¿Cómo funciona el reconocimiento de imágenes con inteligencia artificial? | Guía técnica

Aloísio Vítor
Image Processing Expert
TL;Dr
- La IA de reconocimiento de imágenes traduce los píxeles visuales en datos numéricos para su interpretación por máquinas.
- Las Redes Neuronales Convolucionales (CNN) son la arquitectura principal utilizada para identificar patrones como bordes y formas.
- El proceso implica una cadena de producción estructurada desde la recopilación y etiquetado de datos hasta el entrenamiento y evaluación del modelo.
- Las aplicaciones del mundo real abarcan desde diagnósticos médicos hasta sistemas de seguridad automatizados como el Vision Engine de CapSolver.
- La obtención ética de datos y el cumplimiento técnico son esenciales para el desarrollo sostenible de la IA.
Introducción
La IA de reconocimiento de imágenes funciona convirtiendo la información visual en matrices matemáticas que las redes neuronales analizan en busca de patrones específicos. Esta tecnología permite a las máquinas identificar objetos, personas y acciones dentro de imágenes digitales con una velocidad y precisión notables. Para desarrolladores y entusiastas de los datos, comprender cómo funciona el reconocimiento de imágenes con IA es el primer paso hacia la construcción de sistemas avanzados de visión por computadora.
Para concluir, la efectividad del reconocimiento de imágenes depende de la calidad de los datos de entrenamiento y de la sofisticación de la arquitectura neuronal. Este guía desmitifica las capas técnicas de la IA visual, desde el procesamiento de píxeles hasta la clasificación final de objetos complejos. Exploraremos cómo los sistemas modernos utilizan matemáticas para "ver" e interpretar el mundo que nos rodea.
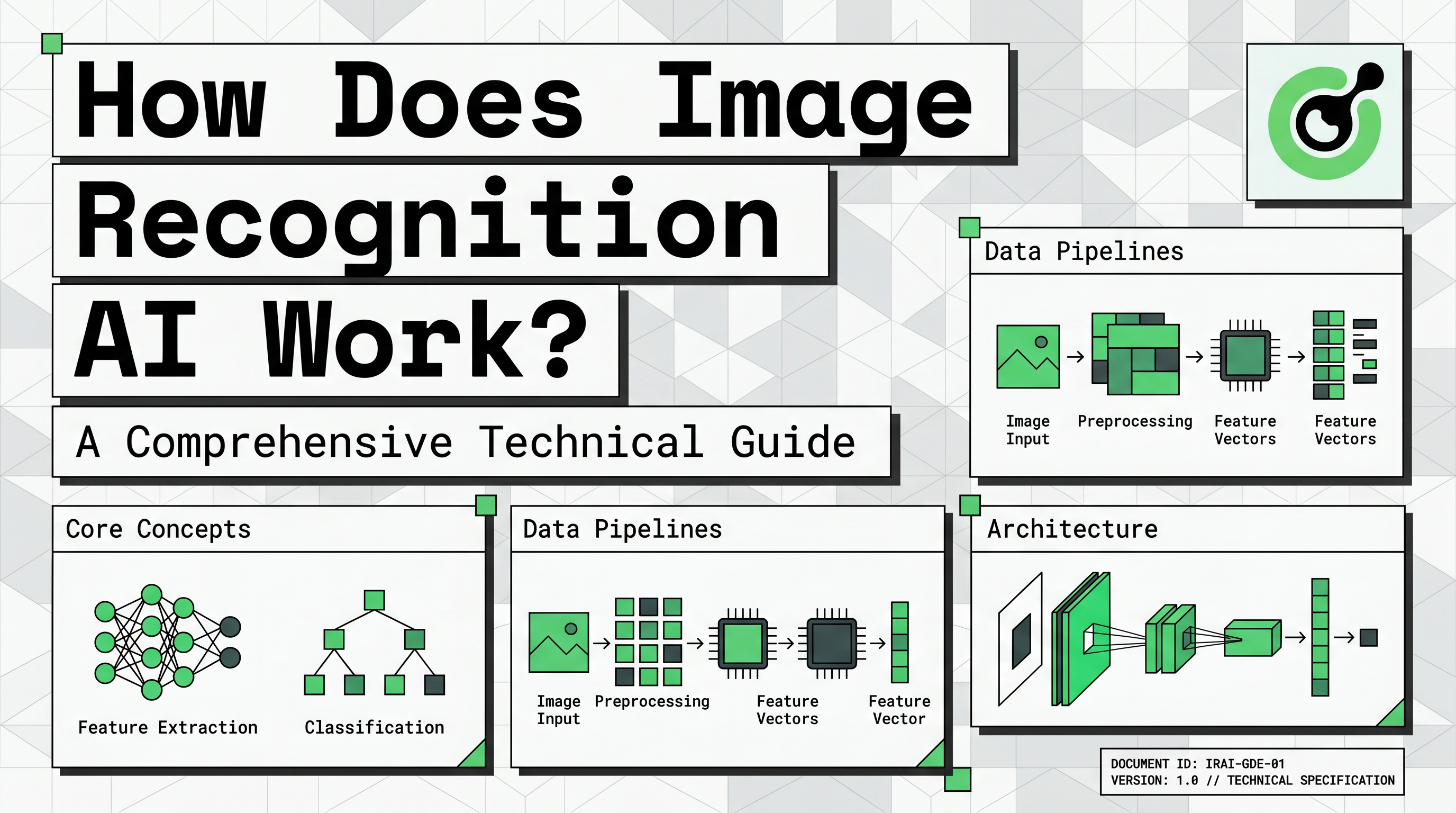
Fundamentos: Píxeles y Datos Numéricos
Para comprender cómo funciona el reconocimiento de imágenes con IA, primero debemos analizar cómo las computadoras perciben las imágenes. Una imagen digital es esencialmente una gran cuadrícula de elementos pequeños llamados píxeles. Cada píxel contiene valores numéricos que representan su intensidad de luz o niveles de color.
En una imagen de color estándar, cada píxel se representa mediante tres valores: rojo, verde y azul (RGB). Estos valores generalmente oscilan entre 0 y 255. Una máquina ve una foto de un automóvil no como un vehículo, sino como una matriz masiva de números. Esta representación numérica es la entrada cruda que un sistema de reconocimiento de imágenes procesa para encontrar patrones significativos.
| Componente | Representación de la máquina | Función |
|---|---|---|
| Píxel | Valor numérico (0-255) | Unidad básica de datos visuales |
| Canal de color | Matriz RGB | Proporciona información de color y profundidad |
| Tensor de imagen | Matriz multidimensional | Estructura de datos completa para la entrada de IA |
Esta transición de entrada visual a tensores legibles por máquinas es crucial. Permite que la IA realice operaciones matemáticas en los datos para identificar características que las personas reconocen instintivamente.
El Motor de la IA Visual: Redes Neuronales Convolucionales (CNN)
La tecnología principal detrás de los sistemas visuales modernos es la Red Neuronal Convolucional (CNN). Esta arquitectura está diseñada específicamente para procesar estructuras de datos en forma de cuadrícula, como las imágenes. Al explorar cómo funciona el reconocimiento de imágenes con IA, las CNN son el componente técnico más importante que entender.
Una CNN consta de varias capas que realizan funciones diferentes. La primera capa es la capa convolucional, que aplica filtros a la imagen para extraer características de bajo nivel. Estas características incluyen elementos simples como líneas horizontales, bordes verticales y texturas básicas.
A continuación, las capas de agrupamiento reducen la dimensionalidad de los datos mientras preservan la información más importante. Este paso hace que el sistema sea más eficiente y ayuda a que se enfoque en las características más relevantes. Finalmente, las capas completamente conectadas toman la información procesada y realizan la clasificación final. Es aquí donde la IA decide si las características identificadas representan un gato, un automóvil o un tipo específico de texto.
Según IBM: ¿Qué es el reconocimiento de imágenes?, estas capas trabajan juntas para construir un entendimiento jerárquico de la imagen. El sistema comienza con líneas simples y gradualmente construye objetos complejos. Esta aproximación jerárquica es la razón por la cual las CNN son tan efectivas para manejar tareas visuales diversas.
La Cadena de Procesamiento del Reconocimiento de Imágenes: Desde los Datos hasta la Implementación
Construir un sistema exitoso implica una cadena de producción estructurada que va más allá de solo la red neuronal. La primera etapa es la recopilación de datos, donde los desarrolladores recopilan miles de imágenes relevantes para su tarea objetivo. Por ejemplo, un sistema diseñado para identificar anomalías médicas requiere un conjunto de datos vasto de escáneres clínicos.
El etiquetado de datos es el siguiente paso crítico. Los anotadores humanos deben etiquetar las imágenes con clasificaciones correctas o dibujar cuadros de límite alrededor de objetos específicos. Estos datos etiquetados sirven como la "verdad de base" que la IA utiliza para aprender durante la fase de entrenamiento. Sin etiquetas de alta calidad, incluso la mejor CNN no producirá resultados precisos.
El preprocesamiento y el aumento de datos también son esenciales. Esto implica redimensionar las imágenes, normalizar los valores de color y crear variaciones de los datos existentes. El aumento ayuda al modelo a ser más robusto al entrenarlo en versiones rotadas, volteadas o ligeramente borrosas de las imágenes originales. Esto asegura que la IA pueda reconocer objetos en diferentes condiciones del mundo real.
Finalmente, el modelo se evalúa utilizando métricas como precisión, recall y exactitud. Esta fase de prueba determina si el sistema está listo para la implementación. Los desarrolladores deben asegurarse de que la IA funcione de manera confiable en datos nuevos y no vistos antes de integrarla en una aplicación en vivo.
Aplicaciones Prácticas: Resolviendo Desafíos Visuales Complejos
El reconocimiento de imágenes se utiliza en muchas industrias para automatizar tareas que antes eran manuales. En la salud, ayuda a los radiólogos a identificar señales tempranas de enfermedad en radiografías. En el comercio minorista, impulsa sistemas de caja automática y herramientas de búsqueda visual que ayudan a los clientes a encontrar productos usando fotos.
Una aplicación especializada de esta tecnología se encuentra en seguridad y automatización. Por ejemplo, CapSolver utiliza reconocimiento de imágenes avanzado para resolver desafíos visuales complejos como CAPTCHAs. Su Vision Engine es un ejemplo destacado de cómo funciona el reconocimiento de imágenes con IA en entornos de alta precisión.
Al utilizar el Vision Engine de CapSolver, los desarrolladores pueden automatizar el reconocimiento de acertijos visuales con precisión extrema. Esto es especialmente útil para tareas de raspado web y extracción de datos donde la automatización tradicional podría estar bloqueada. Para quienes busquen implementar estas tecnologías, un guía práctica sobre IA y LLM en automatización puede proporcionar estrategias de implementación valiosas. A continuación se muestra un ejemplo conceptual de cómo interactuar con una API de reconocimiento visual:
python
import requests
# Ejemplo de uso de un motor de visión para reconocimiento de imágenes
def solve_visual_task(image_path, api_key):
url = "https://api.capsolver.com/createTask"
payload = {
"clientKey": api_key,
"task": {
"type": "ImageToTextTask",
"body": "cadena_codificada_en_base64_de_imagen"
}
}
response = requests.post(url, json=payload)
return response.json()
# Esto demuestra el uso práctico del reconocimiento de imágenes en automatizaciónEl papel de la IA en la resolución de CAPTCHAs destaca la madurez técnica del reconocimiento de imágenes moderno. Muestra que la IA ahora puede manejar tareas visuales subjetivas que antes se consideraban solucionables solo por humanos. Esta evolución forma parte de una tendencia más amplia donde la IA y los LLM están cambiando el paisaje de CAPTCHAs al proporcionar capacidades de razonamiento más sofisticadas.
Tareas Objetivas vs. Subjetivas en la IA Visual
No todas las tareas de reconocimiento de imágenes tienen la misma complejidad. Los desarrolladores a menudo categorizan las tareas según su nivel de subjetividad y la precisión requerida.
| Categoría de Tarea | Descripción | Ejemplo |
|---|---|---|
| Objetiva | Criterios claros con respuestas binarias | ¿Hay un perro en esta foto? |
| Subjetiva | Requiere interpretación sutil | ¿Esta imagen médica muestra un crecimiento benigno o maligno? |
| Cuantitativa | Involucra contar o medir | ¿Cuántos autos hay en este estacionamiento? |
| Calitativa | Evaluar la calidad de una imagen | ¿Esta foto de producto es lo suficientemente clara para un sitio de comercio electrónico? |
Comprender estas categorías ayuda a los desarrolladores a elegir los modelos y estrategias de entrenamiento adecuados. Las tareas objetivas suelen ser más fáciles de dominar para la IA, mientras que las tareas subjetivas requieren conjuntos de datos más extensos y supervisión humana.
Preguntas Frecuentes
¿Cuál es la diferencia entre el reconocimiento de imágenes y la detección de objetos?
El reconocimiento de imágenes identifica el tema principal de una imagen, mientras que la detección de objetos encuentra y etiqueta múltiples objetos dentro de un solo marco. La detección de objetos es generalmente más compleja porque requiere identificar la ubicación de cada objeto.
¿Por qué se prefieren las CNN para tareas relacionadas con imágenes?
Las CNN se prefieren porque pueden aprender automáticamente jerarquías espaciales de características. Utilizan capas convolucionales para identificar patrones simples como bordes y gradualmente los combinan en objetos complejos. Esto las hace más eficientes que las redes neuronales tradicionales para datos visuales.
¿Cuántos datos se necesitan para entrenar un modelo de reconocimiento de imágenes confiable?
La cantidad de datos depende de la complejidad de la tarea. Para clasificaciones simples, unos miles de imágenes podrían ser suficientes. Sin embargo, para sistemas de alta precisión en campos como la conducción autónoma, a menudo se requieren millones de imágenes etiquetadas para garantizar seguridad y confiabilidad.
¿Puede la IA de reconocimiento de imágenes funcionar en tiempo real?
Sí, los hardware modernos y arquitecturas neuronales optimizadas permiten el reconocimiento de imágenes en tiempo real. Esto es esencial para aplicaciones como la seguridad de reconocimiento facial y la navegación de vehículos autónomos, donde las decisiones deben tomarse en milisegundos.
Conclusión
Dominar cómo funciona el reconocimiento de imágenes con IA requiere un profundo entendimiento de ambas arquitecturas neuronales y gestión de datos. Al combinar poderosas CNN con conjuntos de datos de alta calidad, los desarrolladores pueden crear sistemas que interpreten el mundo visual con una precisión increíble. Esta tecnología continúa evolucionando, abriendo nuevas posibilidades para la automatización y la toma de decisiones inteligentes.
Si está buscando integrar una IA visual avanzada en sus flujos de trabajo, explore CapSolver hoy mismo. Nuestras soluciones están diseñadas para manejar las tareas más desafiantes de reconocimiento de imágenes con facilidad.
Ver más
AIJul 23, 2026
Cómo resolver Cloudflare Turnstile en agentes de LangGraph
Construye un flujo de trabajo de solucionador de Cloudflare Turnstile de LangGraph con CapSolver, manejo de sesiones de Playwright, puertas de política, reintentos, verificación y revisión.
Web ScrapingJul 23, 2026
Cómo monitorear los resultados ricos de esquema: Una guía de automatización
Aprende a automatizar el monitoreo de resultados ricos de esquema con la extracción de JSON-LD, líneas base semánticas, validación, datos de Search Console y alertas útiles.