Alternativas para Scraper de IA para Automação Confiável de Dados da Web

Adélia Cruz
Neural Network Developer
Resumo
- Alternativas para raspagem de sites com IA devem ser comparadas por precisão de extração, controle de navegador, cobertura de API, controles de conformidade e manejo de desafios, em vez de apenas pela interface.
- O fluxo de trabalho mais forte geralmente combina uma camada de extração com IA com crawlers determinísticos, APIs oficiais, monitoramento e um caminho controlado para resolver CAPTCHAs em destinos aprovados.
- Automação de navegador é útil para páginas dinâmicas, mas as equipes precisam de limites de taxa, revisão de robots.txt, verificações de permissão e condições claras de parada antes de coletar dados.
- Desafios de CAPTCHA são um ponto de verificação de confiabilidade em alguns fluxos de raspagem autorizados, e o CapSolver pode ajudar as equipes a lidar com eles por meio de APIs documentadas e caminhos de extensão de navegador.
- As equipes devem escolher ferramentas que preservem registros de auditoria, reduzam o trabalho de manutenção e tornem o uso responsável mais fácil para engenheiros e operadores.
Introdução
Alternativas para raspagem de sites com IA já não são apenas ferramentas sem código visual. Elas agora incluem agentes de navegador, APIs de extração, frameworks de crawler e fluxos híbridos que usam aprendizado de máquina apenas onde adiciona valor. A melhor escolha é aquela que coleta dados públicos permitidos com precisão, documenta como o fluxo se comporta e lida com eventos de validação de tráfego de forma responsável. Quando a automação aprovada atinge um CAPTCHA ou desafio semelhante, o guia Resolução de CAPTCHA durante a raspagem do CapSolver pode ajudar as equipes a definir um caminho de exceção controlado em vez de tratar a resolução como a estratégia principal. Este guia compara opções baseadas em IA, APIs, navegadores e híbridas para que as equipes construam automação de dados da web confiável sem repetir padrões frágeis de raspagem.
O que é considerado uma alternativa para raspagem de sites com IA
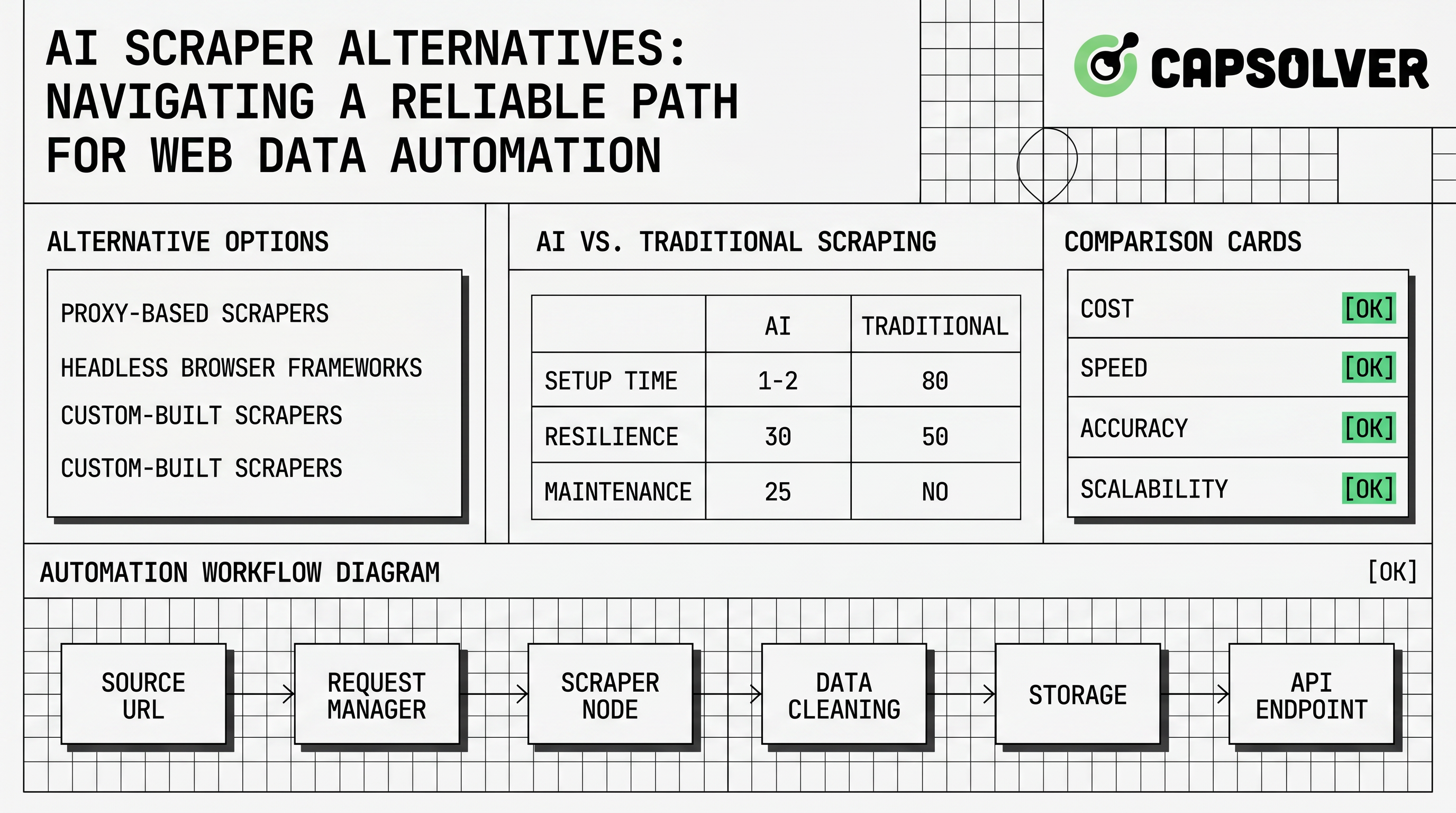
Uma alternativa para raspagem de sites com IA é qualquer ferramenta ou arquitetura que ajude uma equipe a coletar dados da web estruturados sem depender de seletores frágeis e únicos. Algumas ferramentas usam modelos de linguagem para inferir campos a partir de páginas. Outras fornecem renderização gerenciada, raspagem programada, roteamento de proxy ou APIs de extração prontas. Frameworks tradicionais também permanecem relevantes porque código determinístico é mais fácil de auditar, testar e manter quando a estrutura do site de destino é estável.
O mercado é amplo porque páginas da web variam. Catálogos de produtos, placas de empregos, listagens de viagens e diretórios públicos expõem diferentes marcas, paginação, carregamento lento e comportamento de sessão. A visão geral da IBM sobre raspagem com IA descreve a raspagem com IA como o uso de IA para automatizar a extração de dados de sites. A documentação do Scrapy mostra a extremidade oposta: um framework de crawler programável para extração estruturada. Equipes sérias geralmente precisam de ambos os conceitos, pois a IA pode reduzir o trabalho de mapeamento enquanto o código determinístico mantém a produção previsível.
| Tipo de alternativa | Melhor ajuste | Principais vantagens | Riscos a gerenciar |
|---|---|---|---|
| Ferramenta de extração com IA | Layouts em mudança e páginas semi-estruturadas | Mapeamento de campo mais rápido e menor esforço de configuração | Drift de saída e menor auditableidade |
| Automação de navegador | Aplicações dinâmicas e páginas com JavaScript pesado | Execução real da página e suporte a interação | Maior custo, falhas de tempo e eventos de desafio |
| API de raspagem | Renderização gerenciada e simplicidade operacional | Menor trabalho de infraestrutura | Dependência de fornecedor e menos controle de fluxo de trabalho |
| Framework de crawler | Páginas estáveis e pipelines repetíveis | Testes fortes e controle de versão | Mais trabalho de engenharia no início |
| Pilha híbrida | Equipes de produção com destinos variados | Equilíbrio entre flexibilidade e governança | Requer propriedade clara e documentação |
Alternativas para raspagem de sites com IA devem ser selecionadas no nível do fluxo de trabalho. Uma ferramenta que parece impressionante em uma demonstração ainda pode falhar se não puder registrar aprovações, respeitar regras de site, repetir com segurança ou parar quando uma página mudar.
Critérios de avaliação para alternativas para raspagem de sites com IA
O primeiro critério é a precisão dos dados. Um raspador moderno deve retornar campos consistentes, preservar URLs de origem e tornar a incerteza visível. Para extração baseada em IA, isso significa amostrar saídas, comparar com registros revisados por humanos e monitorar campos de alucinação. Para crawlers determinísticos, significa testes unitários, monitoramento de seletores e tratamento claro de páginas vazias ou alteradas.
O segundo critério é o acesso responsável. As equipes devem revisar robots.txt, termos, disponibilidade de API, limites de taxa e permissões contratuais antes da automação. O Protocolo de Exclusão de Robôs RFC 9309 define robots.txt como um protocolo para clientes automatizados identificarem regras de acesso, enquanto a referência de URL do MDN é útil quando as equipes normalizam URLs canônicos e deduplicam registros. Capacidade técnica não cria permissão para coletar dados privados, sensíveis, restritos ou não autorizados.
O terceiro critério é o manejo de desafios. Alguns destinos aprovados usam CAPTCHA, Cloudflare Turnstile ou outros sistemas de validação de tráfego. Nesses casos, a resolução de CAPTCHA deve ser tratada como um caminho de exceção documentado com aprovação, limites de taxa, logs redigidos e validação de resultados. O glossário de CAPTCHA do CapSolver ajuda as equipes a alinhar terminologia antes de projetar um fluxo de trabalho.
Onde a resolução de CAPTCHA se encaixa na automação de dados da web
A resolução de CAPTCHA não é o centro de uma arquitetura de raspagem com IA, mas pode ser uma camada de confiabilidade necessária para automação permitida. A sequência correta é simples. Primeiro, prefira APIs oficiais ou feeds de dados quando existirem. Segundo, use extração HTTP leve quando as páginas forem estáticas e permitidas. Terceiro, use automação de navegador apenas quando for necessário renderização ou interação. Finalmente, adicione um caminho controlado para lidar com desafios apenas quando o fluxo for aprovado e a página apresentar um passo de validação.
Por esse motivo, o CapSolver é melhor introduzido como um componente de fluxo de trabalho. O FAQ de raspagem da web do CapSolver fornece contexto para fluxos de trabalho de extração, enquanto o guia de integração do CapSolver com Playwright mostra como o manejo de desafios pode se conectar à automação de navegador. O objetivo não é forçar cada raspador por um serviço de resolução de desafios. O objetivo é tornar o caminho excepcional consistente, auditável e mais fácil de testar.
Código Bônus para teste de automação aprovada
Resgate seu Código Bônus do CapSolver
Aumente seu orçamento de automação instantaneamente!
Use o código bônus CAP26 ao recarregar sua conta do CapSolver para obter um bônus adicional de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel do CapSolver
Arquitetura prática para alternativas para raspagem de sites com IA
Uma arquitetura confiável separa descoberta, extração, validação e armazenamento. A descoberta identifica URLs permitidos e regras de agendamento. A extração usa o método de menor complexidade que funciona, como uma chamada de API, parser HTTP, automação de navegador ou prompt de extração com IA. A validação verifica a completude do esquema, registros duplicados, horários e evidências de origem. O armazenamento mantém instantâneos brutos ou IDs de rastreamento quando equipes de conformidade precisam revisar o processo de coleta.
Para páginas dinâmicas, ferramentas de navegador como a documentação do Playwright fornecem renderização e interação controladas. Para pipelines de crawler, frameworks como o Scrapy fornecem agendamento, pipelines de itens e middleware. Para eventos de desafio, as equipes podem se referir ao guia de extensão do CapSolver durante a depuração e depois mover fluxos estáveis para uma integração baseada em API. Isso mantém a diagnóstico humano separado da automação de produção repetível.
| Camada de fluxo de trabalho | Controle recomendado | Por que importa |
|---|---|---|
| Revisão de permissão | Domínios aprovados e classes de dados permitidas | Evita coleta além do escopo desejado |
| Extração | API primeiro, depois HTTP, depois navegador, depois análise assistida por IA | Reduz custo e evita complexidade desnecessária |
| Manejo de desafios | Caminho documentado do CapSolver para destinos aprovados | Mantém eventos de CAPTCHA de se tornarem correções manuais ad hoc |
| Monitoramento | Verificação de esquema e alertas de alteração de página | Detecta desvio antes que dados ruins cheguem aos usuários |
| Registro | IDs de tarefa redigidos e evidências de origem | Suporta auditoria sem expor valores sensíveis |
Esta arquitetura também ajuda as equipes a decidir quando não usar IA. Se uma página tiver marcação estável e modelo de paginação previsível, o código determinístico pode ser mais confiável que um extrator baseado em modelo. Se a fonte oferecer uma API documentada, essa API deve normalmente vir antes da raspagem.
Como escolher a melhor opção
Escolha um raspador baseado em IA quando o layout da página mudar frequentemente e o valor comercial justificar revisão e monitoramento. Escolha um framework de crawler quando sua equipe puder manter código e precisar de comportamento de produção repetível. Escolha uma API de raspagem gerenciada quando o custo de infraestrutura for o principal gargalo. Escolha automação de navegador quando o site depender fortemente de JavaScript ou interação semelhante a usuários. Escolha o CapSolver quando um fluxo aprovado atingir um CAPTCHA ou desafio de validação de tráfego suportado e a equipe precisar de um caminho consistente de resolução.
Equipes de segurança e conformidade devem ser envolvidas cedo. O projeto OWASP Automated Threats explica padrões comuns de automação abusiva, o que o torna um checklist útil para o que sistemas responsáveis devem evitar. Um raspador responsável deve se identificar quando apropriado, obedecer limites, evitar dados sensíveis e parar quando a autorização ou comportamento da página for incerto.
Conclusão
Alternativas para raspagem de sites com IA devem ser avaliadas como modelos operacionais, não apenas ferramentas. As melhores equipes combinam APIs oficiais, crawlers determinísticos, automação de navegador, extração com IA, monitoramento e um caminho de exceção documentado para desafios de CAPTCHA. Se seu fluxo de dados da web aprovado precisar de manejo confiável de desafios como parte dessa arquitetura, o guia de raspagem web responsável do CapSolver é uma referência prática porque explica como o tratamento de CAPTCHA se encaixa na governança de automação responsável.
Perguntas frequentes
O que são alternativas para raspagem de sites com IA?
Alternativas para raspagem de sites com IA são ferramentas ou arquiteturas para extração de dados da web, incluindo ferramentas de extração com IA, automação de navegador, APIs de raspagem, frameworks de crawler e sistemas híbridos.
Quando uma equipe deve usar automação de navegador para raspagem?
Use automação de navegador quando páginas de destino permitidas exigirem renderização de JavaScript, interação semelhante a usuários ou extração de dados pós-carregamento que solicitações HTTP simples não conseguem capturar de forma confiável.
Todo raspador com IA precisa de resolução de CAPTCHA?
Não. A resolução de CAPTCHA é relevante apenas quando um fluxo aprovado encontra um desafio suportado. Muitas tarefas de raspagem da web devem usar APIs oficiais, extração estática ou parcerias de dados em vez disso.
Como o CapSolver pode apoiar alternativas para raspagem de sites com IA?
O CapSolver pode apoiar fluxos aprovados ao lidar com desafios de CAPTCHA e validação de tráfego por meio de caminhos de API ou extensão de navegador documentados, especialmente em QA, monitoramento e automação de navegador.
Qual é o caminho mais seguro para começar?
Comece com revisão de permissão, revisão de robots.txt e um pequeno piloto. Em seguida, compare opções de API, crawler, navegador e extração com IA antes de adicionar gerenciamento de desafios de CAPTCHA onde for claramente justificado.
Ver mais
AutomationJul 07, 2026
Tratamento de Captcha na Automação do Protocolo Judicial no Legaltech
Melhorar o gerenciamento de CAPTCHA na automação de protocolos judiciais para LegalTech: fluxos de trabalho compatíveis e ferramentas para simplificar o protocolo eletrônico, reduzir erros e acelerar as submissões.
AutomationJul 07, 2026
Como resolver CAPTCHA em sistemas de rastreamento de estoque de e-commerce
Aprenda como resolver CAPTCHA no rastreamento de estoque em e-commerce com métodos práticos, dicas de automação e conformidade para manter os dados de estoque precisos e escaláveis.