Cómo manejar los bloqueos de scraping web: Métodos prácticos que funcionan

Ethan Collins
Pattern Recognition Specialist

TL;Dr:
- Entender el mecanismo: Los sitios web utilizan seguimiento de IP, fingerprinting de navegador y análisis de comportamiento para identificar y bloquear scripts automatizados.
- Implementar rotación: Utilice proxies residenciales rotatorios y cadenas de User-Agent diversas para imitar patrones de tráfico humanos.
- Manejar desafíos: Integre herramientas especializadas para resolver CAPTCHAs y gestionar eficientemente sistemas complejos de detección de bots.
- Mantenerse ético: Siempre siga las pautas de robots.txt e implemente la limitación de solicitudes para mantener un bajo impacto en los servidores objetivo.
Introducción
El scraping web se ha convertido en un componente esencial en la toma de decisiones basada en datos modernos, pero el escenario de la recolección automatizada de datos es cada vez más desafiante. A medida que los sitios web implementan medidas de seguridad más sofisticadas, aprender cómo manejar los bloqueos de scraping ya no es solo una ventaja, sino una necesidad para cualquier proyecto exitoso de extracción de datos. Esta guía proporciona una visión general completa de por qué ocurren los bloqueos, la tecnología subyacente detrás de los mecanismos de detección y las estrategias más efectivas y éticas para garantizar que sus scrapers permanezcan operativos. Ya sea que sea un desarrollador que construye un rastreador personalizado o un analista de datos que supervisa una operación a gran escala, comprender estos métodos prácticos le ayudará a mantener un acceso constante a la información que necesita.
Comprendiendo la naturaleza de los bloqueos de scraping web
Para manejar eficazmente los obstáculos, primero debe entender qué son y por qué existen. Un bloqueo de scraping web es una medida defensiva implementada por un sitio web para evitar que scripts automatizados accedan a su contenido. Estas medidas suelen formar parte de una estrategia de seguridad más amplia diseñada para proteger los recursos del servidor, prevenir el robo de propiedad intelectual o mantener la integridad de los datos de los usuarios.
Según datos recientes de la industria, el tráfico automatizado representa una parte significativa de todas las solicitudes web, lo que ha llevado a muchas plataformas a adoptar filtros agresivos. Puede encontrar más detalles sobre las tendencias globales en el informe de Statista sobre el tráfico de bots globales. Cuando un servidor detecta patrones que se desvían del comportamiento humano estándar, puede responder sirviendo un CAPTCHA, ralentizando la conexión o emitiendo un bloqueo completo de la IP. Aprender cómo manejar los bloqueos de scraping web en estos escenarios es esencial para la persistencia de los datos.
Antecedentes técnicos: Cómo funcionan los mecanismos de detección
Los sistemas de seguridad modernos no dependen de un solo factor para identificar bots. En su lugar, utilizan una combinación de técnicas para construir un perfil de riesgo para cada solicitud entrante.
1. Seguimiento basado en IP
Esta es la capa más fundamental de defensa. Los servidores monitorean el número de solicitudes que provienen de una sola dirección IP en un período específico. Si la frecuencia excede un umbral predefinido, la IP se marca. Es por esto que conocer cómo manejar los bloqueos de scraping web a nivel de red es tan importante. Los centros de datos suelen ser bloqueados de forma preventiva porque raramente son utilizados por visitantes humanos legítimos.
2. Fingerprinting de navegador
Más allá de la dirección IP, los sitios web pueden recopilar una gran cantidad de información de su entorno de navegador. Esto incluye la resolución de pantalla, las fuentes instaladas, la zona horaria y las especificaciones del hardware. Si estos detalles parecen inconsistentes o demasiado "limpios" (típicos de navegadores headless), el sistema identifica la solicitud como automatizada.
3. Análisis de comportamiento
Plataformas sofisticadas rastrean cómo un usuario interactúa con la página. Los humanos mueven el mouse en patrones no lineales, toman tiempo para leer el contenido y hacen clic en elementos con ritmos variables. En contraste, un script podría saltar directamente a una URL y extraer datos en milisegundos. Cualquier desviación del comportamiento humano esperado activa una alerta roja. Esta detección basada en el comportamiento es uno de los desafíos más difíciles al tratar de aprender cómo manejar los bloqueos de scraping web.
Tipos comunes de desafíos CAPTCHA
Cuando un sistema está inseguro pero sospechoso, suele presentar un CAPTCHA. Comprender estos tipos es crucial para saber cómo manejar eficazmente los bloqueos de scraping web.
| Tipo de CAPTCHA | Descripción | Lógica de detección principal |
|---|---|---|
| Reconocimiento de imágenes | Los usuarios deben seleccionar objetos específicos (por ejemplo, semáforos) de una cuadrícula. | Prueba la capacidad de procesar datos visuales e identifica patrones de clics similares a los humanos. |
| CAPTCHA invisible | Funciona en segundo plano sin interacción del usuario. | Analiza el entorno del navegador y el comportamiento histórico para asignar una puntuación de riesgo. |
| Desafíos de texto/ecuaciones | Requiere resolver una ecuación simple o escribir texto distorsionado. | Se basa en la dificultad de la OCR (Reconocimiento Óptico de Caracteres) para bots antiguos. |
| Acertijo/Deslizador | Los usuarios deben arrastrar una pieza para completar una imagen. | Se enfoca en el movimiento físico del cursor y el momento de la acción. |
Métodos prácticos para manejar los bloqueos de scraping web
Implementar las estrategias técnicas adecuadas puede reducir significativamente la probabilidad de ser detectado. Aquí están los métodos más efectivos utilizados por profesionales hoy en día.
Usar proxies residenciales rotatorios
Dado que los bloqueos de IP son comunes, usar un conjunto de proxies residenciales es una de las mejores formas de evitar bloqueos de IP y garantizar altas tasas de éxito. Estos proxies son la base de las mejores prácticas de scraping web. A diferencia de las IPs de centros de datos, las IPs residenciales están asociadas con conexiones de internet reales en el hogar, lo que las hace mucho más difíciles de distinguir de los usuarios legítimos. Al rotar estas IPs cada pocas solicitudes, puede distribuir su tráfico y permanecer bajo el radar.
Gestionar encabezados y User-Agents
Cada solicitud HTTP incluye encabezados que informan al servidor sobre el cliente. Un error común es usar un encabezado de biblioteca predeterminado como "python-requests/2.25.1". En su lugar, debe usar una variedad de cadenas de User-Agent reales. Consulte la documentación de User-Agent de MDN para entender cómo estructurarlos correctamente. Asegúrese de que sus encabezados incluyan campos como "Accept-Language" y "Referer" para imitar una sesión de navegación real.
Implementar limitación de solicitudes
La velocidad suele ser la principal pista de un bot. Al agregar retrasos aleatorios entre sus solicitudes, puede simular el comportamiento de un usuario humano. Esta técnica, conocida como throttling, evita que sobrecargue al servidor objetivo y reduce las probabilidades de activar alarmas de límite de velocidad. Implementar estas mejores prácticas de scraping web le ayudará a mantener acceso a datos sensibles, al mismo tiempo que le ayuda a evitar bloqueos de IP durante operaciones a gran escala.
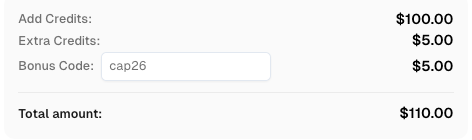
Use el código
CAP26al registrarse en CapSolver para recibir créditos adicionales!
Resolver CAPTCHAs automáticamente
Incluso con encabezados y proxies perfectos, eventualmente encontrará un desafío. Es aquí donde los servicios especializados se vuelven valiosos. Por ejemplo, CapSolver proporciona una API robusta para resolver diversos tipos de desafíos, como ReCaptcha y FriendlyCaptcha, asegurando que sus flujos automatizados permanezcan sin interrupciones. Estas herramientas son parte fundamental de cómo manejar los bloqueos de scraping web en entornos modernos.
Si está utilizando herramientas como cURL o Python para su automatización, puede integrar una solución siguiendo este flujo general:
- Enviar la tarea: Envíe los detalles del CAPTCHA (clave del sitio, URL) al servicio.
- Recuperar la solución: Consulte la API usando el ID de tarea hasta que la solución esté lista.
- Enviar el token: Use el token devuelto para evitar el desafío en el sitio objetivo.
Aquí hay un ejemplo simplificado basado en la documentación de CapSolver para enviar una tarea:
json
{
"clientKey": "SU_CLAVE_DE_API",
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": "https://www.example.com",
"websiteKey": "6LcR_okUAAAAAPYrPe-z_bx1oYxq6zz_S0vO49zV"
}
}Resumen de comparación: Técnicas de scraping
Para ayudarle a elegir el enfoque adecuado, aquí está una comparación de métodos comunes.
| Método | Efectividad | Complejidad de implementación | Costo |
|---|---|---|---|
| Encabezados básicos | Baja | Baja | Gratis |
| Proxys de centros de datos | Media | Media | Bajo |
| Proxys residenciales | Alta | Media | Moderado |
| Navegadores headless | Alta | Alta | Alto (recursos) |
| Solucionadores de CAPTCHA | Esencial | Baja | Bajo |
Consideraciones éticas y de cumplimiento
Al aprender cómo manejar los bloqueos de scraping web, es vital enfatizar prácticas éticas. La recolección automatizada de datos debe realizarse siempre de una manera que respete los términos del sitio web objetivo y la salud del servidor. Siempre verifique el archivo robots.txt de un dominio para ver qué áreas están restringidas. Seguir estas mejores prácticas de scraping web no solo lo protege legalmente, sino que también garantiza la longevidad de sus fuentes de datos.
Para aquellos que buscan herramientas más avanzadas, explorar las mejores herramientas de extracción de datos puede proporcionar insights adicionales sobre la construcción de sistemas resistentes.
Transición natural hacia soluciones
A medida que la tecnología de detección de bots evoluciona, la complejidad de mantener un scraper aumenta. Muchos desarrolladores encuentran que por qué la automatización web sigue fallando en CAPTCHA a menudo se debe a la falta de una estrategia dedicada. Utilizar un mejor solucionador de CAPTCHA le permite enfocarse en el análisis de datos en lugar de corregir constantemente scripts rotos. Al integrar estos servicios profesionales en su pila, puede garantizar altas tasas de éxito incluso en las plataformas más protegidas.
Conclusión
Dominar cómo manejar los bloqueos de scraping web requiere un enfoque de múltiples capas que combine precisión técnica con responsabilidad ética. Al comprender la lógica de detección, implementar una gestión robusta de proxies y utilizar servicios especializados para resolver problemas, puede construir flujos de datos confiables. Recuerde que el objetivo no es solo evitar una barrera individual, sino crear un sistema sostenible que respete el ecosistema digital mientras entrega las perspectivas en las que su negocio depende.
Preguntas frecuentes
1. ¿Por qué aún estoy bloqueado aunque use proxies?
Los bloqueos pueden ocurrir debido al fingerprinting de navegador o a encabezados inconsistentes. Asegúrese de que su User-Agent coincida con la ubicación percibida por el proxy y que no esté filtrando su IP real a través de WebRTC.
2. ¿Es legal evitar los bloqueos de scraping web?
La legalidad depende de su jurisdicción y del tipo de datos que esté recopilando. Generalmente, el scraping de datos públicamente disponibles es legal, pero debe respetar las leyes de derechos de autor y protección de datos personales.
3. ¿Con qué frecuencia debo rotar mi User-Agent?
Es mejor usar un nuevo User-Agent para cada sesión nueva o cada cientos de solicitudes, especialmente si también está rotando su dirección IP.
4. ¿Pueden los navegadores headless evitar todos los bloqueos?
Aunque son útiles, navegadores headless como Puppeteer o Playwright aún pueden ser detectados mediante propiedades específicas. Debe usar "plugins de stealth" para ocultar su naturaleza automatizada.
5. ¿Cuál es la forma más económica de manejar CAPTCHAs?
Usar un servicio de resolución basado en API como CapSolver suele ser más económico que construir sus propios modelos de ML o usar mano de obra manual, ya que ofrece alta velocidad y precisión a un bajo costo por tarea.
Ver más
The Other CAPTCHAMay 15, 2026
API rápida de resolución de CAPTCHA para flujos de trabajo de automatización
API rápida para resolver CAPTCHA para automatización: comparar flujos de trabajo de tokens, desafíos soportados, verificaciones de latencia e integración de CapSolver responsable.

The Other CAPTCHAApr 03, 2026
Explicación del Tiempo de Respuesta de la API de Resolución de CAPTCHA: Factores de Velocidad y Rendimiento
Entender el tiempo de respuesta de la API de resolución de CAPTCHA, su impacto en la automatización y los factores clave que afectan la velocidad. Aprende a optimizar el rendimiento y aprovecha soluciones eficientes como CapSolver para la resolución rápida de CAPTCHA.


