La capa de automatización de la Web para agentes de inteligencia artificial explicado

Aloísio Vítor
Image Processing Expert
TL;DR
- La capa de automatización web para agentes de IA debe traducir la intención del modelo en acciones del navegador con arrendamientos, evidencia del DOM, estado de red y estados de parada tipificados.
- El estado del planificador no es suficiente para una automatización confiable porque el entorno de ejecución del navegador posee cookies, almacenamiento, listo de elementos, política de ruta y contexto de desafío.
- La revisión de trazas debe conectar cada decisión del modelo con un localizador, estado de solicitud, captura de pantalla y resultado final de la misma ID de correlación.
- El manejo de CAPTCHA debe exponerse al planificador como un estado de desafío acotado, no como instrucciones de solucionador en bruto o campos de carga no documentados.
- Los agentes de navegador de larga duración necesitan límites de riesgo para la profundidad de navegación, envíos de formularios, descargas, ventanas de datos privados y bucles repetidos de desafío.
Introducción
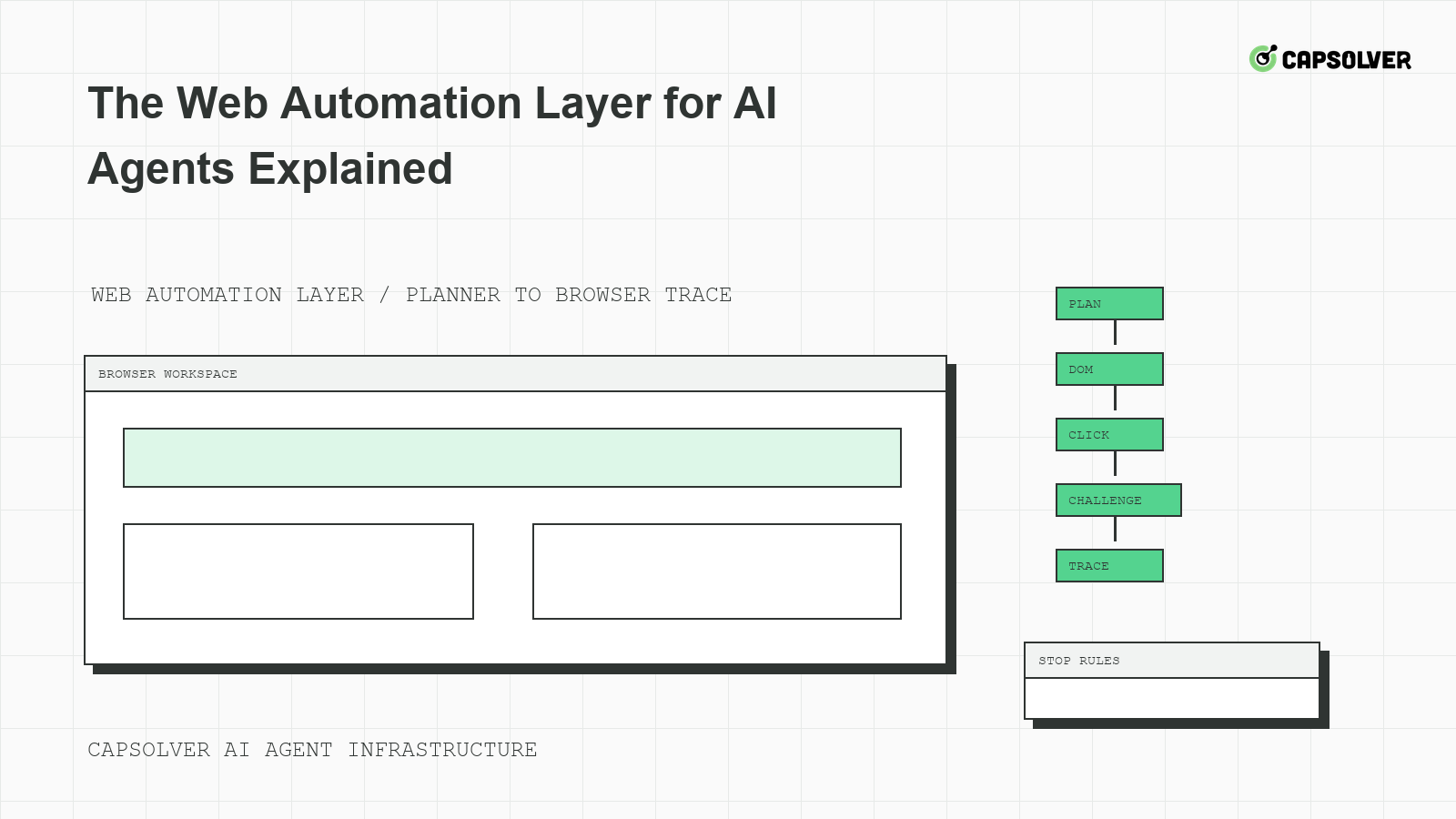
La capa de automatización web para agentes de IA explicada en una oración: es el entorno que convierte la intención del modelo en acciones de navegador gobernadas. CapSolver puede soportar el manejo de CAPTCHA aprobado dentro de ese entorno, pero no debe reemplazar arrendamientos de navegador, fundamentación del DOM, evidencia de traza o límites de riesgo. Cuando los agentes fallan en sitios reales, el problema suele no ser un clic malo. Es la falta de estado entre el planificador, el navegador, la red y el flujo de trabajo protegido.
Explicar la Capa como Planificador Más Entorno de Navegador
La capa de automatización web para agentes de IA se encuentra entre el planificador de modelos y el sitio web en vivo. El planificador decide la próxima acción intencionada. El entorno verifica si la acción es permitida, localiza elementos, espera la disponibilidad, aplica puertas de tasa, registra evidencia y se detiene cuando la tarea cruza un límite. Esta división importa porque el navegador posee estado que el modelo no puede reconstruir confiablemente.
El flujo de trabajo de automatización de navegador de CapSolver LLM es un buen fondo para equipos que conectan modelos con navegadores. La lección principal de producción es que el planificador no debe ser el único punto de control. El entorno debe poseer cookies, almacenamiento local, clase de ruta, vista, descargas y estado de desafío.
Objeto de Arrendamiento de Navegador para Ejecuciones de Agente
Un objeto de arrendamiento de navegador da al entorno un propietario concreto para el estado. Debe incluir dominio, clase de cuenta, grupo de ruta, perfil de almacenamiento, clase de vista, configuración de traza y vencimiento. El modelo de sesión de W3C WebDriver modelo de sesión apoya la misma idea: una sesión de automatización de navegador es un objeto de entorno concreto, no solo una instrucción de prompt.
json
{
"browser_lease": {
"correlation_id": "agent-run-0622-layer-01",
"allowed_domain": "example.com",
"storage_profile": "public-task-profile",
"route_policy": "shared-cooldown-aware",
"trace_mode": "protected_transitions",
"expires_after_actions": 40
}
}Esta configuración pertenece a la capa de automatización web para agentes de IA. No es una solicitud de API de CapSolver. Su propósito es mantener el estado del navegador propiedad y revisable.
Fundamentar Decisiones en Evidencia del DOM y Red
La fundamentación en el DOM evita que los agentes actúen sobre descripciones de página obsoletas. El entorno debe adjuntar cada clic, llenado, espera y envío a un localizador, estado del elemento, captura de pantalla y estado de red. El estándar DOM de WHATWG modelo de nodo del DOM es un buen fondo porque la página es un árbol en constante cambio, no un documento estático.
El artículo de CapSolver sobre bloqueo de agentes de navegador es relevante porque los agentes de navegador suelen fallar cuando confían demasiado en resúmenes visuales o de texto. Un botón puede parecer presente mientras está deshabilitado. Un formulario puede parecer completo mientras un campo oculto ha cambiado. Un desafío puede renderizarse después de que el planificador haya elegido la próxima acción.
Paquete de Evidencia para Cada Transición Protegida
Cada transición protegida debe almacenar localizador, nombre accesible, disponibilidad del elemento, URL actual, estado de solicitud, evento de desafío si está presente, hash de captura de pantalla y afirmación final de aplicación. Este paquete permite a los ingenieros reproducir la ejecución sin vaciar contenido sensible en registros normales. La capa de automatización web para agentes de IA debe enmascarar secretos y campos privados mientras preserva suficiente contexto para depurar estado.
Manejo de Desafíos dentro de la Capa de Automatización
El manejo de desafíos pertenece al entorno, no directamente en el prompt del modelo. El entorno puede detectar un desafío elegible, verificar el permiso de la tarea, seguir la guía de integración documentada, aplicar presupuestos y devolver un resultado tipificado. Debe consultarse la documentación de códigos de error de CapSolver al mapear errores de API a estados de agente. No se deben inventar comportamientos de reintentos o campos de respuesta.
Canjear tu código de bonificación de CapSolver
¡Aumenta tu presupuesto de automatización instantáneamente!
Usa el código de bonificación CAP26 al recargar tu cuenta de CapSolver para obtener un 5% adicional en cada recarga — sin límites.
Canjéalo ahora en tu Panel de CapSolver

Revisión de Trazas para Agentes de Estilo de Navegador
La revisión de trazas es el método práctico de depuración para agentes de navegador. La traza debe mostrar la instrucción del planificador, la acción del navegador, el localizador, la captura de pantalla, el evento de red, el estado del desafío y el resultado final bajo una misma ID de correlación. La documentación del visor de trazas de Playwright es una referencia de implementación útil para equipos que usan runtimes basados en Playwright.
Reconstruyendo una Acción Protegida Fallida
Cuando una acción protegida falla, reconstruye el último estado conocido bueno. ¿El portón de ruta permitió la tarea? ¿El arrendamiento del navegador coincidió con el dominio y la clase de cuenta? ¿El localizador aún apuntaba a un elemento interactuable? ¿La red devolvió 403, 429 o 5xx? ¿Apareció un evento de desafío? ¿Aceptó el backend el envío final? La explicación de los sistemas MCP de CapSolver https://www.capsolver.com/faq/ai-and-automation/what-is-mcp-model-context-protocol-in-ai-systems puede ayudar a los equipos a pensar en límites de herramientas, pero la evidencia de traza debe decidir la solución inmediata.
La traza también debe revelar si el modelo hallucinó progreso. Si el agente dice que el formulario fue enviado pero no se envió ninguna solicitud, el problema es la interacción del DOM. Si la solicitud se envió pero fue rechazada, el problema es la aceptación del backend. Si la página se volvió a renderizar durante la encuesta, el problema es el tiempo de sesión y estado del formulario.
Límites de Riesgo para Tareas Web de Larga Duración
Los agentes de navegador de larga duración necesitan límites de riesgo estrictos. Establezca la profundidad máxima de navegación, el número máximo de envíos de formularios, restricciones de descarga, detenciones de ventanas de datos privados, detenciones de advertencias de cuenta y detenciones de bucles de desafío. La documentación de MDN HTTP 401 No autorizado es un recordatorio útil de que los límites de autenticación no deben tratarse como navegación ordinaria.
Reglas de Detención para Planificadores de Agentes
Exponga las reglas de detención como estados tipificados: navigation_depth_exceeded, download_not_allowed, private_data_prompt, login_required, challenge_budget_exhausted y cooldown_active. El contenido de automatización de navegador de Playwright de CapSolver es útil para entender flujos de trabajo de automatización de navegador, mientras que las reglas de detención de producción deben ser impuestas por su entorno.
La capa de automatización web para agentes de IA es madura cuando el modelo puede pedir acciones pero no puede exceder políticas en silencio. Esto puede sentirse más lento que un prototipo, pero es lo que hace que el sistema sea revisable y confiable. Una traza con detenciones claras es mejor que un transcripción llena de afirmaciones seguras y sin resultado de aplicación.
Matriz de Depuración para Fallas de Capa
Una matriz de depuración ayuda a los equipos a decidir qué parte de la capa de automatización web para agentes de IA falló. Divida los incidentes por planificador, localizador, estado del navegador, política de red, manejo de desafío y aceptación del backend. La categoría debe provenir de la evidencia, no de la opinión. Si el modelo seleccionó la acción equivocada aunque el estado de la página estuviera claro, el planificador necesita mejoras. Si la acción correcta fue seleccionada pero el elemento estaba desconectado o deshabilitado, la estrategia de localizador y espera necesita trabajo. Si la solicitud fue enviada pero rechazada, el equipo debe inspeccionar el estado de sesión y autorización.
Asignación de Evidencia a Propietario
Asigne cada tipo de evidencia a un propietario. Los transcritos del planificador pertenecen al equipo del agente. Los fallos en localización pertenecen a ingenieros de automatización de navegador. El desplazamiento de cookies y almacenamiento pertenece a los propietarios del entorno. Los retrasos de 429 pertenecen a operaciones. Los errores de solucionador documentados pertenecen al propietario de integración de desafío. La rechazo del backend tras una acción de navegador válida pertenece al propietario del flujo de aplicación. Esta asignación evita que cada incidente se convierta en un ejercicio de ajuste de prompts.
La matriz debe ser lo suficientemente corta para usarse durante un incidente. Una versión buena tiene una fila por categoría de fallo, la evidencia que la confirma, la primera respuesta y el propietario. Por ejemplo, eventos repetidos de element_not_interactable deben llevar a una revisión de localizador y disponibilidad. Un evento de solucionador listo seguido de un 403 debe llevar a una revisión de autorización y sesión. Una clave de retraso compartida entre trabajadores debe llevar a un control de cola, no a otro lanzamiento de navegador.
Úsela también después de ejecuciones exitosas. Muestras de trazas de flujos completados y confirme que la evidencia aún se mapea limpiamente a propietarios. Esto captura la degradación silenciosa antes de que se convierta en un pico de fallos. La capa de automatización web para agentes de IA permanece mantenible cuando la depuración comienza desde la evidencia y la propiedad, no desde el último estado de página visible.
Páginas de Prueba Sintéticas para Validación de Capa
Las páginas de prueba sintéticas dan a la capa de automatización web para agentes de IA un lugar controlado para demostrar comportamientos. Construya páginas internas pequeñas que simulen botones deshabilitados, tokens de formulario retrasados, retrasos de ruta, descargas no admitidas, ventanas de inicio de sesión y marcadores de desafío elegibles. El punto no es imitar perfectamente un sitio objetivo. El punto es validar que el entorno devuelva el estado tipificado correcto antes de que el agente alcance un flujo de trabajo protegido real.
Fijaciones de Prueba que Capturan Regresiones
Use una fijación por cada límite. Una página de token retrasado debe fallar si el agente envía antes de que el campo oculto esté listo. Una fijación de retraso de ruta debe detenerse antes del lanzamiento del navegador. Una fijación de datos privados debe cerrar la tarea y preservar la evidencia enmascarada. Una fijación de desafío elegible debe ingresar al camino de desafío documentado solo cuando el contrato de acceso lo permita. Una fijación de rechazo del backend debe demostrar que una acción de navegador completada no se trata automáticamente como éxito de tarea.
Estas fijaciones son valiosas durante actualizaciones de prompts. Un modelo más fuerte puede hacer clic más rápido, elegir rutas de navegación diferentes o reinterpretar un mensaje de advertencia. Las fijaciones confirman que el entorno aún impone políticas sin importar la confianza del planificador. También son útiles después de actualizaciones de navegador porque la disponibilidad de elementos, el tiempo de eventos y el comportamiento de red pueden cambiar entre versiones.
Mantenga la salida de fijación pequeña y comparable. Almacene el estado tipificado esperado, los eventos de traza esperados y la razón de detención esperada para cada caso. Cuando aparezca una regresión, los ingenieros pueden ver si cambió el modelo, el entorno o el navegador. Esto hace que la capa de automatización web para agentes de IA sea más fácil de evolucionar sin exponer sitios reales a tráfico de prueba evitable.
Las páginas sintéticas deben estar versionadas con el entorno. Si una fijación cambia al mismo tiempo que la capa de navegador, el equipo pierde su muestra de control. Mantenga las fijaciones antiguas disponibles por un corto período después de lanzamientos importantes para que las regresiones puedan reproducirse. La capa de automatización web para agentes de IA necesita pruebas estables porque los sitios web en vivo ya son lo suficientemente variables.
Los resultados de las fijaciones deben ser fáciles de leer para no autores. Almacene el estado esperado, estado real, ID de traza y propietario en un informe compacto. Cuando un lanzamiento falle, el equipo debe ver si el fallo es una detención de política, una regresión de localizador, un retraso de red o un problema de manejo de desafío sin reproducir toda la sesión del navegador a mano.
Mantenga esos informes junto a los artefactos de lanzamiento. Se convierten en un historial compacto de cómo se comportó la capa de navegador a medida que los prompts, navegadores, rutas y manejo de desafío cambiaron.
También aceleran la revisión de incidentes.
Conclusión
La capa de automatización web para agentes de IA debe combinar la intención del planificador con arrendamientos de navegador, fundamentación en el DOM, evidencia de red, manejo de desafíos, revisión de trazas y límites de riesgo. La resolución de CAPTCHA es una capacidad acotada dentro de ese entorno, no un sustituto de la gobernanza. Para equipos que construyen agentes de navegador legales con necesidades de desafío aprobadas, CapSolver puede soportar la capa de desafío mientras su entorno preserva estado y política.
Preguntas Frecuentes
¿Qué es la capa de automatización web para agentes de IA?
Es la capa de entorno que convierte la intención del modelo en acciones de navegador mientras gestiona sesiones, evidencia del DOM, estado de red, estados de desafío, registros y reglas de detención.
¿Por qué el estado del planificador no es suficiente?
El planificador no posee cookies, almacenamiento, estado de elementos en vivo, temporización de red, política de ruta o respuestas del backend. El entorno de ejecución del navegador debe gestionar esos hechos.
¿Cómo debería aparecer el manejo de CAPTCHA al planificador?
Debería aparecer como estados tipificados como desafío detectado, pendiente, listo, aceptado por el backend, rechazado por el backend, retraso o requerido revisión.
¿Qué debe probar una traza?
Una traza debe probar qué decisión del modelo llevó a qué acción del navegador, qué devolvió la página y la red y si la acción final de aplicación tuvo éxito.
Ver más
AIJun 22, 2026
Resolución escalable de CAPTCHA para agentes de producción
Una guía de operaciones de producción para la resolución escalable de CAPTCHA en flotas de agentes, enfocada en control de admisión, límites de tasa, métricas de capacidad y respuesta a incidentes.
AIJun 22, 2026
CapSolver: Un solucionador de CAPTCHA listo para Agente
Un marco de evaluación para CapSolver como solucionador de CAPTCHA listo para agentes, enfocado en compatibilidad en tiempo de ejecución, integración documentada, observabilidad y controles de implementación.