画像パズルを解くための最高のAI:2026年のトップツールと戦略

Sora Fujimoto
AI Solutions Architect
TL;Dr
- 画像パズルを解決する最適なAIは、高度なコンピュータビジョンと機械学習を組み合わせ、スライダー、回転、オブジェクト選択などの複雑な視覚的チャレンジを自動化します。
- CapSolverは、ビジョンエンジンやImageToTextTaskなどの専用APIを提供し、ポーリングなしで即座に視覚的パズルを解決する最高のソリューションです。
- グローバルなコンピュータビジョン市場は急速に拡大しており、2030年までに582億9000万ドルに達すると予測されています。これは、画像認識におけるAIの依存が増加していることを示しています。
- n8nなどの自動化プラットフォームと最適なAIを統合することで、ワークフローをスムーズにし、データ抽出の効率を向上させます。
- AIツールの倫理的かつコンプライアンスに準拠した使用は、持続的で安全な自動化運用を保証します。
はじめに
オンラインでより複雑な視覚的チャレンジに直面する開発者、データアナリスト、自動化の愛好家にとって、画像パズルを解決する最適なAIを見つけることは不可欠です。スライダーパズルから複雑な画像認識タスクまで、従来の自動化方法はしばしば限界があります。適切なAIソリューションは時間とコストを節約し、自動化ワークフローの正確性と信頼性を確保します。本記事では、現在利用可能な最高のツールを紹介し、CapSolverの高度な機能に焦点を当てます。データ収集の自動化や高度なウェブスクレイパーの構築に携わる方にとって、画像パズルを解決する最適なAIの活用は、プロジェクトの成功と効率を飛躍的に向上させます。
視覚的パズルとAIソリューションの進化
視覚的パズルは、単純な歪んだテキストから、スライダー、画像回転タスク、オブジェクト選択グリッドなど、正確な空間認識とパターン認識を必要とする複雑なインタラクティブなチャレンジへと進化しました。これらのパズルがより高度になるにつれて、解決するための技術も進化する必要があります。
画像パズルを解決する最適なAIは、畳み込みニューラルネットワーク(CNN)と高度な機械学習アルゴリズムを活用します。これらのシステムは画像のピクセルデータを分析し、エッジ、形状、空間的関係を特定します。業界の報告によると、コンピュータビジョン市場は19.8%のCAGRで成長し、2030年までに582億9000万ドルに達すると予測されています。この急成長は、複雑な視覚データを処理できる信頼性の高いAIソリューションへの需要が高まっていることを示しています。
汎用的なOCRツールがテキストを抽出するのに対し、画像パズルを解決する最適なAIは文脈を理解します。例えば、パズルピースが背景に合うために必要な正確な距離や、画像を整列させるために必要な正確な角度を計算できます。この精度の高さが、基本的な自動化と高度なAI駆動型ソリューションの違いを生み出しています。
CapSolverが画像パズル解決の最適なAIとなる理由
画像パズルを解決する最適なAIを評価する際、CapSolverは明確なリーダーです。CapSolverは視覚認識タスクに特化した専用APIを提供し、驚くほど高速で正確な結果を提供します。
Vision Engine:最高の視覚的パズル解決ツール
Vision Engineは、CapSolverの旗艦ソリューションで、インタラクティブな視覚的チャレンジに対応しています。特定のパズルタイプに特化した複数のモジュールをサポートしています:
- slider_1:スライダーパズルピースが背景に合うために必要な距離を計算します。
- rotate_1 & rotate_2:単一または共円画像の正しい回転角度を決定します。
- shein:特定の質問に基づいてオブジェクト選択タスクの境界ボックスを識別します。
- ocr_gif:アニメーションGIFからのテキスト抽出、これは従来のOCRが失敗するタスクです。
Vision Engineは認識操作であり、1回のAPIコールで結果を即座に返します。トークンを待つ必要や継続的なポーリングが不要で、リアルタイムの自動化に非常に効率的です。
ImageToTextTask:正確なOCR
静的な画像からテキストを抽出するパズルには、CapSolverはImageToTextTaskを提供します。このAPIは複数の専門的なモジュールをサポートし、数値キャプチャのための専用numberモジュールは90%以上の精度を誇ります。同時に最大9枚の画像を処理でき、バッチ処理に最適です。
CapSolverと汎用AIツールの比較概要
| 特徴 | CapSolver Vision Engine | 汎用AIソルバー |
|---|---|---|
| 応答時間 | 即時(1回のAPIコール) | 遅延(ポーリングが必要) |
| 専門的なモジュール | あり(スライダー、回転、オブジェクト選択) | 限られている(主に基本的なOCR) |
| 統合 | 容易(REST API、SDK、n8n) | 一般的に複雑 |
| 正確性 | 高(カスタムトレーニングモデル) | 変動(プロンプトに依存) |
これらの専門的なツールを活用することで、開発者は自動化ワークフローにおいてCapSolverを信頼して利用できます。
n8nとの画像パズル解決AIの統合
n8nなどの自動化プラットフォームは非常に強力ですが、視覚的パズルに直面するとしばしば問題を抱えます。CapSolverとn8nを統合することで、これらのワークフローは手動の介入なしに進行可能になります。
n8nで画像パズル解決の最適なAIを実装するには、CapSolverのコミュニティノードを使用します。このプロセスでは、ノードをVision Engine操作に構成し、base64エンコードされた画像と必要に応じて背景画像を提供します。ノードはこのデータをCapSolverに送信し、スライダーパズルのピクセル距離などの解決策を即座に受け取ります。
この統合は、CapSolverのVision Engineをn8nで使用する方法に関するガイドに詳細に記載されています。n8nの視覚的なワークフロービルダーとCapSolverのAI機能を組み合わせることで、視覚的な中断をスムーズに処理できる頑丈なスクレイパーと自動化システムを構築できます。
CapSolverによるパズル解決のコード実装
CapSolverのPython SDKを使用すると、画像パズルを解決する最適なAIの実装は簡単です。以下は、公式CapSolverドキュメントに基づく参考実装です。
python
# pip install --upgrade capsolver
import capsolver
capsolver.api_key = "YOUR_API_KEY"
# 例: Vision Engineを使用してスライダーパズルを解決
solution = capsolver.solve({
"type": "VisionEngine",
"module": "slider_1",
"image": "base64_encoded_puzzle_piece...",
"imageBackground": "base64_encoded_background..."
})
print(f"スライダーパズルの距離: {solution.get('distance')} ピクセル")このコードは、画像パズルを解決する最適なAIがPythonスクリプトにどのように簡単に統合できるかを示しています。APIが重い作業を処理し、正確で実行可能なデータを返します。
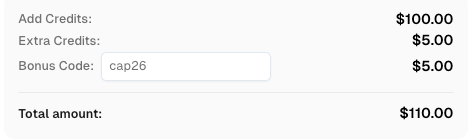
CapSolverボーナスコードを取得する
自動化予算を即座に増やす!
CapSolverアカウントにチャージする際にボーナスコード CAP26 を使用すると、毎回チャージするたびに5%のボーナスを獲得できます。制限はありません。
今すぐCapSolverダッシュボードで取得してください。
コンプライアンスと倫理的な自動化の確保
画像パズルを解決する最適なAIを展開する際には、コンプライアンスと倫理的な運用を最優先にすることが重要です。自動化は生産性の向上、公開データの責任ある収集、および正当なビジネスプロセスの効率化に使用されるべきです。
開発者は自動化システムがウェブサイトの利用規約を尊重し、サーバーに過負荷をかけないことを確認する必要があります。CapSolverはその技術を責任ある方法で使用することを推奨し、効率的で倫理的なデータ収集を促進するツールを提供しています。これらの原則に従うことで、組織は持続可能な方法でAIの能力を活用できます。責任ある自動化に関するより詳しい情報は、AI駆動型画像認識の分野を参照してください。
視覚認識におけるAIの未来
画像パズルを解決する最適なAIの技術は常に進化しています。 2025年のグローバルAI画像認識市場は573億6000万ドルから2030年には1092億3000万ドルに急成長すると予測されています、これによりさらに高度なモデルが登場することが予想されます。今後のバージョンでは、より高い正確性、より高速な処理速度、そしてより複雑な視覚論理パズルを解決する能力が期待されます。
AIモデルが進化するにつれて、人間と機械の視覚的理解のギャップはさらに縮小していきます。CapSolverなどのツールはこの進化の先頭に立っており、新しい課題に対応するためのモジュールを継続的に更新しています。Statistaによると、コンピュータビジョン市場は12.6%のCAGRで大幅な成長を見込むと予測されています。したがって、自動化された視覚認識に依存する人は、これらの進展を把握することが不可欠です。
結論
現代の自動化とデータ抽出において、画像パズルを解決する最適なAIを見つけることは不可欠です。CapSolverは、ビジョンエンジンとImageToTextTask APIを通じて最も強力で効率的なソリューションを提供しています。スライダー、回転、テキスト認識に特化した専門的なモジュールにより、汎用的なAIツールを上回るスピードと正確性を実現しています。
n8nなどのプラットフォームにこれらの機能を統合することで、開発者はシームレスで中断のないワークフローを構築する力を得ます。自動化プロジェクトをスケールアップする際には、倫理的な運用を最優先にし、CapSolverの高度な機能を活用して最適な結果を得ることが重要です。
質問と回答
CapSolverが画像パズル解決の最適なAIとなる理由は何ですか?
CapSolverは、スライダーと回転などの視覚的チャレンジの正確な解決策を即座に計算する専用で特化したモデル(例えばVision Engine)を提供します。汎用OCRツールがテキストを読み取るだけであるのに対し、CapSolverはその違いを生み出しています。
n8nに画像パズル解決を統合するにはどうすればいいですか?
n8nでCapSolverコミュニティノードを使用し、Vision Engine操作にノードを構成することで、base64形式の画像を送信し、即座に必要なパズルの解決策(例:ピクセル距離)を受け取ることができます。
CapSolver APIをPythonで実装するのは難しいですか?
いいえ、実装は簡単です。公式のCapSolver Python SDKを使用し、必要な画像データとモジュールタイプを渡すことで、数行のコードで視覚的パズルを解決できます。
Vision Engineが解決できる種類の視覚的パズルは何ですか?
Vision Engineは、スライダーパズル用のslider_1、画像の整列用のrotate_1とrotate_2、オブジェクト選択用のshein、およびアニメーションテキスト認識用のocr_gifを含む複数のモジュールをサポートしています。
ImageToTextTaskとVision Engineの違いはどこにありますか?
ImageToTextTaskは静的な画像からのテキストと数字の抽出に特化しており、Vision Engineはインタラクティブな視覚的パズルの空間的関係と論理を計算するためのものです。