Cómo los navegadores agentes resuelven CAPTCHA: Infraestructura de resolución de CAPTCHA con IA

Aloísio Vítor
Image Processing Expert
En nuestro artículo anterior, exploramos cómo el Navegador Agente se transforma de una "herramienta de visualización pasiva" en un "agente de acción activa". Examinamos su arquitectura central: comprensión de intención, percepción ambiental y ejecución de acciones. Sin embargo, a medida que estos agentes digitales navegan por la web del mundo real, enfrentan un portero formidable: el CAPTCHA. Este artículo se centra en el "motor invisible", la infraestructura de resolución de CAPTCHA, que garantiza que estos agentes puedan trabajar de manera proactiva para usted sin interrupciones. Analizaremos por qué los CAPTCHAs son el principal obstáculo para la IA y cómo servicios especializados como CapSolver proporcionan la infraestructura crítica necesaria para la próxima generación de automatización web.
Capítulo 1: El "motor invisible" — Infraestructura de resolución de CAPTCHA
Imagina esta situación: le pides a un Navegador Agente que te ayude a conseguir entradas para un concierto popular. Abre correctamente el sitio web, localiza el botón de compra y justo cuando está a punto de hacer clic en "Comprar ahora", aparece repentinamente un rompecabezas deslizante o nueve imágenes difusas de semáforos. Tu asistente digital queda inmediatamente bloqueado. El CAPTCHA, este "test de Turing" nacido en los primeros días de Internet, se ha convertido en el adversario más directo y problemático para los agentes de IA.
1.1 ¿Por qué el CAPTCHA es el principal obstáculo para los agentes de IA?
CAPTCHA significa "Test de Turing Automatizado Público para Distinguir Computadoras y Humanos". Su propósito original era simple: mantener a los bots fuera y dejar pasar a los humanos. Pero a medida que la IA ha evolucionado, los CAPTCHAs también han evolucionado continuamente — desde letras distorsionadas simples hasta complejos deslizadores, tareas de selección de imágenes y sistemas de análisis de comportamiento. Ya no son solo un problema de reconocimiento de caracteres.

Para los scripts de automatización tradicionales, los CAPTCHAs son casi una sentencia de muerte. Pero para los Navegadores Agentes, representan un desafío igualmente grave por tres razones principales:
-
Un aumento drástico en la dificultad de percepción: Incluso los modelos multimodales más avanzados tienen dificultades para reconocer con fiabilidad texto distorsionado, objetos de imagen borrosos o huecos de deslizador ocultos en fondos complejos. La IA puede simplemente "verlo mal", y un solo error puede romper todo el flujo de trabajo.
-
Mecanismos de incentivo antirrobóticos multicapa: Los CAPTCHAs modernos ya no son solo desafíos de primer plano. Los sitios web monitorean las trayectorias del ratón, los ritmos de escritura, el tiempo de permanencia en la página y hasta las huellas del navegador. Si el sistema determina que el operador no "se comporta como un humano", la dificultad del CAPTCHA puede aumentar instantáneamente — desde simplemente marcar una casilla hasta resolver diez tareas de reconocimiento de imágenes consecutivas.
-
Sensibilidad al tiempo y perturbaciones contextuales: Los CAPTCHAs suelen tener límites de caducidad. Cuando un Navegador Agente se atasca demasiado tiempo en un CAPTCHA durante una tarea de múltiples pasos, las sesiones de inicio de sesión pueden caducar, los productos pueden agotarse y toda la cadena de tareas puede colapsar. Es como un derrumbe repentino de un puente en una autopista, deteniendo todo el proceso de automatización.
En otras palabras, sin la capacidad de superar los CAPTCHAs, los Navegadores Agentes solo pueden viajar por las "carreteras secundarias sin vigilancia" de la web, en lugar de navegar realmente por el sistema completo de sitios web del mundo real. Es precisamente por eso que existen infraestructuras de resolución de CAPTCHA como CapSolver.
1.2 ¿Cómo CapSolver abre el camino para los agentes de IA?
CapSolver no es una herramienta orientada a usuarios ordinarios, sino más bien un "motor de CAPTCHA" oculto en los kits de herramientas de los desarrolladores. En su núcleo, es una plataforma de resolución inteligente de CAPTCHA que proporciona interfaces de API específicamente diseñadas para ayudar a programas de automatización y agentes de IA a manejar diversos tipos de CAPTCHA.
Podemos pensar en él como un equipo de resolución de CAPTCHA disponible las 24 horas del día, que nunca se cansa y opera a una velocidad extremadamente alta — excepto que sus "miembros del equipo" no solo consisten en modelos de IA sofisticados, sino también en algoritmos de estrategia altamente optimizados.
Para comprender mejor sus capacidades, la siguiente tabla compara las diferencias entre enfoques tradicionales y las capacidades de CapSolver al enfrentar los mismos desafíos de CAPTCHA:
| Dimensión de comparación | OCR local / Modelos simples | Plataformas de resolución de CAPTCHA por humanos | CapSolver |
|---|---|---|---|
| Tipos de CAPTCHA soportados | Solo CAPTCHA de texto simple; la selección de imágenes es en su mayoría ineficaz | Teóricamente soporta todos los tipos, pero es lento y costoso | Cubre los tipos de CAPTCHA principales |
| Velocidad de reconocimiento | Milisegundos, pero con tasas de éxito bajas | 5–15 segundos por intento | 1–3 segundos por intento |
| Tasa de éxito | Baja (peor en CAPTCHA complejos) | Relativamente alta, pero afectada por la fatiga de los trabajadores y la latencia de la red | Alta y estable |
| Estructura de costos | Costo único de desarrollo | Pago por tarea con altos costos laborales | Pago por tarea con precios bajos y costos marginales bajos |
| Capacidad de evasión de detección | Casi ninguna | No puede manejar sistemas de análisis de comportamiento | Puede integrarse con entornos de navegador y devolver tokens o instrucciones compatibles con el riesgo |
Tabla 1-1 Comparación entre métodos tradicionales de resolución de CAPTCHA y capacidades de CapSolver
El principio operativo central de CapSolver es esencialmente "IA contra IA, estrategia contra estrategia". Para diferentes tipos de CAPTCHA, incorpora pipelines de resolución especializados:
-
CAPTCHA de reconocimiento de imágenes y texto: Utilizando modelos de visión propietarios combinados con grandes conjuntos de datos de entrenamiento, CapSolver puede reconocer con precisión texto distorsionado, superpuesto o ruidoso.
-
CAPTCHA de deslizador y rompecabezas: En lugar de salir directamente con coordenadas de hueco, genera trayectorias de movimiento suaves basadas en el análisis ambiental mientras simula temblores sutiles, patrones de aceleración y desaceleración del tacto humano. Estos parámetros de comportamiento permiten que los programas de automatización arrastren deslizadores de forma natural a través de la verificación.
-
Sistemas de verificación basados en tokens (reCAPTCHA v2/v3, Cloudflare, etc.): Estos CAPTCHA no requieren entrada explícita del usuario. En su lugar, evalúan el comportamiento del navegador en segundo plano y devuelven un token único. CapSolver combina huellas del navegador, reputación de IP, trayectorias del ratón y otros datos contextuales para obtener tokens de verificación válidos a través de interfaces de resolución dedicadas. El Navegador Agente simplemente inserta el token en la página web para pasar la verificación.
Entonces, ¿cómo colaboran CapSolver y los Navegadores Agentes en la práctica? El siguiente diagrama ilustra el proceso completo:
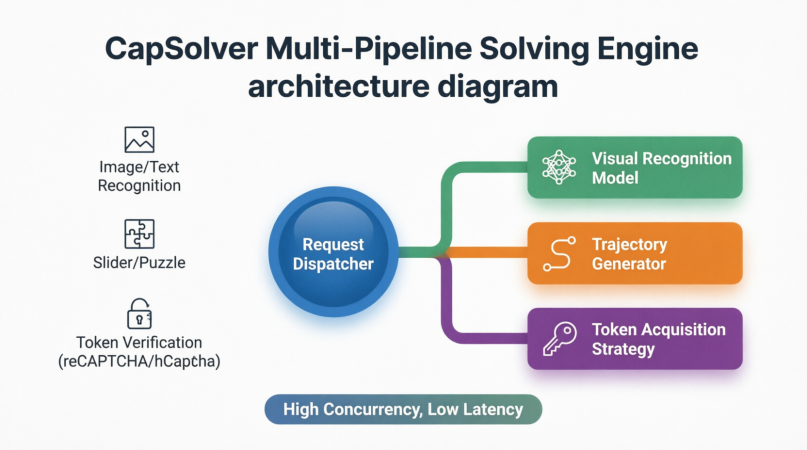
Desde el momento en que el navegador envía una solicitud a un sitio web, encuentra un CAPTCHA, captura pantallazos, llama a la API de CapSolver, recibe un token o una trayectoria de comportamiento, envía la verificación y reanuda la tarea original — todo el flujo de trabajo está estrechamente integrado y generalmente se completa en 1–2 segundos.
Esto significa que para los Navegadores Agentes, los CAPTCHA ya no son problemas que la IA debe "ver" y "adivinar" por sí misma. En cambio, se convierten en tareas estandarizadas que se externalizan a proveedores de infraestructura especializados. El navegador solo necesita capturar el desafío, empaquetar el contexto, enviarlo, esperar la "llave" y continuar su camino.
1.3 El flujo de trabajo colaborativo entre Navegadores Agentes y CapSolver
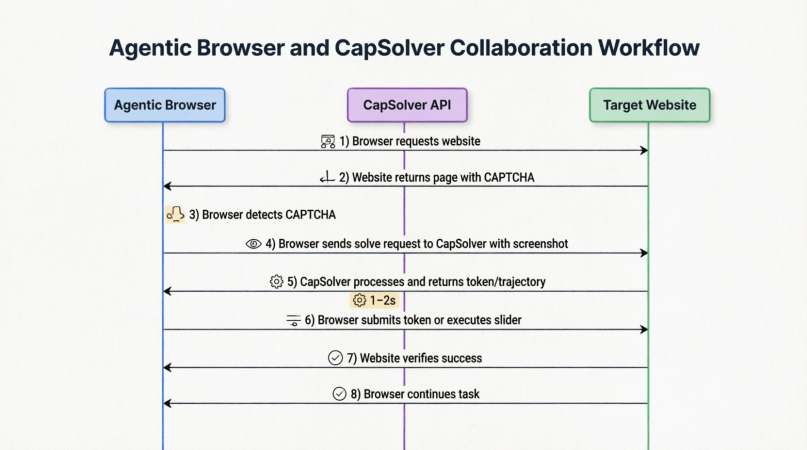
Ahora conectemos el módulo de adaptación dinámica de un Navegador Agente con CapSolver y examinemos cómo trabajan juntos en un "rendimiento de superación de obstáculos" fluido.
Mientras el Navegador Agente ejecuta tareas, su capa de percepción ambiental monitorea continuamente la página web. Una vez que detecta un elemento de CAPTCHA (por ejemplo, un popup que contiene un iframe de reCAPTCHA), la ejecución de acciones se pausa inmediatamente y se activa un subproceso dedicado a la resolución de CAPTCHA.
Este proceso es altamente sofisticado y generalmente incluye los siguientes pasos:
-
Recolección de contexto: El Navegador Agente captura pantallazos de la región del CAPTCHA y recopila información contextual como la URL actual, el sitekey, las dimensiones de la ventana del navegador y el User-Agent.
-
Presentación de la tarea: Los pantallazos y los parámetros se empaquetan juntos y se envían a CapSolver mediante API, especificando el tipo de CAPTCHA.
-
Resolución en segundo plano: Una vez que CapSolver recibe la tarea, la redirige al pipeline de resolución correspondiente. Por ejemplo, cuando se encuentra con reCAPTCHA v2, invoca a un solucionador dedicado para devolver un token
g-recaptcha-responseválido. El proceso de resolución se completa generalmente en 1–2 segundos. -
Devolver instrucciones: El Navegador Agente recibe el resultado devuelto — que puede ser una cadena de token o un conjunto de coordenadas de trayectoria del ratón.
-
Ejecución en el sitio: El Navegador Agente inserta el token en campos ocultos del formulario y envía el formulario, o simula un movimiento del deslizador similar al humano según los datos de trayectoria devueltos. La capa de CAPTCHA desaparece y el flujo de tareas original se reanuda sin interrupciones.
-
Verificación del estado: El navegador verifica si la página ha superado correctamente la validación y si los elementos objetivo han reaparecido antes de continuar con el flujo de trabajo interrumpido.
Es importante destacar que los CAPTCHA modernos tienen muchas formas y niveles de complejidad variables. El siguiente diagrama categoriza los tipos principales de CAPTCHA y marca sus niveles de complejidad correspondientes:
Para los usuarios finales, todo el proceso permanece completamente transparente. En el registro de tareas del Navegador Agente, los usuarios podrían ver solo un mensaje simple como:
"reCAPTCHA v2 detectado. Resuelto automáticamente en 1,2 segundos."
Un obstáculo que antes habría detenido todo el flujo de automatización se resuelve silenciosamente en segundo plano.
Esto también representa un salto crítico en las capacidades de los agentes de IA: el agente ya no se siente intimidado por sistemas defensivos diseñados específicamente para bloquear la automatización. Con la infraestructura de resolución de CAPTCHA funcionando como un "motor invisible", los Navegadores Agente finalmente obtienen la libertad operativa necesaria para ejecutar tareas de forma autónoma a través de Internet abierto.
Sin este motor, todas las promesas alrededor de los agentes inteligentes podrían colapsar fácilmente al primer popup de CAPTCHA.
Capítulo 2: ¿Dónde se están aplicando los Navegadores Agentes hoy en día?
Si los capítulos anteriores hicieron que esta tecnología se sintiera distante, los siguientes ejemplos pueden cambiar completamente su perspectiva. Los Navegadores Agentes no son conceptos abstractos flotando en el futuro — están entrando rápidamente en tres dominios principales: productividad personal, automatización empresarial y recolección de datos. En cada uno, resuelven problemas prácticos a diferentes niveles.
El siguiente diagrama resume los escenarios principales de aplicación de los Navegadores Agentes:
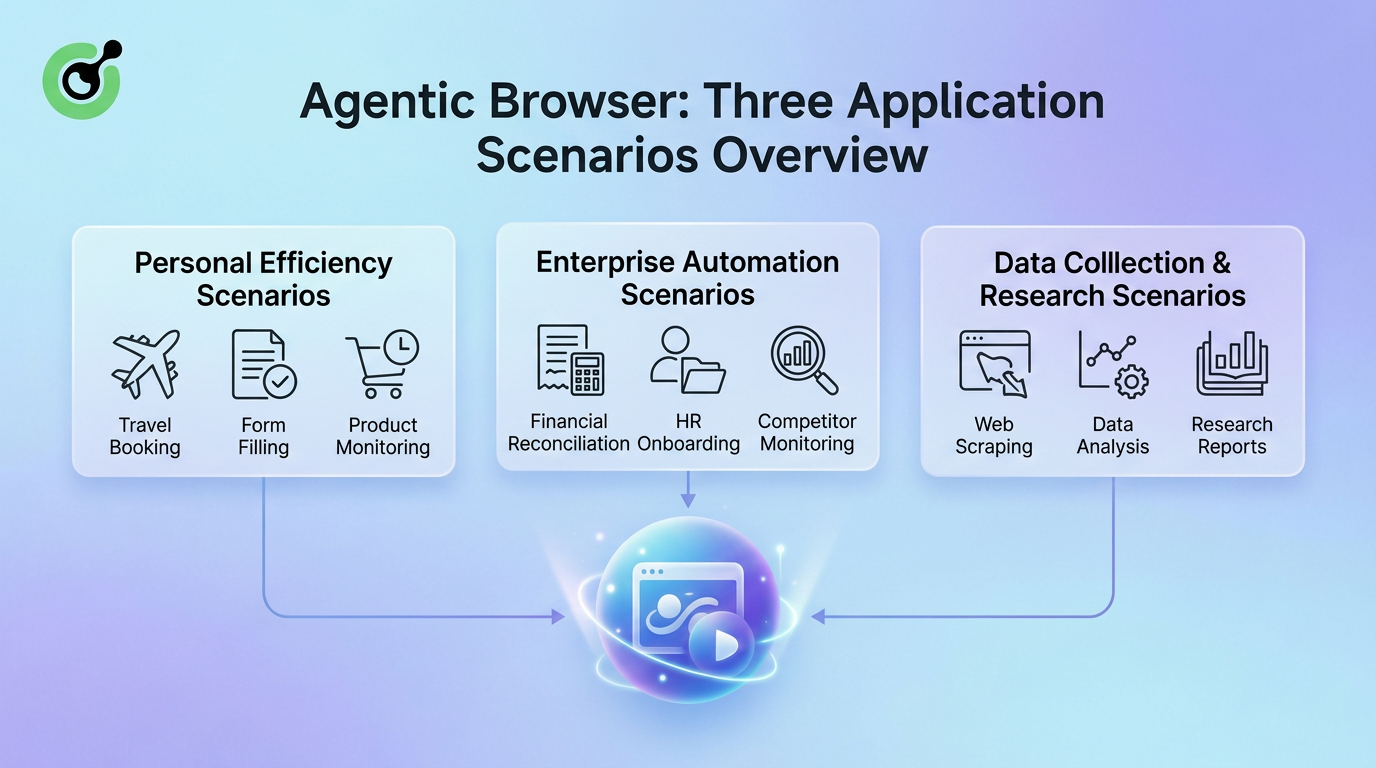
Las aplicaciones de los Navegadores Agentes abarcan desde usuarios individuales hasta grandes empresas, desde tareas diarias hasta flujos de trabajo de investigación profesional. En la productividad personal, ayudan a los usuarios a reservar viajes, completar formularios repetitivos y monitorear fluctuaciones de precios de productos. En la automatización empresarial, manejan conciliaciones financieras, incorporación de empleados y seguimiento de competidores. En la recolección de datos y la investigación, sirven como rastreadores incansables y asistentes de análisis inteligentes.
A continuación, examinaremos estos tres escenarios en detalle para comprender cómo los Navegadores Agentes "realmente realizan el trabajo".
| Organización de datos multiplataforma | 1–2 horas (copiar y pegar y formato) | 5 minutos (extracción y formato automáticos) | De operador a analista |
Tabla 2-1 Comparación entre tareas personales tradicionales y eficiencia del Navegador Agente
Como se muestra arriba, el Navegador Agente actúa efectivamente como un asistente personal. Libera a los usuarios de ser "operadores de flujos de trabajo" y los transforma en "establecedores de objetivos" y "revisores de resultados".
2.2 Automatización empresarial: Coordinación inteligente entre sistemas
Si las mejoras en la productividad personal se tratan de "reducir el esfuerzo", el valor de los Navegadores Agentes en entornos empresariales se trata de conexión.
Las grandes organizaciones suelen depender de numerosos sistemas heredados desconectados, plataformas SaaS y portales de proveedores que no se integran fácilmente a través de APIs. Los empleados se ven obligados a convertirse en "pegamento humano", transfiriendo manualmente información entre sistemas repetidamente.
Este es precisamente el punto donde los Navegadores Agentes demuestran sus mayores ventajas.
Casos de uso empresarial típicos
- Reconciliación financiera y de cadena de suministro
Un Navegador Agente puede iniciar sesión automáticamente en portales bancarios, descargar estados, compararlos contra sistemas ERP, generar informes de discrepancias y hasta redactar correos electrónicos de notificación.
- Flujos completos de incorporación de empleados
Las organizaciones pueden definir paquetes predefinidos de tareas de incorporación. El Navegador Agente crea automáticamente cuentas en sistemas de RR.HH., sistemas de TI, listas de correo y sistemas de control de acceso, garantizando omisiones cero y retrasos cero.
- Monitoreo de competidores y inteligencia de mercado
Los Navegadores Agentes pueden funcionar como sistemas de "radar de mercado" al visitar automáticamente sitios web de competidores, tiendas en línea y páginas de redes sociales, identificar cambios en la información crítica y almacenarlos en bases de datos estructuradas.
Para ilustrar mejor la posición única de los Navegadores Agentes en la automatización empresarial, la siguiente tabla compara sus soluciones con operaciones manuales y integraciones tradicionales por API:
| Dimensión | Operaciones manuales | Desarrollo de integración por API | Navegador Agente |
|---|---|---|---|
| Sistemas aplicables | Cualquier sistema | Solo sistemas con APIs abiertas | Cualquier sistema basado en web, incluidos sistemas internos heredados |
| Ciclo de implementación | No se requiere desarrollo, pero es laborioso | Semanas a meses (depende de los recursos de desarrollo) | Horas a días (configuración y prueba de tareas) |
| Flexibilidad | Alta (los humanos se adaptan dinámicamente) | Baja (se requieren reescrituras de interfaces tras cambios) | Alta (la IA se adapta dinámicamente a los cambios en las páginas) |
| Manejo de CAPTCHA/Inicio de sesión | Requiere manejo manual | Generalmente difícil de manejar directamente | Invoca automáticamente motores de resolución de forma fluida |
| Escalabilidad | Mala | Muy fuerte | Fuerte (ejecución de tareas paralelas posible) |
| Escenarios típicos de fallo | Fatiga humana y omisiones | Límites de tasas de API o incompatibilidades de versión | Puede requerir confirmación humana en condiciones de página extremadamente caóticas |
Tabla 2-2 Comparación de soluciones de automatización transsistema empresarial
Como se muestra arriba, los Navegadores Agentes no están diseñados para reemplazar APIs. En su lugar, proporcionan una capa de integración ligera en situaciones donde las APIs no están disponibles o son demasiado costosas de implementar.
Al aprovechar la flexibilidad y adaptabilidad de la IA, los Navegadores Agentes cubren las brechas dejadas por enfoques de automatización tradicionales, permitiendo a las empresas lograr una coordinación inteligente transsistema sin reconstruir infraestructura heredada.
2.3 Recopilación de datos y investigación: De la recolección manual a la extracción inteligente
Los datos suelen describirse como el petróleo de la era digital, pero recolectar datos web públicos limpios de manera eficiente siempre ha sido difícil.
Los rastreadores web tradicionales dependen de reglas de análisis fijas. Una vez que los sitios web objetivo rediseñan sus diseños o introducen medidas anti-scraping, los rastreadores suelen fallar por completo. Investigadores académicos, empresas de investigación de mercado y equipos de periodismo investigativo frecuentemente necesitan extraer información específica de grandes números de páginas web heterogéneas, lo que hace que los enfoques tradicionales sean costosos y tardados.
Los Navegadores Agentes introducen un nuevo paradigma para la recopilación de datos:
Un cambio de extracción basada en "reglas de código" a extracción basada en "objetivos semánticos".
Su flujo de trabajo generalmente opera de la siguiente manera:
Los investigadores describen las dimensiones de datos requeridas y los rangos de muestra usando lenguaje natural. Por ejemplo:
"Extraer títulos de productos, precios, calificaciones y conteos de reseñas de las 100 primeras páginas de productos de comercio electrónico, excluyendo productos patrocinados."
El Navegador Agente navega de forma autónoma por las páginas web, identifica bloques de información relevantes a través de la percepción ambiental, extrae y estructura inteligentemente los datos, y maneja interacciones complejas como paginación, desplazamiento infinito y ventanas emergentes.
Cuando los sitios web objetivo rediseñan sus diseños, los rastreadores tradicionales suelen colapsar inmediatamente. En contraste, los Navegadores Agentes intentan localizar la información visualmente y continuar la ejecución.
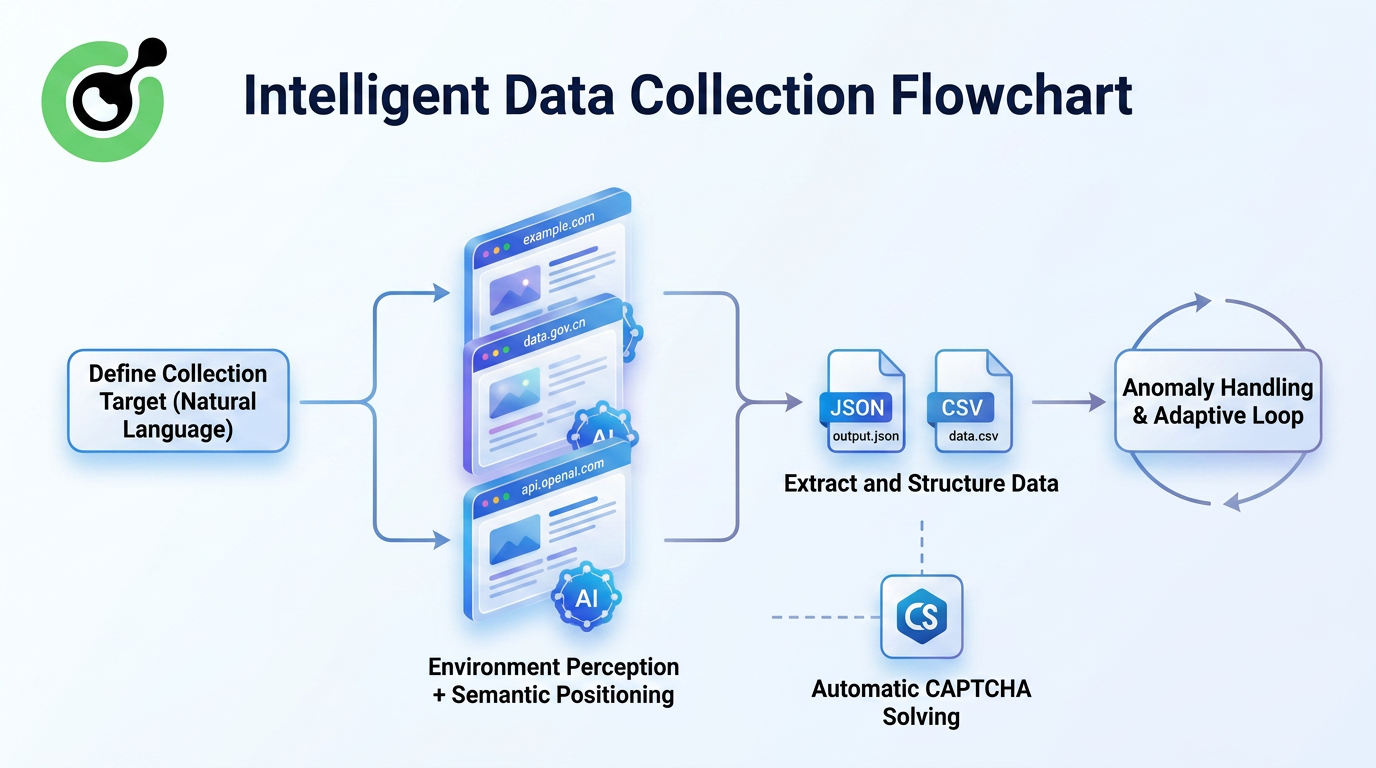
Este enfoque introduce varias mejoras fundamentales:
- No es necesario mantener reglas de análisis
La IA entiende qué se ve un "precio" semánticamente, en lugar de depender de nombres de clases HTML fijos.
- Mayor robustez frente a rediseños de sitios web
Cambios menores en el diseño ya no rompen inmediatamente los canales de extracción.
- Capacidad para manejar interacciones complejas
Para sitios web que requieren inicio de sesión, desplazamiento infinito o cambio de pestañas, los Navegadores Agentes pueden interactuar con la interfaz como usuarios reales antes de extraer información.
- Flujos de trabajo de investigación reproducibles
Las configuraciones de tareas se pueden guardar y compartir, estandarizando y haciendo reproducible la recopilación de datos.
Para demostrar mejor las ventajas de resiliencia de los Navegadores Agentes en tareas de recopilación de datos, la siguiente figura compara rastreadores tradicionales y Navegadores Agentes tras múltiples rediseños de sitios web:
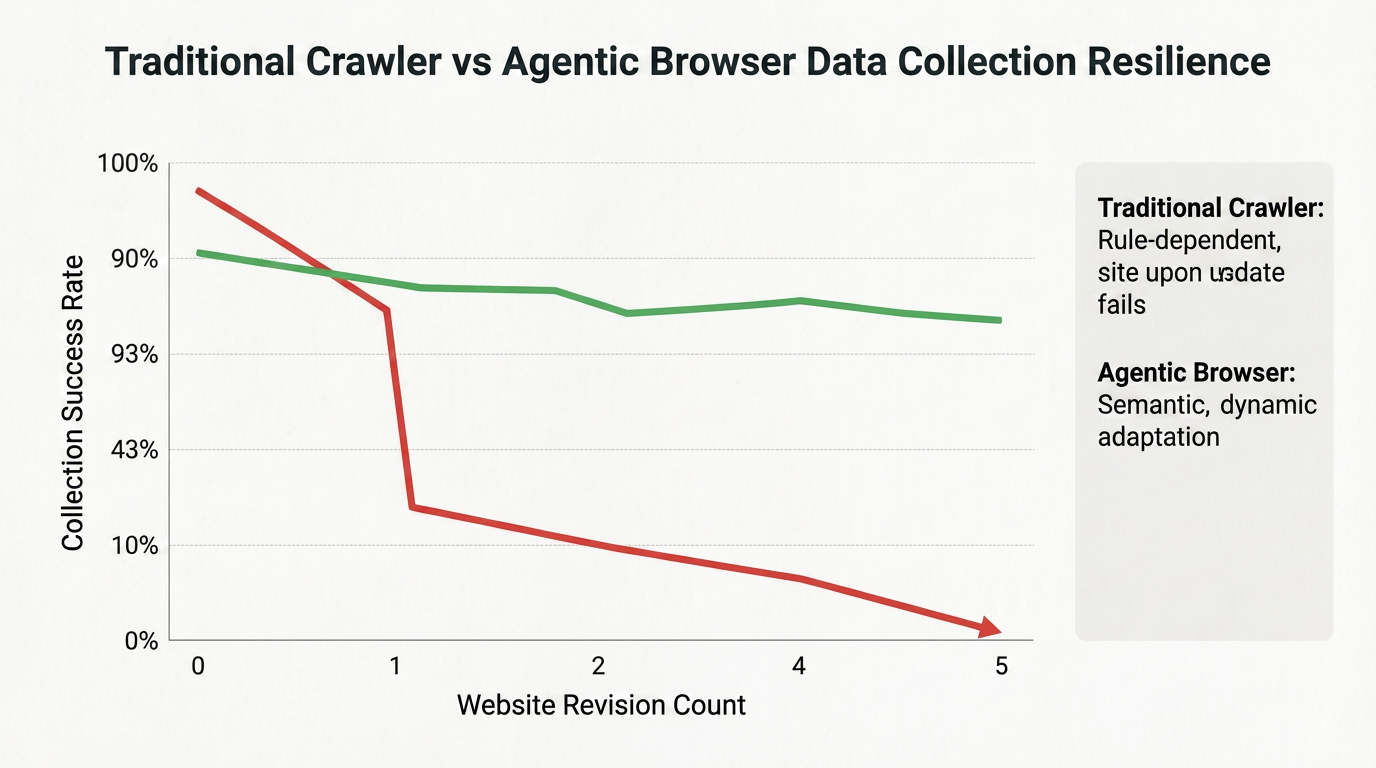
Los rastreadores tradicionales experimentan una drástica caída en la tasa de éxito tras el primer rediseño del sitio web, mientras que los Navegadores Agentes mantienen tasas de éxito de extracción relativamente altas incluso tras múltiples rediseños gracias a sus capacidades de localización visual y comprensión semántica.
Esta resiliencia los hace ideales para proyectos de recopilación de datos a largo plazo y a gran escala.
Por ejemplo, imagina un equipo de investigación en ciencias sociales que necesita comparar cláusulas específicas de políticas en 200 sitios web de políticas en 30 países. Tradicionalmente, esto requeriría a asistentes de investigación pasar meses copiando y organizando información manualmente.
Ahora, los investigadores pueden configurar una tarea del Navegador Agente que recorra automáticamente estos sitios web, localice páginas de políticas que contengan palabras clave objetivo, extraiga las cláusulas relevantes y las clasifique automáticamente.
Los investigadores solo necesitan revisar y analizar los resultados recopilados posteriormente, permitiendo que el valioso esfuerzo humano se enfoque en la "investigación" real en lugar de trabajo repetitivo de "transporte manual".
Conclusión
El Navegador Agente representa no solo un nuevo producto, sino también una nueva filosofía de estar en línea. Su lógica central es: el navegador no debe ser solo una interfaz esperando que lo haga clic, sino un agente inteligente que entienda su intención y lo ayude a completar tareas. Desde una perspectiva de implementación técnica, se basa en la capacidad de razonamiento de modelos de lenguaje grandes para planificar tareas, percepción multimodal para entender páginas web, un entorno de navegador real para ejecutar operaciones y infraestructura como CapSolver para eliminar obstáculos en el camino de la automatización. La fusión de estas tecnologías está actualizando la "ventana de información" que hemos utilizado durante treinta años en una verdadera "plataforma de acción".
Preguntas frecuentes
P1: ¿Por qué los modelos de IA generales no pueden resolver CAPTCHAs por sí mismos?
R1: Aunque los modelos de IA generales son poderosos, los CAPTCHAs están diseñados específicamente para ser adversariales y cambian constantemente. Resolverlos de manera confiable y rápida requiere infraestructura especializada como CapSolver, dedicada a esta única tarea.
P2: ¿Cómo ayuda CapSolver a los Navegadores Agentes?
R2: CapSolver actúa como un "motor invisible" que maneja desafíos de CAPTCHA a través de una API simple. Esto permite al Navegador Agente evitar obstáculos de seguridad de forma fluida y continuar con su tarea sin intervención humana.
P3: ¿Reemplazarán los Navegadores Agentes empleos humanos?
R3: Están diseñados para reemplazar "tareas", no "empleos". Al manejar trabajo digital repetitivo, liberan a los humanos para que se enfoquen en creatividad y toma de decisiones estratégicas de nivel superior.
P4: ¿Cómo puedo empezar a usar un Navegador Agente hoy mismo?
R4: Muchos navegadores y extensiones experimentales ya están disponibles. Sin embargo, para la mejor experiencia, asegúrese de tener un servicio confiable de resolución de CAPTCHA como CapSolver integrado para manejar los obstáculos de seguridad de la web.
Ver más
Web ScrapingJul 22, 2026
Monitoreo de Regresión en SEO Técnico: Pipeline de Automatización
Construir un monitoreo de regresión de SEO técnico con líneas base versionadas, diferencias semánticas, alertas verificadas y un paso opcional de recuperación CAPTCHA autorizado.
CloudflareJul 22, 2026
Solucionador de CAPTCHA MCP: Guía de Integración de Cloudflare Turnstile
Construya un flujo de trabajo de MCP de Cloudflare Turnstile con CapSolver, reintentos limitados, registros con datos eliminados, verificaciones de sesión y validación de resultados.