CapSolver Arquitetura IA-MLG na Prática: Construindo uma Pipeline de Decisão para Sistemas de Reconhecimento de CAPTCHA Adaptativos

Adélia Cruz
Neural Network Developer

CAPTCHAs se tornaram cada vez mais variados e complexos — desde desafios de texto simples até quebra-cabeças interativos e lógica baseada em risco dinâmica — e os fluxos de automação atuais exigem mais do que apenas reconhecimento de imagem básico. OCR tradicional e modelos CNN independentes têm dificuldade em acompanhar os formatos em evolução e as tarefas visuais e semânticas mistas.
Em nosso artigo anterior, "AI-LLM: A Solução Futura para Reconhecimento de Imagens de Controle de Risco e Resolução de CAPTCHA", exploramos por que os grandes modelos de linguagem estão se tornando um componente essencial nos sistemas modernos de CAPTCHA. Este artigo constrói sobre isso, examinando a arquitetura prática por trás da pipeline de decisão do CapSolver: como diferentes tipos de CAPTCHA são direcionados para a estratégia correta de resolução e como o sistema se adapta à medida que novos formatos surgem.
O desafio principal não é apenas reconhecer pixels, mas entender a intenção por trás de um CAPTCHA e se adaptar em tempo real. A Arquitetura do CapSolver AI-LLM combina visão computacional com raciocínio de alto nível para tomar decisões estratégicas em vez de apenas correspondência de padrões.
Aqui está uma visão geral dessa arquitetura:
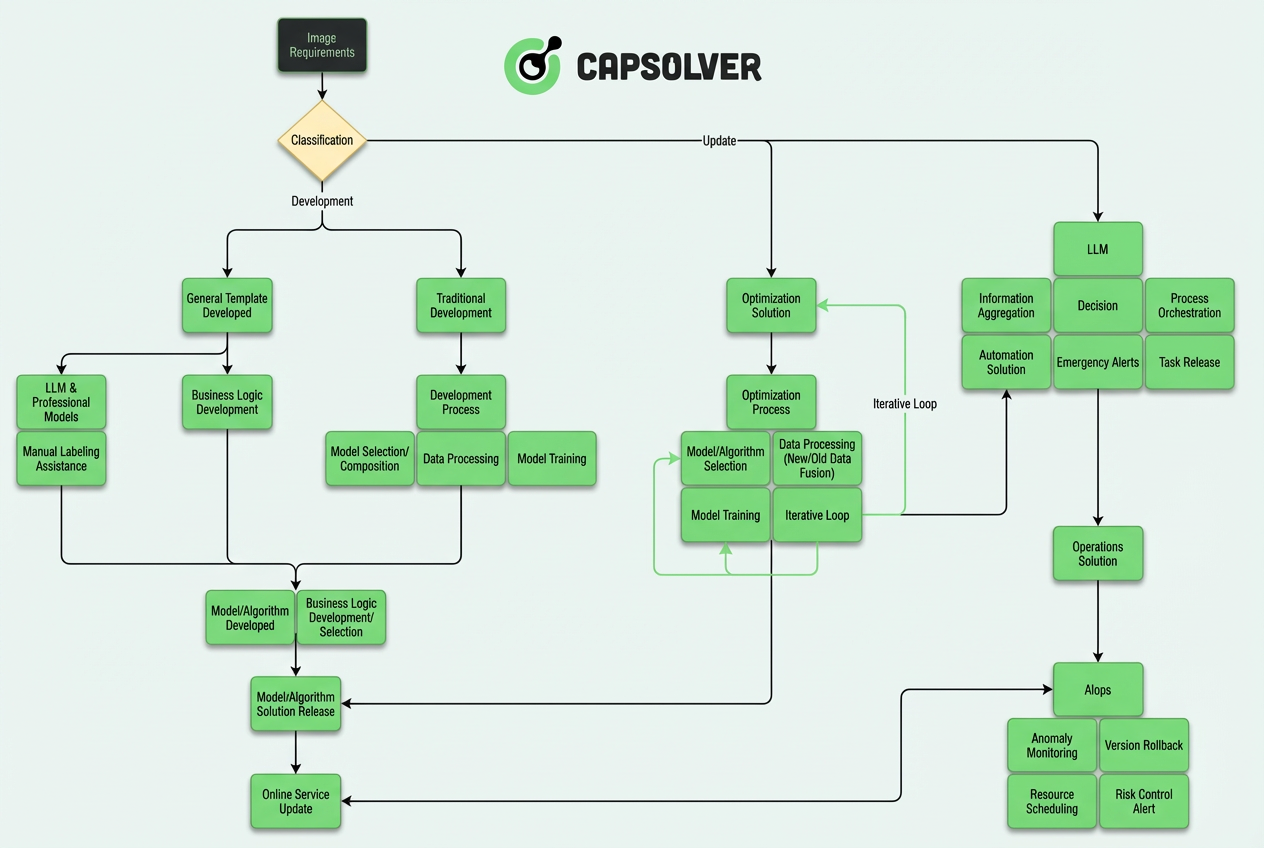
Este artigo explora a engenharia por trás de nosso sistema autônomo de três camadas, conectando a entrada visual bruta ao raciocínio semântico.
De acordo com pesquisa da indústria, até 2026, mais de 80% das empresas terão implantado aplicações habilitadas com IA generativa em ambientes de produção — destacando a rápida transição para fluxos de trabalho automatizados, pipelines de IA e processos multimodais.
Arquitetura Central: Sistema Autônomo de Três Camadas
Com base na prática de engenharia, os sistemas modernos de reconhecimento de CAPTCHA evoluíram de uma arquitetura monolítica de "modelo + regras" para um sistema complexo de autonomia em camadas. A arquitetura inteira pode ser dividida em três camadas centrais:
| Camada | Módulo Central | Posicionamento Funcional | Exemplos de Tecnologia |
|---|---|---|---|
| Camada de Decisão de Aplicação | LLM Brain | Compreensão semântica, orquestração de tarefas, análise de anomalias | GPT-4/Vision, Claude 3, Qwen3, Agentes de LangChain desenvolvidos internamente |
| Camada de Execução de Algoritmos | CV Engine | Detecção de objetos, simulação de trajetória, reconhecimento de imagem | YOLO, ViT, blip, clip, dino |
| Camada de Garantia de O&M | AIops | Monitoramento, rollback, agendamento de recursos, controle de risco | Prometheus, Kubernetes, estratégias de RL personalizadas |
A ideia central dessa arquitetura em camadas é: o LLM é responsável por "pensar", os modelos CV são responsáveis por "executar" e o AIops é responsável por "garantir".
Por que a intervenção do LLM é necessária?
O reconhecimento tradicional de CAPTCHA enfrenta três gargalos fatais:
- Vazio Semântico: Inabilidade de entender textos instrucionais como "Por favor, clique em todas as imagens que contêm xx" ou "Toque no item normalmente usado com o item exibido", enquanto a variedade dessas perguntas aumenta.
- Atraso na Adaptação: Quando os sites-alvo atualizam a lógica de verificação, é necessário reetiquetar e treinar manualmente (ciclos que duram vários dias).
- Tratamento Rígido de Anomalias: Diante de novos modos de defesa (como amostras adversas), os tipos frequentemente mudam de versão, e alguns até aumentam autonomamente a probabilidade de tipos com baixas taxas de passagem. Motores antigos não possuem capacidades autônomas de análise para tais controles de risco.
Nota: O LLM não substitui os modelos CV, mas se torna o "centro neural" do sistema CV, dando-lhe a capacidade de compreender e evoluir.
Mecanismo de Funcionamento da Pipeline de Decisão
O sistema inteiro segue um processo em ciclo fechado de Percepção-Decisão-Execução-Evolução, que pode ser subdividido em quatro etapas-chave:
Etapa 1: Roteamento Inteligente
Quando um novo pedido de imagem entra no sistema, ele primeiro passa por um classificador impulsionado pelo LLM para roteamento inteligente:
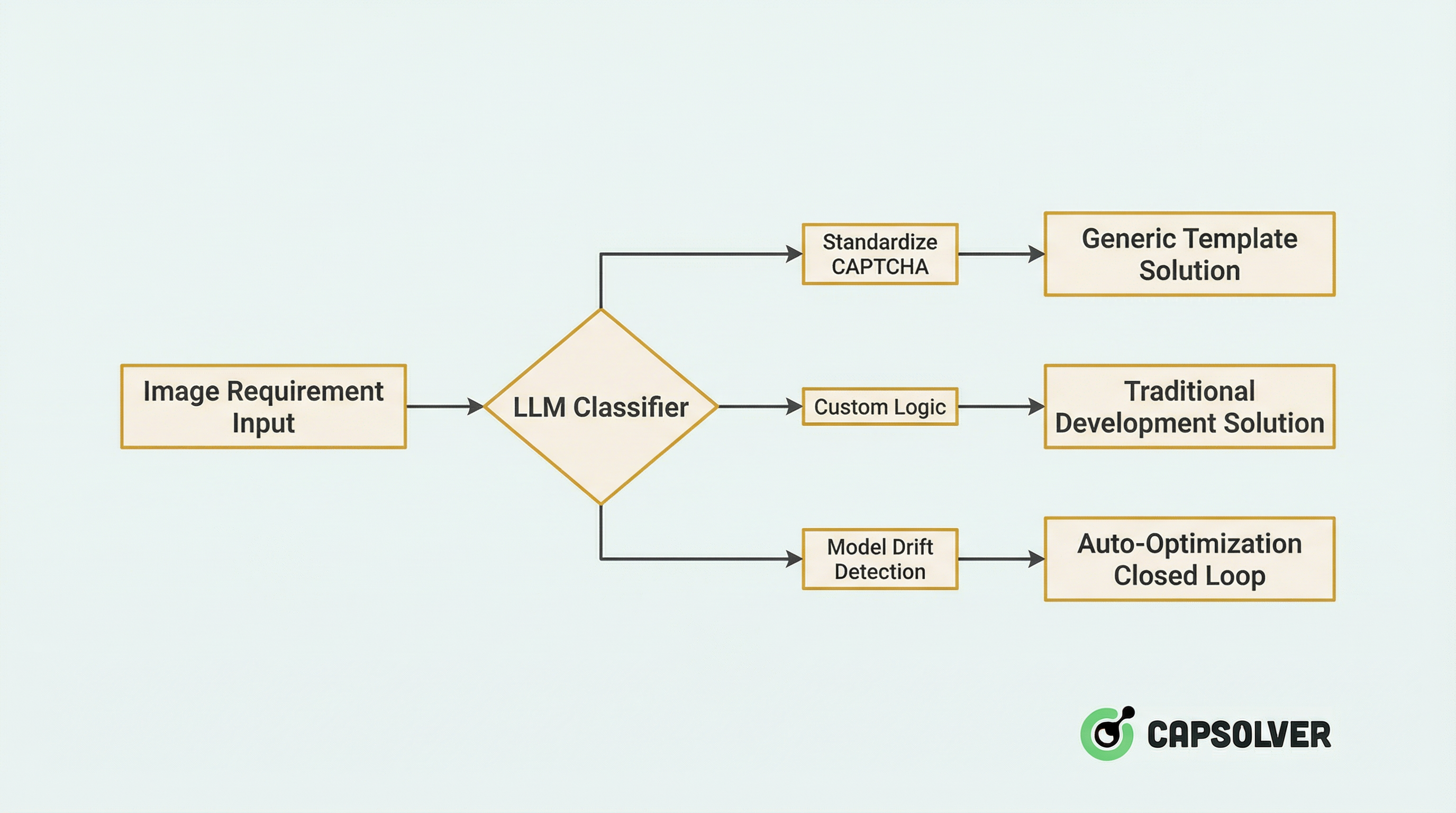
Detalhes Técnicos:
- Classificação Zero-shot: Utilizando as capacidades de compreensão visual dos LLMs para identificar tipos de CAPTCHA (deslizamento, seleção por clique, rotação, ReCaptcha, etc.) sem treinamento.
- Avaliação de Confiança: Quando a confiança do LLM está abaixo de 0,8, ele dispara automaticamente um processo de revisão manual e incorpora a amostra ao conjunto de treinamento incremental.
Dados Práticos: Após a integração desse sistema de roteamento, a eficiência de alocação de recursos aumentou em 47%, e a taxa de classificação incorreta caiu de 12% para 2,1%.
Etapa 2: Desenvolvimento em Duas Trilhas
Com base nos resultados da classificação, o sistema entra em duas trilhas técnicas diferentes:
Trilha A: Trilha de Baixo Código (Resposta Rápida por Meio de Modelos Gerais)
Aplicável a CAPTCHAs padronizados como reCAPTCHA:
Biblioteca de Modelos Universais
language
├── Pré-etiquetagem pelo LLM: Gera automaticamente caixas delimitadoras e rótulos semânticos
├── Modelos Pré-treinados: Detectores gerais treinados em milhões de amostras
└── Pós-processamento pelo LLM: Correção semântica (ex.: distinguir 0/O, 1/l, remover duplicatas)Inovação Chave — Ciclo de Etiquetagem Inteligente:
- O LLM gera pseudo-etiquetas por meio de aprendizado de poucos exemplos.
- Dados de alta qualidade corrigidos por revisão manual retornam ao conjunto de treinamento.
- Os custos de etiquetagem são reduzidos em 60%, enquanto a diversidade de dados aumenta 3 vezes.
Trilha B: Trilha de Código Profissional (Desenvolvimento Profundo Personalizado)
Direcionada a CAPTCHAs personalizados de nível corporativo (ex.: algoritmos específicos de deslizamento, lógica de ângulo de rotação):
Pipeline de Desenvolvimento Tradicional
language
├── Seleção/Composição de Modelo (Detecção + Reconhecimento + Decisão)
├── Processamento de Dados: Limpeza → Etiquetagem → Geração de Amostras Adversas (LLM auxiliado: teste de precisão e filtragem de novos dados)
└── Treinamento Contínuo: Suporta aprendizado incremental e adaptação de domínioPapel do LLM na Geração de Dados:
- Geração de Imagens: Usar modelos de difusão para gerar imagens de fundo diversas e imagens de alvo.
- Geração de Texto: O LLM gera amostras de texto adverso (ex.: fontes distorcidas, borradas, imagens pequenas de objetos do mundo real desenhados de forma abstrata) ou textos instrucionais ("Por favor, clique em todas as imagens que contêm xx").
- Geração e Variação de Regras: Combinar texto e informações para simular regras de combinação de imagem e mecanismos de verificação de controle de risco em tempo real por meio de GANs.
- Mecanismo de Verificação: Usar modelos relacionados ao ViT para verificar e filtrar dados, melhorando a taxa de acerto de amostras positivas.
Etapa 3: Loop de Autoevolução (Núcleo do Framework)
Esta é a parte mais revolucionária da arquitetura. O sistema atinge evolução autônoma por meio do pipeline de AIops → Análise pelo LLM → Otimização Automática:
Liberação de Modelo → Serviço Online → Monitoramento de Anomalias → Análise de Causa Raiz pelo LLM → Geração de Plano de Otimização → Retreinamento Automático → Liberação Canária
Seis Principais Módulos de Decisão do LLM:
| Módulo Funcional | Papel Específico | Valor Comercial |
|---|---|---|
| Resumo de Informação | Agrega logs de erro, identifica padrões de falha (ex.: "taxa de reconhecimento cai em cenas noturnas") | Transforma logs massivos em insights ação |
| Decisão Inteligente | Determina os limiares para disparar atualizações de modelo (ex.: taxa de acerto cai >5% por 1 hora) ou alertas de atualização de controle de risco (taxa de acerto cai >30% instantaneamente) | Evita treinamento excessivo, salva custos de GPU |
| Orquestração de Processos | Orquestra automaticamente o pipeline CI/CD de coleta de dados → etiquetagem → treinamento → teste → liberação | Reduz ciclos de iteração de dias para horas |
| Soluções Automatizadas | Gera estratégias de aumento de dados (ex.: combinar fundos gerados por regras com alvos novos ou coletados) | Preparação de dados sem intervenção manual |
| Alertas de Emergência | Identifica novos padrões de ataque (ex.: produção em massa de amostras adversas) e dispara atualizações de controle de risco | Tempo de resposta < 5 minutos |
| Distribuição de Tarefas | Atribui automaticamente amostras difíceis às equipes de etiquetagem com orientações de etiquetagem geradas pelo LLM | Aumenta a eficiência de etiquetagem em 40% |
Caso Prático: Quando um cliente de comércio eletrônico atualizou seu algoritmo de detecção de lacunas em CAPTCHA de deslizamento, sistemas tradicionais exigiam 3-5 dias de adaptação manual. O sistema baseado em LLM completou detecção de anomalias, análise de causa raiz, geração de dados e ajuste de modelo em 30 minutos, restaurando rapidamente a taxa de reconhecimento de 34% para 96,8%.
Etapa 4: Execução Multimodal (Expansão de Negócios)
O reconhecimento de CAPTCHA não é mais uma tarefa puramente de imagem, mas um processo de tomada de decisão abrangente que integra visão, semântica e comportamento. A expansão para novos tipos não tem mais limitações de tempo e custo.
| Tipo de CAPTCHA | Solução Visual | Ponto de Melhoria do LLM |
|---|---|---|
| CAPTCHA de Deslizamento | Detecção de lacunas (YOLO) + comparação de imagem + simulação de trajetória | O LLM analisa características de textura da lacuna para gerar trajetórias de deslizamento semelhantes às humanas (evitando movimento linear com velocidade constante identificado como robôs) |
| CAPTCHA de Seleção por Clique | Detecção de objetos + posicionamento de coordenadas | O LLM entende instruções semânticas (ex.: "Toque no item normalmente usado com o item exibido"), realizando raciocínio contextual em cenários ambíguos |
| CAPTCHA de Rotação | Previsão de regressão de ângulo | O LLM ajuda a julgar padrões de alinhamento visual e a lidar com cenários de ocultação parcial |
| ReCaptcha v3 | Análise de biométrica comportamental | O LLM sintetiza trajetórias do mouse, intervalos de cliques e padrões de rolagem da página para julgamento humano-robô |
AIops: O Sistema Imunológico dos Sistemas Autônomos
Sem garantia de O&M confiável, mesmo a melhor pipeline de decisão não pode ser colocada em produção. A camada AIops garante a estabilidade do sistema por meio de quatro capacidades principais:
1. Detecção de Anomalias
- Monitoramento de Desvio de Modelo: Comparação em tempo real da distribuição de dados de entrada vs. distribuição do conjunto de treinamento (teste de KS), alertando quando o desvio ultrapassar os limites.
- Rastreamento de Queda de Desempenho: Monitoramento das métricas tridimensionais de taxa de sucesso, latência de resposta e utilização de GPU.
2. Rollback Inteligente
Quando uma nova versão de modelo apresenta comportamento anormal, o sistema não apenas faz rollback automático para uma versão estável, mas também gera um relatório de diagnóstico de falha via análise do LLM, apontando possíveis causas (ex.: "exposição excessiva devido à alta proporção de imagens noturnas nas novas amostras").
3. Agendamento de Recursos Elásticos
Escalabilidade automática com base em previsão de tráfego:
- Períodos de Pico (ex.: Black Friday): Escalabilidade automática para 50 instâncias de GPU.
- Períodos de Baixa Demanda: Escalabilidade para 5 instâncias, migrando dados frios para armazenamento de objetos.
- Economia de custos atinge 65% enquanto garante 99,99% de disponibilidade.
4. Controle de Risco e Defesa contra Amostras Adversas
- Detecção de Amostras Adversas: Identificação de imagens de CAPTCHA com perturbações adversas (ataques FGSM, PGD).
- Controle de Risco Comportamental: Monitoramento de padrões de solicitação anormais (ex.: solicitações de alta frequência de um único IP), disparando automaticamente verificação humano-máquina ou bloqueio de IP.
Caminho de Implementação: Do POC à Produção
Recomendações de implementação com base nessa arquitetura são divididas em quatro fases:
| Fase | Duração | Pontos-chave | Métricas de Sucesso |
|---|---|---|---|
| Fase 1: Infraestrutura | 1-2 meses | Construir base de monitoramento do AIops, alcançar observabilidade de toda a cadeia | MTTR (Tempo Médio para Reparar) < 15 minutos |
| Fase 2: Integração | 2-3 meses | Integração do LLM na análise de erros, alcançando relatórios de diagnóstico automatizados | Carga de trabalho de análise manual reduzida em 70% |
| Fase 3: Automação | 3-4 meses | Construir pipeline de treinamento totalmente automatizado (AutoML + LLM) | Ciclo de iteração do modelo < 4 horas |
| Fase 4: Autonomia | 6-12 meses | Alcançar loop de otimização autônomo impulsionado pelo LLM | Frequência de intervenção manual < 1 vez/semana |
Desafios e Estratégias de Mitigação
Desafio 1: Decisões Incorretas Causadas por Alucinações do LLM
Soluções:
- Adotar arquitetura RAG (Geração Aumentada por Recuperação), fixando as bases das decisões em uma biblioteca de casos reais históricos.
- Estabelecer nós de aprovação manual: Operações de alto risco como rollback de modelo ou exclusão de dados exigem confirmação manual.
Desafio 2: Custos Descontrolados
O custo de análise de imagem do GPT-4V é 50-100 vezes maior do que o de modelos CV tradicionais.
Soluções:
- Processamento em Camadas: Usar modelos CV leves (blip, clip, dino, etc.) para cenários simples, submetendo apenas amostras difíceis ao LLM.
- Gerenciamento de Orçamento de Tokens: Definir tokens máximos por solicitação para evitar picos de custo devido a entradas anormais.
Desafio 3: Cenários com Sensibilidade à Latência
O reconhecimento de CAPTCHA geralmente exige resposta < 2 segundos.
Soluções:
- Análise Assíncrona: Sugestões de otimização do LLM são geradas por processos assíncronos, não bloqueando o caminho de reconhecimento em tempo real.
- Implantação em Borda: Implantar LLMs leves (ex.: Qwen3-8b, Llama-3-8B) em nós de borda, com tempo de processamento < 500ms.
Conclusão: Evolução de Ferramenta para Parceiro
A arquitetura do CapSolver AI-LLM representa uma mudança de paradigma no campo de reconhecimento de CAPTCHA, evoluindo de ferramentas estáticas para agentes dinâmicos. Seu valor reside não apenas em melhorar a precisão do reconhecimento, mas também em construir um ecossistema técnico autossustentável:
- Resposta Mais Rápida: Modelos universais alcançam adaptação em minutos.
- Personalização Mais Profunda: Desenvolvimento tradicional suporta lógica de negócios complexa.
- Evolução Contínua: Laços fechados impulsionados pelo LLM garantem que o sistema esteja sempre atualizado.
"Sistemas de IA futuros não serão mantidos por humanos, mas serão parceiros digitais que colaboram com humanos e crescem de forma autônoma."
Com a evolução contínua dos grandes modelos multimodais (como GPT-4o, Gemini 1.5 Pro), temos motivos para acreditar que o reconhecimento de CAPTCHA não será mais uma confrontação técnica tediosa, mas um processo de negociação automatizado eficiente, seguro e confiável entre sistemas de IA.
Experimente por conta própria! Use o código
CAP26ao se inscrever no CapSolver para receber créditos extras!
Perguntas Frequentes (FAQ)
Q1: Adicionar LLM aumenta a latência de reconhecimento?
A: Por meio de design de arquitetura em camadas, o caminho de reconhecimento em tempo real ainda é tratado por modelos CV otimizados (latência < 200ms). O LLM é principalmente responsável pela análise offline e otimização de estratégias. Para cenários complexos que exigem compreensão semântica, podem ser usados modelos LLM leves implantados na borda (latência < 500ms) ou modos de processamento assíncrono.
Q2: Como lidar com decisões incorretas potenciais do LLM?
A: Implemente um mecanismo de Human-in-the-loop: operações de alto risco (ex.: reversão completa do modelo, exclusão da fonte de dados) exigem aprovação manual. Ao mesmo tempo, estabeleça um ambiente de teste em sandbox onde todos os planos de otimização gerados pelo LLM devem ser validados por meio de testes A/B antes da implantação completa.
Q3: Essa arquitetura é adequada para equipes pequenas?
A: Sim. Recomenda-se implementação progressiva: inicialmente, use apenas APIs de LLM baseadas em nuvem (ex.: Claude 3 Haiku) para análise de anomalias sem construir grandes modelos; use ferramentas de código aberto (LangChain, MLflow) para construir pipelines. À medida que o negócio cresce, introduza gradualmente implantação privada e automação AIops.
Q4: Como o custo se compara a soluções tradicionais puras de CV?
A: O investimento inicial aumenta em cerca de 30-40% (principalmente por chamadas de API do LLM e transformação de engenharia), mas a redução nos custos de O&M manuais por meio da automação geralmente compensa o investimento adicional em 3-6 meses. No longo prazo, devido à eficiência melhorada na iteração de modelos e maiores taxas de automação, o Custo Total de Propriedade (CTP) pode ser reduzido em mais de 50%.
Ver mais
AIMar 27, 2026
Escala da Coleta de Dados para Treinamento de Grandes Modelos de Linguagem: Resolvendo CAPTCHAs em Escala
Aprenda como escalar a coleta de dados para o treinamento de LLM resolvendo CAPTCHAs em larga escala. Descubra estratégias automatizadas para construir conjuntos de dados de alta qualidade para modelos de IA.
AIMar 24, 2026
Como resolver qualquer CAPTCHA no HyperBrowser usando o CapSolver (Guia Completo de Configuração)
Resolva qualquer CAPTCHA no HyperBrowser usando o CapSolver. Automatize reCAPTCHA, Turnstile, AWS WAF e de forma mais fácil.
