¿Qué es el scraping con IA? Definición, Beneficios, Casos de uso.

Sora Fujimoto
AI Solutions Architect

TL;DR:
- Scraping con IA utiliza aprendizaje automático y procesamiento del lenguaje natural (NLP) para automatizar la extracción de datos, superando la fragilidad de los métodos basados en reglas tradicionales.
- Destaca en el manejo de datos no estructurados, evadir medidas anti-bot complejas y adaptarse a los cambios en el diseño de los sitios web sin actualizaciones manuales.
- Los beneficios clave incluyen una precisión del 99,5% en la extracción, reducción de costos de mantenimiento y la capacidad de transformar contenido web crudo en conocimiento accionable.
- Integrar herramientas especializadas como CapSolver es esencial para resolver CAPTCHAs avanzados (reCAPTCHA, Cloudflare) en flujos de trabajo modernos de scraping con IA.
Introducción
El paisaje digital está evolucionando a un ritmo sin precedentes, y los métodos que utilizamos para recopilar información deben mantenerse al día. El scraping con IA representa la siguiente generación de recolección de datos, avanzando más allá de simples scripts hacia sistemas inteligentes que comprenden el web como lo haría un humano. Para las empresas en 2026, la capacidad de extraer datos de alta calidad a gran escala ya no es un lujo, sino una necesidad competitiva fundamental. Este artículo explora cómo la extracción impulsada por IA está reemplazando a los métodos tradicionales, los mecanismos técnicos detrás de su éxito y cómo puedes crear un Agente de Scraping Web para mantenerse a la vanguardia. Ya sea que seas un científico de datos o un líder empresarial, comprender este cambio es vital para navegar en el futuro de la economía de los datos.
¿Qué es el Scraping con IA?
El scraping con IA es el proceso de utilizar inteligencia artificial, específicamente aprendizaje automático (ML) y procesamiento del lenguaje natural (NLP), para extraer datos automáticamente de fuentes digitales. A diferencia del scraping web tradicional, que depende de selectores CSS o expresiones XPath fijas, el scraping con IA interpreta el contexto visual y textual de una página. Esto le permite identificar un "precio" o un "autor", independientemente de cómo esté estructurado el HTML subyacente.
El mercado global de scraping web se proyecta alcanzar 12.34 mil millones de dólares para 2025, según informes recientes de Market Growth Reports. Este crecimiento está impulsado principalmente por la demanda de datos de alta calidad para entrenar modelos de lenguaje a gran escala (LLM). El scraping con IA no solo recopila datos, sino que también recopila conocimiento al comprender las relaciones entre entidades, realizar análisis de sentimiento y limpiar datos en tiempo real.
¿Cómo funciona el Scraping con IA?
La mecánica de la extracción con IA implica un enfoque multifuncional sofisticado que imita el comportamiento de navegación humano mientras aprovecha la gran potencia computacional.
| Capa | Funcionalidad | Tecnologías clave |
|---|---|---|
| Adquisición de datos | Navega por sitios web, maneja JavaScript y gestiona proxies. | Playwright, Puppeteer, Chrome sin interfaz gráfica |
| Interpretación | Identifica campos relevantes (títulos, precios, reseñas) usando contexto. | LLMs (GPT-4, Claude), Visión por computadora |
| Adaptabilidad | Se autocurará cuando los diseños cambien al reasignar puntos de datos. | Aprendizaje por refuerzo, Reconocimiento de patrones |
| Capa de navegación de seguridad | Resuelve desafíos de seguridad como CAPTCHAs y límites de velocidad. | CapSolver, Fingerprinting de navegadores impulsado por IA |
En un flujo de trabajo típico, un agente de IA recibe un comando en lenguaje natural. Luego navega hasta la URL objetivo, utiliza visión por computadora para "ver" el diseño de la página y emplea NLP para extraer información específica. Si se encuentra con un obstáculo, puede combinar navegadores de IA con solucionadores de CAPTCHA para mantener un flujo ininterrumpido de datos.
Scraping con IA vs. Scraping web tradicional
La transición de los métodos tradicionales a los impulsados por IA a menudo se compara con pasar de una línea de ensamblaje rígida a un sistema robótico flexible.
El scraping tradicional se basa en "si-entonces". Si un desarrollador le dice al script que busque un precio en una etiqueta específica <div>, y el propietario del sitio web cambia esa etiqueta a <span>, el scraper deja de funcionar. Esto conlleva altos costos de mantenimiento y frecuentes tiempos de inactividad.
Sin embargo, el scraping con IA utiliza comprensión semántica. Sabe que un signo de dólar seguido de un número es probablemente un precio, independientemente de la etiqueta HTML utilizada. Esta resiliencia es la razón por la que las herramientas impulsadas por IA están experimentando un aumento del 30-40% en la velocidad de extracción en comparación con la configuración manual, según el informe de tendencias de Scrapingdog de 2025.
Resumen de comparación
| Característica | Scraping web tradicional | Scraping con IA |
|---|---|---|
| Base de lógica | Reglas codificadas (CSS/XPath) | Comprensión semántica y visual |
| Mantenimiento | Alto (se rompe con cambios en el diseño) | Bajo (capacidad de autocuración) |
| Calidad de los datos | Requiere limpieza manual | Normalización y limpieza automatizadas |
| Complejidad | Tienen dificultades con datos dinámicos o no estructurados | Excelen en imágenes, PDF y sitios con JavaScript intensivo |
| Tasa de éxito | Moderada (se bloquea fácilmente) | Alta (simula el comportamiento humano) |
Ventajas principales del Scraping con IA
Implementar la IA en tu cadena de datos ofrece varias ventajas transformadoras que van más allá de la simple automatización.
- Resiliencia sin precedentes: Los scrapers con IA pueden adaptarse a actualizaciones menores de los sitios web sin intervención humana. Esta propiedad de "autocuración" asegura que tus flujos de datos permanezcan estables incluso cuando los sitios objetivo tengan frecuentes rediseños.
- Manejo de datos no estructurados: La mayor parte de la información valiosa en la web es no estructurada: piensa en comentarios en redes sociales, publicaciones en foros o transcripciones de videos. La IA puede dominar el MCP (Protocolo de Contexto del Modelo) para transmitir esta información cruda directamente a herramientas analíticas.
- Superior capacidad para evadir anti-bot: Los sitios web modernos utilizan análisis de comportamiento avanzado para bloquear bots. Los scrapers con IA pueden simular movimientos del ratón humanos, velocidades de escritura y patrones de navegación. Cuando se enfrentan a un desafío, pueden integrar resolución de CAPTCHA en tu flujo de trabajo de scraping con IA usando servicios como CapSolver para garantizar disponibilidad las 24 horas del día, los 7 días de la semana.
- Eficiencia de costos a gran escala: Aunque la configuración inicial de un sistema de IA puede ser más alta, los ahorros a largo plazo en horas de desarrolladores dedicadas a arreglar scrapers rotos son significativos.
Casos de uso comunes para el Scraping con IA
El scraping con IA se está utilizando en diversos sectores para impulsar innovación y eficiencia. La versatilidad de la extracción inteligente permite a las organizaciones abordar desafíos de datos que antes eran insuperables.
Inteligencia de comercio electrónico y precios dinámicos
En el mundo hipercompetitivo del comercio electrónico en línea, los precios cambian por minuto. El scraping con IA permite a los minoristas monitorear precios de competidores, niveles de inventario y sentimiento de los clientes en miles de tiendas globales en tiempo real. Más allá del simple seguimiento de precios, la IA puede analizar descripciones de productos e imágenes para garantizar que las comparaciones sean precisas, incluso cuando los competidores utilicen convenciones de nombres diferentes. Esta precisión permite estrategias de precios dinámicos que pueden aumentar significativamente los márgenes de beneficio.
Datos de entrenamiento de IA de alta fidelidad
La actual revolución de la IA está impulsada por datos. Recopilar conjuntos de datos masivos para entrenar la próxima generación de modelos de lenguaje a gran escala (GML) requiere datos de alta fidelidad que solo puede proporcionar la extracción impulsada por IA. Los scrapers tradicionales suelen introducir "ruido" en los conjuntos de datos al no filtrar contenido irrelevante. Los scrapers con IA, sin embargo, pueden distinguir entre el contenido principal de un artículo y los anuncios o enlaces de navegación circundantes, asegurando que los datos de entrenamiento sean limpios y contextualmente relevantes.
Análisis de mercados financieros y datos alternativos
Los fondos de hedge y las instituciones financieras se están volviendo cada vez más dependientes de datos alternativos para obtener una ventaja. Esto incluye el scraping de sitios de noticias, documentos regulatorios, tendencias en redes sociales e incluso datos de imágenes satelitales representados en tablas. El scraping con IA puede procesar estas fuentes diversas simultáneamente, identificando tendencias emergentes en los mercados antes de que lleguen a lo mainstream. Al realizar análisis de sentimiento en tiempo real sobre noticias financieras, los agentes de IA pueden proporcionar a los operadores insights accionables en segundos.
Inmobiliario y generación de clientes potenciales
La industria inmobiliaria depende en gran medida de listados actualizados de múltiples plataformas. El scraping con IA puede agrupar estos listados, normalizar los datos (por ejemplo, convertir pies cuadrados o monedas) e identificar propiedades subvaloradas automáticamente. De manera similar, para ventas B2B, la IA puede identificar y calificar clientes potenciales de redes profesionales y directorios de empresas al analizar títulos de empleo, patrones de crecimiento de la empresa y menciones recientes en noticias, creando una canalización de ventas altamente enfocada.
Implementación técnica: Construir una cadena de datos resistente
Para aprovechar realmente el scraping con IA, es necesario comprender la arquitectura de una cadena de datos resistente. Comienza con elegir el entorno adecuado. Los desarrolladores modernos suelen preferir soluciones contenerizadas que puedan escalar horizontalmente a medida que aumenta el volumen de URLs objetivo.
El papel de los navegadores headless
Herramientas como Playwright y Puppeteer son los trabajadores de la capa de adquisición. Permiten a los agentes de IA interactuar con sitios web como lo haría un humano: hacer clic en botones, desplazarse por feeds infinitos y esperar a que JavaScript asincrónico se cargue. Sin embargo, ejecutar estos navegadores a gran escala es intensivo en recursos. La optimización de IA puede ayudar determinando qué páginas requieren una renderización completa del navegador y cuáles pueden ser obtenidas mediante solicitudes HTTP más rápidas y ligeras.
Integrar inteligencia en el borde
Las configuraciones más avanzadas de scraping con IA realizan la extracción y limpieza de datos "en el borde". Esto significa que en lugar de enviar HTML crudo a un servidor central para su procesamiento, el agente de IA realiza la extracción localmente. Esto reduce la latencia y los costos de ancho de banda. Al usar LLMs ligeros o modelos especializados de NLP, estos agentes pueden entregar datos estructurados en formato JSON directamente desde el entorno del navegador.
Gestionar desafíos de seguridad
Como se mencionó anteriormente, la "Capa de navegación de seguridad" es crítica. Una cadena de datos es tan fuerte como su eslabón más débil. Si tu agente de IA es bloqueado por un desafío de Cloudflare, todo el flujo de trabajo se detiene. Por eso, una integración sólida con un servicio como CapSolver es ineludible. Proporciona los "credenciales" necesarios para que tu agente de IA pase por los puntos de control de seguridad sin activar alarmas. Las mejores prácticas incluyen rotar agentes de usuario, gestionar cookies de sesión de manera inteligente y usar proxies de vivienda de alta calidad para ocultar la huella del scraper.
Superar obstáculos de seguridad con CapSolver
Una de las mayores barreras en el scraping con IA es la creciente sofisticación de las defensas anti-bot. Los sitios web ahora utilizan reCAPTCHA v3, Cloudflare Turnstile y AWS WAF para proteger sus datos. Es aquí donde una solución especializada como CapSolver se vuelve indispensable. Al proporcionar una API impulsada por IA que resuelve estos desafíos en milisegundos, CapSolver permite que tus scrapers de IA se enfoquen en lo que hacen mejor: extraer valor. Integrar IA-LLM para resolver CAPTCHA asegura que tus agentes automatizados nunca se queden atrapados detrás de un muro de "Verifica que eres humano".
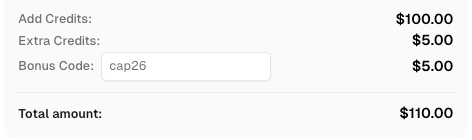
Utilice el código
CAP26al registrarse en CapSolver para recibir créditos adicionales!
Conclusión
El scraping con IA no es solo una tendencia; es la evolución inevitable de cómo interactuamos con los datos web. Al combinar la potencia semántica de los GML con la fiabilidad de herramientas como CapSolver, las organizaciones pueden construir canales de datos más rápidos, inteligentes y resistentes que nunca. A medida que avanzamos más en 2026, la brecha entre quienes utilizan scripts tradicionales y quienes aprovechan la IA solo se ampliará. Es hora de actualizar tu infraestructura y abrazar el futuro de la extracción de datos inteligente.
Preguntas frecuentes
1. ¿Es legal el scraping con IA?
El scraping web es generalmente legal para datos disponibles públicamente, pero debe cumplir con los Términos de Servicio del sitio web y leyes de privacidad de datos como el RGPD. Sentencias recientes, como el caso de Meta vs. Bright Data 2024, subrayan la importancia de respetar las restricciones contractuales.
2. ¿Cómo maneja el scraping con IA los CAPTCHA?
Los scrapers con IA suelen integrarse con APIs de terceros como CapSolver, que utilizan modelos de aprendizaje automático para resolver desafíos complejos como reCAPTCHA y Cloudflare Turnstile de forma automática.
3. ¿Necesito ser programador para usar el scraping con IA?
Aunque un conocimiento técnico ayuda, muchas herramientas modernas de scraping con IA ofrecen interfaces sin código o de bajo código donde puedes describir tus requisitos en inglés cotidiano.
4. ¿Cuál es la diferencia principal entre un rastreador y un scraper?
Un rastreador (como Googlebot) navega por la web para indexar páginas, mientras que un scraper extrae puntos de datos específicos de esas páginas. La IA mejora ambos al hacer que la navegación y la extracción sean más "como las de un humano".
5. ¿Puede el scraping con IA manejar imágenes y PDF?
Sí, los scrapers con IA utilizan visión por computadora y OCR (Reconocimiento Óptico de Caracteres) para extraer texto y datos de formatos no textuales, algo que los scrapers tradicionales no pueden hacer.
Ver más
Web ScrapingApr 22, 2026
Arquitectura de raspado de web para extracción de datos escalable
Aprende una arquitectura de raspado web escalable en Rust con reqwest, scraper, raspado asíncrono, raspado con navegador sin cabeza, rotación de proxies y manejo de CAPTCHA conforme.

Web ScrapingFeb 17, 2026
Cómo resolver Captcha en Nanobot con CapSolver
Automatiza la resolución de CAPTCHA con Nanobot y CapSolver. Utiliza Playwright para resolver reCAPTCHA y Cloudflare autónomamente.

