¿Qué es el aterrizaje de datos en IA? Guía práctica para LLMs confiables

Aloísio Vítor
Image Processing Expert
TL;DR
- La sujeción de datos conecta las salidas de la IA con fuentes de información confiables, actualizadas y relevantes.
- La sujeción de datos reduce respuestas no respaldadas al agregar contexto en el momento de la inferencia.
- Los datos de sujeción pueden incluir documentos, bases de datos, resultados de búsqueda, catálogos, políticas y registros permitidos.
- RAG es una técnica común para la sujeción de datos, pero no es toda la disciplina.
- Una fuerte sujeción de datos requiere verificaciones de calidad, permisos, evaluación de recuperación, citas y monitoreo.
- Los equipos que usan automatización deben recopilar datos legalmente y manejar desafíos de CAPTCHA solo en flujos autorizados.
Introducción
La sujeción de datos es la práctica que hace que las respuestas de la IA sean más precisas, actualizadas y verificables. Proporciona al modelo el contexto adecuado antes de que responda. Esta guía está dirigida a equipos de productos, equipos de SEO, desarrolladores y equipos de automatización que construyen herramientas de IA sobre LLM. Aprenderás qué significa la sujeción de datos en la IA, cómo funciona, cómo se diferencia de RAG y la fine-tuning, y cómo aplicarla de manera responsable. El valor es práctico: los sistemas de IA con sujeción pueden citar fuentes, respetar permisos y reducir respuestas obsoletas. Cuando los flujos de automatización legales se encuentran con validación de tráfico o desafíos de CAPTCHA, CapSolver puede apoyar procesos de prueba compatibles.
Definición de Sujeción de Datos
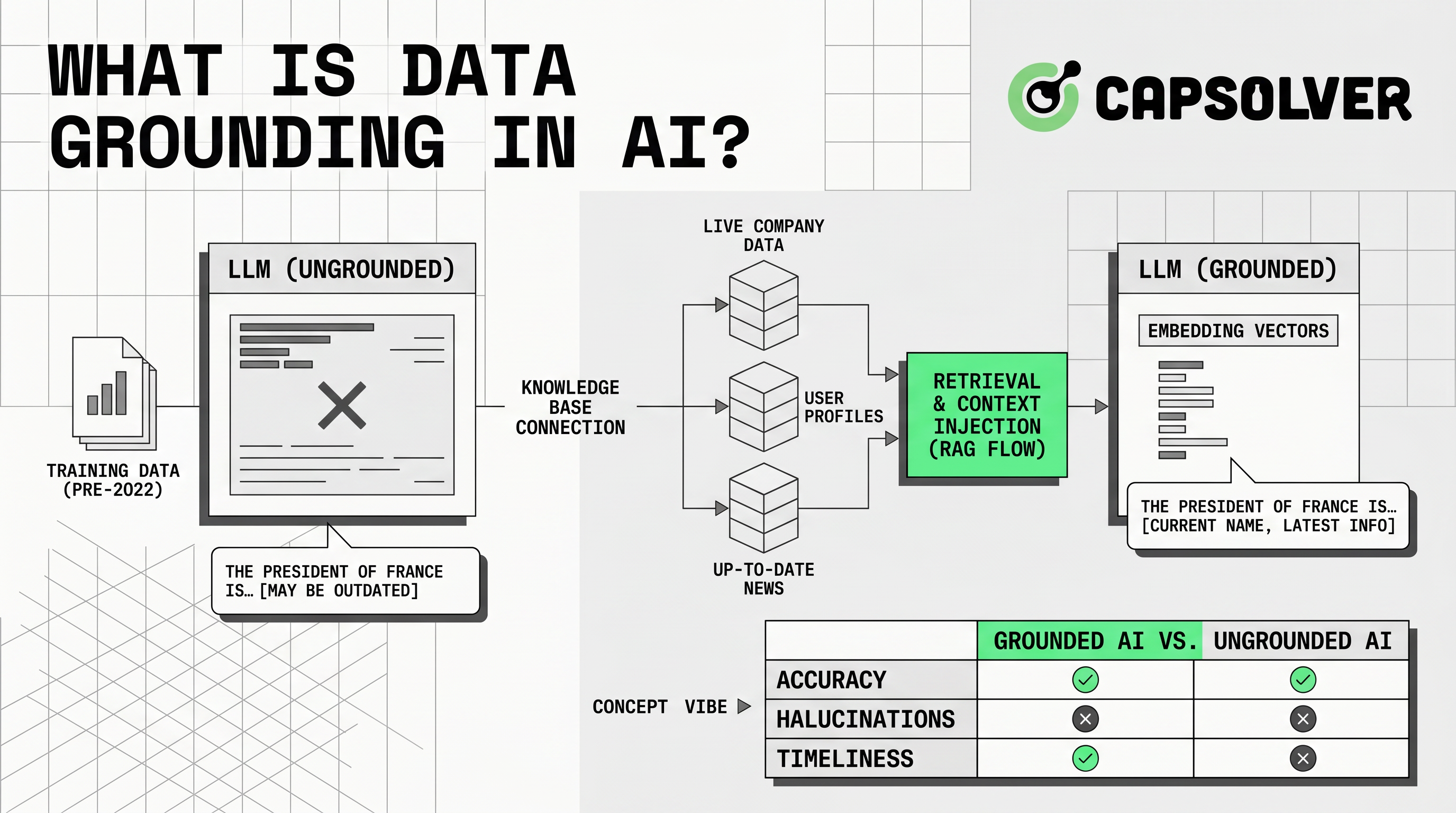
La sujeción de datos significa anclar las respuestas de la IA en contexto externo de confianza. La aplicación proporciona información relevante a un modelo cuando un usuario hace una pregunta. Microsoft define los datos de sujeción como información proporcionada a un modelo de lenguaje en el momento de la inferencia para mejorar la precisión y la relevancia a través de la guía Azure Well-Architected de Microsoft.
La sujeción de datos es importante porque los LLM predicen lenguaje. No conocen automáticamente sus últimos precios, políticas, documentos, registros de clientes o datos del mercado público. Sin contexto confiable, una respuesta puede sonar segura mientras se pierden hechos. Con la sujeción de datos, el sistema puede recuperar material de origen, insertarlo en el prompt y pedirle al modelo que responda a partir de ese material.
La sujeción de datos de la IA no es solo un truco de prompt. Es un patrón de diseño de datos. Incluye selección de fuentes, limpieza, indexación, control de acceso, recuperación, generación de respuestas, citas, evaluación y monitoreo.
¿Por qué la Sujeción de Datos Importa para la Precisión de la IA?
La sujeción de datos mejora la confiabilidad de la IA al reducir el espacio de respuestas del modelo. Google Cloud describe la sujeción empresarial como conectar modelos con información web, datos empresariales, bases de datos, aplicaciones y fuentes confiables para mejorar la completitud y la precisión a través de la verdad empresarial de Google Cloud.
Esto es útil para dominios que cambian rápidamente. El inventario, las políticas de soporte, la documentación, los precios y los horarios de eventos cambian con frecuencia. Un modelo entrenado hace meses no puede conocer cada actualización. La sujeción de datos da al aplicativo un camino para información fresca sin reentrenar el modelo todos los días.
La sujeción de datos también ayuda a los equipos a explicar respuestas. Las citas, las marcas de tiempo y los campos de fuente respaldan la QA, la revisión de cumplimiento y la confianza del usuario.
Cómo Funciona la Sujeción de Datos
La sujeción de datos funciona a través de un flujo de recuperación y generación. El sistema primero identifica qué fuentes son confiables. Luego prepara esas fuentes para la búsqueda. Las fuentes comunes incluyen centros de ayuda, manuales, APIs, bases de datos SQL, índices vectoriales, alimentaciones de productos y páginas públicas aprobadas.
El siguiente paso es la ingestión. Los equipos limpian documentos, eliminan duplicados, estandarizan metadatos, dividen el contenido en fragmentos y lo almacenan en un índice de búsqueda. El índice puede usar búsqueda de palabras clave, búsqueda vectorial, búsqueda híbrida o búsqueda de grafos. Microsoft recomienda externalizar los datos de sujeción a un índice de búsqueda cuando mejore la recuperación, el rendimiento y la protección del sistema de fuentes a través de diseño de datos de sujeción de IA.
Cuando un usuario hace una pregunta, el sistema recupera registros relevantes. Filtra por permisos, frescura, idioma, región o línea de producto. Luego agrega el contexto recuperado al prompt del modelo. El modelo responde a partir de ese contexto y puede devolver citas de fuentes.
La sujeción de datos tiene éxito cuando la recuperación es precisa. Los sistemas sólidos miden relevancia, fidelidad, latencia y cobertura de fuentes.
Resumen de Comparación
La sujeción de datos se superpone con varios métodos de IA. La tabla a continuación muestra la diferencia práctica.
| Método | Propósito principal | Mejor caso de uso | Limitación clave |
|---|---|---|---|
| Sujeción de datos | Anclar respuestas en contexto de confianza | Respuestas actuales respaldadas por fuentes | Requiere recuperación y gobernanza sólidas |
| RAG | Recuperar documentos antes de la generación | Preguntas y agentes de soporte de base de conocimiento | Puede recuperar contexto irrelevante o obsoleto |
| Fine-tuning | Cambiar el comportamiento del modelo a través de ejemplos | Comportamiento de estilo, formato o dominio | No es ideal para cambiar hechos |
| Ingeniería de prompts | Guiar el comportamiento con instrucciones | Tareas pequeñas y formato de respuesta | No puede suministrar hechos faltantes solo |
| Guardias | Enforzar políticas y controles de salida | Verificaciones de seguridad, formato y cumplimiento | No puede reemplazar contexto de fuente verificada |
Esta comparación muestra por qué la sujeción de datos es más amplia que RAG. RAG es un patrón de implementación común. La sujeción de datos es la disciplina completa de conectar la salida del modelo con evidencia confiable.
Fuentes Comunes de Sujeción de Datos
La sujeción de datos comienza con la calidad de las fuentes. Los equipos deben clasificar las fuentes por autoridad, frescura, propiedad y nivel de permiso.
Las fuentes internas suelen proporcionar el mayor valor empresarial. Estas incluyen registros de CRM, tickets, políticas, sistemas de inventario, especificaciones de productos y bases de conocimiento. Requieren control de acceso estricto.
Las fuentes externas añaden frescura y amplitud. Estas incluyen documentación oficial, orientación gubernamental, conjuntos de datos públicos, organismos de estándares y datos de mercado reputables. NIST afirma que su Marco de Gestión de Riesgos de IA ayuda a las organizaciones a gestionar riesgos para individuos, organizaciones y sociedad a través de NIST AI RMF. Tales fuentes son útiles al escribir políticas para sistemas de IA confiables.
Los datos de la web pública pueden apoyar el monitoreo del mercado, la investigación de SEO y el análisis competitivo. Los equipos deben mantenerlos legales y razonables. Deben respetar los términos del sitio, los límites de velocidad, las directrices aplicables de robots y las obligaciones de privacidad. Los recursos de CapSolver sobre IA y automatización y flujos de automatización son puntos de partida útiles para procesos responsables.
Un Flujo de Trabajo de Producción para la Sujeción de Datos
La sujeción de datos funciona mejor con un modelo operativo claro. Primero, defina el límite de la respuesta. Decida qué puede responder la IA, qué fuentes puede usar y cuándo debe rechazar o escalar.
Segundo, prepare los datos. Elimine duplicados, registros obsoletos, campos privados y texto ruidoso. Añada metadatos como propietario, fecha, región, producto, idioma y nivel de permiso. Esto hace que la recuperación sea más precisa.
Tercero, diseñe la recuperación. Use búsqueda de palabras clave para términos exactos, búsqueda vectorial para similitud semántica y filtros para registros permitidos.
Cuarto, evalúe el rendimiento. Cree un conjunto de pruebas de preguntas reales. Puntué la relevancia de la recuperación, la fidelidad de la respuesta, la precisión de las citas y la latencia. Revise casos extremos con expertos en el dominio. No dependa solo de la confianza del modelo.
Quinto, monitoree el desfasamiento. La sujeción de datos puede fallar cuando los documentos se vuelven obsoletos, los índices fallan, los permisos cambian o el propósito del usuario se desvía. Los sistemas críticos necesitan verificaciones automatizadas de frescura y caminos de revisión humana.
Consideraciones de Cumplimiento y Seguridad
La sujeción de datos debe respetar límites legales, de privacidad y de seguridad. El acceso técnico no significa permiso. Los sistemas de IA con sujeción deben evitar datos privados, restringidos, sensibles o no autorizados, a menos que la organización tenga una base legal clara y permiso del usuario.
Los riesgos de seguridad también importan. OWASP enumera inyección de comandos, divulgación de información sensible, agencia excesiva y dependencia excesiva entre los principales riesgos para aplicaciones de LLM a través de OWASP Top 10 for LLM Applications. La sujeción de datos puede reducir afirmaciones no respaldadas, pero puede introducir riesgos si la recuperación acepta contenido malicioso o expone registros protegidos.
Los equipos deben usar recuperación consciente de permisos. Deben limpiar texto no confiable, registrar IDs de fuentes en lugar de registros sensibles y separar datos por clasificación.
Los equipos de automatización necesitan cuidado adicional. La recolección de datos web debe enfocarse en datos públicos permitidos, tasas de solicitud razonables y propósitos comerciales documentados. Cuando aparezcan desafíos de CAPTCHA en QA autorizados, monitoreo o flujos de datos, los equipos deben tratarlos como parte de la validación de tráfico. El artículo de CapSolver sobre recolección de datos de la web pública y su guía sobre desafíos de CAPTCHA pueden ayudar a los equipos a comprender el contexto operativo.
Dónde Encaja CapSolver en Flujos de IA Responsables
CapSolver es relevante cuando la sujeción de datos depende de flujos de automatización legales. Algunos equipos recopilan datos públicos para monitoreo de precios, verificación de SEO, verificación de anuncios, pruebas de QA o investigación. Estos flujos pueden enfrentar desafíos de CAPTCHA durante navegación o pruebas normales.
CapSolver puede ayudar a los equipos a manejar esos desafíos a través de un servicio diseñado para entornos de automatización. La recomendación es estrecha y orientada al cumplimiento. Úselo solo donde tenga autorización, respete las reglas aplicables y evite datos restringidos o sensibles. Los equipos pueden revisar productos de CapSolver para entender escenarios compatibles y alinearlos con flujos aprobados.
Redime tu código de bono de CapSolver
¡Aumenta tu presupuesto de automatización instantáneamente!
Usa el código de bono CAP26 al recargar tu cuenta de CapSolver para obtener un 5% adicional en cada recarga — sin límites.
Redímelo ahora en tu Panel de CapSolver
La sujeción de datos y el manejo de CAPTCHA no deben mezclarse casualmente. La capa de sujeción decide qué evidencia puede usar la IA. La capa de automatización recopila o verifica datos bajo reglas aprobadas. Mantener estas capas separadas facilita las auditorías y reduce el riesgo operativo.
Métricas Prácticas para Sistemas de IA con Sujeción
La sujeción de datos necesita estándares de calidad medibles. La relevancia de recuperación pregunta si el contexto recuperado responde a la pregunta. Una puntuación baja significa que el modelo trabaja con evidencia débil.
La fidelidad de la respuesta pregunta si la respuesta permanece dentro de las fuentes recuperadas. Esto importa porque respuestas fluidas aún pueden agregar detalles no respaldados.
La precisión de las citas verifica si cada fuente citada respalda la oración que sigue. La frescura rastrea la edad del documento, el momento de la actualización del índice y la frecuencia de actualización de la fuente. La calidad de rechazo verifica si el sistema dice cuando falta evidencia.
Conclusión y CTA
La sujeción de datos es una de las formas más prácticas de hacer que los sistemas de IA sean más confiables. Conecta respuestas a contexto de confianza, mejora la frescura, respalda citas y ayuda a los equipos a gestionar riesgos. RAG suele ser parte de la solución, pero la sujeción de datos de grado de producción también necesita datos limpios, permisos sólidos, evaluación, monitoreo y prácticas responsables de automatización.
Si su flujo de trabajo de IA depende de monitoreo de datos públicos, automatización del navegador, pruebas de QA o investigación, planifique cuidadosamente la canalización de datos. Mantenga el acceso a fuentes legal. Proteja datos sensibles. Revise salidas antes de usarlas para decisiones importantes. Para flujos aprobados que enfrenten desafíos de CAPTCHA, considere evaluar CapSolver como parte de una pila de automatización compatible.
Preguntas Frecuentes
¿Qué es la sujeción de datos en la IA?
La sujeción de datos es el proceso de conectar respuestas de IA con contexto de confianza. El contexto puede provenir de documentos, bases de datos, APIs, índices de búsqueda o fuentes públicas aprobadas. Ayuda al modelo a responder desde evidencia en lugar de depender solo de datos de entrenamiento.
¿Es la sujeción de datos lo mismo que RAG?
No. RAG es una forma común de implementar la sujeción de datos. La sujeción de datos es más amplia. Incluye gobernanza de fuentes, indexación, permisos, evaluación de recuperación, citas, monitoreo y reglas de escalado.
¿Por qué la sujeción de datos reduce respuestas de IA no respaldadas?
La sujeción de datos reduce respuestas no respaldadas porque da al modelo evidencia relevante en el momento de la inferencia. El modelo puede responder desde contexto actual en lugar de llenar vacíos solo con patrones estadísticos.
¿Qué datos deben usarse para la sujeción de datos para LLM?
Use datos que sean precisos, permitidos, actualizados y relevantes. Buenos ejemplos incluyen documentación oficial, registros de productos, políticas de soporte, bases de conocimiento, conjuntos de datos públicos y bases de datos empresariales aprobadas. Evite datos privados o restringidos sin autorización adecuada.
¿Cómo deben los equipos aplicar la sujeción de datos de manera responsable?
Los equipos deben definir reglas de fuentes, hacer cumplir controles de acceso, monitorear la calidad de recuperación y revisar salidas de alto impacto. Los equipos de automatización deben recopilar datos legalmente, respetar las reglas del sitio y usar servicios relacionados con CAPTCHA solo en flujos autorizados.
Ver más
Web ScrapingJul 22, 2026
Monitoreo de Regresión en SEO Técnico: Pipeline de Automatización
Construir un monitoreo de regresión de SEO técnico con líneas base versionadas, diferencias semánticas, alertas verificadas y un paso opcional de recuperación CAPTCHA autorizado.
CloudflareJul 22, 2026
Solucionador de CAPTCHA MCP: Guía de Integración de Cloudflare Turnstile
Construya un flujo de trabajo de MCP de Cloudflare Turnstile con CapSolver, reintentos limitados, registros con datos eliminados, verificaciones de sesión y validación de resultados.