Mejores bibliotecas de scraping web en Java para una extracción de datos confiable

Aloísio Vítor
Image Processing Expert
Por favor, traduzca el siguiente texto en inglés a es y devuelva solo la traducción, tenga en cuenta: no escape los símbolos especiales en código:

TL;DR
- Las bibliotecas de scraping web en Java deben elegirse según el tipo de página, no por popularidad.
- jsoup es ideal para el análisis de HTML estático y la extracción basada en selectores.
- Selenium Java scraping se adapta a páginas que requieren acciones de navegador real.
- Playwright para Java es fuerte en flujos modernos con JavaScript intensivo.
- HtmlUnit funciona para tareas ligeras similares a un navegador sin un navegador completo.
- Apache Nutch es adecuado para el rastreo y indexación empresarial.
- Una API de scraping web es mejor cuando los CAPTCHA, la escala y las operaciones dominan.
Introducción
Las mejores bibliotecas de scraping web en Java dependen de cómo entrega la página objetivo los datos. Las páginas estáticas necesitan un análisis rápido. Las páginas dinámicas necesitan automatización de navegadores. Los programas de rastreo grandes necesitan colas, indexación y monitoreo. Los flujos de CAPTCHA necesitan un servicio documentado, no lógica frágil. Esta guía ayuda a los desarrolladores a elegir entre jsoup, Selenium Java scraping, Playwright para Java, HtmlUnit, Apache Nutch, opciones de marco de rastreador Java y una API de scraping web. Usa la herramienta más pequeña y confiable, sigue las reglas del sitio y mantén los flujos de trabajo mantenibles.
¿Por qué se usa Java para el scraping web?
Java es un lenguaje sólido para scraping cuando los proyectos deben ejecutarse durante meses, no minutos. Soporta código tipado, gestión estable de dependencias, clientes HTTP maduros y observabilidad amigable para producción. Oracle describe Java como una plataforma de desarrollo principal para reducir el tiempo de desarrollo y ejecutar aplicaciones en entornos a través del modelo Java Java de Oracle.
Las bibliotecas de scraping web en Java también se adaptan a hábitos empresariales. Los equipos pueden agregar reintentos, registros, límites de velocidad, pruebas y controles de acceso. Java puede no ser el más rápido para prototipos. Se vuelve atractivo cuando la fiabilidad y el mantenimiento importan.
La clave es alinear las herramientas al contenido. Un analizador no puede renderizar una página React. Un navegador puede ser un gasto innecesario para HTML estático. Un marco de rastreador puede ser demasiado pesado para una sola página de producto. Las mejores bibliotecas de scraping web en Java resuelven un problema definido.
Resumen de comparación
| Herramienta | Mejor para | Manejo de JavaScript | Adecuación a escala | Limitación principal |
|---|---|---|---|---|
| jsoup | Análisis de HTML estático | No | Medio | Necesita otras herramientas para renderizado |
| HttpClient + jsoup | Scraping estático controlado | No | Medio a Alto | Requiere lógica de búsqueda personalizada |
| Selenium | Automatización del navegador | Fuerte | Bajo a Medio | Tiempo de ejecución pesado y selectores frágiles |
| Playwright para Java | Automatización de navegadores modernos | Fuerte | Medio | Requiere gestión de tiempo de ejecución del navegador |
| HtmlUnit | Flujos ligeros similares a un navegador | Parcial a Bueno | Medio | No es un reemplazo completo del navegador |
| WebMagic o Gecco | Proyectos de marco de rastreador Java | Limitado | Medio | Ecosistema más pequeño |
| Apache Nutch | Rastreo y indexación empresarial | Limitado | Alto | Configuración y operaciones complejas |
| API de scraping web | Operaciones de scraping gestionadas | Manejado por proveedor | Alto | Menor control directo |
Bibliotecas de scraping web estático en Java
El scraping estático debe comenzar con analizadores. Si la primera respuesta HTML contiene los datos necesarios, la automatización del navegador agrega costo sin mejorar la precisión. Las bibliotecas de scraping web en Java en esta categoría son rápidas, probables y fáciles de operar.
jsoup para análisis de HTML
jsoup es la primera elección para HTML estático. Su sitio oficial lo describe como un analizador de HTML para Java en HTML y XML reales, con búsqueda de URL, análisis, métodos DOM, selectores CSS y selectores XPath documentación oficial de jsoup.
Usa jsoup para páginas de artículos, páginas de categorías, páginas de productos simples, tablas y fragmentos de HTML. Maneja bien la marcación imperfecta. Eso importa porque muchas páginas son legibles por navegadores pero no limpias suficiente para herramientas XML estrictas.
Un flujo de trabajo confiable de jsoup es directo. Solicita la página con encabezados claros. Analiza el documento. Selecciona campos con selectores CSS estables. Valida valores vacíos antes del almacenamiento. Este patrón mantiene las bibliotecas de scraping web en Java predecibles.
jsoup no es un navegador. No ejecuta JavaScript. Si el contenido aparece solo después de que se ejecuten scripts, inspecciona primero las llamadas de red. Si existen puntos finales permitidos, úsalos con un cliente HTTP. Si se requiere comportamiento de navegador, usa Selenium o Playwright para Java.
Enfoque HttpClient + jsoup
HttpClient más jsoup es ideal para scraping estático controlado. El cliente HTTP de Java puede manejar encabezados, tiempos de espera, redirecciones y cuerpos de respuesta. jsoup luego analiza el HTML. Esta separación mantiene la búsqueda y el análisis limpios.
Este enfoque funciona para monitoreo de precios, directorios públicos, auditorías de contenido y conjuntos de datos de investigación. Es mejor que la búsqueda directa de jsoup cuando necesitas rastreo, reglas de reintentos, retrasos de rastreo o configuración de proxy.
Bibliotecas de scraping web dinámico en Java
Las páginas dinámicas necesitan comportamiento de navegador. Pueden cargar contenido después de desplazarse, hacer clic, autenticarse o solicitudes en segundo plano. Selenium Java scraping, Playwright para Java y HtmlUnit resuelven esto de forma diferente.
Selenium para automatización de navegadores
Selenium es maduro y ampliamente documentado. El proyecto oficial lo describe como herramientas y bibliotecas que permiten automatización de navegadores, con WebDriver como interfaz central para ejecutar instrucciones en navegadores principales documentación de Selenium.
El scraping Java de Selenium funciona cuando los sitios requieren acciones de navegador real. Puede hacer clic en botones, esperar elementos, enviar formularios y leer el DOM renderizado. También se adapta a equipos que ya usan Selenium para pruebas de QA.
El intercambio es costo. Las sesiones del navegador consumen CPU y memoria. Los selectores pueden romperse cuando cambie la interfaz. Usa el scraping Java de Selenium cuando la fidelidad del navegador importe más que la velocidad.
Si aparece un CAPTCHA en pruebas autorizadas o automatización permitida, no lo ocultes en scripts frágiles. Revisa primero las reglas del objetivo. Luego usa un flujo documentado como la integración de CAPTCHA de Selenium de CapSolver.
Playwright para Java
Playwright para Java es fuerte para automatización moderna. Su sitio oficial dice que Playwright puede controlar Chromium, Firefox y WebKit a través de una API, con soporte para Java disponible documentación de Playwright para Java.
Playwright para Java a menudo reduce la automatización frágil. La espera automática, contextos del navegador, registro de trazas y localizadores resistentes ayudan a mantener los flujos estables. Se adapta a proyectos de bibliotecas de scraping web en Java que necesiten capturas de pantalla, descargas, navegación entre páginas o esperas confiables.
Elige Playwright para Java cuando las páginas tengan JavaScript intensivo y los contextos de navegador repetibles importen. Evítalo cuando una solicitud HTTP simple devuelva los mismos datos. Un navegador debe ser la capa necesaria última, no el hábito primero.
Para CAPTCHA en automatización aprobada, conecta el flujo a la guía oficial. CapSolver publica una integración de CAPTCHA de Playwright que es más segura que copiar fragmentos aleatorios.
HtmlUnit para manejo ligero de JS
HtmlUnit se encuentra entre análisis y automatización completa del navegador. Su sitio oficial lo llama "navegador sin interfaz gráfica para programas Java". Puede invocar páginas, completar formularios, hacer clic en enlaces, manejar cookies y proporcionar soporte de JavaScript para muchos flujos AJAX documentación de HtmlUnit.
Usa HtmlUnit para sitios antiguos, flujos de formulario simples, herramientas internas y sistemas de prueba. Es más ligero que la automatización completa del navegador. Eso puede reducir el costo de infraestructura para cargas de trabajo moderadas.
HtmlUnit no es un reemplazo completo para Chrome, Firefox o WebKit. Los marcos modernos de frontend pueden exponer lagunas. Si la renderización visual o eventos complejos importan, Selenium o Playwright para Java son más seguros.
Marcos de scraping web en Java para rastreo a gran escala
El rastreo a gran escala es diferente de la extracción de páginas. Necesita gestión de frontera, deduplicación, reglas de reintentos, controles de cortesía, análisis, indexación y monitoreo. Un marco de rastreador Java ayuda cuando un raspador se convierte en un sistema.
WebMagic y Gecco
WebMagic y Gecco son opciones prácticas para proyectos medianos. Estructuran la lógica del descargador, procesadores de páginas, tuberías y modelos de datos. Eso hace que el código sea más fácil de dividir entre equipos.
Úsalos para catálogos públicos, espejos de documentación, descubrimiento de contenido recurrente y páginas similares. Son menos adecuados para páginas muy dinámicas a menos que se combinen con una capa de renderizado. Su principal fortaleza es la mantenibilidad. Su principal debilidad es un ecosistema más pequeño que jsoup, Selenium o Playwright.
Apache Nutch para rastreo empresarial
Apache Nutch está construido para programas de rastreo grandes. Su página principal lo describe como un rastreador web altamente extensible, escalable, maduro y listo para producción proyecto Apache Nutch. Soporta análisis intercambiable, indexación, puntuación e integraciones con sistemas de búsqueda.
Úsalo cuando el rastreo sea un requisito de plataforma. Se adapta a indexación de búsqueda, descubrimiento empresarial y adquisición de datos a gran escala recurrente. No es ideal para un raspador pequeño de un solo uso. La configuración y operaciones requieren tiempo real de ingeniería.
Antes de escalar cualquier marco de rastreador Java, define dominios permitidos, frecuencia de actualización, reglas de almacenamiento y límites de solicitud. La guía de CapSolver sobre legalidad del scraping web y reglas clave es útil para planificación.
Desafíos de CAPTCHA en scraping Java
El CAPTCHA es una señal de flujo, no solo un problema técnico. Puede indicar presión de velocidad, riesgo de inicio de sesión, reglas de acceso o permiso faltante. Trátalo con cuidado. Confirma que tu caso de uso sea permitido, minimiza el volumen de solicitudes y recopila solo datos necesarios.
Las bibliotecas de scraping web en Java no resuelven el CAPTCHA por sí mismas. Jsoup no puede interactuar con un desafío. Selenium y Playwright pueden mostrar uno, pero aún necesitan un proceso de manejo válido. HtmlUnit rara vez es la capa adecuada para esta tarea.
CapSolver es relevante cuando un proceso de automatización legítimo necesita manejo de CAPTCHA. Ejemplos incluyen pruebas de QA, flujos con cuenta propia y scraping permitido. La documentación oficial de la API de CapSolver lista createTask y getTaskResult como puntos finales principales para creación de tareas y recuperación de resultados documentación de la API de CapSolver. Usa la documentación oficial directamente para detalles de implementación.
Un proceso seguro es simple. Documenta el objetivo, confirma el permiso, limita las tasas de solicitud y almacena solo campos necesarios. La FAQ de CapSolver sobre scraping web y APIs de resolución de CAPTCHA es un recurso útil para planificación.
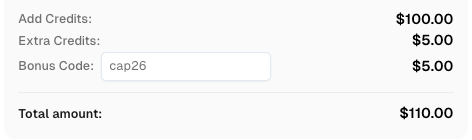
Redime tu código de bonificación de CapSolver
¡Aumenta tu presupuesto de automatización de inmediato!
Usa el código de bonificación CAP26 al recargar tu cuenta de CapSolver para obtener un 5% adicional de bonificación en cada recarga — sin límites.
Redímelo ahora en tu Panel de control de CapSolver
Cuándo usar una API de scraping web en lugar de bibliotecas
Usa una API de scraping web cuando las operaciones importen más que el control del código. Las bibliotecas de scraping web en Java son flexibles, pero los equipos deben manejar tiempos de ejecución del navegador, reintentos, monitoreo, desviación del analizador y flujos de CAPTCHA.
Una API de scraping web tiene sentido para recolección de alto volumen, front ends inestables, páginas con JavaScript intensivo y equipos sin infraestructura de scraping. También puede reducir la necesidad de granjas de navegadores. El intercambio es dependencia de proveedor, por lo que revisa calidad de datos, precios, registros y términos de cumplimiento.
Un modelo híbrido suele ser el mejor. Usa jsoup para páginas estáticas estables. Usa Selenium Java scraping o Playwright para Java para un pequeño conjunto de flujos dinámicos. Usa Apache Nutch cuando el rastreo se convierta en una plataforma de búsqueda. Usa una API de scraping web cuando la infraestructura se convierta en el principal trabajo. La guía de CapSolver sobre desafíos comunes en scraping web puede ayudar a los equipos a prepararse.
Conclusión y CTA
Las mejores bibliotecas de scraping web en Java se clasifican por ajuste, no por hype. Jsoup es mejor para HTML estático. HttpClient más jsoup agrega control. Selenium Java scraping y Playwright para Java manejan páginas dinámicas. HtmlUnit cubre flujos ligeros similares a un navegador. WebMagic, Gecco y Apache Nutch apoyan arquitectura de rastreador. Una API de scraping web ayuda cuando el costo de infraestructura crece.
Empieza pequeño y mantén el cumplimiento. Lee las reglas del sitio, respeta los límites de velocidad, minimiza la recolección y mantén registros. Si aparece un CAPTCHA en un flujo aprobado, usa la documentación oficial y un proveedor dedicado como CapSolver.
Preguntas frecuentes
¿Cuál es la mejor biblioteca de scraping web en Java?
Jsoup es la primera elección para HTML estático. Playwright para Java o Selenium es mejor para páginas con JavaScript intensivo. Apache Nutch es mejor para rastreo empresarial.
¿Es mejor el scraping Java de Selenium que el Playwright para Java?
Selenium tiene mayor historia y soporte del ecosistema. Playwright para Java a menudo ofrece características de automatización moderna más fuertes, incluyendo espera automática y contextos de navegador.
¿Puede jsoup raspar sitios web dinámicos?
Jsoup puede analizar HTML devuelto, pero no ejecuta JavaScript. Usa automatización de navegador cuando el contenido aparezca solo después de que se ejecuten scripts.
¿Es adecuado Apache Nutch para proyectos pequeños de scraping?
Normalmente no. Apache Nutch es poderoso, pero es mejor para sistemas de rastreo grandes, indexación de búsqueda y adquisición de datos empresarial.
¿Cuándo debo usar CapSolver con scraping en Java?
Usa CapSolver solo para automatización legítima y documentada donde el manejo de CAPTCHA sea permitido. Sigue la documentación oficial de la API de CapSolver y las reglas del sitio objetivo.
Ver más
AIJun 23, 2026
Nativos SDKs de Solucionadores de CAPTCHA para Agentes de IA
Una guía orientada a desarrolladores sobre SDKs nativos para resolver CAPTCHA para agentes de inteligencia artificial, con límites de envoltura, ejemplos oficiales, verificaciones de sesión y manejo de errores.
AIJun 23, 2026
Elegir un Servicio de Resolución de CAPTCHA para la Automatización de Agentes
Un checklist práctico para compradores e ingenieros para elegir un servicio de resolución de CAPTCHA para la automatización de agentes en flujos de trabajo controlados y documentados.