Cómo resolver reCAPTCHA v2 en Crawl4AI con integración de CapSolver

Adélia Cruz
Neural Network Developer

La casilla "No soy un robot" sirve como mecanismo de defensa crucial contra el tráfico de bots y el abuso automatizado en los sitios web. Aunque es esencial para la seguridad, a menudo representa un desafío significativo para las operaciones de scraping web y extracción de datos. La necesidad de soluciones eficientes y automatizadas para resolver CAPTCHA se ha vuelto fundamental para desarrolladores y empresas que dependen de la automatización web.
Este artículo explora la integración robusta de Crawl4AI, un avanzado crawler web, con CapSolver, un servicio líder para resolver CAPTCHA, enfocándose específicamente en la resolución de reCAPTCHA v2. Exploraremos ambos métodos de integración basados en API y en extensiones de navegador, proporcionando ejemplos de código y explicaciones detalladas para ayudarte a lograr una recopilación de datos web fluida e ininterrumpida.
Entendiendo reCAPTCHA v2 y sus desafíos
reCAPTCHA v2 requiere que los usuarios hagan clic en una casilla y, en ocasiones, completen desafíos de imágenes, para demostrar que son humanos. Para sistemas automatizados como los crawlers web, este elemento interactivo detiene el proceso de scraping, exigiendo intervención manual o técnicas sofisticadas de supresión. Sin una solución efectiva, la recopilación de datos se vuelve ineficiente, inestable y costosa.
CapSolver ofrece una solución de alta precisión y respuesta rápida para reCAPTCHA v2 mediante algoritmos de inteligencia artificial avanzada. Al integrarse con Crawl4AI, convierte un obstáculo significativo en un paso automatizado fluido, garantizando que tus tareas de automatización web permanezcan fluidas y productivas.
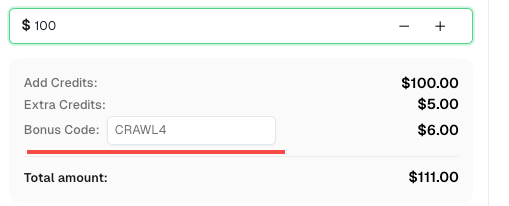
💡 Bonificación exclusiva para usuarios de integración con Crawl4AI:
Para celebrar esta integración, ofrecemos un código de bonificación exclusivo de 6% —CRAWL4para todos los usuarios de CapSolver que se registren a través de este tutorial.
Simplemente ingrese el código durante el recarga en Panel de control para recibir créditos adicionales de 6% de inmediato.
Método de integración 1: Integración de la API de CapSolver con Crawl4AI
El método de integración de la API proporciona un control detallado y generalmente se recomienda por su flexibilidad y precisión. Implica el uso de la función js_code de Crawl4AI para inyectar el token de CAPTCHA obtenido de CapSolver directamente en la página web objetivo.
Cómo funciona:
- Navegar a la página de CAPTCHA: Crawl4AI accede a la página web objetivo como de costumbre.
- Obtener token: En tu script de Python, llama a la API de CapSolver usando su SDK, pasando parámetros necesarios como
siteKeyywebsiteURLpara recibir el tokengRecaptchaResponse. - Inyectar token: Utiliza el parámetro
js_codedeCrawlerRunConfigpara inyectar el token obtenido en el elemento de textog-recaptcha-responsede la página. - Continuar operaciones: Después de una inyección exitosa del token, Crawl4AI puede continuar con acciones posteriores, como la presentación de formularios o clics, evitando eficazmente el reCAPTCHA.
Ejemplo de código: Integración de API para reCAPTCHA v2
El siguiente código de Python demuestra cómo integrar la API de CapSolver con Crawl4AI para resolver reCAPTCHA v2. Este ejemplo apunta a la página de demostración de la casilla de reCAPTCHA v2.
python
import asyncio
import capsolver
from crawl4ai import *
# TODO: establezca su configuración
api_key = "CAP-xxxxxxxxxxxxxxxxxxxxx" # su clave de API de capsolver
site_key = "6LfW6wATAAAAAHLqO2pb8bDBahxlMxNdo9g947u9" # clave del sitio de su sitio objetivo
site_url = "https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php" # URL de la página de su sitio objetivo
captcha_type = "ReCaptchaV2TaskProxyLess" # tipo de su CAPTCHA objetivo
capsolver.api_key = api_key
async def main():
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# obtener token de recaptcha usando el SDK de capsolver
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"websiteKey": site_key,
})
token = solution["gRecaptchaResponse"]
print("token de recaptcha:", token)
js_code = """
const textarea = document.getElementById(\'g-recaptcha-response\');
if (textarea) {
textarea.value = \"""" + token + """\";
document.querySelector(\'button.form-field[type="submit"]\').click();
}
"""
wait_condition = """() => {
const items = document.querySelectorAll(\'h2\');
return items.length > 1;
}"""
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
wait_for=f"js:{wait_condition}"
)
result_next = await crawler.arun(
url=site_url,
config=run_config,
)
print(result_next.markdown)
if __name__ == "__main__":
asyncio.run(main())Análisis del código:
- Llamada al SDK de CapSolver: El método
capsolver.solvese invoca con el tipoReCaptchaV2TaskProxyLess,websiteURLywebsiteKeypara recuperar el tokengRecaptchaResponse. Este token es la solución proporcionada por CapSolver. - Inyección de JavaScript (
js_code): La cadenajs_codecontiene JavaScript que localiza el elemento de textog-recaptcha-responseen la página y asigna el token obtenido a su propiedadvalue. Posteriormente, simula un clic en el botón de envío, asegurando que el formulario se envíe con el token de CAPTCHA válido. - Condición
wait_for: Se define unawait_conditionpara garantizar que Crawl4AI espere a que un elemento específico aparezca en la página, indicando que el envío fue exitoso y que la página ha cargado nuevo contenido.
Método de integración 2: Integración de la extensión de navegador de CapSolver
Para escenarios donde la inyección directa de API podría ser compleja o menos deseable, la extensión de navegador de CapSolver ofrece una alternativa. Este método aprovecha la capacidad de la extensión para detectar y resolver CAPTCHA dentro del contexto del navegador gestionado por Crawl4AI.
Cómo funciona:
- Iniciar el navegador con
user_data_dir: Configura Crawl4AI para iniciar una instancia del navegador con un directoriouser_data_direspecificado para mantener un contexto persistente. - Instalar y configurar la extensión: Instala manualmente la extensión CapSolver en este perfil de navegador y configura tu clave de API de CapSolver. También puedes configurar previamente los parámetros
apiKeyymanualSolvingen el archivoconfig.jsde la extensión. - Navegar a la página de CAPTCHA: Crawl4AI navega a la página que contiene el reCAPTCHA v2.
- Resolución automática o manual: Dependiendo de la configuración
manualSolvingde la extensión, el CAPTCHA se resolverá automáticamente al detectarlo, o podrás activarlo manualmente mediante JavaScript inyectado. - Verificación: Una vez resuelto, el token es manejado automáticamente por la extensión, y las acciones posteriores, como el envío de formularios, llevarán la verificación válida.
Ejemplo de código: Integración de extensión para reCAPTCHA v2 (Resolución automática)
Este ejemplo muestra cómo configurar Crawl4AI para usar un perfil de navegador con la extensión CapSolver para la resolución automática de reCAPTCHA v2.
python
import asyncio
import time
from crawl4ai import *
# TODO: establezca su configuración
user_data_dir = "/browser-profile/Default1" # Asegúrese de que esta ruta esté correctamente configurada y contenga su extensión configurada
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120", # Opcional: configure el proxy si es necesario
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# La extensión resolverá automáticamente el CAPTCHA al cargar la página.
# Es posible que necesites agregar una condición de espera o time.sleep para que el CAPTCHA se resuelva
# antes de continuar con otras acciones.
time.sleep(30) # Ejemplo de espera, ajusta según sea necesario
# Continuar con otras operaciones de Crawl4AI después de que el CAPTCHA haya sido resuelto
# Por ejemplo, revisar elementos que aparezcan después del envío exitoso
# print(result_initial.markdown) # Puedes inspeccionar el contenido de la página después de la espera
if __name__ == "__main__":
asyncio.run(main())Análisis del código:
user_data_dir: Este parámetro es crucial para que Crawl4AI inicie una instancia del navegador que conserve la extensión CapSolver instalada y sus configuraciones. Asegúrate de que la ruta apunte a un directorio válido de perfil de navegador donde se haya instalado la extensión.- Resolución automática: Con
manualSolvingconfigurado enfalse(o por defecto) en la configuración de la extensión, esta resolverá automáticamente el reCAPTCHA v2 al cargar la página. Se incluyetime.sleepcomo ejemplo para permitir que la extensión tenga tiempo suficiente para resolver el CAPTCHA antes de intentar otras acciones.
Ejemplo de código: Integración de extensión para reCAPTCHA v2 (Resolución manual)
Si prefieres activar la resolución del CAPTCHA manualmente en un punto específico de tu lógica de scraping, puedes configurar el parámetro manualSolving de la extensión en true y luego usar js_code para hacer clic en el botón de resolución proporcionado por la extensión.
python
import asyncio
import time
from crawl4ai import *
# TODO: establezca su configuración
user_data_dir = "/browser-profile/Default1" # Asegúrese de que esta ruta esté correctamente configurada y contenga su extensión configurada
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120", # Opcional: configure el proxy si es necesario
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# Esperar un momento para que la página se cargue y la extensión esté lista
time.sleep(6)
# Utilizar js_code para activar el botón de resolución manual proporcionado por la extensión de CapSolver
js_code = """
let solverButton = document.querySelector(\'#capsolver-solver-tip-button\');
if (solverButton) {
const clickEvent = new MouseEvent(\'click\', {
bubbles: true,
cancelable: true,
view: window
});
solverButton.dispatchEvent(clickEvent);
}
"""
print(js_code)
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
)
result_next = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
config=run_config
)
print("Resultados de ejecución de JS:", result_next.js_execution_result)
# Permitir tiempo para que el CAPTCHA se resuelva después de la activación manual
time.sleep(30) # Ejemplo de espera, ajuste según sea necesario
# Continuar con otras operaciones de Crawl4AI
if __name__ == "__main__":
asyncio.run(main())Análisis del código:
manualSolving: Antes de ejecutar este código, asegúrate de que en el archivoconfig.jsde la extensión de CapSolver se establezcamanualSolvingentrue.- Activar resolución: El
js_codesimula un evento de clic en el#capsolver-solver-tip-button, que es el botón proporcionado por la extensión de CapSolver para la resolución manual. Esto te da un control preciso sobre cuándo se inicia el proceso de resolución del CAPTCHA.
Conclusión
La integración de Crawl4AI con CapSolver proporciona soluciones poderosas y flexibles para evitar reCAPTCHA v2, mejorando significativamente la eficiencia y fiabilidad de las operaciones de scraping web. Ya sea que optes por el control preciso de la integración de API o la configuración simplificada de la integración de extensión de navegador, ambos métodos aseguran que reCAPTCHA v2 ya no sea un obstáculo para tus objetivos de recopilación de datos.
Al automatizar la resolución de CAPTCHA, los desarrolladores pueden enfocarse en extraer datos valiosos, confiando en que sus crawlers naveguen sin problemas por sitios web protegidos. Esta sinergia entre las avanzadas capacidades de crawling de Crawl4AI y la tecnología robusta de resolución de CAPTCHA de CapSolver marca un importante avance en la extracción automatizada de datos web.
Referencias
Ver más
Web ScrapingJul 23, 2026
Cómo monitorear los resultados ricos de esquema: Una guía de automatización
Aprende a automatizar el monitoreo de resultados ricos de esquema con la extracción de JSON-LD, líneas base semánticas, validación, datos de Search Console y alertas útiles.

Web ScrapingJul 22, 2026
Monitoreo de Regresión en SEO Técnico: Pipeline de Automatización
Construir un monitoreo de regresión de SEO técnico con líneas base versionadas, diferencias semánticas, alertas verificadas y un paso opcional de recuperación CAPTCHA autorizado.