Como resolver AWS WAF no Crawl4AI com integração CapSolver

Adélia Cruz
Neural Network Developer

Introdução
O Amazon Web Services (AWS) Web Application Firewall (WAF) é um serviço de segurança poderoso que ajuda a proteger aplicações web de explorações comuns que podem afetar a disponibilidade, comprometer a segurança ou consumir recursos excessivos. Embora seja crucial para proteger os ativos web, o AWS WAF pode apresentar um desafio significativo para processos de raspagem web automatizados e extração de dados, muitas vezes bloqueando crawlers legítimos.
Este artigo fornece um guia completo sobre como integrar de forma fluida o Crawl4AI, um raspador web avançado, com o CapSolver, um serviço líder de solução de CAPTCHA e anti-bot, para resolver efetivamente as proteções do AWS WAF. Detalharemos o método de integração via API e de extensão, incluindo exemplos de código e explicações, para garantir que suas tarefas de automação web possam prosseguir sem interrupções.
Entendendo o AWS WAF e seus Desafios para Raspagem de Web
AWS WAF opera monitorando solicitações HTTP(S) que são encaminhadas para uma distribuição Amazon CloudFront, um Application Load Balancer, um Amazon API Gateway ou uma API GraphQL AWS AppSync. Ele permite que você configure regras que bloqueiem padrões de ataque comuns, como injeção de SQL ou scripting entre sites, e também pode filtrar o tráfego com base em endereços IP, cabeçalhos HTTP, corpo HTTP ou strings de URI. Para raspadores web, isso muitas vezes significa:
- Filtragem de Solicitações: As regras do WAF podem identificar e bloquear solicitações que pareçam automatizadas ou maliciosas.
- Verificação Baseada em Cookies: O AWS WAF usa frequentemente cookies específicos para rastrear e verificar sessões de usuários legítimos. Sem esses cookies, as solicitações são frequentemente negadas.
- Desafios Dinâmicos: Embora não seja um CAPTCHA tradicional, os mecanismos subjacentes podem atuar como uma barreira, exigindo tokens específicos ou identificadores de sessão para prosseguir.
O CapSolver fornece uma solução robusta para obter o cookie aws-waf-token, que é essencial para contornar o AWS WAF. Quando integrado ao Crawl4AI, isso permite que seus raspadores imitem o comportamento de usuários legítimos e naveguem com sucesso em sites protegidos.
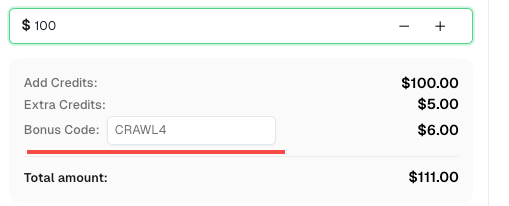
💡 Bônus Exclusivo para Usuários de Integração com Crawl4AI:
Para comemorar esta integração, oferecemos um código de bônus exclusivo de 6% —CRAWL4para todos os usuários do CapSolver que se registrarem por meio deste tutorial.
Basta inserir o código durante o recarregamento no Painel de Controle para receber créditos extras de 6% instantaneamente.
Método de Integração 1: Integração da API do CapSolver com o Crawl4AI
O modo mais eficaz de lidar com desafios do AWS WAF com o Crawl4AI e o CapSolver é através da integração via API. Este método envolve o uso do CapSolver para obter o aws-waf-token necessário e, em seguida, injetar este token como um cookie no contexto do navegador do Crawl4AI antes de recarregar a página de destino.
Como Funciona:
- Navegação Inicial: O Crawl4AI tenta acessar a página web protegida pelo AWS WAF.
- Identificar Desafio do WAF: Ao encontrar o WAF, seu script reconhecerá a necessidade de um
aws-waf-token. - Obter Cookie AWS WAF: Chame a API do CapSolver usando seu SDK, especificando o tipo
AntiAwsWafTaskProxyLessjunto comwebsiteURL. O CapSolver retornará o cookieaws-waf-tokennecessário. - Injetar Cookie e Recarregar: Utilize a funcionalidade
js_codedo Crawl4AI para definir oaws-waf-tokenobtido como um cookie no contexto do navegador. Após definir o cookie, a página é recarregada. - Continuar Operações: Com o cookie
aws-waf-tokencorreto em vigor, o Crawl4AI pode acessar com sucesso a página protegida e continuar com suas tarefas de extração de dados.
Exemplo de Código: Integração via API para AWS WAF
O seguinte código Python demonstra como integrar a API do CapSolver ao Crawl4AI para resolver desafios do AWS WAF. Este exemplo visa uma página de onboarding de NFT da Porsche protegida pelo AWS WAF.
python
import asyncio
import capsolver
from crawl4ai import *
# TODO: defina sua configuração
api_key = "CAP-xxxxxxxxxxxxxxxxxxxxx" # sua chave de API do capsolver
site_url = "https://nft.porsche.com/onboarding@6" # URL da página de destino
cookie_domain = ".nft.porsche.com" # o nome do domínio ao qual deseja aplicar o cookie
captcha_type = "AntiAwsWafTaskProxyLess" # tipo do seu CAPTCHA alvo
capsolver.api_key = api_key
async def main():
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# obter cookie aws waf usando o sdk capsolver
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
})
cookie = solution["cookie"]
print("cookie aws waf:", cookie)
js_code = """
document.cookie = \'aws-waf-token=""" + cookie + """;domain=""" + cookie_domain + """;path=/\
\';
location.reload();
"""
wait_condition = """() => {
return document.title === \'Join Porsche’s journey into Web3\';
}"""
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
wait_for=f"js:{wait_condition}"
)
result_next = await crawler.arun(
url=site_url,
config=run_config,
)
print(result_next.markdown)
if __name__ == "__main__":
asyncio.run(main())Análise do Código:
- Chamada do SDK do CapSolver: O método
capsolver.solveé invocado com o tipoAntiAwsWafTaskProxyLessewebsiteURLpara recuperar o cookieaws-waf-token. Este é o passo crucial onde o AI do CapSolver resolve o desafio do WAF e fornece o cookie necessário. - Injeção de JavaScript (
js_code): A stringjs_codecontém JavaScript que define o cookieaws-waf-tokenno contexto do navegador usandodocument.cookie. Em seguida, disparalocation.reload()para recarregar a página, garantindo que a próxima solicitação inclua o cookie válido recém-definido. - Condição
wait_for: Umawait_conditioné definida para garantir que o Crawl4AI espere pelo título da página ser 'Join Porsche’s journey into Web3', indicando que o WAF foi contornado com sucesso e o conteúdo desejado foi carregado.
Método de Integração 2: Integração da Extensão do CapSolver
A extensão do CapSolver oferece uma abordagem simplificada para lidar com desafios do AWS WAF, especialmente quando se utiliza suas capacidades de resolução automática dentro de um contexto de navegador persistente gerenciado pelo Crawl4AI.
Como Funciona:
- Contexto de Navegador Persistente: Configure o Crawl4AI para usar um
user_data_dirpara iniciar uma instância de navegador que mantém a extensão CapSolver instalada e suas configurações. - Instalar e Configurar a Extensão: Instale manualmente a extensão CapSolver neste perfil de navegador e configure sua chave de API do CapSolver. A extensão pode ser configurada para resolver automaticamente os desafios do AWS WAF.
- Navegar para a Página Alvo: O Crawl4AI navega para a página protegida pelo AWS WAF.
- Resolução Automática: A extensão CapSolver, executando dentro do contexto do navegador, detecta o desafio do AWS WAF e obtém automaticamente o cookie
aws-waf-token. Este cookie é então automaticamente aplicado às solicitações subsequentes. - Proceder com Ações: Após a resolução do AWS WAF pela extensão, o Crawl4AI pode continuar com suas tarefas de raspagem, pois o contexto do navegador agora terá os cookies válidos necessários para solicitações subsequentes.
Exemplo de Código: Integração de Extensão para AWS WAF (Resolução Automática)
Este exemplo demonstra como configurar o Crawl4AI para usar um perfil de navegador com a extensão CapSolver para resolução automática do AWS WAF.
python
import asyncio
import time
from crawl4ai import *
# TODO: defina sua configuração
user_data_dir = "/browser-profile/Default1" # Certifique-se de que este caminho esteja correto e contenha sua extensão configurada
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120", # Opcional: configure o proxy se necessário
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://nft.porsche.com/onboarding@6",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# A extensão resolverá automaticamente o AWS WAF ao carregar a página.
# Você pode precisar adicionar uma condição de espera ou time.sleep para que o WAF seja resolvido
# antes de prosseguir com outras ações.
time.sleep(30) # Exemplo de espera, ajuste conforme necessário para a extensão operar
# Continue com outras operações do Crawl4AI após a resolução do AWS WAF
# Por exemplo, verifique elementos ou conteúdo que apareçam após a verificação bem-sucedida
# print(result_initial.markdown) # Você pode inspecionar o conteúdo da página após a espera
if __name__ == "__main__":
asyncio.run(main())Análise do Código:
user_data_dir: Este parâmetro é essencial para o Crawl4AI iniciar uma instância de navegador que mantém a extensão CapSolver instalada e suas configurações. Certifique-se de que o caminho aponte para um diretório válido de perfil de navegador onde a extensão esteja instalada.- Resolução Automática: A extensão CapSolver é projetada para detectar e resolver automaticamente desafios do AWS WAF. Um
time.sleepé incluído como um exemplo geral para permitir que a extensão complete suas operações em segundo plano. Para soluções mais robustas, considere usar a funcionalidadewait_fordo Crawl4AI para verificar mudanças específicas na página que indiquem a resolução bem-sucedida do AWS WAF.
Exemplo de Código: Integração de Extensão para AWS WAF (Resolução Manual)
Se você preferir disparar a resolução do AWS WAF manualmente em um ponto específico da lógica de raspagem, pode configurar o parâmetro manualSolving da extensão para true e, em seguida, usar js_code para clicar no botão de resolução fornecido pela extensão.
python
import asyncio
import time
from crawl4ai import *
# TODO: defina sua configuração
user_data_dir = "/browser-profile/Default1" # Certifique-se de que este caminho esteja correto e contenha sua extensão configurada
browser_config = BrowserConfig(
verbose=True,
headless=False,
user_data_dir=user_data_dir,
use_persistent_context=True,
proxy="http://127.0.0.1:13120", # Opcional: configure o proxy se necessário
)
async def main():
async with AsyncWebCrawler(config=browser_config) as crawler:
result_initial = await crawler.arun(
url="https://nft.porsche.com/onboarding@6",
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
# Aguarde um momento para que a página carregue e a extensão esteja pronta
time.sleep(6)
# Use js_code para disparar o botão de resolução manual fornecido pela extensão CapSolver
js_code = """
let solverButton = document.querySelector(\'#capsolver-solver-tip-button\');
if (solverButton) {
// evento de clique
const clickEvent = new MouseEvent(\'click\', {
bubbles: true,
cancelable: true,
view: window
});
solverButton.dispatchEvent(clickEvent);
}
"""
print(js_code)
run_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test",
js_code=js_code,
js_only=True,
)
result_next = await crawler.arun(
url="https://nft.porsche.com/onboarding@6",
config=run_config
)
print("Resultados da execução JS:", result_next.js_execution_result)
# Permita tempo para que o AWS WAF seja resolvido após o disparo manual
time.sleep(30) # Exemplo de espera, ajuste conforme necessário
# Continue com outras operações do Crawl4AI
if __name__ == "__main__":
asyncio.run(main())Análise do Código:
manualSolving: Antes de executar este código, certifique-se de que oconfig.jsda extensão CapSolver tenhamanualSolvingdefinido comotrue.- Disparar Resolução: O
js_codesimula um evento de clique no#capsolver-solver-tip-button, que é o botão fornecido pela extensão CapSolver para resolução manual. Isso lhe dá controle preciso sobre quando o processo de resolução do AWS WAF é iniciado.
Conclusão
A integração do Crawl4AI com o CapSolver oferece uma solução robusta e eficiente para contornar as proteções do AWS WAF, permitindo raspagem de web e extração de dados sem interrupções. Ao utilizar a capacidade do CapSolver de obter o token crítico aws-waf-token e as funcionalidades flexíveis de injeção de js_code do Crawl4AI, os desenvolvedores podem garantir que seus processos automatizados naveguem por sites protegidos pelo WAF de forma fluida.
Esta integração não apenas melhora a estabilidade e a taxa de sucesso dos seus raspadores, mas também reduz significativamente a carga operacional associada à gestão de mecanismos anti-bot complexos. Com esta combinação poderosa, você pode coletar dados com confiança até mesmo de aplicações web protegidas de forma mais segura.
Perguntas Frequentes (FAQ)
Q1: O que é AWS WAF e por que ele é usado na raspagem de web?
A1: O AWS WAF (Firewall de Aplicação Web) é um serviço de segurança baseado em nuvem que protege aplicações web de explorações comuns. Na raspagem de web, ele é encontrado como um mecanismo anti-bot que bloqueia solicitações consideradas suspeitas ou automatizadas, exigindo técnicas de contorno para acessar os dados alvo.
Q2: Como o CapSolver ajuda a contornar o AWS WAF?
A2: O CapSolver fornece serviços especializados, como AntiAwsWafTaskProxyLess, para resolver desafios do AWS WAF. Ele obtém o cookie aws-waf-token necessário, que é então usado pelo Crawl4AI para imitar o comportamento de usuários legítimos e obter acesso ao site protegido.
Q3: Quais são os principais métodos de integração da AWS WAF com o Crawl4AI e o CapSolver?
A3: Existem dois métodos principais: integração via API, onde a API do CapSolver é chamada para obter o aws-waf-token que é então injetado via js_code do Crawl4AI, e integração via Extensão do Navegador, onde a extensão do CapSolver lida automaticamente com o desafio do WAF dentro de um contexto de navegador persistente.
Q4: É necessário usar um proxy ao resolver a AWS WAF com o CapSolver?
A4: Embora nem sempre seja estritamente necessário, o uso de um pro
Ver mais
aws wafJul 23, 2026
Como resolver o AWS WAF em LangChain com CapSolver
Construa um fluxo de trabalho autorizado da AWS WAF LangChain com ferramentas CapSolver, detecção de respostas, portas de política, gerenciamento de sessão, tentativas de repetição e verificação.
aws wafApr 21, 2026
AWS WAF vs Cloudflare: Resolução de CAPTCHA para automação (Guia de 2026)
Compare o AWS WAF vs desafios de CAPTCHA do Cloudflare. Aprenda como resolver o AWS WAF e o Cloudflare Turnstile para automação web com altas taxas de sucesso usando o CapSolver.
