ReCAPTCHA en el scraping de comercio electrónico: Una guía con enfoque en cumplimiento

Aloísio Vítor
Image Processing Expert
TL;DR
- ReCAPTCHA aparece cuando los sitios de comercio electrónico necesitan verificaciones de confianza más fuertes.
- Trata a ReCAPTCHA como una señal de flujo de trabajo, no solo como un rompecabezas.
- Verifica los permisos, robots.txt, términos y el alcance de los datos primero.
- Reduce desafíos innecesarios mediante pausas y sesiones estables.
- Usa APIs oficiales o fuentes de datos cuando existan.
- Usa CapSolver solo para automatización legítima y trabajo de datos autorizado.
- Mantén registros, límites de frecuencia y reglas de escalado para cada rastreador.
Introducción
El manejo de ReCAPTCHA en el scraping de comercio electrónico debe realizarse con un proceso orientado al cumplimiento. La respuesta correcta no es un rastreo más agresivo. Es un flujo de trabajo más limpio que respeta los permisos, reduce el tráfico ruidoso y utiliza un paso documentado para resolverlo solo cuando sea permitido. Esta guía está dirigida a ingenieros de datos, equipos de SEO, analistas de precios y equipos de crecimiento que recolecten datos de comercio electrónico públicos de manera responsable. Explica por qué aparece ReCAPTCHA, cuándo reducir la velocidad y cuándo CapSolver se ajusta a un proceso legítimo.
¿Por qué los rastreadores de comercio electrónico encuentran ReCAPTCHA?
ReCAPTCHA aparece porque los sitios de comercio electrónico protegen flujos valiosos de clientes y negocios. Las páginas de productos, páginas de búsqueda, carritos y registros de inicio de sesión tienen riesgos comerciales. Google describe ReCAPTCHA como un servicio que protege sitios web contra spam y abuso utilizando un análisis de riesgo avanzado para distinguir entre humanos y bots a través de señales y puntuaciones documentación de ReCAPTCHA de Google.
Los equipos de comercio electrónico añaden ReCAPTCHA porque el tráfico automatizado ahora es común. Thales e Imperva informaron que el tráfico automatizado alcanzó el 51% del tráfico web en 2024. También informaron que el tráfico automatizado dañino representó el 37% del tráfico de internet, mientras que los ataques dirigidos por API alcanzaron el 44% del tráfico de bots avanzados Informe de bots maliciosos de Imperva 2025. Este contexto explica por qué los sitios desafían rápidamente los patrones de rastreo inusuales.
ReCAPTCHA también es común cerca de flujos de pago y cuenta. Google Cloud dice que Transaction Defense para ReCAPTCHA ayuda a proteger transacciones de pago contra ataques de carding y transacciones fraudulentas Transaction Defense de Google Cloud. Un rastreador que toque páginas de carrito, pago o cuenta enfrenta controles más estrictos que un monitoreo público de productos.
Primera regla: Confirma que los datos son permitidos
El cumplimiento viene antes de los cambios técnicos. Un rastreador debe recolectar solo datos públicos, autorizados y necesarios. Debe evitar páginas de inicio de sesión, datos privados de clientes, pasos de pago y áreas restringidas sin autorización explícita.
El Protocolo de Exclusión de Robots también es importante. RFC 9309 dice que robots.txt da a los propietarios de servicios una forma de controlar cómo los rastreadores acceden al espacio URI, y se pide a los rastreadores que respeten esas reglas Protocolo de Exclusión de Robots RFC 9309. robots.txt no es la única prueba legal. Sin embargo, los rastreadores responsables deben analizarlo antes de ejecutarlo.
Antes de manejar ReCAPTCHA, documenta cuatro elementos. Define el propósito comercial, las páginas de origen, los campos de datos, los caminos permitidos, los términos, los límites de solicitud, la concurrencia y el período de retención. Esto convierte el manejo de ReCAPTCHA en un proceso de datos gobernado.
La guía de CapSolver sobre qué es ReCAPTCHA puede ayudar a los responsables a entender el tipo de desafío.
Diagnóstico del tipo de ReCAPTCHA
El diagnóstico debe ocurrir antes de cambios en el código. ReCAPTCHA v2 a menudo aparece como una casilla de verificación o un desafío visual. ReCAPTCHA v3 normalmente devuelve una puntuación sin interacción del usuario, por lo que la página puede degradarse, bloquear una acción o pedir una verificación más fuerte más tarde. Google señala que ReCAPTCHA v3 devuelve una puntuación para que los propietarios de sitios elijan una acción sin mostrar un desafío a los usuarios visión general de ReCAPTCHA v3 de Google.
| Situación | Significado probable | Respuesta recomendada |
|---|---|---|
| El desafío aparece después de muchas solicitudes rápidas | El patrón de tráfico parece anormal | Reducir la concurrencia y agregar pausas |
| El desafío aparece solo en inicio de sesión o pago | La página es de alto riesgo | Detenerse a menos que esté explícitamente autorizado |
| El desafío aparece en páginas públicas de productos | El patrón de sesión o solicitud necesita revisión | Estabilizar las cookies y reducir los picos |
| La puntuación v3 causa páginas vacías o degradadas | La puntuación de confianza es baja | Revisar el contexto del navegador y la frecuencia de las solicitudes |
| El desafío aparece después de redirecciones | El estado del flujo es inconsistente | Mantener la sesión y el orden de las páginas |
Este diagnóstico también controla los costos. Un rastreador más calmado suele desencadenar menos desafíos y devolver datos de comercio electrónico más limpios.
Resumen de comparación
Un rastreador de comercio electrónico útil comienza con la opción menos intrusiva. La tabla a continuación compara casos comunes.
| Enfoque | Caso de uso ideal | Notas de cumplimiento | Riesgo operativo | Perfil de costo |
|---|---|---|---|---|
| API oficial o fuente del comerciante | Acceso a datos con socios | Mejor opción cuando esté disponible | Bajo | Predecible |
| Scraping de páginas públicas con pausas | Monitoreo de productos y precios públicos | Respetar robots.txt y términos | Medio | Bajo a medio |
| Automatización del navegador | Páginas de productos con JavaScript | Evitar flujos restringidos | Medio | Medio |
| Cola de revisión humana | Verificaciones de alto valor raras | Rastro de auditoría fuerte | Bajo | Mayor costo laboral |
| Integración de CapSolver | Automatización autorizada que encuentra ReCAPTCHA | Usar solo para flujos legales y benéficos | Medio | Basado en uso |
La tabla muestra un punto práctico. ReCAPTCHA debe ser un camino de excepción dentro de un rastreador que respete las reglas y límites.
Construye un flujo de scraping de comercio electrónico más limpio
Un flujo más limpio reduce desafíos innecesarios de ReCAPTCHA. Comienza con la selección de páginas. Rastrea solo categorías o páginas de productos públicos y permitidos. Evita agregar artículos al carrito, enviar formularios o abrir páginas de cuenta a menos que el negocio posea la cuenta y tenga permiso.
A continuación, controla la forma del tráfico. Usa concurrencia moderada, reglas de retroceso y programación estable. Los sitios de comercio electrónico son sensibles durante ventas, lanzamientos y picos de vacaciones. Un rastreador que respete esos períodos es menos probable que genere estrés operativo.
El manejo de sesiones también importa. Mantén las cookies consistentes durante un rastreo corto. No mezcles flujos de páginas no relacionadas dentro de una misma sesión. Un camino de descubrimiento de productos no debe solicitar repentinamente páginas de pago. Este patrón puede hacer que aparezca ReCAPTCHA.
Rastrea la tasa de desafíos, páginas vacías, códigos HTTP, fallos en el análisis de precios y duplicados. Un aumento en la tasa de ReCAPTCHA es una alerta temprana.
Si tu equipo elige entre el rastreo directo y el acceso a datos oficiales, este artículo de CapSolver sobre scraping web versus APIs es un enlace útil para discusiones internas.
Dónde se ajusta CapSolver
CapSolver se ajusta cuando un proceso de automatización legítimo encuentra ReCAPTCHA tras verificar cumplimiento. Es útil para auditorías de SEO, verificación de anuncios y rastreadores benignos cuando los datos objetivo son permitidos. La posición de CapSolver establece que actividades ilegales, fraudulentas o abusivas están prohibidas, y enumera casos de uso como SEO, verificación de anuncios, rastreadores benignos y escenarios de crecimiento empresarial declaración de cumplimiento de CapSolver.
Esta posición es importante. Una integración de CapSolver nunca debe apuntar a cuentas privadas, pasos de pago, contenido restringido o datos claramente no permitidos.
CapSolver es especialmente relevante cuando tu rastreador ya sigue un ritmo respetuoso pero aún así encuentra ReCAPTCHA en páginas públicas permitidas. Puede ayudar a mantener un flujo estable sin forzar trabajo manual para cada desafío. Para un escenario de comercio electrónico enfocado, consulta la guía de CapSolver sobre cómo resolver CAPTCHAs al raspar sitios web de comercio electrónico.
Referencia de código oficial de CapSolver
El siguiente código sigue la documentación oficial de CapSolver para ReCAPTCHA v2. No cambies el tipo de tarea o los parámetros sin revisar la documentación actual. Úsalo solo en flujos autorizados y con una clave de API válida.
python
# pip install requests
import requests
import time
# TODO: configure su configuración
api_key = "SU_CLAVE_DE_API" # su clave de API de capsolver
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # clave del sitio de su sitio objetivo
site_url = "https://www.google.com/recaptcha/api2/demo" # URL de la página de su sitio objetivo
def capsolver():
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print("No se pudo crear la tarea:", res.text)
return
print(f"Obtuve taskId: {task_id} / Obteniendo resultado...")
while True:
time.sleep(1) # retraso
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
return resp.get("solution", {}).get('gRecaptchaResponse')
if status == "failed" or resp.get("errorId"):
print("¡Falló la resolución! respuesta:", res.text)
return
token = capsolver()
print(token)La documentación oficial de CapSolver dice que crear la tarea con createTask y recuperar el resultado con getTaskResult. También explica que campos como websiteURL y websiteKey son necesarios para la tarea. Para más contexto de implementación, lee la guía oficial de CapSolver sobre cómo resolver ReCAPTCHA en el scraping web usando Python.
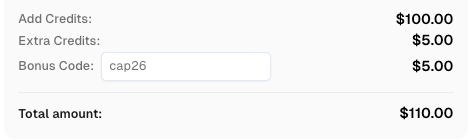
Redime tu código de bono de CapSolver
¡Aumente su presupuesto de automatización de inmediato!
Use el código de bono CAP26 al recargar su cuenta de CapSolver para obtener un bono adicional del 5% en cada recarga — sin límites.
Redímalo ahora en su Panel de CapSolver
Controles prácticos para producción
El scraping de comercio electrónico en producción necesita controles que puedan auditar no ingenieros. Crea una política de rastreador antes de la implementación. La política debe nombrar al propietario de los datos, dominios permitidos, caminos permitidos, concurrencia máxima, solicitudes diarias máximas, período de retención y contacto de escalado.
Usa la tasa de encuentro de ReCAPTCHA como métrica clave. Si la tasa supera un umbral definido, reduce la velocidad de rastreo o pausa. Si los desafíos aparecen en flujos restringidos, detén el trabajo. Si un objetivo cambia su robots.txt o términos, revisa el rastreador antes de continuar.
Mantén los datos estrechos. Precios, disponibilidad, título, URL de imagen y cantidad de reseñas públicas pueden ser válidos para algunos casos de negocio. Nombres de clientes, reseñas privadas detrás de inicio de sesión, tokens de carrito y datos de cuenta deben mantenerse fuera del alcance a menos que el propietario del sitio haya autorizado el acceso.
También es aquí donde una cola de respaldo ayuda. Un rastreador puede almacenar páginas no resueltas para revisión en lugar de reintentar repetidamente. Esa elección de diseño reduce la carga, el costo y mantiene el manejo de ReCAPTCHA defensable.
Para patrones adicionales de ingeniería, el artículo de CapSolver sobre tres formas de resolver CAPTCHA al raspar puede apoyar en la planificación de implementación.
Errores comunes a evitar
El primer error es tratar ReCAPTCHA solo como un obstáculo técnico. Es a menudo una señal de que el rastreador es demasiado amplio, rápido o fuera del flujo previsto. Arregla el flujo antes de añadir herramientas.
El segundo error es ignorar el contexto de la página. Los sitios de comercio electrónico tratan páginas de búsqueda, productos, carrito, inicio de sesión y pago de manera diferente. Tu rastreador debe hacer lo mismo. El monitoreo de productos públicos tiene un perfil de riesgo diferente al de la automatización de cuentas.
El tercer error es omitir los registros de auditoría. Cada evento de ReCAPTCHA debe registrar el grupo de URL, marca de tiempo, versión del rastreador, código de respuesta y acción tomada.
El cuarto error es usar código obsoleto. Las implementaciones de ReCAPTCHA cambian. La documentación de CapSolver debe ser la fuente para la estructura del código, tipos de tarea y campos necesarios.
Conclusión y CTA
ReCAPTCHA en scraping de comercio electrónico se maneja mejor mediante gobernanza, diagnóstico y herramientas cuidadosas. Comienza con verificaciones de permisos, robots.txt, términos y minimización de datos. Luego reduce desafíos innecesarios con pausas, sesiones estables y alcance limitado. Si ReCAPTCHA aún aparece en un proceso de automatización legal y autorizado, CapSolver puede proporcionar una capa de resolución práctica basada en la documentación oficial.
Si su equipo necesita un modo controlado para manejar ReCAPTCHA durante la recolección de datos de comercio electrónico, revise la documentación de CapSolver, defina sus reglas de cumplimiento y pruébelo primero en páginas públicas de bajo volumen. Un rastreador responsable debe recopilar solo lo que necesita, detenerse cuando cambien las reglas y dejar un registro claro de auditoría.
Preguntas frecuentes
¿Es legal manejar ReCAPTCHA durante el scraping de comercio electrónico?
Depende de los permisos, el tipo de datos, la jurisdicción y los términos del sitio. Un flujo más seguro usa páginas permitidas públicas, respeta robots.txt, evita datos privados y sigue límites documentados. Es recomendable una revisión legal para proyectos comerciales.
¿Por qué aparece ReCAPTCHA en páginas de productos?
ReCAPTCHA puede aparecer cuando el volumen de solicitudes, el historial de sesión, el contexto del navegador o el momento del tráfico parece inusual. También puede aparecer porque el sitio aplica protección estricta a páginas de precios y disponibilidad.
¿Debo resolver cada ReCAPTCHA que vea?
No. Una alta tasa de ReCAPTCHA generalmente significa que el rastreador necesita revisión. Ralentiza, reduce el alcance, revisa los caminos permitidos y usa la resolución solo para casos de excepción autorizados.
¿Puede ayudar CapSolver con el scraping de comercio electrónico?
Sí, CapSolver puede ayudar cuando un flujo de trabajo de automatización de comercio electrónico legítimo se encuentra con recaptcha. Úsalo solo para trabajos de datos legales, benévolos y permitidos, y sigue la documentación oficial.
¿Qué debo monitorear después del despliegue?
Monitorizar la tasa de recaptcha, códigos de estado, errores de análisis, volumen, grupos de rutas y colas no resueltas. Pausa el raspador cuando se excedan los límites.
Ver más
AIJun 26, 2026
CAPTCHA: El componente faltante en la infraestructura de agentes de IA
Descubre por qué gestionar la validación del tráfico es el componente faltante en la infraestructura de agentes de IA. Aprende cómo integrar soluciones robustas para agentes autónomos.
AIJun 26, 2026
Cómo los agentes de IA manejan los CAPTCHAs a gran escala
- Los agentes de IA requieren infraestructura robusta para manejar CAPTCHAS a gran escala durante operaciones web automatizadas. - Los sistemas modernos de validación de tráfico utilizan análisis de comportamiento y huella digital de dispositivos para detectar solicitudes automatizadas. - Integrar una API de resolución de CAPTCHA confiable garantiza operación continua para agentes autónomos. - Las arquitecturas distribuidas y la rotación de proxies son esenciales para gestionar alto volumen.