revisarse nuevamente el flujo de trabajo.
Para flujos de trabajo con muchos navegadores, la documentación de Playwright proporciona un punto de partida práctico para el renderizado y la interacción controlados de páginas. Para flujos de trabajo con muchos rastreadores, la documentación de Scrapy explica arañas, elementos e hilos. Para flujos de trabajo aprobados con muchos desafíos, la guía de extensión de CapSolver puede ayudar a los ingenieros a diagnosticar el comportamiento real de la página antes de diseñar un camino repetible basado en API.
| Patrón de arquitectura | Úselo cuando | Agregue este control |
|---|---|---|
| Solo API | Los campos requeridos están disponibles y los términos lo permiten | Monitoreo de puntos finales y manejo de límites de tasa |
| Raspado estático | Las páginas públicas son estables y permitidas | Revisión de robots.txt y pruebas de selectores |
| Automatización del navegador | Se requiere renderizado o interacción | Presupuestos de tiempo de espera y validación de estado de página |
| Híbrido API más raspado | La API cubre la mayoría de los campos, pero las páginas añaden contexto | Reglas de fuente de verdad y deduplicación |
| Raspado más CapSolver | Las páginas aprobadas presentan desafíos de CAPTCHA | Boletos de aprobación, registros redactados y límites de reintentos |
Esta estructura hace transparente la mejor elección entre raspado web y API. También reduce el riesgo de que los equipos agreguen automatización del navegador o resolución de CAPTCHA antes de probar que métodos más simples no puedan cumplir con el requisito del negocio.
Lista de verificación para uso responsable
Un programa de automatización responsable comienza con una revisión de la fuente. Confirme que los datos son públicos u otros autorizados, que el propósito de la recolección es legítimo y que los datos personales sensibles o restringidos están fuera del alcance, a menos que exista una base legal y controles de seguridad. Luego revise robots.txt, términos del sitio, documentación de API y obligaciones contractuales. Finalmente, pruebe con volumen bajo y haga que el flujo de trabajo se detenga ante paredes de inicio de sesión inesperadas, cambios de permisos, picos de desafíos o desviación de esquema.
El Proyecto de Amenazas Automatizadas de OWASP es un recordatorio útil de que las mismas técnicas de automatización pueden ser mal utilizadas. Su estándar interno debe requerir permiso, tasas de solicitud proporcionales, identificación clara cuando sea apropiado y revisión humana cuando cambie un flujo de trabajo. CapSolver debe usarse solo para objetivos propios, en fase de prueba, aprobados por el cliente u otros permitidos donde el manejo de desafíos sea parte de un proceso de automatización legítimo.
Conclusión
Las mejores decisiones entre raspado web y API deben tomarse con una jerarquía simple: usar una API cuando cumpla con el requisito, usar raspado estático permitido cuando no lo haga, usar automatización del navegador cuando sea necesario el renderizado y agregar resolución de CAPTCHA solo como un camino de excepción documentado. Para equipos que necesiten manejo de desafíos confiable en automatización aprobada, la guía legal de raspado web de CapSolver puede ayudar a integrar la resolución dentro de un flujo de trabajo gobernado junto con APIs, rastreadores, automatización del navegador, monitoreo y revisión de cumplimiento.
Preguntas frecuentes
¿Cuál es la regla mejor para el raspado web frente a API?
La mejor regla es priorizar las APIs. Usar una API cuando proporcione los datos bajo términos aceptables, y usar el raspado solo cuando las páginas permitidas sean la fuente práctica.
¿Cuándo es mejor el raspado web que una API?
El raspado web es mejor cuando los datos de páginas públicas permitidas no están disponibles a través de una API adecuada, o cuando la presentación de la página en sí misma es los datos que su equipo necesita monitorear.
¿Cuándo debe agregarse la automatización del navegador?
Agregue la automatización del navegador solo cuando la extracción HTTP estática no pueda capturar contenido renderizado, interacciones del usuario o datos posteriores a la carga necesarios para el flujo de trabajo aprobado.
¿Cómo se integra CapSolver en flujos de raspado web frente a API?
CapSolver se integra cuando un flujo de raspado web o automatización del navegador aprobado se encuentra con un desafío de CAPTCHA o validación de tráfico admitido y necesita un camino de resolución documentado.
¿Qué deben verificar los equipos antes de raspar?
Los equipos deben verificar el permiso, robots.txt, términos, sensibilidad de datos, tasa de solicitud y reglas de monitoreo. También pueden revisar la Preguntas frecuentes de raspado web de CapSolver cuando el manejo de desafíos sea parte del plan aprobado.
Ver más
Web ScrapingApr 22, 2026
Arquitectura de raspado de web para extracción de datos escalable
Aprende una arquitectura de raspado web escalable en Rust con reqwest, scraper, raspado asíncrono, raspado con navegador sin cabeza, rotación de proxies y manejo de CAPTCHA conforme.
Web ScrapingFeb 17, 2026
Cómo resolver Captcha en Nanobot con CapSolver
Automatiza la resolución de CAPTCHA con Nanobot y CapSolver. Utiliza Playwright para resolver reCAPTCHA y Cloudflare autónomamente.


