Navegador Agente: Cuando el navegador comienza a trabajar proactivamente para ti

Aloísio Vítor
Image Processing Expert

Introducción
Imagina esto: pasas una hora reservando un vuelo, comparando repetidamente precios y completando formularios. En contraste, un Navegador Agente completa la tarea en minutos con solo un comando: "Ayúdame a reservar un asiento de ventanilla para un vuelo de Beijing a Shanghai esta tarde del viernes". Ya no es solo una herramienta de visualización, sino un agente inteligente capaz de comprender la intención y ejecutar tareas de forma autónoma. En los últimos dos años, este concepto se ha acercado a la productivización, con Google Chrome lanzando Auto Browse y Opera lanzando Opera Neon. Este artículo proporcionará una introducción popular sobre cómo funcionan los Navegadores Agentes y el papel crucial que juega la infraestructura como CapSolver en este ecosistema.
Capítulo 1: Reimaginar el Navegador: De "Herramienta de Visualización" a "Agente de Acción"
1.1 El Rol y Limitaciones de los Navegadores Tradicionales
Desde su nacimiento en la década de 1990, el objetivo principal del navegador siempre ha sido la "presentación e interacción de información". Es esencialmente un motor de renderizado pasivo: el usuario ingresa instrucciones y el navegador analiza el DOM y devuelve retroalimentación visual. En este modo unidireccional "humano-operado-máquina", el navegador cumple fielmente el rol de "ventana" al mundo digital.
Sin embargo, a medida que las aplicaciones web han crecido exponencialmente en complejidad, las limitaciones de los navegadores tradicionales se han vuelto cada vez más prominentes:
- Carga Cognitiva Excesiva: Los usuarios deben encontrar objetivos entre una multitud de pestañas, ventanas emergentes y menús anidados, consumiendo energía significativa en "encontrar botones" en lugar de "completar tareas".
- Incapacidad para Automatizar Operaciones Repetitivas: Escenarios de alta frecuencia como la migración de datos entre plataformas, el llenado masivo de formularios y las aprobaciones de varios pasos aún dependen de copiar y pegar manualmente o configuraciones de scripts tediosas.
- Fragmentación Contextual: El navegador no recuerda lo que estabas "haciendo justo ahora" ni entiende lo que "quieres hacer a continuación". Cada interacción es un evento aislado, sin memoria continua a nivel de tarea.
- El Conflicto Entre Seguridad y Experiencia: Para prevenir el spam de bots, los sitios web introducen grandes cantidades de CAPTCHAS, verificaciones de bots y carga dinámica, aumentando aún más la fricción operativa para los usuarios humanos.
Para contrastar claramente las deficiencias de los navegadores tradicionales, podemos organizarlos en dimensiones como el modo de interacción, la comprensión de tareas y la continuidad del proceso, como se muestra en la tabla a continuación:
| Dimensión | Navegador Tradicional | Problemas Principales / Limitaciones |
|---|---|---|
| Modo de Interacción | Controlado por ratón/teclado, operación punto a punto | Operaciones fragmentadas, baja eficiencia |
| Comprensión de Tareas | Solo analiza URL y estructura DOM, sin reconocimiento de intención | No puede manejar instrucciones en lenguaje natural |
| Continuidad del Proceso | Sin estado; conectar entre páginas/sitios requiere conexión manual | Pérdida de contexto, tareas de varios pasos interrumpidas fácilmente |
| Capacidad de Automatización | Depende de complementos o scripts externos (por ejemplo, Selenium) | Alto umbral de configuración, poca resistencia a interferencias |
| Percepción del Entorno | Renderizado estático, no puede entender semántica visual | Impotente ante contenido dinámico, CAPTCHAS y mecanismos anti-escaneo |
Tabla 1-1: Rendimiento y Limitaciones de los Navegadores Tradicionales en Diferentes Dimensiones
En general, los navegadores tradicionales son buenos para "mostrar contenido por instrucción" pero malos para "entender tareas y asistir proactivamente". Esta naturaleza pasiva, fragmentada y sin estado es precisamente el problema central que los Navegadores Agentes buscan resolver.
1.2 Definición del Navegador Agente: Un Navegador que "Actúa" por Ti
Un Navegador Agente no es una simple adición de funciones a un navegador tradicional; es un terminal de interacción de próxima generación que integra profundamente LLM con el núcleo del navegador. Su definición central se puede resumir como: un agente de acción digital con capacidad de comprensión de intención, percepción del entorno, planificación autónoma y ejecución.
Si un navegador tradicional es la "pantalla que miras", un Navegador Agente es el "empleado digital que trabaja para ti". Ya no espera a que los usuarios hagan clic paso a paso, sino que recibe directamente instrucciones en lenguaje natural (por ejemplo, "Ayúdame a transcribir la grabación de la reunión de la semana pasada, resumirla y enviarla al equipo del proyecto"). Luego completa de forma autónoma una serie de operaciones en el entorno del navegador, como abrir aplicaciones, encontrar archivos, llamar a herramientas de IA, editar documentos y enviar correos electrónicos.
Su operación subyacente depende de una arquitectura completa de agente. La figura 1-1 presenta de forma intuitiva los módulos principales y el flujo de datos de esta arquitectura:
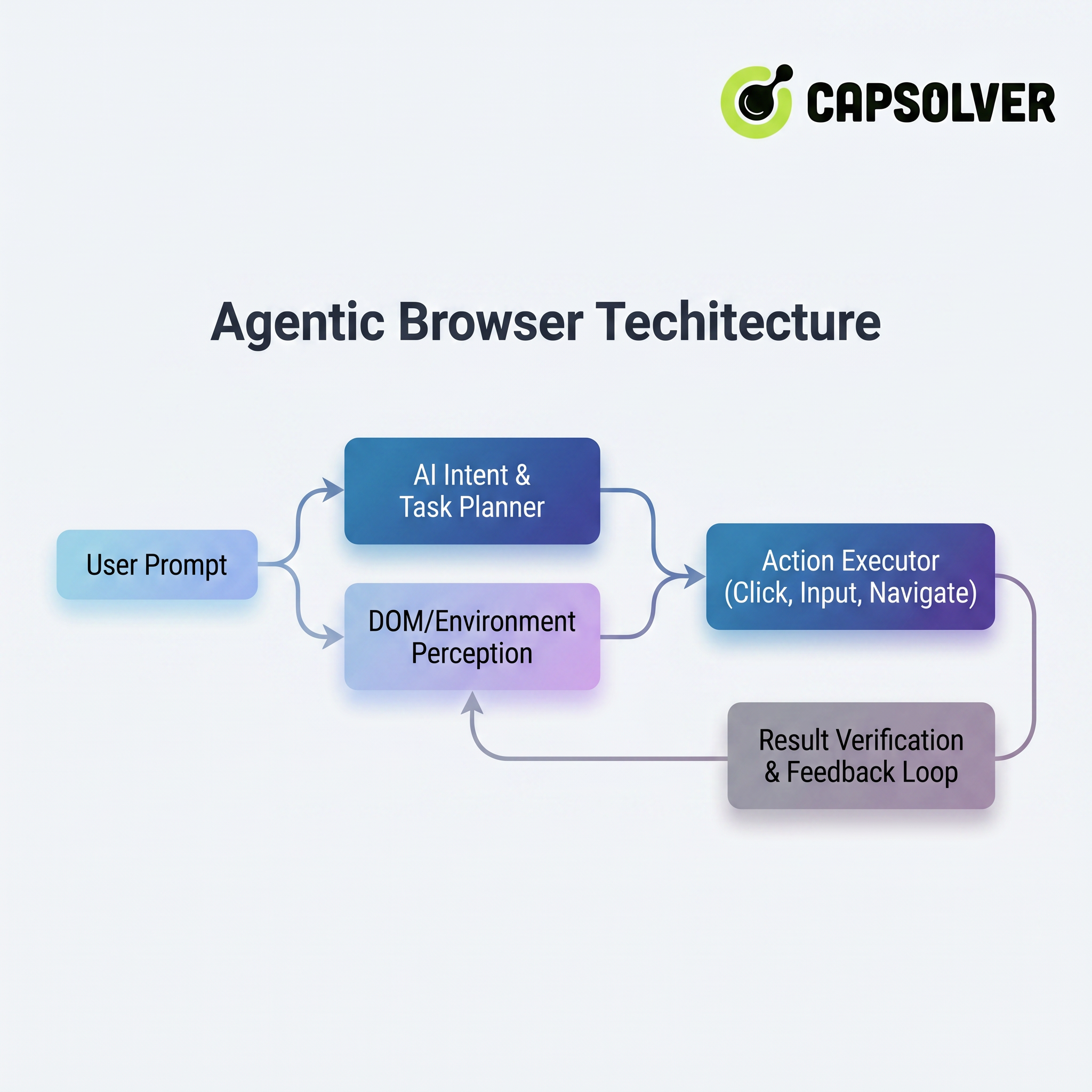
La arquitectura consta de cuatro capas clave de arriba a abajo (o por proceso):
- Planner de Intención y Tareas de IA: Descompone el lenguaje natural vago en secuencias de operaciones atómicas ejecutables y predice ramas de camino potenciales.
- Percepción del DOM/Entorno: "Lee" en tiempo real la estructura de la página web, combinada con reconocimiento multimodal visual para entender funciones de botones, semántica de formularios y cambios de estado de la página.
- Ejecutor de Acciones: Simula con precisión operaciones humanas (hacer clic, escribir, deslizar, cargar archivos, etc.) a través de protocolos de automatización de navegador y llama de forma segura a APIs externas.
- Verificación de Resultados y Bucle de Retroalimentación: Verifica automáticamente si el resultado de cada paso cumple con las expectativas. Si ocurre un error o cambio de página, ajusta dinámicamente la estrategia y vuelve a intentarlo, logrando "autocorrección".
Gracias a esta arquitectura, el Navegador Agente transforma la intención macro del usuario en operaciones micro del navegador, logrando realmente el concepto de "dices una palabra, él hace el trabajo".
1.3 De Pasivo a Proactivo: Un Cambio Fundamental en el Paradigma del Navegador
La aparición del Navegador Agente marca un salto fundamental en el paradigma de interacción humano-máquina. Este cambio no es solo sobre eficiencia; es una reconstrucción de la lógica de control e interacción.
En el modo tradicional, los humanos deben adaptarse a la lógica de la máquina: aprender jerarquías de menú tediosas, recordar atajos y manejar manualmente ventanas emergentes anómalas. En el modo Agente, la máquina comienza a adaptarse a la lógica humana: entender instrucciones coloquiales, anticipar la intención del usuario y coordinar proactivamente tareas entre aplicaciones.
Para contrastar intuitivamente estos dos modos, la figura siguiente muestra la diferencia esencial en los roles de interacción entre navegadores pasivos tradicionales y navegadores proactivos agentes:
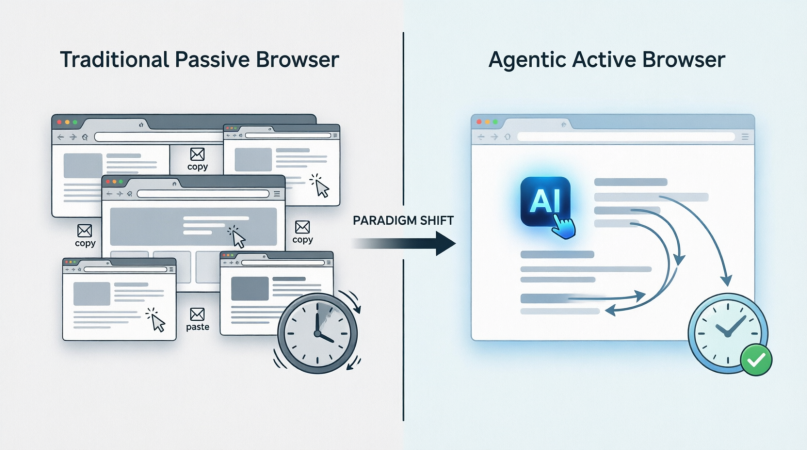
Este cambio de paradigma se refleja en tres dimensiones clave:
- De "Controlado por Instrucciones" a "Controlado por Objetivos": Los usuarios ya no se preocupan por "cómo" hacerlo (Cómo), sino que solo definen "qué" hacer (Qué). El navegador es responsable de descender objetivos de alto nivel a cadenas de operaciones de bajo nivel.
- De "Interfaz Estática" a "Colaboración Dinámica": Las páginas web ya no son diseños de interfaz fijos, sino "flujos de datos" que pueden ser analizados, reorganizados y operados por IA en tiempo real. Los navegadores agentes pueden atravesar sin problemas diferentes sitios y sistemas, rompiendo los silos de datos.
- De "Reversión Manual" a "Tolerancia Inteligente a Fallos": Frente a rediseños de páginas, retrasos en la carga o bloques de CAPTCHA, los scripts tradicionales se caen, mientras que los navegadores agentes poseen capacidades de razonamiento contextual, permitiéndoles "intentar otro camino" como un humano, reduciendo significativamente el costo de mantenimiento de procesos automatizados.
Para usuarios ordinarios, esto significa que el navegador se transformará de una "herramienta que consume tiempo" en un "lever que libera tiempo". Cuando el navegador comience a trabajar proactivamente para ti, el enfoque de la vida digital verdaderamente regresará a la creación, la toma de decisiones y el pensamiento en sí mismo.
Capítulo 2: ¿Cómo Funciona un Navegador Agente?
Tómate unos segundos para imaginar una escena: Le dices a un Navegador Agente: "Ayúdame a encontrar auriculares Sony WH-1000XM5 en el Sitio de Comercio Electrónico A, seleccionar negro, encontrar la tienda oficial con el precio más bajo, realizar un pedido con envío del día siguiente y elegir pago contra reembolso". Solo esta oración implica una serie compleja de eventos detrás de escena. El Navegador Agente necesita "entender" tus necesidades, descomponerlas en pasos ejecutables, "ver" el contenido en la página web, "actuar" sobre él y manejar situaciones inesperadas como cambios de página.
El siguiente diagrama resume todo el proceso:
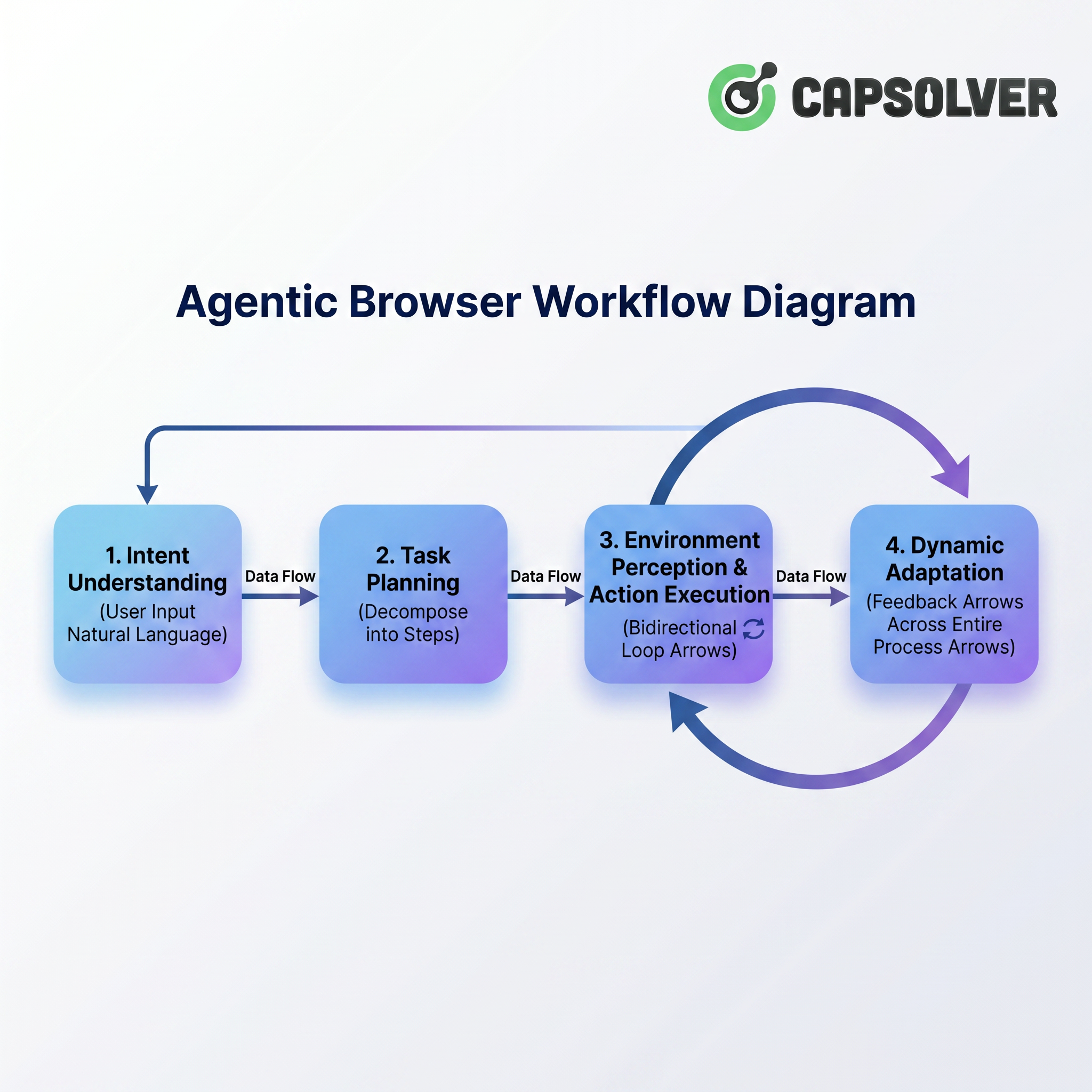
El proceso comienza con la instrucción en lenguaje natural del usuario, pasa por la comprensión de intención y planificación de tareas, y luego entra en la etapa central de "percepción del entorno y ejecución de acciones". Notablemente, hay un bucle bidireccional entre la percepción del entorno y la ejecución de acciones: el Navegador Agente observa el estado de la página mientras ejecuta operaciones y continúa percibiendo el siguiente cambio de página basado en los resultados de la ejecución. Al mismo tiempo, "adaptación dinámica" corre a lo largo de todo el proceso como una flecha de retroalimentación, asegurando flexibilidad al ajustar estrategias al enfrentar ventanas emergentes, CAPTCHAS o cambios en la estructura de la página. A continuación, profundizaremos en cada etapa para desglosar cómo el Navegador Agente "entiende, ve, actúa y se adapta".
2.1 Comprensión de la Intención: De Lenguaje Natural a Planificación de Tareas
Cuando una oración casual se le lanza al navegador, primero debe convertirla en una "lista de tareas" claramente estructurada. Esta es la etapa de comprensión de intención.
Si le dices a un navegador tradicional que "compre auriculares", probablemente solo pueda abrir un motor de búsqueda predeterminado y escribir exactamente esas palabras. Un Navegador Agente, sin embargo, utiliza Modelos de Lenguaje Grande (LLMs) para un análisis profundo. Su objetivo no es buscar, sino descomponer la tarea.
Usando el ejemplo anterior, la IA necesita identificar:
- Producto Objetivo: "Auriculares Sony WH-1000XM5"
- Restricciones: "Negro", "Precio más bajo", "Tienda oficial"
- Cadena de Acciones: Buscar producto → Filtrar por negro → Ordenar por precio → Localizar tienda oficial → Añadir al carrito → Rellenar dirección de envío → Seleccionar método de envío (envío del día siguiente) → Seleccionar método de pago (pago contra reembolso) → Confirmar pedido
- Dependencias Implícitas: El usuario debe estar conectado, el libro de direcciones debe tener una dirección válida, el método de pago debe permitir el pago contra reembolso, etc.
Este proceso de descomposición no es una aplicación simple de plantillas, sino que requiere razonamiento contextual. Por ejemplo, necesita determinar qué opción de logística corresponde a "envío del día siguiente" y confirmar si el producto lo admite. Finalmente, se genera un mapa de planificación de tareas. La figura siguiente muestra la estructura completa de esta tarea en forma de árbol de decisión:
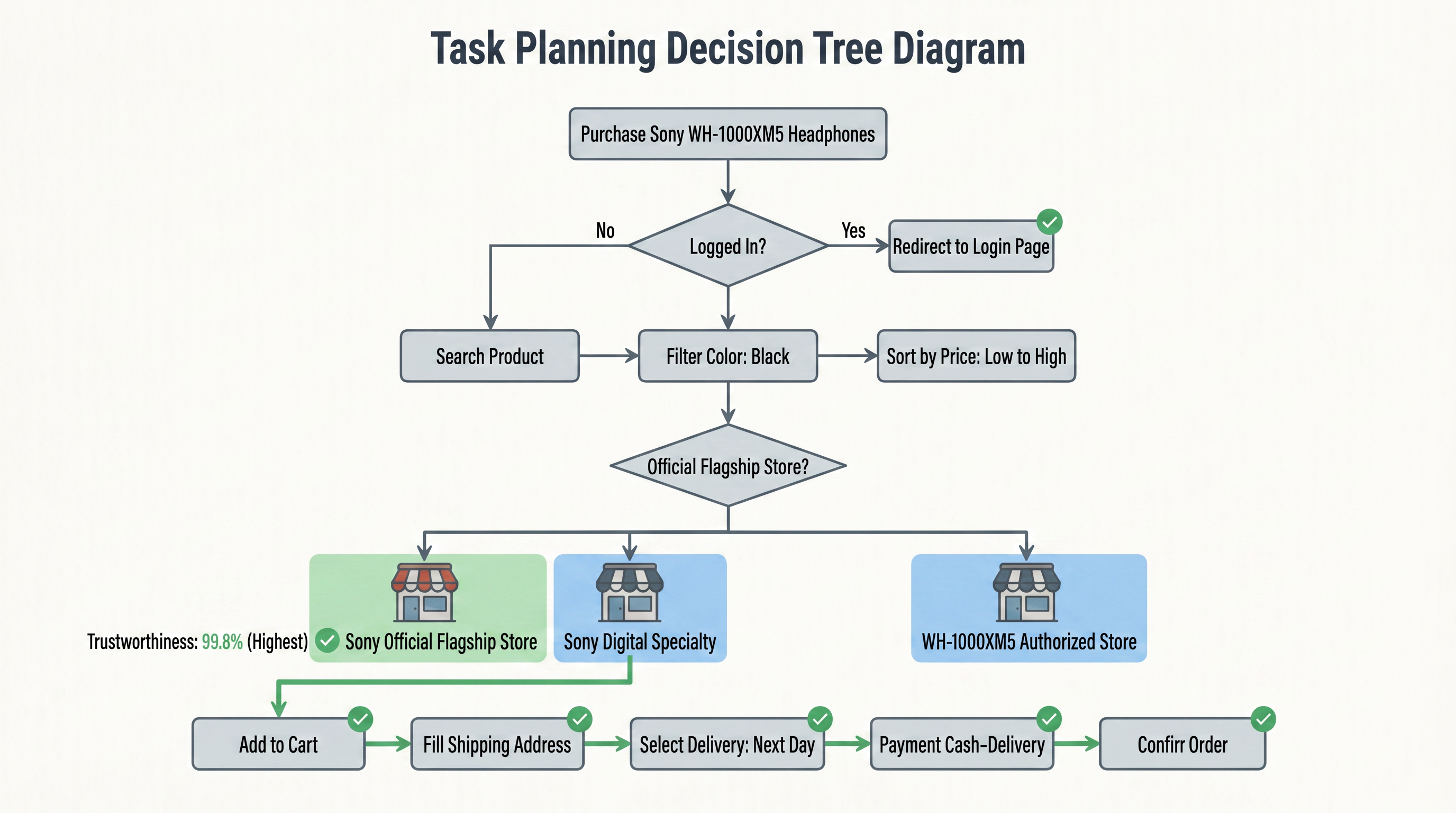
Este árbol de decisión transforma la instrucción en lenguaje natural del usuario en un árbol de operaciones ejecutables. Comenzando desde el nodo raíz "Comprar auriculares", se refina paso a paso a lo largo de las ramas "Sí", con cada paso conteniendo juicios de condiciones (por ejemplo, si es una tienda oficial, comparación de puntaje de crédito) y acciones atómicas (por ejemplo, buscar, filtrar, completar). Esta planificación de tareas estructurada permite al navegador saber claramente "qué hacer primero, qué hacer a continuación y cómo elegir cuando se encuentre con ramas". Desde este momento, el navegador ya no es solo una caja de búsqueda, sino un ejecutor que se dirige al mundo web con un objetivo claro.
2.2 Percepción del Entorno: Cómo la IA "Ve" la Web
Con un plan en lugar, el siguiente paso es permitir que la IA "vea" la página web colorida como un humano. Esto técnicamente se llama percepción del entorno. Los scripts de automatización tradicionales dependen de la ubicación de elementos (selectores CSS, XPath), lo cual es extremadamente frágil: un cambio en una clase de página hará que fallen. Los Navegadores Agentes utilizan un enfoque de fusión de múltiples percepciones, actuando como si tuvieran tanto ojos como sentido del tacto.
Los tres niveles de percepción se resumen en la tabla a continuación:
| Nivel | Descripción | Implementación Técnica | Ejemplo |
|---|---|---|---|
| Análisis de Estructura DOM y Semántica | Lee el Modelo de Objeto de Documento de la página, extrayendo etiquetas, roles y texto, combinado con etiquetas de accesibilidad ARIA para entender funciones de elementos. | Análisis de HTML, etiquetado semántico | Puede identificar "esto es un botón" y "eso es una caja de entrada", sabiendo qué div realmente lleva la acción "Añadir al carrito". |
| Comprensión de Captura de Pantalla Visual | Toma una captura de pantalla de la ventana actual y utiliza modelos multimodales para analizar píxeles, entendiendo el diseño y las relaciones visuales como un ojo humano. | Visión por computadora, segmentación de imágenes | Incluso si la etiqueta HTML de un botón no es estándar, siempre que parezca un botón (esquinas redondeadas, bloque de color, texto), puede localizarlo. |
| Razonamiento del Estado de Interacción | Determina el estado actual de componentes a través de estilos CSS, estados de enfoque, atributos deshabilitados, etc. | Análisis de estilo, detección de estado | Puede ver si un botón está gris y no se puede hacer clic o resaltado y se puede hacer clic; si un menú desplegable está colapsado o expandido. |
Tabla 2-1: Los Tres Niveles de Percepción del Entorno
Estos tres tipos de percepción no funcionan de forma aislada, sino que ocurren simultáneamente y se verifican mutuamente. La figura 2-3 muestra de forma intuitiva este proceso de fusión:

En cualquier momento dado, el Navegador Agente lee el árbol DOM (estructura), analiza el mapa de calor (visual) y marca cajas de interacción (interacción). Los tres se superponen para formar un "entendimiento integral" de la página web. Es esta diseño redundante de "confiar en la visión si el código no se entiende" lo que da a los Navegadores Agentes una robustez extrema. Cuando una página cambia "Comprar ahora" a "Atrápalo ahora", o hace que un botón sea un enlace de imagen elegante, aún puede localizar y ejecutar la operación con precisión.
2.3 Ejecución de Acciones: Completando Operaciones en un Navegador Real
Con el plan de tareas y la comprensión del entorno, es hora de actuar. La etapa de ejecución de acciones se encarga de transformar las "etapas" abstractas en operaciones atómicas en un navegador real: hacer clic, escribir, desplazarse, pasar el cursor, manejar ventanas emergentes, etc.
Los navegadores agentes suelen ejecutarse en una instancia de navegador real controlada (como Chromium con interfaz gráfica o sin ella), simulando operaciones humanas mediante protocolos de automatización de navegadores (como CDP). Sin embargo, son más inteligentes que la automatización tradicional gracias a la ejecución biomimética:
- Control de ritmo: Añadir retrasos aleatorios entre dos clics y simular la escritura carácter por carácter en lugar de pegar instantáneamente evita eficazmente que un sitio web bloquee la automatización.
- Simulación de trayectoria del mouse: En lugar de moverse en línea recta de forma inmediata, genera una trayectoria de curva de Bézier con ligeros temblores, como haría una mano humana real.
- Espera inteligente: En lugar de usar de forma cruda un
sleepfijo, escucha eventos como cambios en el DOM, finalización de solicitudes de red y visibilidad de elementos clave.
Para mostrar de manera más intuitiva la secuencia completa de una interacción típica, la figura 2-4 utiliza como ejemplo "Haz clic en 'Añadir al carrito'" para mostrar los pasos detallados de la ejecución de acciones:
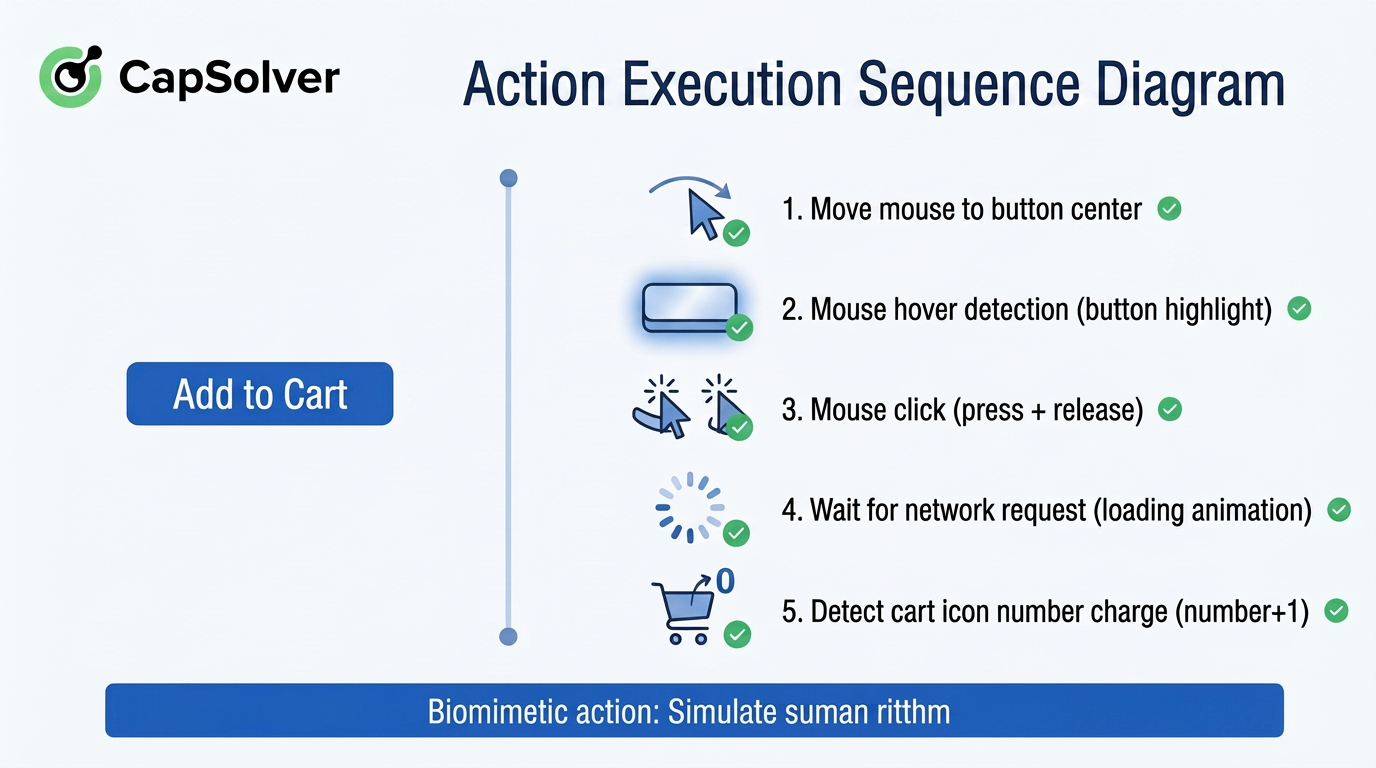
Como se muestra en la figura 2-4, cada paso corresponde a los hábitos de operación de un usuario real: desde pasar el cursor para activar retroalimentación visual, hasta esperar la respuesta del backend después de hacer clic, y finalmente verificar el cambio en el estado del frontend. Este diseño de secuencia detallada permite que el Navegador Agente no solo "realice la acción correcta", sino que también "actúe como un humano".
Además, el proceso completo genera un registro de acciones en tiempo real, permitiendo a los usuarios pausar, preguntar sobre el progreso o corregir errores en cualquier momento. El Navegador Agente no es una herramienta que se ejecuta una vez y termina, sino un modo de colaboración humano-máquina "semi-automático": puedes intervenir en puntos clave de decisión, como hacer que el navegador se detenga y espere tu confirmación antes del pago final. A continuación se encuentra "Ejecución biomimética: Simular el ritmo operativo real de un humano", que resume la filosofía detrás de esta serie de acciones: hacer que cada paso de la máquina lleve un toque humano.
2.4 Adaptación dinámica: Cuando la página web cambia
Las páginas web en el mundo real están vivas: las pruebas A/B podrían mostrarle un botón azul esta vez y un botón rojo la próxima; los diseños de las páginas cambian drásticamente durante temporadas de promoción; los modales "Claim Coupon" o desafíos CAPTCHA pueden aparecer repentinamente. Esta es la parte donde los navegadores agentes se diferencian de los tradicionales RPA – la capacidad de adaptación dinámica.
La adaptación dinámica incluye tres niveles de reacción:
- Detección de anomalías y recuperación: Cuando un elemento esperado no aparece (por ejemplo, el texto del botón cambia, el selector falla), el sistema pasa inmediatamente al modo de posicionamiento visual o amplía el rango de búsqueda para encontrar el objetivo más cercano semánticamente. Si falla repetidamente, genera un informe de error y pide al usuario.
- Manejo de ventanas emergentes e interrupciones: La IA identifica "si esta cosa inesperada debe cerrarse" como lo haría un humano. Para ventanas emergentes promocionales, normalmente hace clic en cerrar; para ventanas emergentes de expiración de inicio de sesión, activa una sub-tarea de reinicio de sesión.
- Respuesta a CAPTCHA (pre-integración): Una vez que se detecta un CAPTCHA (deslizador gráfico, reCAPTCHA, etc.) en la página, el Navegador Agente pausa la tarea actual y transfiere la situación CAPTCHA a un "motor invisible" especializado – este es el problema principal que el protagonista de nuestro tercer capítulo, CapSolver, busca resolver. Después de una solución exitosa, reanuda sin problemas el flujo de la tarea original.
Podemos ver todo el proceso de adaptación como un bucle de auto-corrección continuo:
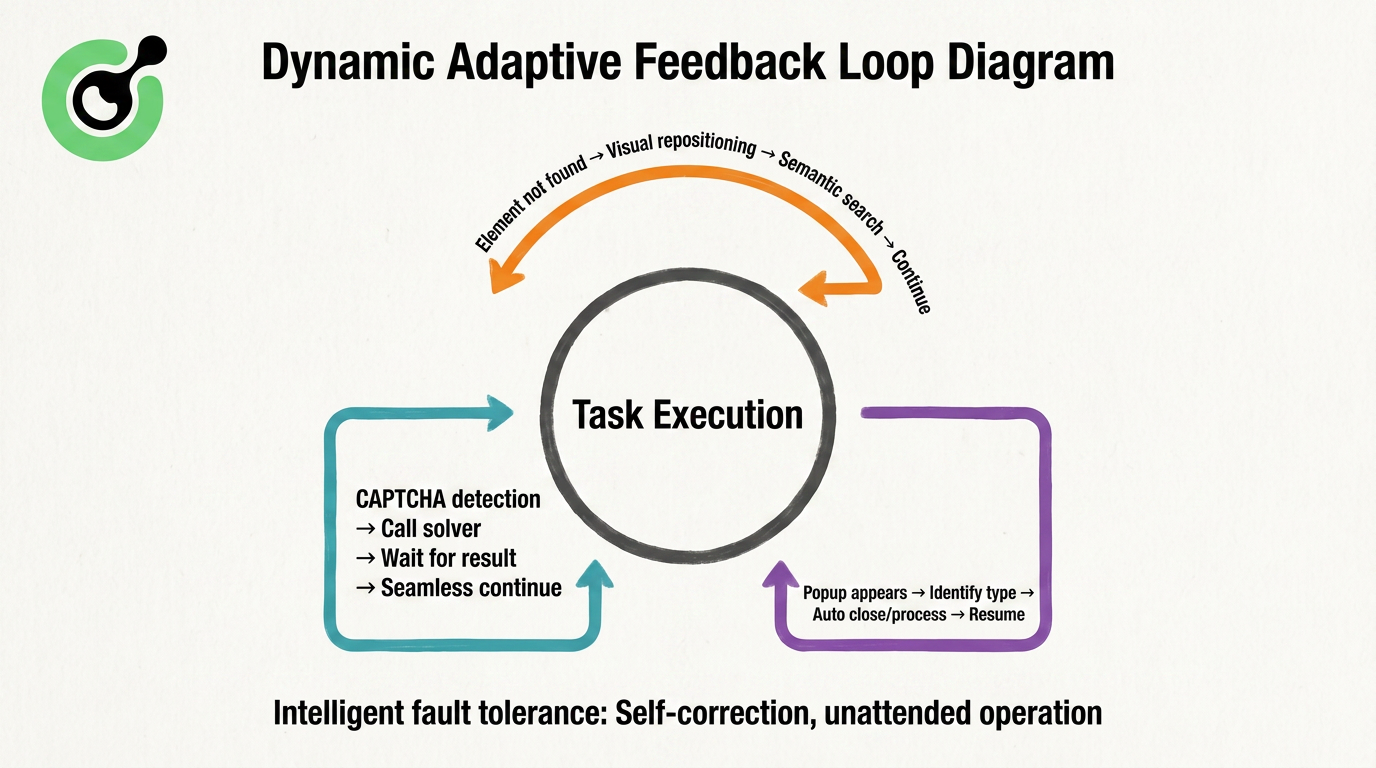
El bucle completo gira en torno a la "ejecución de tareas": al encontrarse con un CAPTCHA, el sistema llama automáticamente a recursos externos de resolución, espera el resultado y reanuda sin problemas; al encontrarse con una ventana emergente, la identifica y la maneja, luego regresa al flujo principal de la tarea. Este mecanismo complementa el "mecanismo de tolerancia inteligente a fallos" en la parte inferior, asegurando que el Navegador Agente pueda completar procesos complejos en páginas web que antes "seguramente fallarían" sin supervisión. Es este bucle el que hace que el Navegador Agente ya no tema los cambios, sino que aprenda a adaptarse como un humano.
Fuentes externas autorizadas
Para más información sobre el desarrollo y el panorama técnico de los navegadores agentes y la automatización web, por favor consulte las siguientes fuentes autorizadas:
- Anthropic: Presentando el uso de computadoras para Claude 3.5 Sonnet
- Opera: Conoce a Opera Neon, el primer navegador agente de inteligencia artificial
- Snowplow: ¿Qué es un navegador agente?
Conclusión
La evolución desde navegadores tradicionales hasta navegadores agentes representa un cambio monumental en la forma en que interactuamos con el mundo digital. Al integrar modelos de lenguaje de gran tamaño (LLMs), percepción multimodal y ejecución biomimética, los navegadores agentes ya no son solo ventanas pasivas, sino asistentes activos e inteligentes capaces de comprender intenciones complejas y navegar en entornos web dinámicos. Manejan las tareas tediosas y repetitivas, liberando a los usuarios humanos para que se enfoquen en toma de decisiones de nivel superior y creatividad. Sin embargo, a medida que estos agentes se vuelven más sofisticados, inevitablemente se enfrentan a los guardianes finales de la web: los CAPTCHA. Para liberar plenamente el potencial de los navegadores agentes, se requiere infraestructura robusta para superar estos obstáculos de forma fluida.
Recomendación: Para asegurar que su navegador agente o scripts de automatización funcionen sin problemas y no sean bloqueados por CAPTCHA complejos, le recomendamos altamente integrar CapSolver. CapSolver ofrece una infraestructura confiable y impulsada por inteligencia artificial para superar diversos desafíos CAPTCHA de forma fluida, actuando como el "motor invisible" perfecto para sus flujos de automatización.
Código promocional
Redime tu código promocional de CapSolver
Aumenta tu presupuesto de automatización instantáneamente.
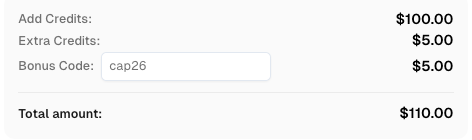
Usa el código promocional CAP26 al recargar tu cuenta de CapSolver para obtener un 5% adicional en cada recarga — sin límites.
Redimiéndolo ahora en tu Panel de CapSolver
Leer la segunda parte de esta serie: El motor invisible del navegador agente: Superar CAPTCHA con infraestructura especializada
Preguntas frecuentes
P1: ¿Cuál es la principal diferencia entre un navegador tradicional y un navegador agente?
R1: Un navegador tradicional es una herramienta pasiva que requiere entrada manual paso a paso (clics, escritura) para navegar y realizar tareas. Un navegador agente es un agente digital activo que entiende comandos en lenguaje natural, planifica tareas de forma autónoma y las ejecuta en su nombre.
P2: ¿Cómo entiende un navegador agente qué hacer en una página web?
R2: Utiliza una combinación de análisis de la estructura del DOM, comprensión de capturas de pantalla visuales (usando visión por computadora) y razonamiento del estado de interacción para "ver" y comprender la página web como lo haría un humano, lo que lo hace muy resistente a los cambios en la interfaz de usuario.
P3: ¿Puede un navegador agente manejar ventanas emergentes inesperadas o cambios en un sitio web?
R3: Sí, cuenta con capacidades de adaptación dinámica. Puede detectar anomalías, manejar ventanas emergentes inesperadas de forma inteligente y ajustar su estrategia de ejecución en tiempo real sin colapsar como lo harían los scripts de automatización tradicionales.
P4: ¿Qué ocurre cuando un navegador agente encuentra un CAPTCHA?
R4: Al detectar un CAPTCHA, el navegador agente pausa su tarea actual y delega el proceso de resolución a infraestructura especializada, como CapSolver. Una vez resuelto, reanuda sin problemas la tarea.
Ver más
Web ScrapingJul 22, 2026
Monitoreo de Regresión en SEO Técnico: Pipeline de Automatización
Construir un monitoreo de regresión de SEO técnico con líneas base versionadas, diferencias semánticas, alertas verificadas y un paso opcional de recuperación CAPTCHA autorizado.
CloudflareJul 22, 2026
Solucionador de CAPTCHA MCP: Guía de Integración de Cloudflare Turnstile
Construya un flujo de trabajo de MCP de Cloudflare Turnstile con CapSolver, reintentos limitados, registros con datos eliminados, verificaciones de sesión y validación de resultados.