Melhor Escolha de Web Scraping vs API para Equipes de Automação

Adélia Cruz
Neural Network Developer
TL;DR
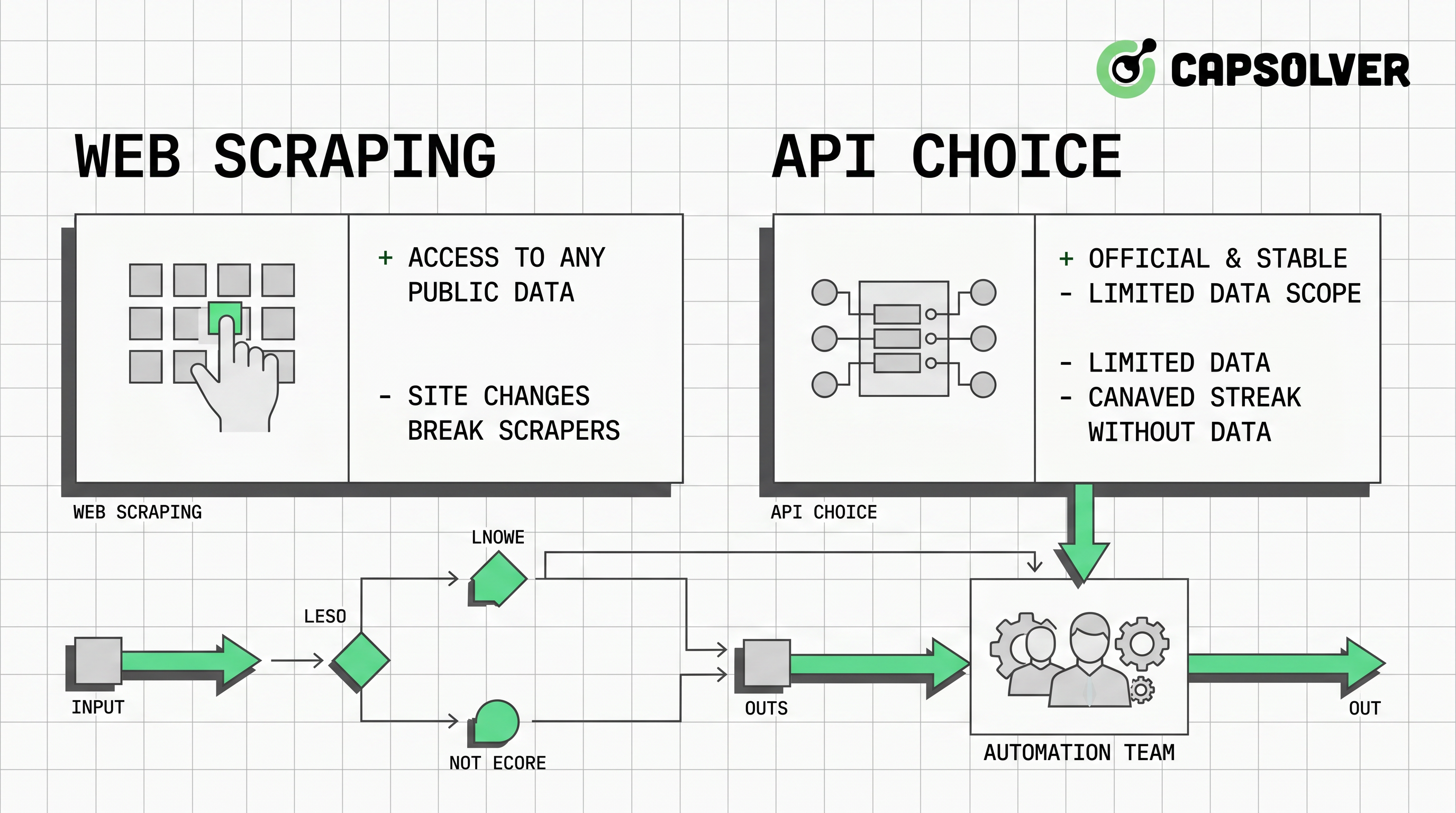
- As melhores decisões de raspagem de web vs API devem começar com direitos de dados, disponibilidade da fonte, requisitos de confiabilidade e custo de manutenção.
- APIs são geralmente melhores para sistemas de produção regulados, pois esquemas, limites de taxa, autenticação e versionamento são mais fáceis de documentar.
- A raspagem de web é útil quando dados públicos permitidos não têm uma API adequada, mas requer revisão do robots.txt, controle de taxa, monitoramento de mudanças nas páginas e verificações de conformidade.
- A automação de navegadores adiciona valor para páginas dinâmicas, e o CapSolver pode ajudar fluxos aprovados a lidar com desafios de CAPTCHA ou validação de tráfego quando eles aparecem.
- A arquitetura mais resiliente usa APIs primeiro, raspagem em segundo lugar, automação de navegadores apenas quando necessário e resolução de CAPTCHA como um caminho excepcional controlado.
Introdução
As melhores escolhas entre raspagem de web e APIs raramente se tratam de qual método é mais poderoso. Tratam-se de qual método é mais confiável, permitido, mantido e auditável para os dados que sua equipe precisa. APIs devem geralmente vir em primeiro lugar quando fornecem os campos necessários, frescor e termos adequados. A raspagem de web se torna útil quando páginas públicas permitidas são a única fonte prática ou quando as equipes precisam monitorar mudanças na camada de apresentação. Se um fluxo aprovado de raspagem ou automação de navegador encontrar um desafio de CAPTCHA, o guia de resolução de CAPTCHA enquanto raspagem do CapSolver pode fornecer um caminho de resolução documentado que se encaixa em um processo de automação mais amplo.
A abordagem de API-first deve ser a decisão padrão
APIs geralmente são a escolha padrão porque expressam um contrato suportado pelo provedor. Uma API bem projetada fornece campos previsíveis, autenticação, limites de taxa, códigos de erro e versionamento. Essas propriedades tornam as revisões de engenharia mais fáceis e reduzem a necessidade de análise frágil. APIs também simplificam a linha de dados, pois cada registro pode ser associado a um ponto de extremidade, horário, ID de solicitação ou esquema documentado.
O tutorial e referência de API REST explica ideias comuns de design de API, como recursos, métodos e representações. O documento de limite de taxa da API REST do GitHub mostra por que os limites de taxa não são um obstáculo, mas um contrato de operação. Em muitos programas de automação, uma API oficial mais lenta é melhor do que um raspador mais rápido, pois a API é mais fácil de defender em auditorias e mais fácil de manter quando os consumidores de dados crescem.
| Fator de decisão | Vantagem da API | Vantagem da raspagem de web |
|---|---|---|
| Contrato de dados | Esquemas estáveis e erros documentados | Pode coletar campos visíveis não expostos por um ponto de extremidade |
| Manutenção | Versionamento e canais de suporte | Funciona quando nenhuma API adequada existe |
| Frescor | Poling previsível e limites de taxa | Pode refletir atualizações de página rapidamente |
| Páginas dinâmicas | Menos sobrecarga de navegador | Automação de navegador pode inspecionar estados renderizados |
| Eventos de desafio | Geralmente evitados | Pode exigir fluxos de resolução de CAPTCHA controlados |
A chave não é rejeitar a raspagem. A chave é provar que a raspagem é necessária antes de adicionar complexidade operacional.
Quando a raspagem de web é a melhor opção
A raspagem de web é a melhor opção quando os dados são públicos, permitidos, não disponíveis por meio de uma API adequada e valiosos o suficiente para justificar o monitoramento. Exemplos comuns incluem páginas de preços públicas, páginas de disponibilidade de produtos, listagens de empregos públicas, diretórios públicos e monitoramento de mudanças em sites. Mesmo assim, a equipe deve documentar os campos de dados, páginas fonte, frequência de varredura, regras de exclusão e o proprietário do negócio responsável pelo fluxo.
O Protocolo de Exclusão de Robôs RFC 9309 define como os sites podem comunicar regras de varredura a clientes automatizados. O referência de URL da MDN é útil para normalização de URLs, que é um requisito básico para deduplicação e limites de varredura. Essas referências apoiam uma regra prática: a raspagem de web deve ser tratada como um sistema de engenharia com permissões e limites, não como um script informal.
A raspagem de web também se beneficia de um design em camadas. Páginas estáticas podem ser geralmente tratadas com solicitações HTTP e analisadores. Páginas com alto uso de JavaScript podem exigir automação de navegador. Páginas com validação de tráfego podem precisar de uma política documentada para lidar com desafios. O guia de integração do Playwright do CapSolver é útil quando a camada de automação precisa de extração e tratamento controlado de desafios.
Onde a resolução de CAPTCHA pertence na decisão
A resolução de CAPTCHA pertence no final da árvore de decisões de melhor raspagem de web vs API. Se uma API existir e atender às necessidades, use-a. Se a página pública puder ser coletada por meio de extração estática permitida, use-a. Se a automação de navegador for necessária, adicione controles de renderização e interação. Apenas após essas escolhas, a equipe deve decidir como lidar com um desafio de CAPTCHA ou validação de tráfego aprovado.
O glossário de reCAPTCHA do CapSolver e a orientação sobre terminologia de CAPTCHA ajudam as equipes a identificar famílias comuns de desafios antes de escolher um caminho de resolução. A decisão deve incluir escopo de aprovação, domínios aprovados, limites de tentativas, logs, política de proxy e verificação de sucesso em nível de página. Uma solução de desafio não é suficiente; o fluxo deve confirmar que a tarefa aprovada foi concluída corretamente.
Código bônus para pilotos de automação aprovados
Resgate seu código bônus do CapSolver
Aumente seu orçamento de automação instantaneamente!
Use o código bônus CAP26 ao recarregar sua conta no CapSolver para obter um bônus extra de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel do CapSolver
Padrões de arquitetura para equipes de automação
Uma arquitetura sólida separa método de acesso, execução, validação e governança. O método de acesso pode ser uma API, raspagem estática, script de automação de navegador ou fluxo híbrido. A execução deve aplicar limites de taxa, tentativas e condições de parada seguras. A validação deve comparar contagem de registros, campos obrigatórios, horários de fonte e mudanças de esquema. A governança deve registrar quem aprovou a fonte, quais dados são permitidos e quando o fluxo deve ser revisado novamente.
Para fluxos com alto uso de navegador, a documentação do Playwright fornece um ponto de partida prático para renderização e interação controladas de páginas. Para fluxos com alto uso de raspagem, a documentação do Scrapy explica spideers, itens e pipelines. Para fluxos aprovados com alto uso de desafios, o guia de extensão do CapSolver pode ajudar os engenheiros a diagnosticar o comportamento real da página antes de projetar um caminho de API-first repetível.
| Padrão de arquitetura | Use quando | Adicione este controle |
|---|---|---|
| Apenas API | Campos obrigatórios estão disponíveis e os termos permitem o uso | Monitoramento de ponto de extremidade e tratamento de limites de taxa |
| Raspagem estática | Páginas públicas são estáveis e permitidas | Revisão do robots.txt e testes de seletores |
| Automação de navegador | Renderização ou interação é necessária | Orçamentos de tempo limite e validação de estado da página |
| Híbrido API mais raspagem | API cobre a maioria dos campos, mas páginas adicionam contexto | Regras de fonte de verdade e deduplicação |
| Raspagem mais CapSolver | Páginas aprovadas apresentam desafios de CAPTCHA | Tickets de aprovação, logs redigidos e limites de tentativas |
Essa estrutura torna a escolha ideal de raspagem de web vs API transparente. Também reduz o risco de equipes adicionarem automação de navegador ou resolução de CAPTCHA antes de provar que métodos mais simples não atendem aos requisitos comerciais.
Checklist de uso responsável
Um programa de automação responsável começa com revisão da fonte. Confirme que os dados são públicos ou autorizados, que o propósito da coleta é legítimo e que dados pessoais sensíveis ou restritos estão fora do escopo, a menos que exista uma base legal e controles de segurança. Em seguida, revise robots.txt, termos do site, documentação da API e obrigações contratuais. Por fim, teste em volume baixo e faça o fluxo parar quando paredes de login inesperadas, mudanças de permissão, picos de desafios ou desvio de esquema aparecerem.
O projeto de ameaças automatizadas da OWASP é um lembrete útil de que as mesmas técnicas de automação podem ser mal utilizadas. Seu padrão interno deve exigir permissão, taxas de solicitação proporcionais, identificação clara quando apropriado e revisão humana quando um fluxo mudar. O CapSolver deve ser usado apenas para alvos próprios, em estágio, aprovados por cliente ou de outra forma permitidos, onde o tratamento de desafios é parte de um processo de automação legítimo.
Conclusão
As melhores decisões de raspagem de web vs API devem ser feitas com uma hierarquia simples: use uma API quando atende aos requisitos, use raspagem estática permitida quando não for possível, use automação de navegador quando a renderização for necessária e adicione resolução de CAPTCHA apenas como um caminho excepcional documentado. Para equipes que precisam de tratamento confiável de desafios em automação aprovada, o guia legal de raspagem de web do CapSolver pode ajudar a integrar a resolução em um fluxo governado junto com APIs, raspadores, automação de navegador, monitoramento e revisão de conformidade.
Perguntas frequentes
Qual é a regra ideal para raspagem de web vs API?
A melhor regra é priorizar APIs. Use uma API quando ela fornece os dados sob termos aceitáveis e use a raspagem apenas quando páginas permitidas forem a fonte prática.
Quando a raspagem de web é melhor que uma API?
A raspagem de web é melhor quando dados públicos, permitidos, não estão disponíveis por meio de uma API adequada ou quando a própria apresentação da página é os dados que sua equipe precisa monitorar.
Quando a automação de navegador deve ser adicionada?
Adicione automação de navegador apenas quando extração HTTP estática não conseguir capturar conteúdo renderizado, interações do usuário ou dados pós-carregamento necessários para o fluxo aprovado.
Como o CapSolver se encaixa nos fluxos de raspagem de web vs API?
O CapSolver se encaixa quando um fluxo de raspagem de web ou automação de navegador aprovado encontra um desafio de CAPTCHA ou validação de tráfego suportado e precisa de um caminho de resolução documentado.
O que as equipes devem verificar antes da raspagem?
As equipes devem verificar permissão, robots.txt, termos, sensibilidade dos dados, taxa de solicitação e regras de monitoramento. Elas também podem revisar a Perguntas Frequentes sobre raspagem de web do CapSolver quando o tratamento de desafios for parte do plano aprovado.
Ver mais
Web ScrapingApr 22, 2026
Arquitetura de Web Scraping em Rust para Extração de Dados Escalável
Aprenda arquitetura de raspagem web escalável em Rust com reqwest, scraper, raspagem assíncrona, raspagem de navegador headless, rotação de proxies e tratamento de CAPTCHA compatível.
Web ScrapingApr 08, 2026
Selenium vs Puppeteer para Resolução de CAPTCHA: Comparação de Desempenho e Caso de Uso
Compare o Selenium vs Puppeteer para resolver CAPTCHA. Descubra benchmarks de desempenho, notas de estabilidade e como integrar o CapSolver para o máximo de sucesso.

