Como resolver reCAPTCHA v2 no Crawl4AI com integração do CapSolver

Adélia Cruz
Neural Network Developer

O checkbox "Não sou um robô" serve como um mecanismo de defesa crucial contra tráfego de bots e abuso automatizado em sites. Embora essencial para a segurança, ele frequentemente apresenta um desafio significativo para operações legítimas de raspagem de web e extração de dados. A necessidade de soluções eficientes e automatizadas para resolver CAPTCHAs tornou-se fundamental para desenvolvedores e empresas que dependem de automação web.
Este artigo explora a integração robusta do Crawl4AI, um raspador de web avançado, com o CapSolver, um serviço líder de resolução de CAPTCHA, especificamente focando na resolução do reCAPTCHA v2. Exploraremos os métodos de integração baseados em API e em extensão do navegador, fornecendo exemplos de código detalhados e explicações para ajudá-lo a alcançar a coleta de dados web sem interrupções.
Entendendo o reCAPTCHA v2 e seus Desafios
O reCAPTCHA v2 exige que os usuários cliquem em um checkbox, e às vezes completem desafios de imagem, para provar que são humanos. Para sistemas automatizados como raspadores de web, esse elemento interativo interrompe o processo de raspagem, exigindo intervenção manual ou técnicas avançadas de contorno. Sem uma solução eficaz, a coleta de dados torna-se ineficiente, instável e cara.
O CapSolver oferece uma solução de alta precisão e resposta rápida para o reCAPTCHA v2, utilizando algoritmos avançados de IA. Quando integrado ao Crawl4AI, ele transforma um obstáculo significativo em um passo automatizado, garantindo que suas tarefas de automação web permaneçam fluidas e produtivas.
💡 Bônus Exclusivo para Usuários de Integração com Crawl4AI:
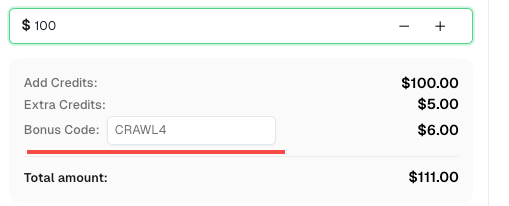
Para comemorar esta integração, oferecemos um código de bônus exclusivo —CRAWL4— para todos os usuários do CapSolver que se registrarem por meio deste tutorial.
Basta inserir o código durante o recarregamento no Painel de Controle para receber créditos extras de 6% instantaneamente.
Método de Integração 1: Integração da API do CapSolver com o Crawl4AI
O método de integração via API fornece controle fino e é geralmente recomendado por sua flexibilidade e precisão. Ele envolve o uso da funcionalidade js_code do Crawl4AI para injetar o token CAPTCHA obtido do CapSolver diretamente na página de destino.
Como Funciona:
- Navegar para a página do CAPTCHA: O Crawl4AI acessa a página da web alvo normalmente.
- Obter Token: No seu script Python, chame a API do CapSolver usando seu SDK, passando parâmetros necessários como
siteKeyewebsiteURLpara receber o tokengRecaptchaResponse. - Injetar Token: Utilize o parâmetro
js_codedentro doCrawlerRunConfigpara injetar o token obtido no elemento de textog-recaptcha-responsena página. - Continuar Operações: Após a injeção bem-sucedida do token, o Crawl4AI pode prosseguir com ações subsequentes, como submissões de formulário ou cliques, efetivamente contornando o reCAPTCHA.
Exemplo de Código: Integração via API para reCAPTCHA v2
O seguinte código Python demonstra como integrar a API do CapSolver ao Crawl4AI para resolver o reCAPTCHA v2. Este exemplo visa a página de demonstração do checkbox do reCAPTCHA v2.
python
import asyncio
import capsolver
from crawl4ai import *
# TODO: defina sua configuração
api_key = "CAP-xxxxxxxxxxxxxxxxxxxxx" # sua chave de API do CapSolver
site_key = "6LfW6wATAAAAAHLqO2pb8bDBahxlMxNdo9g947u9" # chave do site da sua página alvo
site_url = "https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php" # URL da página da sua página alvo
captcha_type = "ReCaptchaV2TaskProxyLess" # tipo do CAPTCHA da sua página alvo
capsolver.api_key = api_key
async def main():
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# obtenha o token do reCAPTCHA usando o SDK do CapSolver
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"websiteKey": site_key,
})
token = solution["gRecaptchaResponse"]
print("token do reCAPTCHA:", token)
js_code = """
const textarea = document.getElementById(\'g-recaptcha-response\');
if (textarea) {
textarea.value = \"""" + token + """\";
document.querySelector(\'button.form-field[type="submit"]\').click();
}
"""
wait_condition = """() => {
const items = document.querySelectorAll(\'h2\');
return items.length > 1;
}"""
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
wait_for=f"js:{wait_condition}"
)
result_next = await crawler.arun(
url=site_url,
config=run_config,
)
print(result_next.markdown)
if __name__ == "__main__":
asyncio.run(main())Análise do Código:
- Chamada da SDK do CapSolver: O método
capsolver.solveé invocado com o tipoReCaptchaV2TaskProxyLess,websiteURLewebsiteKeypara recuperar o tokengRecaptchaResponse. Este token é a solução fornecida pelo CapSolver. - Injeção de JavaScript (
js_code): A stringjs_codecontém JavaScript que localiza o elemento de textog-recaptcha-responsena página e atribui o token obtido à propriedadevalue. Em seguida, simula um clique no botão de submissão, garantindo que o formulário seja submetido com o token CAPTCHA válido. - Condição de Espera: Uma
wait_conditioné definida para garantir que o Crawl4AI aguarde por um elemento específico para aparecer na página, indicando que a submissão foi bem-sucedida e que a página carregou novo conteúdo.
Método de Integração 2: Integração da Extensão do CapSolver
Para cenários em que a injeção direta da API pode ser complexa ou menos desejável, a extensão do CapSolver oferece uma alternativa. Este método utiliza a capacidade da extensão de detectar e resolver CAPTCHAs automaticamente dentro do contexto do navegador gerenciado pelo Crawl4AI.
Como Funciona:
- Iniciar o navegador com
user_data_dir: Configure o Crawl4AI para iniciar uma instância do navegador com umuser_data_direspecificado para manter o contexto persistente. - Instalar e Configurar a Extensão: Instale manualmente a extensão CapSolver neste perfil do navegador e configure sua chave de API do CapSolver. Você também pode pré-configurar os parâmetros
apiKeyemanualSolvingno arquivoconfig.jsda extensão. - Navegar para a Página do CAPTCHA: O Crawl4AI navega para a página que contém o reCAPTCHA v2.
- Resolução Automática ou Manual: Dependendo da configuração
manualSolvingda extensão, o CAPTCHA será resolvido automaticamente ao ser detectado, ou você pode ativá-lo manualmente via JavaScript injetado. - Verificação: Após resolver, o token é automaticamente gerenciado pela extensão, e ações subsequentes como submissões de formulário carregarão a verificação válida.
Exemplo de Código: Integração via Extensão para reCAPTCHA v2 (Resolução Automática)
Este exemplo mostra como o Crawl4AI pode ser configurado para usar um perfil do navegador com a extensão CapSolver para resolução automática do reCAPTCHA v2.
python
import asyncio
import time
from crawl4ai import *
# TODO: defina sua configuração
user_data_dir = "/browser-profile/Default1" # Certifique-se de que este caminho esteja correto e contenha sua extensão configurada
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120", # Opcional: configure o proxy se necessário
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# A extensão resolverá automaticamente o CAPTCHA ao carregar a página.
# Você pode precisar adicionar uma condição de espera ou usar time.sleep para dar tempo ao CAPTCHA ser resolvido
# antes de prosseguir com outras ações.
time.sleep(30) # Exemplo de espera, ajuste conforme necessário
# Continue com outras operações do Crawl4AI após a resolução do CAPTCHA
# Por exemplo, verifique elementos que aparecem após a submissão bem-sucedida
# print(result_initial.markdown) # Você pode inspecionar o conteúdo da página após a espera
if __name__ == "__main__":
asyncio.run(main())Análise do Código:
user_data_dir: Este parâmetro é crucial para o Crawl4AI iniciar uma instância do navegador que mantém a extensão CapSolver instalada e suas configurações. Certifique-se de que o caminho aponte para um diretório válido de perfil do navegador onde a extensão está instalada.- Resolução Automática: Com
manualSolvingdefinido comofalse(ou padrão) na configuração da extensão, a extensão automaticamente detectará e resolverá o reCAPTCHA v2 ao carregar a página. Umtime.sleepé incluído como exemplo para dar tempo à extensão resolver o CAPTCHA antes de quaisquer ações subsequentes.
Exemplo de Código: Integração via Extensão para reCAPTCHA v2 (Resolução Manual)
Se preferir disparar a resolução do CAPTCHA manualmente em um ponto específico da lógica de raspagem, você pode configurar o parâmetro manualSolving da extensão como true e usar js_code para clicar no botão do solucionador fornecido pela extensão.
python
import asyncio
import time
from crawl4ai import *
# TODO: defina sua configuração
user_data_dir = "/browser-profile/Default1" # Certifique-se de que este caminho esteja correto e contenha sua extensão configurada
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120", # Opcional: configure o proxy se necessário
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# Aguarde um momento para a página carregar e a extensão estar pronta
time.sleep(6)
# Use js_code para disparar o botão de resolução manual fornecido pela extensão do CapSolver
js_code = """
let solverButton = document.querySelector(\'#capsolver-solver-tip-button\');
if (solverButton) {
const clickEvent = new MouseEvent(\'click\', {
bubbles: true,
cancelable: true,
view: window
});
solverButton.dispatchEvent(clickEvent);
}
"""
print(js_code)
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
)
result_next = await crawler.arun(
url="https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php",
config=run_config
)
print("Resultados da execução JS:", result_next.js_execution_result)
# Permita tempo para o CAPTCHA ser resolvido após o disparo manual
time.sleep(30) # Exemplo de espera, ajuste conforme necessário
# Continue com outras operações do Crawl4AI
if __name__ == "__main__":
asyncio.run(main())Análise do Código:
manualSolving: Antes de executar este código, certifique-se de que oconfig.jsda extensão do CapSolver tenhamanualSolvingdefinido comotrue.- Disparar a Solução: O
js_codesimula um evento de clique no#capsolver-solver-tip-button, que é o botão fornecido pela extensão do CapSolver para resolução manual. Isso lhe dá controle preciso sobre quando o processo de resolução do CAPTCHA é iniciado.
Conclusão
A integração do Crawl4AI com o CapSolver fornece soluções poderosas e flexíveis para contornar o reCAPTCHA v2, aumentando significativamente a eficiência e a confiabilidade das operações de raspagem de web. Se optar pelo controle preciso da integração via API ou pela configuração simplificada da integração via extensão, ambos os métodos garantem que o reCAPTCHA v2 não seja mais um obstáculo para seus objetivos de coleta de dados.
Ao automatizar a resolução de CAPTCHA, os desenvolvedores podem focar na extração de dados valiosos, confiantes de que seus raspadores navegarão por sites protegidos de forma semanal. Esta sinergia entre as capacidades avançadas de raspagem do Crawl4AI e a tecnologia robusta de resolução de CAPTCHA do CapSolver representa um grande passo à frente na extração automatizada de dados da web.
Referências
Ver mais
reCAPTCHAApr 16, 2026
reCAPTCHA Chave de Site Inválida ou Token Inválido? Causas & Guia de Solução
Enfrentando "Chave de Site Inválida do reCAPTCHA" ou "token do reCAPTCHA inválido"? Descubra causas comuns, soluções passo a passo e dicas de solução de problemas para resolver problemas de verificação do reCAPTCHA. Aprenda como corrigir o erro de verificação do reCAPTCHA, por favor tente novamente.

reCAPTCHAFeb 12, 2026
Como corrigir problemas comuns de reCAPTCHA em raspagem de web
Aprenda como corrigir problemas comuns do reCAPTCHA na raspagem da web. Descubra soluções práticas para o reCAPTCHA v2 e v3 para manter fluxos de coleta de dados sem interrupções.

